GLIP オブジェクト検出への言語-画像事前学習の導入
GLIP オブジェクト検出への言語-画像事前学習の導入' can be condensed to 'GLIPの言語-画像事前学習の導入
論文サマリー:グラウンデッド言語・画像プリトレーニング
今日は、CLIPの言語・画像プリトレーニングの大きな成功を基にし、物体検出のタスクに拡張した論文であるGLIP(グラウンデッド言語・画像プリトレーニング)について掘り下げます。論文のキーコンセプトと結果を理解しやすくするために、画像と実験結果に注釈を付け、さらなる文脈を提供します。さあ、始めましょう!
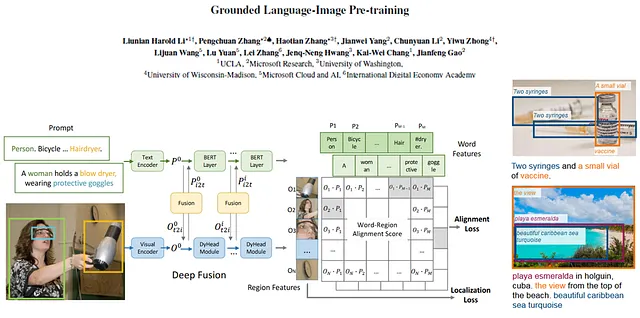
論文: グラウンデッド言語・画像プリトレーニング
コード: https://github.com/microsoft/GLIP
初出版: 2021年12月7日
著者: Liunian Harold Li、Pengchuan Zhang、Haotian Zhang、Jianwei Yang、Chunyuan Li、Yiwu Zhong、Lijuan Wang、Lu Yuan、Lei Zhang、Jenq-Neng Hwang、Kai-Wei Chang、Jianfeng Gao
カテゴリー: 表現学習、物体検出、フレーズグラウンディング、マルチモーダルディープラーニング、コンピュータビジョン、自然言語処理、基礎モデル
アウトライン
- 文脈と背景
- 主張された貢献
- 手法
- 実験
- さらなる資料とリソース
文脈と背景
GLIP(グラウンデッド言語・画像プリトレーニング)は、マルチモーダルな言語・画像モデルです。CLIP(コントラスティブ言語・画像プリトレーニング)と同様に、意味的に豊かな表現を学習し、モダリティ間でそれらを整列させるためにコントラスティブプリトレーニングを行います。CLIPがこれらの表現を画像レベルで学習するのに対して、GLIPはこのアプローチをオブジェクトレベルの表現に拡張し、1つの文が画像内の複数のオブジェクトに対応する可能性があるという意味で、フレーズグラウンディングと呼ばれるテキストプロンプトの単語と画像内のオブジェクトや領域との対応を特定するタスクに焦点を当てています。したがって、GLIPは以下を目指しています:
- 大規模プリトレーニングのためのフレーズグラウンディングと物体検出を統一する。
- 固定されたクラスの制約にとらわれない、ゼロショットの物体検出のための柔軟なフレームワークを提供する。
- ゼロショットまたはフューショットの方法で、さまざまなタスクとドメインにシームレスに適用できるプリトレーニングモデルを構築する。
このようなモデルで何ができるのでしょうか?テキストプロンプトを使用して、与えられた入力画像内のオブジェクトや関心領域を見つけることができます。そして最高のパートは、事前定義されたクラスに制約されないことです。

これらの検出結果をさらに処理することができます(例:追跡システムに入力するなど)、また、特定の興味のあるクラスのカスタムデータセットを作成し、それらを使用して独自の教師あり検出システムをトレーニングすることもできます。特定のレアなクラスや非常に具体的なクラスをカバーできるだけでなく、手動のラベル作成のための時間とお金を節約することもできます。後ほど見ていくように、GLIPの著者たちは、さらにパフォーマンスを向上させるためにティーチャー・スチューデントのフレームワークを導入するという似たようなアイデアを持っていました。
GLIPは、深層学習の多くの他のプロジェクトやドメインで採用されています。例えば、GLIGEN(グラウンデッド言語からの画像生成)は、GLIPを使用して潜在的な拡散モデルの画像生成を条件付けて、制御性を高めています。さらに、GLIPはDINO(ラベルなしのセルフディスティレーション)やSAM(セグメントアニシング)などの他の基礎モデルと組み合わせて、それぞれGroundingDINOとGrounded-Segment-Anythingとして使用されています。GLIPv2は、初期のGLIPモデルをビジョン言語理解と組み合わせて、フレーズグラウンディングを改善するだけでなく、ビジュアルクエスチョンアンサリングのタスクも可能にします。
主張された貢献
- 組み合わせたフレーズの接地と物体検出のための大規模な事前学習
- 物体検出とフレーズの接地に統一的な視点を提供する
- 高品質な言語認識画像表現を学習し、優れた転移学習のパフォーマンスを達成するための深い異なるモダリティの融合
- 浅く結合されたネットワーク(例:CLIP)ではなく、深いビジョン言語融合(例:GLIP)において、プロンプトチューニングがより効果的であることを示す
手法
GLIPでできることの概要を把握したら、論文の詳細を見てみましょう。
アーキテクチャの概要
高いレベルでは、GLIPのアーキテクチャはCLIPと非常に似ており、テキストエンコーダ、画像エンコーダ、およびテキストと画像の特徴の類似性に関する対比学習を含んでいます。GLIPのアーキテクチャは図2に示されています。
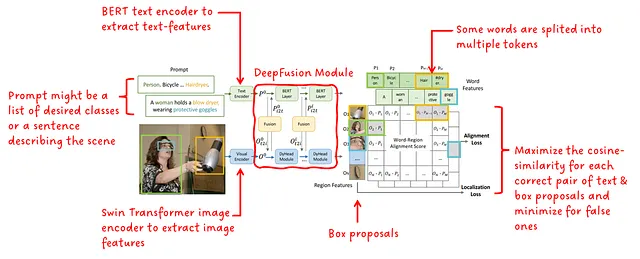
GLIPは、テキストエンコーダと画像エンコーダの後に、言語-画像認識を可能にする深い融合モジュールを追加します。このモジュールはクロスモーダルの注意を行い、さらなる特徴を抽出します。結果の領域特徴と単語特徴の間で余弦類似度が計算されます。トレーニング中、マッチングペアの類似度は最大化され、不正なペアの類似度は最小化されます。CLIPと異なり、マッチングペアは類似度行列の対角線上に位置するのではなく、通常は対角線外に位置します。
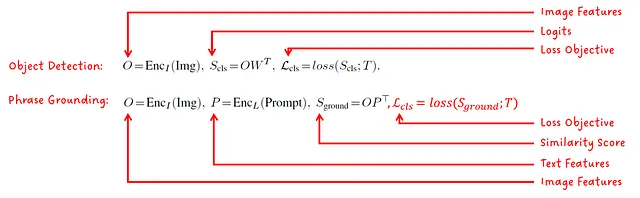
フレーズの接地を物体検出問題として定式化する
著者は、フレーズの接地(=画像内の単語とオブジェクト/領域の関連付け)の問題を物体検出目的として定式化できることに気付きました。標準の損失目的関数は次のようになります:

位置損失は予測された境界ボックスの品質に関係しており、形式によってはボックスのサイズと位置になる場合もあります。分類損失は統一化の鍵です。画像分類器のロジットではなく、テキスト-画像特徴の類似スコア上でロジットを計算することにより、同じ損失目的関数を使用してトレーニングすることができます。
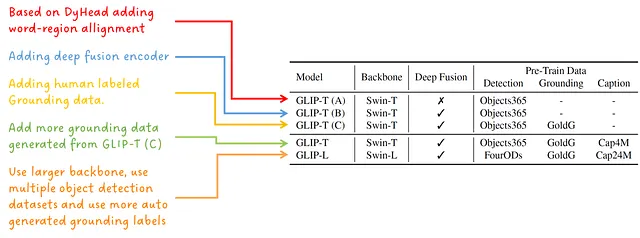
異なるモデルのバリアント
著者の設計選択肢とモデルスケールの効果を示すために、5つの異なるモデルがトレーニングされます:
教師-生徒の事前トレーニング
GLIPのパフォーマンスを向上させるために、著者は人間によって注釈付けされたデータであるGoldGを使用してGLIP-T(C)モデル(図3参照)をトレーニングし、インターネットのテキスト-画像ペアから接地データを生成します。このモデルを教師モデルと呼び、その後、教師モデルのトレーニングに使用されたデータと教師モデルが生成したデータを与えて、学生モデルをトレーニングします。図4を参照してください。
注意:教師と生徒という用語が使用されていますが、これは知識蒸留とは異なるプロセスであり、ここではより小さい生徒モデルがより大きな教師モデルの出力に一致するようにトレーニングされるプロセスではありません。

興味深いことに、実験で見るように、学生はゼロショットとフューショットの検出の両方のために、多くの(しかしすべてではない)データセットで教師を上回っています。なぜでしょうか?論文は仮説を立てています。教師が低い信頼度で予測を提供しても(それを「教養ある推測」と呼びます)、それは学生が消費する生成されたデータセットでの「教師信号」となります。
実験
GLIP論文では、さまざまな実験と削除研究が紹介されています。主に以下のことに関心を持っています:
- ゼロショットドメイン転送
- データ効率
- プロンプトエンジニアリング
結果とその提示方法についていくつかの疑問点がありますが、GLIPの成果を減じるつもりはなく、批判的な目で見るつもりです。
では、詳細に入ってみましょう!
ゼロショットドメイン転送
まず、ゼロショットドメイン転送の結果を見てみましょう。このタスクでは、事前訓練中に使用されたデータセット(COCOおよびLVIS)で事前訓練されたGLIPモデルが、別のデータセットでどれだけうまく機能するかを分析し、教師あり学習で訓練されたモデルと比較します。その後、事前訓練されたGLIPをさらに微調整して、テストデータセットで評価します。
図5では、COCOでのゼロショットドメイン転送の結果が表示されます。すべてのGLIPモデルが教師ありFaster RCNNよりも優れた0ショットの性能を持っていることがわかります。また、GLIP-Lが以前のSOTAを上回っていることも示されています。さらに、大きな学生モデルであるGLIP-Lが教師モデルであるGLIP-T(C)を上回っていることもわかります。
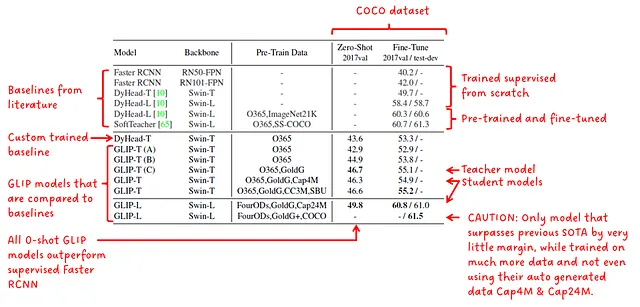
次に、これらの結果と論文で行われた主張を読む際に私が抱く疑問をリストアップします。論文では、GLIP-Lが最高の教師モデルSoftTeacherを上回っていると述べられています。
- ソフトティーチャーよりもメトリックが優れたモデルはGLIP-Lであり、0.2ポイント優れています。このわずかな差は、GLIPの新しいメソッドの結果ではなく、トレーニングのハイパーパラメータの違いによるものかもしれません。
- GLIP-Lは、彼らが良い解決策として紹介した教師モデルから生成されたデータ(Cap4MまたはCap24M)さえ使用していません。
- GLIP-Lは、SoftTeacherよりもはるかに大きなトレーニングデータのコーパスで訓練されています。
私の意見では、さまざまなGLIPモデルと彼ら自身で訓練したDyHead-Tを比較する結果は完全に正当であり、異なる制約下で異なる方法やモデルを比較する際に一般的な疑問を抱いているだけです。
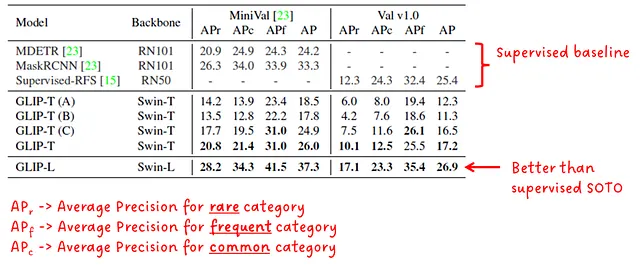
図6では、LVISデータセットでのゼロショットドメイン転送のパフォーマンスが表示されます。最も大きなGLIPモデルであるGLIP-Lが、他のすべての教師ありモデルを上回っていることがわかります。
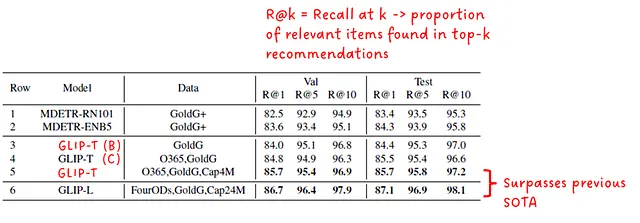
最後に、GLIPはFlickr30Kのエンティティに対するフレーズグラウンディングのパフォーマンスでMDETRと比較されています(図7を参照)。学生モデルであるGLIP-TとGLIP-Lの両方が、MDETRのベースラインを上回っています。
データ効率性
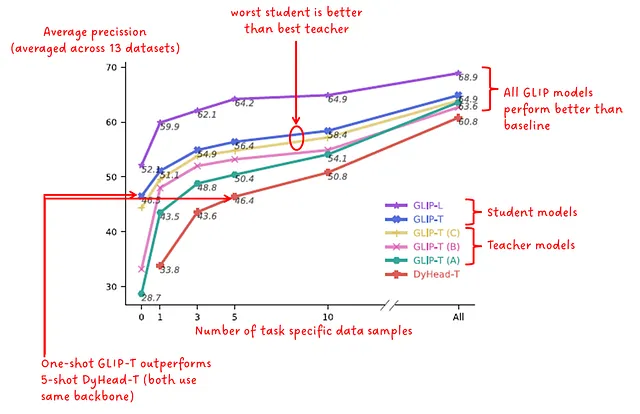
別の実験はデータ効率性に関連しています。この実験では、事前学習モデルを特定のタスク専用データの数に対して微調整すると、パフォーマンス(平均精度に基づく)がどのように変化するかを示すことを目的としています。図8では、モデルは13の異なるデータセットで評価され、そのパフォーマンスは13のデータセットを平均化した平均精度として報告されます。結果は0-shot、1-shot、3-shot、5-shot、10-shot、および「all」-shot(完全な微調整の公式用語ではないと思いますが、ポイントは理解できると思います 😅)について報告されます。
プロンプトエンジニアリング
CLIPと同様に、著者らはモデルのパフォーマンスと入力テキストプロンプトの形式との相関を報告しています。彼らは、事前学習モデルのパフォーマンスを改善するための2つの技術を提案しています(モデルの重みを再学習する必要はありません):
- 手動プロンプト調整
- プロンプト調整
手動プロンプト調整のアイデアは、追加の説明的な単語の形でさらなる文脈を提供することです。図9を参照してください:
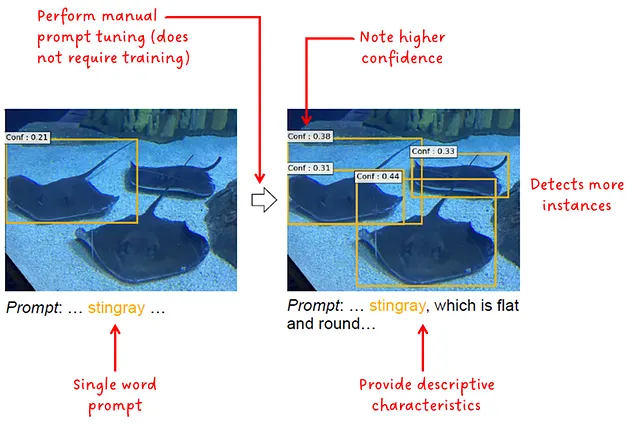
手動プロンプト調整は常にパフォーマンスを向上させるため、モデルが完全に微調整されているか、ゼロショットまたはフューショットシナリオで使用されているかは重要ではありません。
2つ目のアプローチであるプロンプト調整は、ダウンストリームタスクの正解ラベルへのアクセスが必要であり、各検出タスクに単一のプロンプト(例:「車を検出する」)があるシナリオに特に適しています。このプロンプトはまずテキストエンコーダを使用して特徴埋め込みに変換され、その後、画像エンコーダとディープフュージョンモジュールは固定され、入力埋め込みのみが正解ラベルを使用して最適化されます。最適化された埋め込みはモデルへの入力として使用され、テキストエンコーダは削除されることができます。
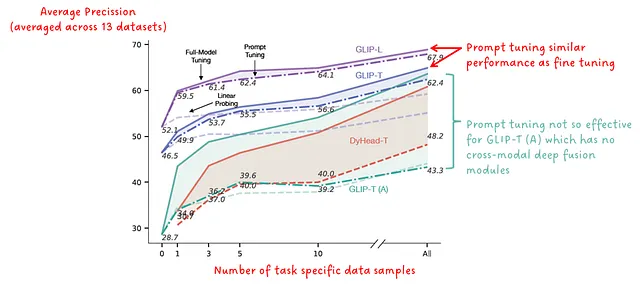
図10は、このプロンプト調整をさまざまなGLIPモデルに適用した結果を示しています。ディープフュージョンモジュールを持つモデルに適用すると、プロンプト調整はモデルの重みを微調整するのとほぼ同じパフォーマンスを実現します。
さらなる読み物とリソース
この記事の冒頭で述べたように、GLIPは多数のプロジェクトで広く採用されています。
GLIPに基づいた論文のリストは以下の通りです:
- GLIPv2: Unifying Localization and Vision-Language Understanding
- GLIGEN: Open-Set Grounded Text-to-Image Generation
- Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
GLIPやGLIPに基づいた他の興味深いプロジェクトの実装について詳しく知りたい場合は、以下のリポジトリのリストを参照してください:
- GLIPの公式実装
- GLIPを試すためのPythonノートブック
- GroundingDINO: GLIPとDINOの組み合わせ
- Grounded-Segment-Anything: GroundingDINOとSAMの組み合わせ
CLIP基礎モデルについての私の記事の一つも、この記事と同じ要約のアプローチを取っています:
CLIP基礎モデル
論文要約-自然言語指導からの転移可能なビジュアルモデルの学習
towardsdatascience.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






