「GPTの内部- I:テキスト生成の理解」
GPTの内部- I テキスト生成の理解
ChatGPTの背後にあるモデルの簡単な説明

さまざまな領域の同僚と定期的に関わりながら、データサイエンスのバックグラウンドがほとんどない人々に機械学習の概念を伝えるというチャレンジが楽しいです。ここでは、GPTがどのように構築されているかを簡単な言葉で説明しようと試みます。
ChatGPTの人気のある魔法の裏には、あまり人気のないロジックがあります。あなたはChatGPTにプロンプトを書き込み、それがテキストを生成し、それが正確であるかどうかにかかわらず、人間の回答に似たものを生成します。では、なぜそれがあなたのプロンプトを理解し、一貫した理解可能な回答を生成できるのでしょうか?
トランスフォーマーニューラルネットワーク。私たちの場合、テキストを含む非構造データを処理するために設計されたアーキテクチャです。アーキテクチャと言うと、基本的には複数の層で並行して行われた数学的操作のシリーズを意味します。この方程式のシステムを通じて、テキスト生成の長年の課題を解決するのに役立ついくつかのイノベーションが導入されました。それは、5年前まで解決に苦労していた課題です。
GPTはもう5年も存在しているのに(実際、GPTの論文は2018年に公開されました)、GPTはもはや新しい情報ではありませんか?なぜ最近非常に人気になったのですか?GPT 1、2、3、3.5(ChatGPT)および4の違いは何ですか?
すべてのGPTバージョンは同じアーキテクチャ上に構築されています。ただし、後続のモデルごとにより多くのパラメータが含まれ、より大きなテキストデータセットを使用してトレーニングされました。後のGPTリリースでは、特に強化学習を通じた人間のフィードバックによるトレーニングプロセスなど、明らかに他の新機能が導入されました。これについては、このブログシリーズの第3部で説明します。
ベクトル、行列、テンソル。これらの派手な言葉は、基本的には数値の塊を含む単位です。これらの数値は、主に乗算と加算の数学的操作を通じて、最適な出力値に到達するまで処理されます。最適な出力値とは、可能な結果の確率です。
出力値?この意味では、言語モデルによって生成されるテキストですよね?はい。では、入力値は何ですか?私のプロンプトですか?はい、ですが完全にではありません。それ以外には何があるのですか?
次のブログ記事のトピックである異なるテキストデコーディング戦略に移る前に、あいまいさを取り除くのに役立ちます。最初に私たちが尋ねた基本的な質問に戻ってみましょう。それはどのようにして人間の言語を理解するのでしょうか?
Generative Pre-trained Transformers。GPTの略称である3つの単語です。上記でトランスフォーマーパートに触れましたが、それは重い計算が行われるアーキテクチャを表しています。しかし、実際に何を計算しているのでしょうか?どこから数値を得るのですか?それは言語モデルであり、テキストを書くだけでテキストを計算することができるのでしょうか?
データは無関係です。すべてのデータは、テキスト、音声、画像という形式に関係なく同じです。¹
トークン。テキストを小さなチャンク(トークン)に分割し、それぞれに一意の番号(トークンID)を割り当てます。モデルは単語や画像、音声録音を知りません。それらを数値の長いシリーズ(パラメータ)で表現する方法を学びます。トークンは意味を伝える言語の単位であり、トークンIDはトークンをエンコードする一意の番号です。
明らかに、言語をトークン化する方法は異なる場合があります。トークン化には、文、単語、単語の一部(サブワード)、または個々の文字に分割することが含まれることがあります。
言語コーパスに50,000のトークンがあるシナリオを考えてみましょう(GPT-2には50,257があります)。トークン化後、それらの単位をどのように表現しますか?
文: "学生たちは大きなパーティーで卒業を祝います"トークンラベル:['[CLS]', '学生たち', 'は', '大きな', 'パーティー', 'で', '卒業', 'を', '祝います', '[SEP]']トークンID:tensor([[ 101, 2493, 8439, 1996, 7665, 2007, 1037, 2502, 2283, 102]])上記は単語に分割された例文です。トークン化の手法は実装によって異なる場合があります。現時点で私たちが理解するために重要なのは、言語単位(トークン)の数値表現を対応するトークンIDを通じて取得することです。では、これらのトークンIDを持っているので、計算が行われるモデルに直接入力するだけでよいのでしょうか?
数学では基数が重要です。トークン表現としての101と2493はモデルに影響を与えます。なぜなら、私たちが行っていることは主に大量の数字の乗算と合計です。したがって、数を101または2493で乗算することは重要です。では、トークンが101という数値で表されているために、任意にトークン化されたものよりも2493よりも重要でないことをどのように確認できますか?架空の順序を引き起こさずに単語をエンコードするにはどうすればよいでしょうか?
ワンホットエンコーディング。トークンの疎なマッピング。ワンホットエンコーディングとは、各トークンをバイナリベクトルとして投影する技術です。つまり、ベクトルの中の1つの要素だけが1(「hot」)であり、残りは0(「cold」)です。
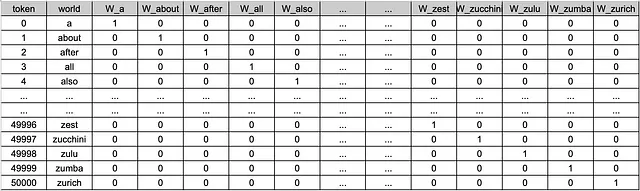
トークンは、コーパス内のトークンの合計数を持つベクトルで表されます。簡単に言えば、言語に50,000のトークンがある場合、各トークンは50,000のベクトルで表され、その中の1つの要素だけが1で他は0です。この投影に含まれるベクトルは、非ゼロの要素が1つだけであるため、疎な表現と呼ばれます。ただし、この手法は非常に効率的ではありません。トークンID間の人工的な基数を取り除くことに成功しましたが、単語の意味に関する情報を抽出することはできません。疎なベクトルを使用して、単語「party」が祝賀会を指すのか政治組織を指すのかを理解することはできません。さらに、サイズが50,000のベクトルで各トークンを表すことは、合計で50,000個の長さ50,000のベクトルを意味します。これは、必要なメモリと計算量の面で非常に効率的ではありません。幸いにも、より良い解決策があります。
埋め込み。トークンの密な表現。トークン化された単位は、各トークンが固定サイズの連続ベクトル表現に変換される埋め込み層を通過します。たとえば、GPT 3の場合、各トークンは768個の数値からなるベクトルで表されます。これらの数値はランダムに割り当てられ、その後、多くのデータ(トレーニング)を見た後にモデルによって学習されます。
トークンのラベル:“party”トークン:2283埋め込みベクトルの長さ:768埋め込みテンソルの形状:([1, 10, 768])埋め込みベクトル:tensor([ 2.9950e-01、-2.3271e-01、3.1800e-01、-1.2017e-01、-3.0701e-01、-6.1967e-01、2.7525e-01、3.4051e-01、-8.3757e-01、-1.2975e-02、-2.0752e-01、-2.5624e-01、3.5545e-01、2.1002e-01、2.7588e-02、-1.2303e-01、5.9052e-01、-1.1794e-01、4.2682e-02、7.9062e-01、2.2610e-01、9.2405e-02、-3.2584e-01、7.4268e-01、4.1670e-01、-7.9906e-02、3.6215e-01、4.6919e-01、7.8014e-02、-6.4713e-01、4.9873e-02、-8.9567e-02、-7.7649e-02、3.1117e-01、-6.7861e-02、-9.7275e-01、9.4126e-02、4.4848e-01、1.5413e-01、3.5430e-01、3.6865e-02、-7.5635e-01、5.5526e-01、1.8341e-02、1.3527e-01、-6.6653e-01、9.7280e-01、-6.6816e-02、1.0383e-01、3.9125e-02、-2.2133e-01、1.5785e-01、-1.8400e-01、3.4476e-01、1.6725e-01、-2.6855e-01、-6.8380e-01、-1.8720e-01、-3.5997e-01、-1.5782e-01、3.5001e-01、2.4083e-01、-4.4515e-01、-7.2435e-01、-2.5413e-01、2.3536e-01、2.8430e-01、5.7878e-01、-7.4840e-01、1.5779e-01、-1.7003e-01、3.9774e-01、-1.5828e-01、-5.0969e-01、-4.7879e-01、-1.6672e-01、7.3282e-01、-1.2093e-01、6.9689e-02、-3.1715e-01、-7.4038e-02、2.9851e-01、5.7611e-01、1.0658e+00、-1.9357e-01、1.3133e-01、1.0120e-01、-5.2478e-01、1.5248e-01、6.2976e-01、-4.5310e-01、2.9950e-01、-5.6907e-02、-2.2957e-01、-1.7587e-02、-1.9266e-01、2.8820e-02、3.9966e-03、2.0535e-01、3.6137e-01、1.7169e-01、1.0535e-01、1.4280e-01、8.4879e-01、-9.0673e-01、... ])上記は、単語「party」の埋め込みベクトルの例です。
今、私たちは50,000×786のベクトルのサイズを持っており、50,000×50,000のワンホットエンコーディングと比べて、はるかに効率的です。
埋め込みベクトルはモデルへの入力となります。密な数値表現のおかげで、単語の意味を捉えることができます。似ているトークンの埋め込みベクトルは、お互いに近い位置になります。
コンテキスト内で2つの言語単位の類似性をどのように測定することができますか?同じサイズの2つのベクトル間の類似性を測定するためのいくつかの関数があります。例を使って説明しましょう。
「cat」、「dog」、「car」、「banana」というトークンの埋め込みベクトルを持つシンプルな例を考えましょう。単純化のために、埋め込みサイズを4とします。つまり、各トークンを表現するために4つの学習された数値があります。
import numpy as npfrom sklearn.metrics.pairwise import cosine_similarity# "cat"、"dog"、"car"、"banana"の例の単語埋め込みembedding_cat = np.array([0.5, 0.3, -0.1, 0.9])embedding_dog = np.array([0.6, 0.4, -0.2, 0.8])embedding_car = np.array([0.5, 0.3, -0.1, 0.9])embedding_banana = np.array([0.1, -0.8, 0.2, 0.4])上記のベクトルを使用して、コサイン類似度を使用して類似度スコアを計算しましょう。人間の論理では、犬と猫の方がバナナと車よりも関連が高いと考えられます。私たちは数学によって論理をシミュレートできるでしょうか?
# コサイン類似度を計算similarity = cosine_similarity([embedding_cat], [embedding_dog])[0][0]print(f"'cat'と'dog'のコサイン類似度:{similarity:.4f}")# コサイン類似度を計算similarity_2 = cosine_similarity([embedding_car], [embedding_banana])[0][0]print(f"'car'と'banana'のコサイン類似度:{similarity:.4f}")「cat」と「dog」の単語は非常に高い類似度スコアを持ち、「car」と「banana」の単語は非常に低いスコアを持っていることがわかります。今度は、言語コーパスの各トークンごとに長さ768の埋め込みベクトルを想像してみましょう。これにより、関連する単語を見つけることができます。
さて、以下の2つの文を見てみましょう。これらはより高い意味的複雑さを持っています。
"学生たちは大きなパーティーで卒業を祝います""副リーダーは党内で高く評価されています"最初の文と2番目の文からの単語「party」は異なる意味を伝えています。大規模な言語モデルは、「party」を政治組織としての意味と、社交イベントとしての「party」の違いをマッピングすることができるのでしょうか?
トークンの埋め込みに頼って、同じトークンの異なる意味を区別できるでしょうか?真実は、埋め込みがさまざまな利点を提供してくれる一方で、人間の言語の意味的な複雑さを解き明かすのには十分ではないということです。
セルフアテンション。この問題に再び対処する方法は、Transformerニューラルネットワークによって提供されました。クエリ、キー、バリューマトリクスという名前の新しい重みのセットを生成します。これらの重みは、トークンの埋め込みベクトルを新しい埋め込みベクトルのセットとして表現するために学習されます。簡単に言えば、元の埋め込みベクトルの加重平均を取ることによって行われます。各トークンは、入力文の他のすべてのトークン(それ自体も含む)に「参加」し、一連のアテンションの重みまたは他の言葉で言うところの「文脈埋め込み」のセットを計算します。
実際のところ、それは単に入力文の単語の重要性をマッピングするだけであり、トークンの埋め込みを使用して計算される一連の数値(アテンションの重み)を割り当てることです。
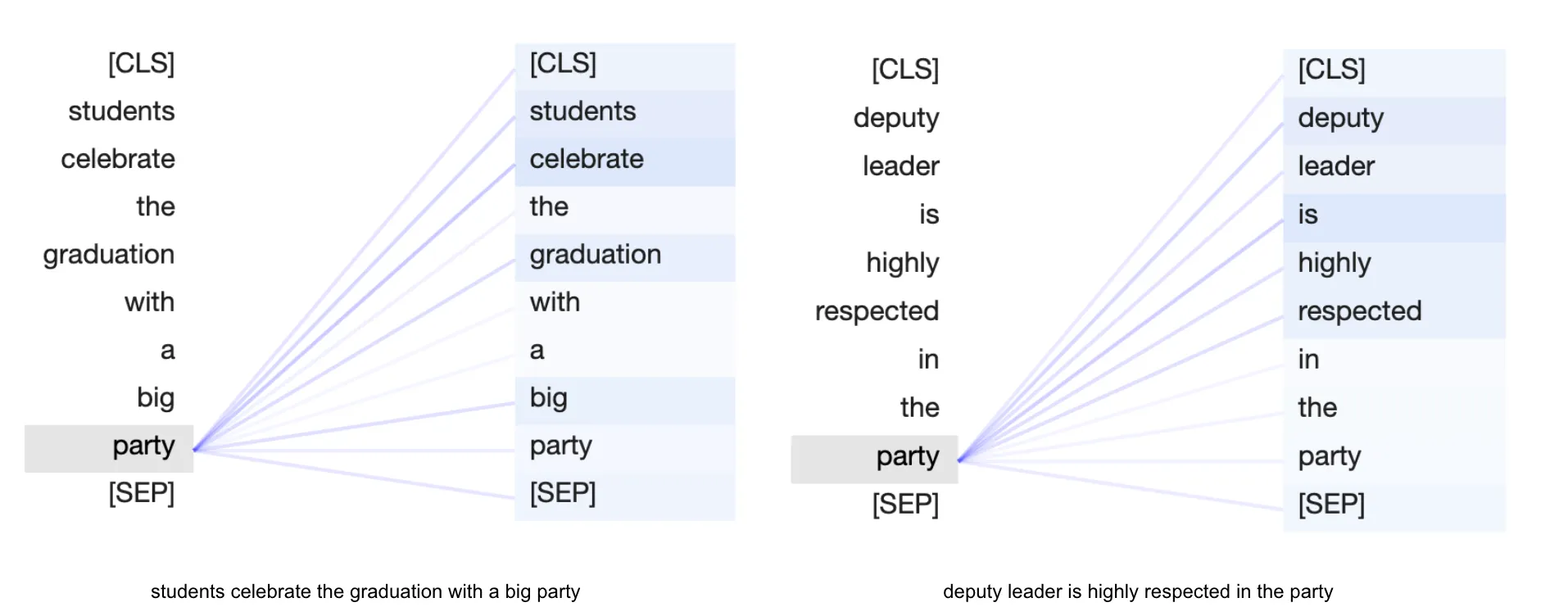
上記の視覚化は、2つの文の「party」というトークンが他のトークンに対してどのように「アテンション」しているかを示しています。接続の太さは、トークンの重要性または関連性を示しています。アテンションと「参加」は、単に数値とその大きさであり、単語の重要性を数値で表すために使用されます。最初の文では、単語「party」は単語「celebrate」に最も参加しており、2番目の文では単語「deputy」が最もアテンションしています。これにより、モデルは周囲の単語を調べることで文脈を組み込むことができます。
アテンションメカニズムで説明したように、新しい重み行列である「クエリ」、「キー」、「値」(通常は埋め込みベクトルよりも小さいサイズ)を導出します(単にq、k、vと呼ばれます)。これらは言語単位の複雑さを捉えるためにアーキテクチャに導入される、同じサイズの連鎖行列です。アテンションパラメータは、単語、単語のペア、単語のペアのペア、単語のペアのペアのペアなどの関係を明らかにするために学習されます。以下は、最も関連性の高い単語を見つけるためのクエリ、キー、値行列の可視化です。
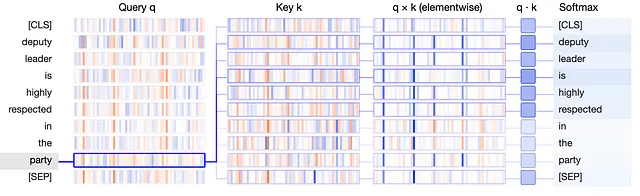
この可視化では、qベクトルとkベクトルを垂直バンドとして示しており、各バンドの太さはその大きさを反映しています。トークン間の接続は、アテンションによって決定された重みを示しており、”party”のqベクトルが”is”、”deputy”、”respected”のkベクトルと最も強く一致していることを示しています。
アテンションメカニズムとq、k、vの概念をより具体的にするために、パーティーに行って素晴らしい曲を聞いたと想像してください。パーティーの後、その曲を見つけてもう一度聞きたくてたまらないのですが、歌詞のわずかな5つの単語と一部の曲のメロディ(クエリ)しか覚えていません。曲を見つけるために、パーティープレイリスト(キー)を調べ、パーティーで再生されたリストのすべての曲を聴きます(類似性関数)。曲を認識したら、曲名(値)をメモします。
トランスフォーマーが導入した最後の重要なトリックは、ベクトル埋め込みに位置エンコーディングを追加することです。単語の位置情報を捉えたいからです。これにより、次のトークンをより正確に予測するための文脈に沿った情報を強化することができます。文脈を完全に変えることがしばしばあるため、これは重要な情報です。例えば、文「Tim chased clouds all his life」と「clouds chased Tim all his life」は本質的にまったく異なります。
これまで基本的なレベルで探求したすべての数学的なトリックは、入力トークンのシーケンスが与えられた場合に次のトークンを予測するという目的を持っています。実際には、GPTはテキスト生成、言い換えれば次のトークンの予測という単純なタスクで訓練されています。その本質的な部分では、私たちはトークンのシーケンスがそれより前に表示されたトークンのシーケンスが与えられた場合のトークンの確率を測定しています。
ランダムに割り当てられた数値からモデルが最適な数値を学ぶのはどのようにしているのか疑問に思うかもしれません。それはおそらく別のブログ投稿のトピックですが、それは実際に理解する上で基本的な要素です。また、基礎を疑問に思っているということは素晴らしい兆候です。明確さを持たせるために、損失関数と呼ばれるメトリックに基づいてパラメータを調整する最適化アルゴリズムを使用します。このメトリックは、予測値と実際の値を比較して計算されます。モデルはメトリックの確率を追跡し、損失の値がどれだけ小さいかまたは大きいかに応じて数値を調整します。このプロセスは、ルールを設定したアルゴリズムで定められたルールに基づいて、損失がより小さくならない限り繰り返されます。例えば、損失を計算し、重みを調整する頻度をどのように設定するかというハイパーパラメータがあります。これは学習の基本的な考え方です。
この短い投稿で少なくとも少しは説明できたことを願っています。このブログシリーズの次の部分では、プロンプトの重要性に焦点を当てたデコーディング戦略について説明します。3番目で最後の部分では、ChatGPTの成功の鍵となる要素である強化学習について取り上げます。読んでいただきありがとうございました。次回までお楽しみに。
参考文献:
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention Is All You Need,” in Advances in Neural Information Processing Systems 30 (NIPS 2017), 2017.
J. Vig, “A Multiscale Visualization of Attention in the Transformer Model,” In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pp. 37–42, Florence, Italy, Association for Computational Linguistics, 2019.
L. Tunstall, L. von Werra, and T. Wolf, “Natural Language Processing with Transformers, Revised Edition,” O’Reilly Media, Inc., Released May 2022, ISBN: 9781098136796.
1 – レイジープログラマーブログ
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
