GitHubトピックススクレイパー | PythonによるWebスクレイピング
GitHub Topics Scraper Web Scraping with Python.

Web スクレイピングは、ウェブサイトからデータを抽出するための技術です。これにより、ウェブページから情報を収集し、データ分析、研究、アプリケーションの構築など、さまざまな目的に使用できます。
本記事では、「GitHub Topics Scraper」と呼ばれる Python プロジェクトを紹介します。このプロジェクトは、Web スクレイピングを活用して GitHub トピックスページから情報を抽出し、各トピックのリポジトリ名と詳細を取得することができます。
はじめに
GitHub は、コードリポジトリをホスティングし、共同作業するための広く普及しているプラットフォームです。特定の主題やテーマに基づいてリポジトリを分類する「トピックス」という機能があります。GitHub Topics Scraper プロジェクトは、これらのトピックをスクレイピングし、関連するリポジトリ情報を取得するプロセスを自動化します。
プロジェクト概要
GitHub Topics Scraper は、Python を使用して実装され、以下のライブラリを利用しています:
requests: ウェブページの HTML コンテンツを取得するために使用されます。BeautifulSoup: HTML を解析し、データを抽出するための強力なライブラリです。pandas: スクレイピングしたデータを構造化された形式に整理するために使用される、汎用性の高いライブラリです。
コードに入り、プロジェクトの各コンポーネントがどのように機能するかを理解しましょう。
Python スクリプト
import requestsfrom bs4 import BeautifulSoupimport pandas as pd上記のコードスニペットは、requests、BeautifulSoup、pandas の 3 つのライブラリをインポートしています。
def topic_page_authentication(url): topics_url = url response = requests.get(topics_url) page_content = response.text doc = BeautifulSoup(page_content, 'html.parser') return docURL を引数として受け取る topic_page_authentication という関数が定義されています。
以下は、コードの詳細です。
1. topics_url = url : この行は、提供された URL を topics_url 変数に割り当てます。この URL は、認証してコンテンツを取得したいウェブページを表します。
2. response = requests.get(topics_url) : この行は、requests.get() 関数を使用して HTTP GET リクエストを topics_url に送信し、レスポンスを response 変数に格納します。このリクエストは、ウェブページの HTML コンテンツを取得するために使用されます。
3. page_content = response.text : この行は、レスポンスオブジェクトから HTML コンテンツを抽出し、page_content 変数に割り当てます。 response.text 属性は、レスポンスのテキストコンテンツを取得します。
- 4.
doc = BeautifulSoup(page_content, 'html.parser') - この行は、「html.parser」をパーサーとして使用して
page_contentを解析し、BeautifulSoup オブジェクト called を作成します。これにより、ウェブページの HTML 構造をナビゲートして情報を抽出することができます。
5. return doc : この行は、関数から BeautifulSoup オブジェクト doc を返します。つまり、topic_page_authentication 関数が呼び出されると、解析された HTML コンテンツが BeautifulSoup オブジェクトとして返されます。
この関数の目的は、提供された URL で指定されたウェブページの認証と HTML コンテンツの取得です。 requests ライブラリを使用して HTTP GET リクエストを送信し、レスポンスコンテンツを取得し、その後 BeautifulSoup を使用してナビゲート可能なオブジェクトを作成して HTML 構造を表します。
ただし、提供されたコードスニペットは、ウェブページの認証と解析の初期ステップを処理しますが、具体的なスクレイピングやデータ抽出のタスクは実行しません。
def topicSraper(doc): # Extract title title_class = 'f3 lh-condensed mb-0 mt-1 Link--primary' topic_title_tags = doc.find_all('p', {'class':title_class}) # Extract description description_class = 'f5 color-fg-muted mb-0 mt-1' topic_desc_tags = doc.find_all('p', {'class':description_class}) # Extract link link_class = 'no-underline flex-1 d-flex flex-column' topic_link_tags = doc.find_all('a',{'class':link_class}) #Extract all the topic names topic_titles = [] for tag in topic_title_tags: topic_titles.append(tag.text) #Extract the descrition text of the particular topic topic_description = [] for tag in topic_desc_tags: topic_description.append(tag.text.strip()) #Extract the urls of the particular topics topic_urls = [] base_url = "https://github.com" for tags in topic_link_tags: topic_urls.append(base_url + tags['href']) topics_dict = { 'Title':topic_titles, 'Description':topic_description, 'URL':topic_urls } topics_df = pd.DataFrame(topics_dict) return topics_dftopicScraperという関数を定義し、引数としてBeautifulSoupオブジェクト(doc)を取ります。

このコードが行うことの詳細は以下の通りです:
1. title_class = 'f3 lh-condensed mb-0 mt-1 Link--primary':この行は、Webページ上のトピックタイトルを含むHTML要素のCSSクラス名(title_class)を定義します。
2. topic_title_tags = doc.find_all('p', {'class':title_class}):この行は、BeautifulSoupオブジェクトのfind_all()メソッドを使用して、指定されたCSSクラス(title_class)を持つすべてのHTML要素(<p>)を検索します。トピックタイトルタグを表すBeautifulSoup Tagオブジェクトのリストを取得します。
3. description_class = 'f5 color-fg-muted mb-0 mt-1':この行は、Webページ上のトピックの説明を含むHTML要素のCSSクラス名(description_class)を定義します。
4. topic_desc_tags = doc.find_all('p', {'class':description_class}):この行は、find_all()メソッドを使用して、指定されたCSSクラス(description_class)を持つすべてのHTML要素(<p>)を検索します。トピック説明タグを表すBeautifulSoup Tagオブジェクトのリストを取得します。
5. link_class = 'no-underline flex-1 d-flex flex-column':この行は、Webページ上のトピックリンクを含むHTML要素のCSSクラス名(link_class)を定義します。
6. topic_link_tags = doc.find_all('a',{'class':link_class}):この行は、find_all()メソッドを使用して、指定されたCSSクラス(link_class)を持つすべてのHTML要素(<a>)を検索します。トピックリンクタグを表すBeautifulSoup Tagオブジェクトのリストを取得します。
7. topic_titles = []:この行は、抽出したトピックタイトルを格納するための空のリストを初期化します。
8. for tag in topic_title_tags: ...:このループはtopic_title_tagsリストを反復処理し、各タグのテキストコンテンツをtopic_titlesリストに追加します。
9. topic_description = []:この行は、抽出したトピック説明を格納するための空のリストを初期化します。
10. for tag in topic_desc_tags: ...:このループはtopic_desc_tagsリストを反復処理し、各タグのテキストコンテンツをtopic_descriptionリストに追加します。
11. topic_urls = []:この行は、抽出されたトピックURLを格納するための空のリストを初期化します。
12. base_url = "https://github.com":この行は、WebサイトのベースURLを定義します。
13. for tags in topic_link_tags: ...:このループはtopic_link_tagsリストを反復処理し、各タグの連結されたURL(ベースURL + href属性)をtopic_urlsリストに追加します。
14. topics_dict = {...}:このブロックは、抽出されたデータ(トピックタイトル、説明、URL)を含む辞書(topics_dict)を作成します。
15. topics_df = pd.DataFrame(topics_dict):この行は、topics_dict辞書をpandas DataFrameに変換します。各キーがDataFrameの列になります。
16. return topics_df:この行は、抽出されたデータを含むpandas DataFrameを返します。
この関数の目的は、提供されたBeautifulSoupオブジェクト(doc)から情報をスクレイプして抽出することです。特定のHTML要素からトピックのタイトル、説明、URLを取得し、pandasデータフレームに格納して、さらなる分析や処理に使用します。
def topic_url_extractor(dataframe): url_lst = [] for i in range(len(dataframe)): topic_url = dataframe['URL'][i] url_lst.append(topic_url) return url_lst引数としてpandasデータフレーム(dataframe)を取るtopic_url_extractorという関数を定義します。
このコードの詳細は以下の通りです。
1. url_lst = []:この行は、抽出されたURLを格納する空のリスト(url_lst)を初期化します。
2. for i in range(len(dataframe)): ...:このループは、データフレームの行のインデックスを繰り返します。
3. topic_url = dataframe['URL'][i]:この行は、データフレーム内の現在の行インデックス(i)の ‘URL’列の値を取得します。
4. url_lst.append(topic_url):この行は、取得されたURLをurl_lstリストに追加します。
5. return url_lst:この行は、抽出されたURLを含むurl_lstリストを返します。
この関数の目的は、提供されたデータフレームの ‘URL’列からURLを抽出することです。
データフレームの各行を繰り返し、各行のURL値を取得し、リストに追加します。最後に、関数は抽出されたURLのリストを返します。
この関数は、DataFrameからURLを抽出して、各URLを訪問したり、個々のWebページで追加のWebスクレイピングを実行したりするなど、さらなる処理や分析に使用する場合に役立ちます。
def parse_star_count(stars_str): stars_str = stars_str.strip()[6:] if stars_str[-1] == 'k': stars_str = float(stars_str[:-1]) * 1000 return int(stars_str)引数として文字列(stars_str)を取るparse_star_countという関数を定義します。
このコードの詳細は以下の通りです。
1. stars_str = stars_str.strip()[6:]:この行は、strip()メソッドを使用してstars_str文字列の前後の空白を削除します。次に、6番目の文字から文字列をスライスし、結果をstars_strに再割り当てします。この行の目的は、文字列から不要な文字やスペースを削除することです。
2. if stars_str[-1] == 'k': ...:この行は、stars_strの最後の文字が ‘k’である場合、スター数が千であることを示します。
3. stars_str = float(stars_str[:-1]) * 1000:この行は、文字列の数値部分( ‘k’を除く)を浮動小数点数に変換し、1000を乗算して実際のスター数に変換します。
4. return int(stars_str):この行は、stars_strを整数に変換して返します。
この関数の目的は、文字列表現からスターカウントを解析して整数値に変換することです。スターカウントが千である場合( ‘k’を含む場合)に対処することができます。関数は解析されたスターカウントを整数値として返します。
この関数は、 ‘1.2k’のような文字列で表されるスターカウントを数値化して、さらなる分析や処理のために数値に変換する必要がある場合に役立ちます。
def get_repo_info(h3_tags, star_tag): base_url = 'https://github.com' a_tags = h3_tags.find_all('a') username = a_tags[0].text.strip() repo_name = a_tags[1].text.strip() repo_url = base_url + a_tags[1]['href'] stars = parse_star_count(star_tag.text.strip()) return username, repo_name, stars, repo_urlget_repo_info 関数を定義します。この関数は、h3_tags と star_tag の 2 つの引数を取ります。
このコードが行うことを以下に示します:
1. base_url = 'https://github.com' : この行は、GitHub ウェブサイトのベース URL を定義します。
2. a_tags = h3_tags.find_all('a') : この行は、h3_tags オブジェクトの find_all() メソッドを使用して、その中にあるすべての HTML 要素 (<a>) を検索します。これにより、アンカータグを表す BeautifulSoup Tag オブジェクトのリストが取得されます。
3. username = a_tags[0].text.strip() : この行は、最初のアンカータグ (a_tags[0]) のテキストコンテンツを抽出し、username 変数に割り当てます。また、strip() メソッドを使用して、先頭および末尾の空白を削除します。
4. repo_name = a_tags[1].text.strip() : この行は、2 番目のアンカータグ (a_tags[1]) のテキストコンテンツを抽出し、repo_name 変数に割り当てます。また、strip() メソッドを使用して、先頭および末尾の空白を削除します。
5. repo_url = base_url + a_tags[1]['href'] : この行は、2 番目のアンカータグ (a_tags[1]) から ‘href’ 属性の値を取得し、それを base_url と連結してリポジトリの完全な URL を形成します。結果の URL は repo_url 変数に割り当てられます。
- 6.
stars = parse_star_count(star_tag.text.strip()) - この行は、
star_tagオブジェクトのテキストコンテンツを抽出し、先頭および末尾の空白を削除してparse_star_count関数の引数として渡します。関数は解析されたスター数を整数で返し、stars変数に割り当てられます。
7. return username, repo_name, stars, repo_url : この行は、抽出された情報を含むタプルを返します: username、repo_name、stars、および repo_url。
この関数の目的は、提供された h3_tags と star_tag オブジェクトから GitHub リポジトリに関する情報を抽出することです。HTML 構造から特定の要素をナビゲートして抽出することで、ユーザ名、リポジトリ名、スター数、およびリポジトリ URL を取得します。関数は、この情報をタプルとして返します。
この関数は、GitHub トピックをスクレイピングする場合など、リポジトリの一覧が含まれる Web ページからリポジトリ情報を抽出する際に役立ちます。
def topic_information_scraper(topic_url): # ページの認証 topic_doc = topic_page_authentication(topic_url) # 名前を抽出 h3_class = 'f3 color-fg-muted text-normal lh-condensed' repo_tags = topic_doc.find_all('h3', {'class':h3_class}) # スタータグを取得 star_class = 'tooltipped tooltipped-s btn-sm btn BtnGroup-item color-bg-default' star_tags = topic_doc.find_all('a',{'class':star_class}) # トピックに関する情報を取得する topic_repos_dict = { 'username': [], 'repo_name': [], 'stars': [], 'repo_url': [] } for i in range(len(repo_tags)): repo_info = get_repo_info(repo_tags[i], star_tags[i]) topic_repos_dict['username'].append(repo_info[0]) topic_repos_dict['repo_name'].append(repo_info[1]) topic_repos_dict['stars'].append(repo_info[2]) topic_repos_dict['repo_url'].append(repo_info[3]) return pd.DataFrame(topic_repos_dict)topic_information_scraper 関数を定義します。この関数は、topic_url を引数として取ります。
このコードが行うことを以下に示します:
- 1.
topic_doc = topic_page_authentication(topic_url) - この行は、
topic_urlの HTML コンテンツを認証して取得するためにtopic_page_authentication関数を呼び出します。解析された HTML コンテンツはtopic_doc変数に割り当てられます。
2. h3_class = 'f3 color-fg-muted text-normal lh-condensed' : この行は、トピックページ内にあるリポジトリ名を含むHTML要素のCSSクラス名(h3_class)を定義します。
3. repo_tags = topic_doc.find_all('h3', {'class':h3_class}) : この行は、topic_docオブジェクトのfind_all()メソッドを使用して、指定されたCSSクラス(h3_class)を持つすべてのHTML要素(<h3>)を検索します。リポジトリ名のタグを表すBeautifulSoup Tagオブジェクトのリストを取得します。
4. star_class = 'tooltipped tooltipped-s btn-sm btn BtnGroup-item color-bg-default' : この行は、トピックページ内にあるスター数を含むHTML要素のCSSクラス名(star_class)を定義します。
5. star_tags = topic_doc.find_all('a',{'class':star_class}) : この行は、find_all()メソッドを使用して、指定されたCSSクラス(star_class)を持つすべてのHTML要素(<a>)を検索します。スター数を表すBeautifulSoup Tagオブジェクトのリストを取得します。
6. topic_repos_dict = {...} : このブロックは、抽出されたリポジトリ情報:ユーザー名、リポジトリ名、スター数、リポジトリURLを格納する辞書(topic_repos_dict)を作成します。
7. for i in range(len(repo_tags)): ... : このループは、repo_tagsリストのインデックスを繰り返し処理し、star_tagsリストと同じ長さであると仮定します。
8. repo_info = get_repo_info(repo_tags[i], star_tags[i]) : この行は、特定のリポジトリに関する情報を抽出するためにget_repo_info関数を呼び出します。現在のリポジトリ名のタグ(repo_tags[i])とスター数のタグ(star_tags[i])を引数に渡します。返された情報は、repo_info変数に割り当てられます。
9. topic_repos_dict['username'].append(repo_info[0]) : この行は、repo_infoから抽出されたユーザー名をtopic_repos_dictの’username’リストに追加します。
10. topic_repos_dict['repo_name'].append(repo_info[1]) : この行は、repo_infoから抽出されたリポジトリ名をtopic_repos_dictの’repo_name’リストに追加します。
- 11.
topic_repos_dict['stars'].append(repo_info[2]) - この行は、
repo_infoから抽出されたスター数をtopic_repos_dictの’stars’リストに追加します。
12. topic_repos_dict['repo_url'].append(repo_info[3]) : この行は、repo_infoから抽出されたリポジトリURLをtopic_repos_dictの’repo_url’リストに追加します。
13. return pd.DataFrame(topic_repos_dict) : この行は、topic_repos_dict辞書をpandas DataFrameに変換し、各キーがDataFrameの列になるようにします。生成されたデータフレームには、抽出されたリポジトリ情報が含まれます。
この関数の目的は、GitHubの特定のトピック内のリポジトリに関する情報をスクレイピングして抽出することです。トピックページのHTMLコンテンツを認証して取得し、特定のCSSクラス名を使用してリポジトリ名とスター数を抽出します。
それぞれのリポジトリについてget_repo_info関数を呼び出して、ユーザー名、リポジトリ名、スター数、リポジトリURLを取得します。
抽出された情報は辞書に格納され、その後pandas DataFrameに変換され、関数によって返されます。
if __name__ == "__main__": url = 'https://github.com/topics' topic_dataframe = topicSraper(topic_page_authentication(url)) topic_dataframe.to_csv('GitHubtopics.csv', index=None) # Make Other CSV files acording to the topics url = topic_url_extractor(topic_dataframe) name = topic_dataframe['Title'] for i in range(len(topic_dataframe)): new_df = topic_information_scraper(url[i]) new_df.to_csv(f'GitHubTopic_CSV-Files/{name[i]}.csv', index=None)このコードスニペットは、スクリプトのメイン実行フローを示しています。
ここでは、コードが何を行っているかの詳細を示します。
1. if __name__ == "__main__": :この条件文は、スクリプトが直接実行されているかどうか(モジュールとしてインポートされていないかどうか)を確認します。
2. url = 'https://github.com/topics' :この行は、GitHubのトピックページのURLを定義します。
3. topic_dataframe = topicSraper(topic_page_authentication(url)) :この行は、topic_page_authenticationを使用してトピックページのHTMLコンテンツを取得し、解析されたHTML(doc)をtopicSraper関数に渡します。結果のデータフレーム(topic_dataframe)を変数に割り当てます。
4. topic_dataframe.to_csv('GitHubtopics.csv', index=None) :この行は、topic_dataframeデータフレームをCSVファイル「GitHubtopics.csv」にエクスポートします。index=None引数により、行インデックスがCSVファイルに含まれないようにします。
5. url = topic_url_extractor(topic_dataframe) :この行は、topic_dataframeを引数としてtopic_url_extractor関数を呼び出します。データフレームから抽出されたURLのリスト(url)を取得します。
6. name = topic_dataframe['Title'] :この行は、topic_dataframeから「タイトル」列を取得し、name変数に割り当てます。
7. for i in range(len(topic_dataframe)): ... :このループは、topic_dataframeデータフレームのインデックスを反復処理します。
8. new_df = topic_information_scraper(url[i]) :この行は、URL(url[i])を引数としてtopic_information_scraper関数を呼び出します。特定のトピックURLのリポジトリ情報を取得し、new_dfデータフレームに割り当てます。
9. new_df.to_csv(f'GitHubTopic_CSV-Files/{name[i]}.csv', index=None) :この行は、new_dfデータフレームをCSVファイルにエクスポートします。ファイル名はf-stringを使用して動的に生成され、トピック名(name[i])を組み込んでいます。index=None引数により、行インデックスがCSVファイルに含まれないようにします。
このスクリプトの目的は、GitHubのトピックページから情報をスクレイピングして抽出し、抽出したデータを含むCSVファイルを作成することです。最初にメイントピックページをスクレイピングし、「GitHubtopics.csv」に抽出した情報を保存し、その後、抽出したURLを使用して個々のトピックページをスクレイピングします。
各トピックについて、トピック名に基づいた新しいCSVファイルを作成し、リポジトリ情報を保存します。
このスクリプトを直接実行すると、スクレイピングが実行され、必要なCSVファイルが生成されます。
最終出力
url = 'https://github.com/topics'topic_dataframe = topicSraper(topic_page_authentication(url))topic_dataframe.to_csv('GitHubtopics.csv', index=None)このコードが実行されると、’GitHubtopics.csv’という名前のCSVファイルが生成され、以下のようになります。csvには、すべてのトピック名、その説明、およびURLが含まれています。

url = topic_url_extractor(topic_dataframe) name = topic_dataframe['Title']for i in range(len(topic_dataframe)): new_df = topic_information_scraper(url[i]) new_df.to_csv(f'GitHubTopic_CSV-Files/{name[i]}.csv', index=None)次に、このコードが実行され、以前に保存した「GitHubtopics.csv」ファイルに基づいて特定のcsvファイルが作成されます。その後、それらのCSVファイルは、それぞれの固有のトピック名で「GitHubTopic_CSV-Files」というディレクトリに保存されます。これらのcsvファイルは次のようになります。
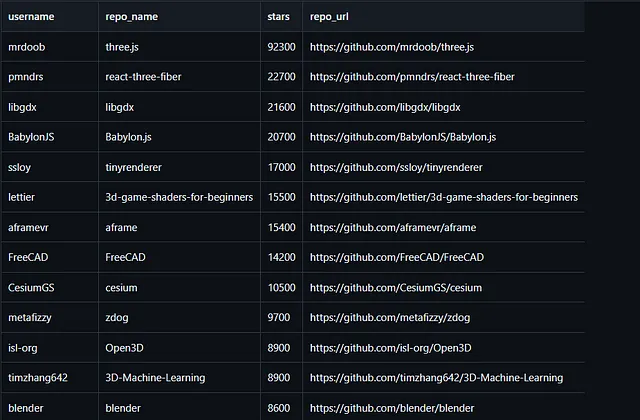
これらのトピックのcsvファイルには、ユーザー名、リポジトリ名、リポジトリのスター、リポジトリのURLなど、トピックに関する情報が格納されています。
注:ウェブサイトのタグは変更される可能性があるため、このPythonスクリプトを実行する前に、ウェブサイトのタグを確認してください。
完全なスクリプトのアクセス >> https://github.com/PrajjwalSule21/GitHub-Topic-Scraper/blob/main/RepoScraper.py

We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






