「Googleの研究者は、シーンのダイナミクスに先行する画像空間をモデリングするための新しい人工知能アプローチを発表します」
Google researchers announce a new AI approach for modeling image space that precedes scene dynamics.


風や水の流れ、呼吸、自然のリズムなどのために、静止しているように思われる画像にも微細な振動が含まれています。これは自然界が常に動いているためです。人間は特に動きに敏感であり、これが最も顕著な視覚信号の一つになります。動きのない(またはやや幻想的な動きがある)画像は時折不安定であり、超現実的に感じられることがあります。しかし、人々はシーン内の動きを理解したりイメージしたりすることは簡単です。モデルに現実的な動きを獲得させることはより複雑です。シーンの物理的なダイナミクス、または物体の質量、弾性などの特定の物理的特性によって物体に作用する力は、人々が外部の世界で見る動きを生み出します。
これらの力や特性は、大規模に測定・捉えることが困難ですが、観察された動きから捉えて学ぶことができるため、しばしば定量化する必要はありません。この観測可能な動きは多様な形であり、複雑な物理プロセスに基づいていますが、予測可能です。ろうそくは特定のパターンで揺らぎ、木々は揺れ動き、葉をなびかせます。彼らは、静止画像を見ることで、その画像に基づく自然な動きの分布やその時点で進行中だったかもしれない可能性のある動きを想像することができます。この予測可能性は、彼らの人間の現実のシーンへの知覚に根付いています。
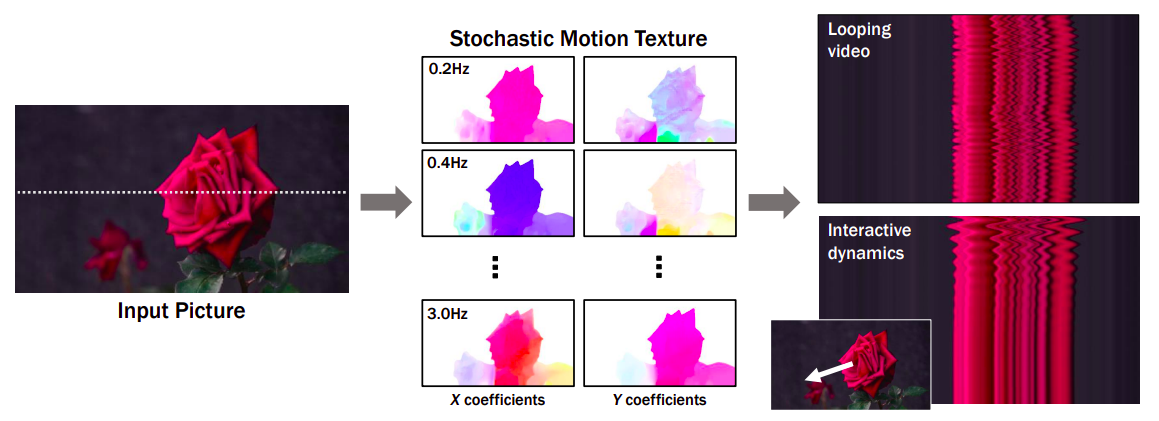
図1: この手法がシーンのダイナミクスに先行する生成画像空間のモデリングをどのようにシミュレートするかが分かります。単一のRGB画像から始めて、モデルはフーリエ領域で密な長期的な動きの軌跡をシミュレートするニューラル確率モーションテクスチャを作成します。彼らは、このモーション先行情報が、単一の画像を滑らかにループするムービーに変換したり、インタラクティブなユーザーの刺激(オブジェクトの点をドラッグしてリリースするなど)に応じてオブジェクトのダイナミクスを模倣したりするためにどのように使用できるかを示しています。彼らは、ビデオの10秒間(入力画像に表示されるスキャンラインに沿った)の空間-時間X-tスライスを使用して、右側の出力フィルムを視覚化しています。
- エイントホーフェンとノースウェスタン大学の研究者が、外部のトレーニングを必要としないオンチップ学習が可能な新しいニューロモーフィックバイオセンサーを開発しました
- 疾病の原因を特定するための遺伝子変異のカタログ
- メリーランド大学とMeta AIの研究者は、「OmnimatteRF」という新しいビデオマッティング手法を提案していますこの手法は、動的な2D前景レイヤーと3D背景モデルを組み合わせたものです
人間がこれらの潜在的な動きを容易に視覚化できるため、これをデジタル上で類似の分布をシミュレートすることは自然な研究課題です。最近の生成モデル、特に条件付き拡散モデルの進歩により、テキストに基づいた実際の画像の分布を含む非常に豊かで複雑な分布をシミュレートすることが可能になりました。この能力のおかげで、以前は実現不可能だったテキストに基づいたランダムで多様なリアルなビジュアル素材の生成など、多数の応用が実現可能になりました。これらの画像モデルの成功を受けて、ビデオや3Dジオメトリなど、さまざまなドメインのモデリングも同様に下流応用において有益であることが最近の研究で示されています。
この論文では、Google Researchの研究者が、単一の画像内の各ピクセルのモーション、または画像空間のシーンモーションとして知られるものの生成先行をモデリングしています。このモデルは、大量の実際のビデオシーケンスから自動的に取得されるモーション軌跡を使用してトレーニングされます。トレーニングされたモデルは、入力画像に基づいてニューラル確率モーションテクスチャを予測し、各ピクセルの将来の軌跡を記述するモーション基底係数の集合を生成します。彼らはフーリエ級数を基底関数として選択し、風で揺れる木や花など、振動するダイナミクスを持つ現実世界の風景に限定して分析します。彼らは、拡散モデルを使用してニューラル確率モーションテクスチャを予測し、1回の予測で1つの周波数の係数を生成し、これらの予測を周波数帯域全体で調整します。
図1に示されているように、生成された周波数空間のテクスチャは、画像ベースのレンダリング拡散モデルを使用して密な長距離ピクセルモーション軌跡に変換され、静止画像をリアルなアニメーションに変換します。モーションキャプチャに関する先行研究と比較して、動画合成を行う従来の技術とは異なり、彼らのモーション表現はより一貫性のある長期的な生成とより細かい制御を可能にします。さらに、彼らは生成されたモーション表現が、シームレスにループするビデオの作成、誘発されたモーションの編集、ユーザーが適用した力に対してオブジェクトがどのように反応するかをシミュレートするインタラクティブなダイナミックイメージなど、さまざまな下流応用に容易に使用できることを示しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「CMUの研究者たちは、スロット中心のモデル(Slot-TTA)を用いたテスト時の適応を提案していますこれは、シーンを共通してセグメント化し、再構築するスロット中心のボトルネックを備えた半教師付きモデルです」
- ペンシルバニア大学の研究者が、軽量で柔軟、モデルに依存しないオープンソースのAIフレームワーク「Kani」を導入し、言語モデルアプリケーションの構築を行います
- 「Google ResearchがMediaPipe FaceStylizerを紹介:少数のショットでの効率的な顔スタイリゼーションのための設計」
- 「韓国のAI研究がマギキャプチャを紹介:主題とスタイルの概念を統合して高解像度のポートレート画像を生成するための個人化手法」
- 「MITの学者たちは、生成型AIの社会的な影響を探るためのシードグラントを授与されました」
- 「タンパク質設計の次は何か?マイクロソフトの研究者がエボディフ:シーケンスファーストのタンパク質エンジニアリングのための画期的なAIフレームワークを紹介」
- このAI研究は、AstroLLaMAを紹介しますこれは、ArXivからの30万以上の天文学の要約を使用して、LLaMA-2からファインチューンされた7Bパラメーターモデルです






