Google DeepMindの研究者がSynJaxを紹介:JAX構造化確率分布のためのディープラーニングライブラリ
Google DeepMind研究者がSynJaxを紹介:JAXディープラーニングライブラリ


データは、その構成要素がどのように組み合わさって全体を形成するかを説明するさまざまな領域で構造を持っていると見なすことができます。活動によっては、この構造は通常潜在的であり、変化します。自然言語の異なる構造の例を図1に示します。単語は一連の単語で構成され、それぞれの単語には品詞タグが適用されます。これらのタグは相互に関連し、赤色の線状の連鎖を生成します。文の分割により、泡で示された文の単語は小さな不連続なクラスターに組み合わせることができます。言語のより詳細な調査では、グループを再帰的に作成し、構文木構造を作成することができます。構造は2つの言語を結びつけることもできます。
たとえば、同じ画像内のアライメントは、日本語の翻訳を英語のソースにリンクさせることができます。これらの文法的構造は普遍的です。生物学では、類似の構造が見つかることがあります。RNAのツリーベースのモデルは、タンパク質の折りたたみ過程の階層的な側面を捉えていますが、一方、単調なアライメントはRNA配列のヌクレオチドを一致させるために使用されます。ゲノムデータも連続したグループに分割されます。ほとんどの現在の深層学習モデルは、中間構造を明示的に表現しようとせず、入力から直接出力変数を予測しようとします。これらのモデルは、さまざまな方法で構造の明示的なモデリングから利益を得ることができます。適切な帰納バイアスを使用することで、改善された一般化が容易になります。これにより、サンプル効率性に加えて下流のパフォーマンスも向上します。

明示的な構造モデリングは、問題固有の制約や方法を組み込むことができます。離散的な構造のため、モデルが行った判断はより理解しやすくなります。最後に、構造が学習自体の結果である場合もあります。たとえば、データが特定の形状の隠れた構造によって説明されることを知っているが、それについてさらに詳しく知る必要がある場合があります。シーケンスのモデリングでは、自己回帰モデルが主流の技術です。一部の場合では、非順序の構造を線形化し、順序構造で近似することができます。これらのモデルは、独立した仮定に依存せず、多くのデータを使用してトレーニングすることができるため、強力です。最適な構造の特定や隠れた変数の周辺化は一般的な推論の問題ですが、自己回帰モデルからのサンプリングはしばしば扱いにくいです。
- 「AIモデルは強力ですが、生物学的に妥当でしょうか?」
- 「ジョンズ・ホプキンス大学の研究者たちは、がんに関連するタンパク質フラグメントを正確に予測することができる深層学習技術を開発しました」
- 「DeepMindの研究者たちは、AlphaStar Unpluggedを紹介しました:リアルタイムストラテジーゲームStarCraft IIの大規模なオフライン強化学習において、飛躍的な進歩を遂げました」
大規模モデルにおいて自己回帰モデルを使用することは、バイアスのあるまたは高分散の近似を要求するため、しばしば計算コストが高いです。対象構造と同じように因子グラフ上のモデルは、自己回帰モデルの代替手段です。これらのモデルは、専用の手法を使用することで興味深い推論問題を正確かつ効率的に計算することができます。各構造には固有の方法が必要ですが、各推論タスクには専用のアルゴリズム(argmax、サンプリング、周辺、エントロピーなど)は必要ありません。SynJaxでは、各構造タイプごとに1つの関数から複数の数値を抽出するために、自動微分を使用しています。
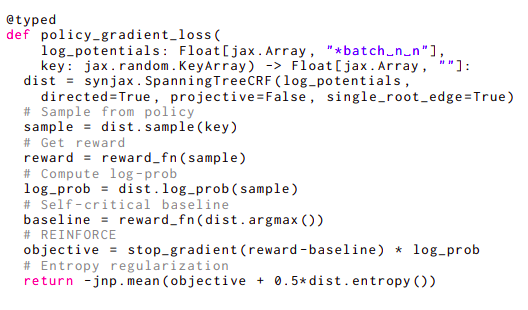
構造要素のアクセラレータに対応した実装を提供する実用的なライブラリが存在しないため、構造化分布の深い理解のための研究は遅れています。特に、これらのコンポーネントは、Transformerモデルとは異なり、利用可能な深層学習プリミティブに直接マッピングしないアルゴリズムに依存することが頻繁にあります。Google Deepmindの研究者は、JAX機械学習フレームワーク内で組み合わせるための簡単に使用できる構造プリミティブを提供し、SynJaxがこの課題を解決するのに役立っています。使用法を示すために、図2の例を考えてください。このコードでは、サンプリング、argmax、エントロピー、および対数確率を含むいくつかのパラメータを計算する必要があるポリシーグラディエント損失を実装しています。それぞれのパラメータを計算するには、別々のアプローチが必要です。
このコード行では、非射影的な有向全域木であり、単一のルートエッジ制約があります。その結果、SynJaxは単一ルートツリーに対してdist.sample() Wilsonのサンプリング手法、dist.entropy()、およびTarjanの最大全域木アルゴリズムを使用します。単一ルートエッジツリーでは、Matrix-Tree定理を使用することができます。SynJaxはそのようなアルゴリズムに関連するすべてのことを処理するため、ユーザーはそれらを実装することなく、またはそれらがどのように機能するかを理解することなく、自分の問題のモデリングに集中することができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「研究論文要約のための自律型デュアルチャットボットシステムの開発」
- XGen-Image-1の内部:Salesforce Researchが巨大なテキストから画像へのモデルを構築、トレーニング、評価する方法
- 「ケンブリッジの研究者たちは、機械学習システムに不確実性を組み込むことを開発しています」
- ボストン大学の研究者たちは、プラチプスファミリーと称されるファインチューニングされたLLMsを公開しました:ベースLLMsの安価で高速かつパワフルな改良を実現するために
- IBMの研究者が、深層学習推論のためのアナログAIチップを紹介:スケーラブルなミックスドシグナルアーキテクチャの重要な構成要素を披露
- アップルとブリティッシュコロンビア大学のAI研究者が提案する「FaceLit:ニューラル3D再点灯可能な顔のための革新的なAIフレームワーク」
- Salesforceの研究者は、XGen-Image-1を導入しました:複数の事前学習済みコンポーネントを再利用するために訓練されたテキストから画像への潜在的な拡散モデル