GoogleのSymbol Tuningは、LLM(Language Learning Models)におけるIn-Context Learningを行う新しいFine-Tuningテクニックです
GoogleのSymbol Tuningは、LLMにおけるIn-Context Learningを行うFine-Tuningテクニックです
新しいメソッドは、新しいファインチューニングの技術の基盤になる可能性があります。

私は最近、AIに焦点を当てた教育ニュースレターを始めました。すでに16万人以上の購読者がいます。TheSequenceは、5分で読めるML志向のニュースレターで、ハイプやニュースなどはありません。目的は、機械学習のプロジェクト、研究論文、コンセプトについて最新情報を提供することです。以下のリンクから購読して試してみてください:
TheSequence | Jesus Rodriguez | Substack
機械学習、人工知能、データの最新動向を追い続けるための最良の情報源です。
thesequence.substack.com
言語モデルのスケーリングにより、機械学習は革命的な進展を遂げ、文脈に基づいた学習を通じて難解な推論タスクを達成することが可能になりました。しかし、未解決の問題が残っています。言語モデルはプロンプトの変化に対して感度を示し、堅牢な推論の欠如を示唆しています。これらのモデルはしばしば、広範なプロンプトエンジニアリングや教示表現が必要であり、不正確なラベルにさらされてもタスクのパフォーマンスに変化がないという特異な動作を示すことさえあります。Googleの最新の研究では、人間の知能の基本的な特徴である、わずかな例で新しいタスクを推論学習する能力を明らかにしています。
Googleの画期的な論文「シンボルチューニングによる文脈学習の改善」では、シンボルチューニングという革新的なファインチューニング手法が紹介されています。この手法は、Flan-PaLMモデルの文脈学習におけるさまざまなシナリオでの大幅な改善をもたらす、入力-ラベルのマッピングを強調します。
- 「トップ12のコンピュータビジョンのGitHubリポジトリ」
- 「OpenAIとLangchainを使用した言語的なメール作成Webアプリケーション」
- 「Med-Flamingoに会ってください:医療分野向けのマルチモーダルな文脈学習を実行できるユニークな基盤モデル」

シンボルチューニング
Google Researchは「シンボルチューニング」という、従来の教示チューニング手法の制約に対処する効果的なファインチューニング手法を紹介しています。教示チューニングはモデルのパフォーマンスと文脈理解を向上させることができますが、その欠点もあります。なぜなら、タスクが指示や自然言語のラベルによって冗長に定義されているため、モデルは例から学ぶ必要がない場合があるからです。例えば、感情分析のタスクでは、モデルは提供された指示に依存し、例を無視することができます。
シンボルチューニングは、従来の方法では不十分な指示や自然言語のラベルがない未知の文脈学習タスクに特に有効であり、アルゴリズム的な推論タスクでも優れた能力を発揮します。
最も注目すべき成果は、文脈内で提示された反転ラベルの処理の大幅な改善です。この成果は、モデルが文脈情報を活用する優れた能力を示しており、既存の知識を超えています。
シンボルチューニングは、指示を持たず、自然言語のラベルを「Foo」「Bar」などの意味的に関連のないラベルで置き換えた例に基づいてモデルをファインチューニングすることで、問題を解決します。この設定では、文脈の例を参照しないとタスクが曖昧になります。これらの例に対する推論が成功のために重要になります。その結果、シンボルチューニングされたモデルは、文脈の例とラベルの間の微妙な推論を要求するタスクでのパフォーマンスが向上します。
シンボルチューニングの有効性を評価するために、研究者たちは分類型のタスクを持つ公開されている自然言語処理(NLP)データセット22種類を使用しました。ラベルは、3つのカテゴリ(整数、文字の組み合わせ、単語)に属する約30,000の任意のラベルの中からランダムに選ばれたものにリマップされました。

実験では、Flan-PaLMモデル(具体的にはFlan-PaLM-8B、Flan-PaLM-62B、Flan-PaLM-540B)に対してシンボルチューニングが行われました。また、Flan-cont-PaLM-62B(62B-cと略されます)もテストされ、通常の7800億トークンではなく約1.3兆トークンでFlan-PaLM-62Bを表します。
シンボル調整手法は、タスクを効果的に実行するためにモデルに文脈内の例との推論を行わせる必要があります。プロンプトは、関連するラベルや指示だけで学習するのを防ぐために設計されています。シンボル調整されたモデルは、文脈内の例とラベルの間で複雑な推論が要求される設定で優れたパフォーマンスを発揮します。これらの設定を探るために、入力とタスクのラベル間で必要な推論レベル(指示/関連するラベルの利用可能性に応じて)が異なる4つの文脈内学習シナリオが定義されました。
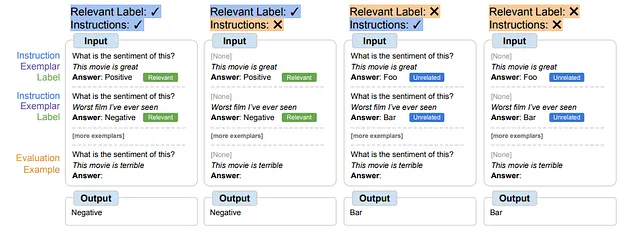
結果は、モデル62B以上で全ての設定でパフォーマンスが向上し、関連する自然言語ラベルがある設定ではわずかな改善が見られました(+0.8%から+4.2%まで)、そのようなラベルがない設定では大幅な改善が見られました(+5.5%から+15.5%まで)。特に関連するラベルが利用できない場合、シンボル調整されたFlan-PaLM-8BはFlan-PaLM-62Bを凌駕し、シンボル調整されたFlan-PaLM-62BはFlan-PaLM-540Bを上回りました。これは、シンボル調整が小さなモデルにこれらのタスクで大きなモデルのパフォーマンスに匹敵する能力を与えることを示しており、推論の計算要件を著しく削減する(計算を約10倍節約する)ことができます。

一般的に、シンボル調整は文脈内学習タスクで大きな改善が見られ、特に適切に指定されていないプロンプトに対して効果的です。この技術は、推論タスクにおいて従来のファインチューニングよりも優れたパフォーマンスを示し、コンテンツ情報を事前知識で上書きする能力もより高いです。全体的に、シンボル調整は最も興味深いファインチューニング技術の一つとなり得ます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 大規模な言語モデルを税理士として活用する:このAI論文は、税法の適用におけるLLMの能力を探求します
- ロラハブにお会いしましょう:新しいタスクにおいて適応性のあるパフォーマンスを達成するために、多様なタスクでトレーニングされたロラ(低ランク適応)モジュールを組み立てるための戦略的なAIフレームワーク
- 「プログラミング言語の構築方法:成功への(困難な)道のり」
- モジラのコモンボイスでの音声言語認識 — Part I.
- エッジエモーション認識:リアルタイム音声分析による人間と機械の相互作用の向上
- 「機械学習、ブロックチェーン技術はフェイクニュースの拡散に対抗するのに役立つかもしれません」
- 「SDXL 1.0の登場」





