Google Researchにおける責任あるAI 社会的善のためのAI
Google Research Responsible AI for Social Good
Google Research、AI for Social GoodのソフトウェアエンジニアであるJimmy TobinとKatrin Tomanekが投稿しました。
GoogleのAI for Social Goodチームは、研究者、エンジニア、ボランティア、その他のメンバーが、ポジティブな社会的インパクトに焦点を合わせたチームです。私たちの使命は、公衆衛生、アクセシビリティ、危機対応、気候とエネルギー、自然と社会の各分野で、現実世界での価値を実現することによって、AIの社会的な利益を示すことです。私たちは、未開発なコミュニティに対してポジティブな変化をもたらす最良の方法は、変化をもたらす人々やその組織と協力することだと信じています。
このブログ記事では、AI for Social Good内のチームであるProject Euphoniaが行った作業について説明します。このチームは、障害のある人々のための自動音声認識(ASR)の改善を目的としています。通常の発話を持つ人々にとって、ASRモデルの単語エラー率(WER)は10%未満になることがありますが、吃音、失語症、失行症などの障害のある人々の場合、エチオロジーと重症度に応じてWERは50%または90%に達することがあります。この問題に対処するために、私たちは1,000人以上の参加者と協力して、1,000時間以上の障害のある音声サンプルを収集し、個人化されたASRが障害のある人々のパフォーマンスギャップを埋めるための実現可能な道であることを示しました。私たちは、レイヤー凍結技術を使用して、3〜4分のトレーニング音声で個人化が成功することを示しました。
この作業は、個人化された音声モデルを必要とする人々にとって有益であるProject Relateの開発につながりました。GoogleのSpeechチームと共同で構築されたProject Relateは、典型的な音声の理解が難しい人々が自分自身のモデルをトレーニングできるようにするものです。人々はこれらの個人化されたモデルを使用して、より効果的にコミュニケーションを取り、より独立した生活を送ることができます。ASRをよりアクセス可能で使いやすくするために、デジタルアシスタント技術、ディクテーションアプリ、および会話で使用するために、GoogleのUniversal Speech Model(USM)を調整する方法について説明します。
- DeepMindの研究者たちは、任意のポイントを追跡するための新しいAIモデルであるTAPIRをオープンソース化しましたこのモデルは、ビデオシーケンス内のクエリポイントを効果的に追跡します
- バイデン政権は、チップ研究の取り組みにGoogleの議長を起用します
- トヨタのAIにより、電気自動車の設計がより迅速になりました
課題に対処する
Project Relateのユーザーと緊密に連携して作業を行うことで、個人化されたモデルは非常に有用であることが明らかになりましたが、多くのユーザーにとって、数十または数百の例を記録することは困難です。さらに、個人化されたモデルは、自由形式の会話では常にうまく機能しなかったこともわかりました。
これらの課題に対処するために、Euphoniaの研究努力は、追加のトレーニングが必要なく、障害のある人々にとってモデルが初めからうまく機能するようにするために、話者非依存ASR(SI-ASR)に焦点を合わせています。
SI-ASRのためのプロンプト音声データセット
堅牢なSI-ASRモデルを構築する最初のステップは、代表的なデータセットの分割を作成することでした。私たちは、Euphoniaコーパスをトレーニング、バリデーション、テストの部分に分割して、各分割が音声障害の重症度と基礎となるエチオロジーの範囲をカバーし、話者またはフレーズが複数の分割に表示されないようにしました。トレーニング部分には、障害のある1,000人以上のスピーカーから950k以上の音声発話が含まれています。テストセットには、350人以上のスピーカーから約5,700の発話が含まれています。言語病理学者が、テストセットのすべての発話を転写の正確さと音質の点で手動でレビューしました。
実際の会話のテストセット
プロンプト音声とは異なり、自発的または会話の音声にはいくつかの違いがあります。会話では、人々はより速く話し、はっきり発音しないことがあります。言葉を繰り返し、誤った言葉を修正し、自分自身や自分自身のコミュニティに固有のより広範な語彙を使用します。このユースケースのモデルを改善するために、私たちはパフォーマンスをベンチマークするために、実際の会話のテストセットを作成しました。
実際の会話のテストセットは、会話中に自分自身の話し方を録音した信頼できるテスターの協力を得て作成されました。音声はレビューされ、個人を特定できる情報(PII)は削除され、そのデータは言語病理学者によって転写されました。実際の会話のテストセットには、29人のスピーカーから1,500以上の発話が含まれています。
USMを障害のある音声に適応する
次に、Euphonia Prompted Speechセットのトレーニング分割でUSMを調整して、障害のある音声のパフォーマンスを向上させました。完全なモデルを微調整する代わりに、私たちの調整は残留アダプタに基づいています。これは、トランスフォーマーレイヤー間に調整可能なボトルネックレイヤーを残差として追加するパラメータ効率のチューニングアプローチです。これらのレイヤーのみが調整され、モデルの残りの重みは変更されません。以前に、このアプローチがASRモデルを障害のある音声に適応するのに非常にうまく機能することを示しました。残留アダプタはエンコーダーレイヤーにのみ追加され、ボトルネック次元は64に設定されました。
結果
適応されたUSMを評価するために、上記に説明した2つのテストセットを使用して、古いASRモデルと比較しました。各テストでは、適応されたUSMをそのタスクに最適な事前USMモデルと比較します。(1) 短い促された音声の場合、短いフォームのASRに最適化されたGoogleの製造ASRモデルと比較します。(2) 長い実際の会話音声の場合、長いフォームのASRにトレーニングされたモデルと比較します。USMの事前USMモデルに対する改善は、USMの相対的なサイズの増加、120Mから2Bのパラメータ、およびUSMブログポストで説明されているその他の改善によって説明できます。
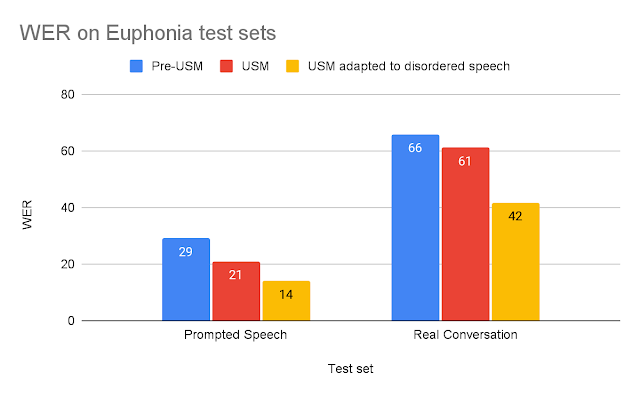 |
| 各テストセットのモデル単語誤り率(WER) (低い方が良い)。 |
USMを混乱した音声で適応することで、他のモデルを大幅に上回ることがわかりました。適応されたUSMのReal ConversationのWERは、事前USMモデルよりも37%優れており、Prompted Speechのテストセットでは、適応されたUSMは53%優れています。
これらの結果は、適応されたUSMが混乱した音声を持つエンドユーザーにとってより使いやすくなることを示唆しています。EuphoniaとProject Relateの信頼できるテスターのReal Conversationテストセットの録音の転写を見ることで、この改善を示すことができます(以下を参照)。
| 音声 1 | 正解 | 事前USM ASR | 適応されたUSM | |||
| 私は今、膝の上にXboxアダプティブコントローラーを持っています。 | 今、多くのコンサルタントが私の口にたくさんいる | 私は今、Xboxアダプターコントローラーを持っています。 | ||||
| 私はかなり長い間話しています。さて。 | かなり長い間話しています | 私はかなり長い間話しています。 |
| 信頼できるテスターのスピーチの例と転写(Real Conversationテストセット)。 |
事前USMと適応されたUSMの転写を比較すると、いくつかの主要な利点が明らかになります:
- 最初の例は、適応されたUSMが混乱した音声パターンを認識するのに優れていることを示しています。基準線は、聞き手が何を言おうとしているかを理解するために重要な「XBox」と「コントローラー」などの重要な単語を見落としています。
- 第2の例は、削除が混乱した音声でトレーニングされていないASRモデルの主要な問題であることを示す良い例です。基準モデルは一部正しく転写したが、発言の大部分は転写されず、話者の意図したメッセージが失われてしまいました。
結論
私たちは、この取り組みが、発話障害のある人々に音声認識をよりアクセスしやすくするための重要な一歩であると信じています。私たちはモデルの性能を向上させるために引き続き取り組んでいます。ASRの急速な進歩に伴い、発話障害のある人々が同様に恩恵を受けられるようにすることを目指しています。
謝辞
このプロジェクトの主な貢献者には、Fadi Biadsy、Michael Brenner、Julie Cattiau、Richard Cave、Amy Chung-Yu Chou、Dotan Emanuel、Jordan Green、Rus Heywood、Pan-Pan Jiang、Anton Kast、Marilyn Ladewig、Bob MacDonald、Philip Nelson、Katie Seaver、Joel Shor、Jimmy Tobin、Katrin Tomanek、およびSubhashini Venugopalanが含まれます。私たちは、Yu Zhang、Wei Han、Nanxin ChenなどのUSM研究チームのメンバーから受けたプロジェクトEuphoniaの支援に感謝しています。最も重要なのは、2,200人以上の参加者と多くの支援団体に感謝し、彼らと繋がることができたことです。
1 音量は聴きやすさのために調整されていますが、元のファイルは、一貫性のあるトレーニングに使用されるもので、一時停止、沈黙、可変ボリュームなどが含まれています。↩︎
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Covid-19の多様な変異株に対応する多目的ワクチンの作成
- マックス・プランク研究所の研究者たちは、MIME(3D人間モーションキャプチャを取得し、その動きに一致する可能性のある3Dシーンを生成する生成AIモデル)を提案しています
- UCサンディエゴとクアルコムの研究者たちは「Natural Program」を公開しましたそれは自然言語での厳密な推論チェーンの容易な検証にとって強力なツールであり、AIにおける大きな転換点となります
- 中国の研究者グループが開発したWebGLM:汎用言語モデル(GLM)に基づくWeb強化型質問応答システム
- SalesForceのAI研究者が、マスク不要のOVISを紹介:オープンボキャブラリーインスタンスセグメンテーションマスクジェネレータ
- 広大な化学空間で適切な遷移金属を採掘する
- 宇宙からの詳細な画像は、植物に対する干ばつの影響をより明確に示します






