「AIの画像をどのように保存すべきか?Googleの研究者がスコアベースの生成モデルを使用した画像圧縮方法を提案」
Googleの研究者がスコアベースの生成モデルを使い、AIの画像の保存方法を提案


1年前、AIによるリアルな画像生成は夢でした。ほとんどの出力が3つの目や2つの鼻などを持つものであるにもかかわらず、実際の顔に似た生成された顔を見ることに感動しました。しかし、拡散モデルのリリースにより、状況は非常に急速に変化しました。現在では、AIによって生成された画像と本物の画像を区別することが困難になりました。
高品質な画像を生成する能力は方程式の一部です。それらを適切に利用するためには、効率的に圧縮することが、コンテンツ生成、データ保存、伝送、および帯域幅の最適化などのタスクにおいて重要な役割を果たします。しかし、画像の圧縮は、変換符号化や量子化技術などの伝統的な手法に主に依存しており、生成モデルの探索は限定的でした。
画像生成の成功にもかかわらず、拡散モデルやスコアベースの生成モデルは、画像圧縮の主要な手法としてまだ台頭していません。彼らは、高解像度の画像に関しては、HiFiCなどのGANベースの手法に劣るか同等の結果を示すことが多いです。また、テキストから画像へのモデルを画像圧縮に再利用しようとする試みも、元の入力から逸脱した再構成や望ましくないアーティファクトを含む結果に終わっています。
- 研究者たちは、ビデオ記録を使用して、鳥の姿勢を3Dで追跡するための新しいマーカーレスAIメソッドを開発しました
- スタンフォード大学の研究者が、言語モデルの事前トレーニングのための拡張可能な二次最適化手法であるSophiaを紹介しました
- このPythonライブラリ「Imitation」は、PyTorchでの模倣と報酬学習アルゴリズムのオープンソース実装を提供します
画像生成のタスクにおけるスコアベースの生成モデルの性能と、画像圧縮の特定のタスクにおけるGANを上回ることができないというギャップは、興味深い疑問を提起し、さらなる調査を促しています。高品質な画像を生成できるモデルが、画像圧縮の特定のタスクでGANを上回ることができなかったことは驚きです。この相違点は、スコアベースの生成モデルを圧縮タスクに適用する際に、固有の課題と考慮事項が存在し、その全ポテンシャルを引き出すために専門のアプローチが必要であることを示唆しています。

したがって、スコアベースの生成モデルを画像圧縮に使用する可能性があることがわかりました。問題は、どのようにしてそれを実現するかということです。それでは、その答えに入ってみましょう。
Googleの研究者は、標準のオートエンコーダを使用し、平均二乗誤差(MSE)に最適化された拡散プロセスと組み合わせて、オートエンコーダによって破棄された微細なディテールを復元し追加する方法を提案しました。画像のエンコードのビットレートは、拡散プロセスでは追加のビットは必要としないため、オートエンコーダによってのみ決定されます。画像圧縮のために拡散モデルを特に微調整することで、画像の品質に関していくつかの最近の生成アプローチを凌駕することが示されています。

この方法は、拡散モデルと直接関連している2つのアプローチを探求しています。拡散モデルは、サンプリングステップの数が多いほど優れた性能を発揮しますが、サンプリングステップが少ない場合には、修正フローの方が優れたパフォーマンスを発揮します。
この2ステップのアプローチは、まずMSEに最適化されたオートエンコーダを使用して入力画像をエンコードし、その後、拡散プロセスまたは修正フローを適用して再構成のリアリズムを高めることで構成されています。拡散モデルは、テキストから画像へのモデルとは逆の方向にシフトされたノイズスケジュールを使用し、グローバルな構造よりも詳細を優先します。一方、修正フローモデルは、オートエンコーダから提供されるペアリングを利用して、オートエンコーダの出力を非圧縮画像に直接マッピングします。
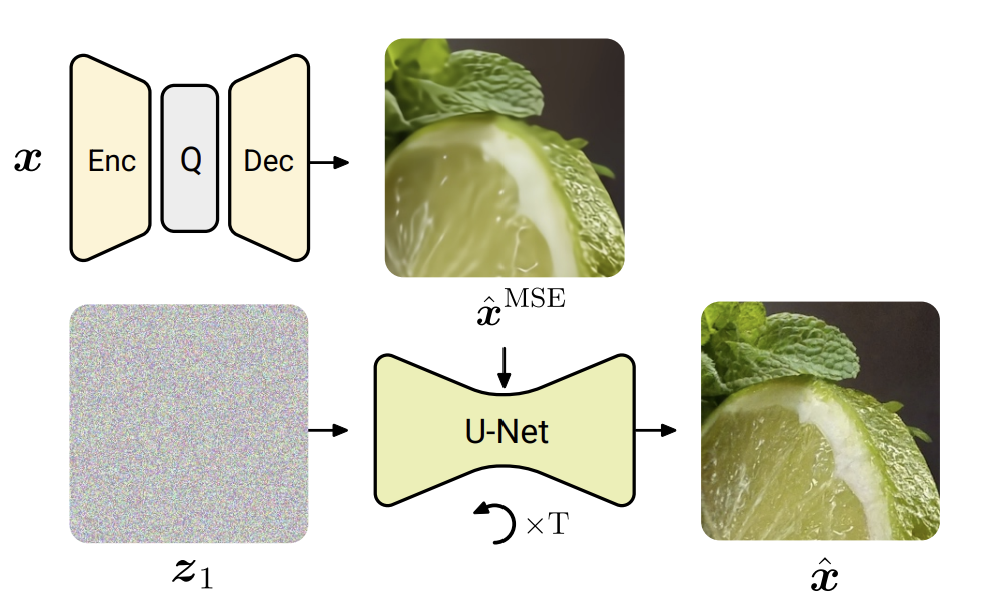
さらに、この研究では、この領域での将来の研究に役立つ具体的な詳細が明らかにされました。たとえば、ノイズスケジュールや画像生成時に注入されるノイズの量が結果に大きな影響を与えることが示されています。興味深いことに、高解像度の画像をトレーニングする際には、テキストから画像へのモデルはノイズレベルの増加によって利益を得る一方で、拡散プロセス全体のノイズを減らすことが圧縮に有利であることがわかっています。この調整により、モデルは細部により注力することができ、粗い詳細は既にオートエンコーダの再構築によって十分に捉えられています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「Ph.D.学生や研究者向けの無料オンラインコース10選」
- サムスンのAI研究者が、ニューラルヘアカットを紹介しましたこれは、ビデオや画像から人間の髪の毛のストランドベースのジオメトリを再構築するための新しいAI手法です
- 「サリー大学の研究者が開発した新しいソフトウェアは、AIが実際にどれだけの情報を知っているかを検証することができます」
- 新しいAIの研究は、事前学習済みおよび指示微調整モデルのゼロショットタスクの一般化性能を改善するために、コンテキスト内の指導学習(ICIL)がどのように機能するかを説明しています
- 「スタンフォード大学の新しいAI研究は、言語モデルにおける過信と不確実性の表現の役割を説明します」
- アリババAI研究所が提案する「Composer」は、数十億の(テキスト、画像)ペアで訓練された、巨大な(50億パラメータ)コントロール可能な拡散モデルです
- UCサンディエゴとMeta AIの研究者がMonoNeRFを紹介:カメラエンコーダとデプスエンコーダを通じて、ビデオをカメラ動作とデプスマップに分解するオートエンコーダアーキテクチャ





