これをデジタルパペットにしてください:GenMMは、単一の例を使用して動きを合成できるAIモデルです
GenMM is an AI model that can synthesize movements using a single example. Please make this into a digital puppet.


コンピュータ生成のアニメーションは、毎日より現実的になっています。この進歩は、ビデオゲームで最もよく見ることができます。トゥームレイダーシリーズの最初のララ・クロフトと最新のララ・クロフトを考えてみてください。私たちは、230ポリゴンのパペットがおかしな動きをするのから、スクリーン上でスムーズに動くリアルなキャラクターに移行しました。
コンピュータアニメーションで自然で多様な動きを生成することは、長年にわたって難しい問題でした。モーションキャプチャシステムや手動アニメーション作成などの従来の方法は、高価で時間がかかり、スタイル、骨格構造、モデルタイプに多様性が欠けた動きのデータセットに結果をもたらします。アニメーション生成のこの手動で時間がかかる性質は、業界に自動化された解決策が必要とされています。
既存のデータ駆動型のモーション合成手法は、その効果が限定的です。しかし、近年、ディープラーニングがコンピュータアニメーションにおいて多様で現実的な動きを生成することができる強力な技術として登場しました。大規模かつ包括的なデータセットでトレーニングされた場合、多様で現実的な動きを合成できます。
- LLMの巨人たちの戦い:Google PaLM 2 vs OpenAI GPT-3.5
- Video-ControlNetを紹介します:コントロール可能なビデオ生成の未来を形作る革新的なテキストからビデオへの拡散モデル
- グラフの復活:グラフの年ニュースレター2023年春
ディープラーニング手法は、モーション合成において印象的な結果を示していますが、実用的な適用性が制限される欠点があります。まず、長時間のトレーニングが必要であり、アニメーションの製作パイプラインにおいて大きなボトルネックとなる可能性があります。さらに、ジッタリングや過度なスムージングなどの視覚的なアーティファクトが生じるため、合成された動きの品質に影響を与えます。最後に、複雑な骨格構造にスケーリングするのが困難であるため、複雑な動きが必要なシナリオで使用が制限されます。
私たちは、実用的なシナリオで適用できる信頼性のあるモーション合成手法が需要があると知っています。しかし、これらの問題を克服することは容易ではありません。では、解決策は何でしょうか?それでは、GenMMに出会う時間です。
GenMM は、モーション最近傍とモーションマッチングの古典的なアイデアに基づく代替アプローチです。キャラクターアニメーションに広く使用されるモーションマッチングを利用し、自然に見え、さまざまなローカルコンテキストに適応した高品質のアニメーションを生成します。
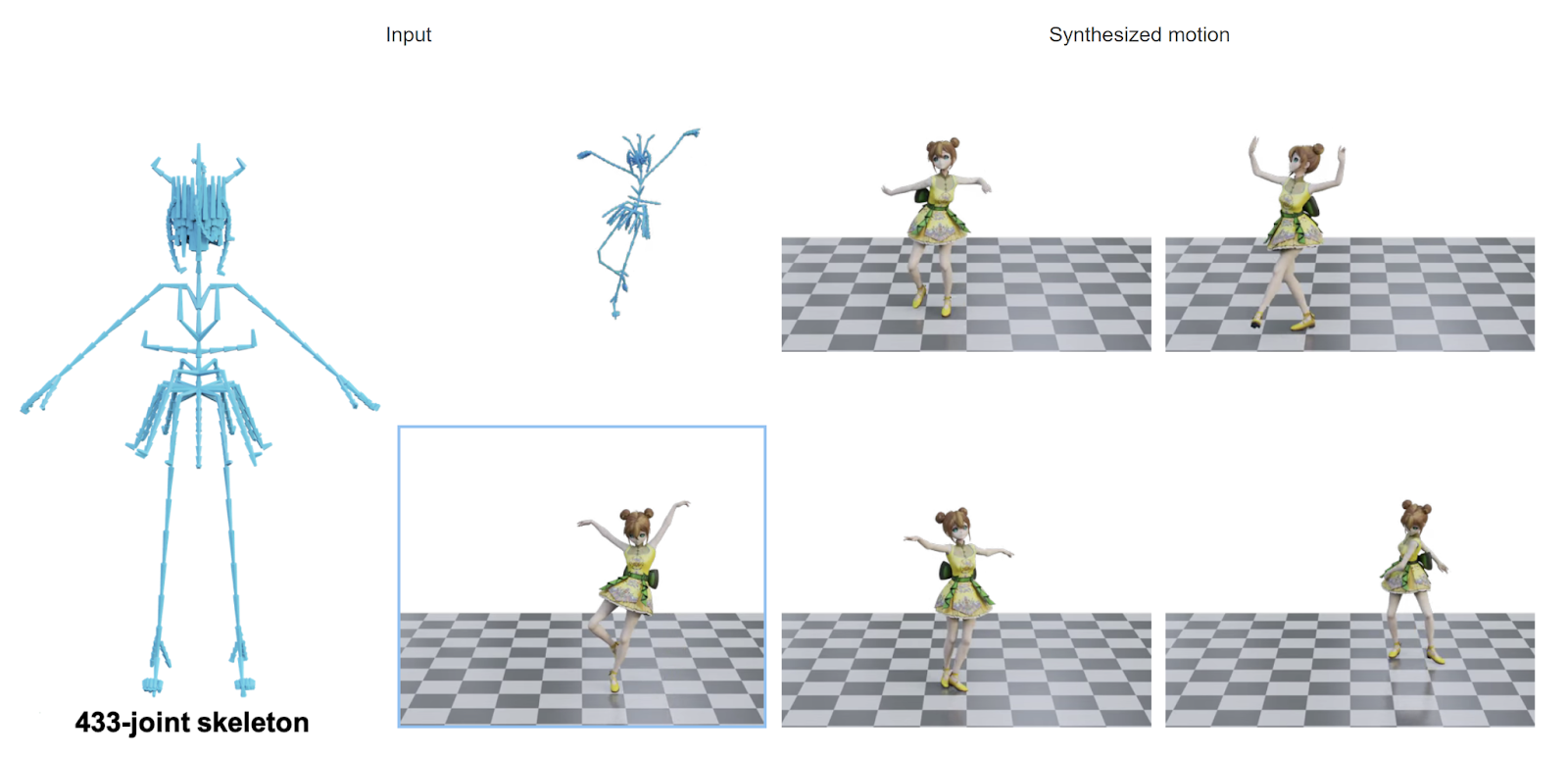
GenMM は、単一または少数の例のシーケンスから多様な動きを抽出できる生成モデルです。これは、自然な動き空間全体の近似として広範なモーションキャプチャデータベースを活用することによって達成されます。
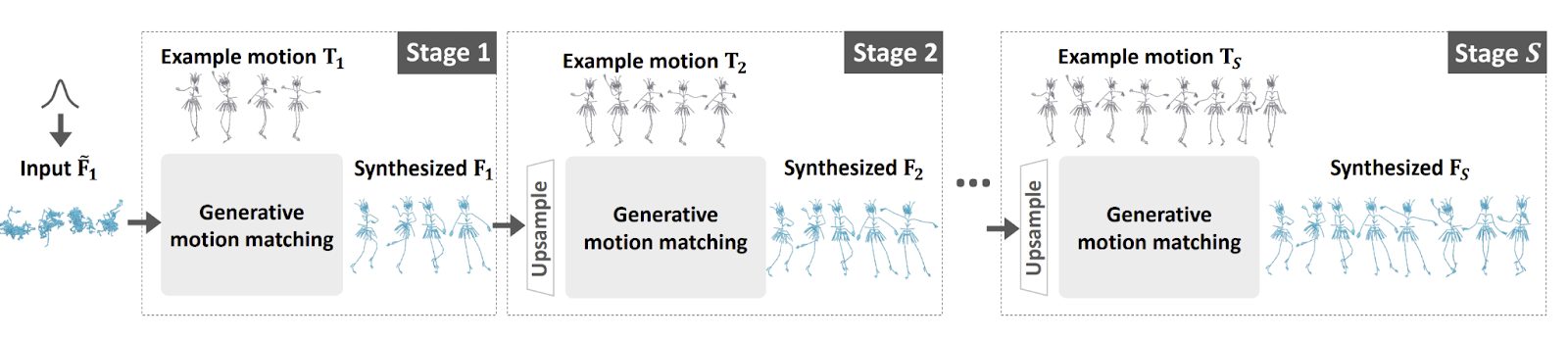
GenMM は、新しい生成コスト関数として双方向の類似性を組み込んでいます。この類似度測定により、合成されたモーションシーケンスには提供された例からのモーションパッチのみが含まれ、その逆も同様です。このアプローチは、モーションマッチングの品質を維持しながら、生成能力を可能にします。多様性をさらに高めるために、例と比較して分布の不一致が最小限に抑えられたモーションシーケンスを段階的に合成するマルチステージフレームワークを利用しています。また、画像合成におけるGANベースの手法の成功に着想を得て、パイプラインに対して無条件のノイズ入力が導入され、高度に多様な合成結果が実現されています。
多様なモーション生成能力に加え、GenMMは、モーションマッチング単独の能力を超えたさまざまなシナリオに拡張できる汎用的なフレームワークであることが証明されています。これには、モーション補完、キーフレームによる生成、無限ループ、モーション再構成が含まれ、生成モーションマッチングアプローチによって可能になる広範なアプリケーションの範囲を示しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- PythonとRにおける機械学習アルゴリズムの比較
- 事前学習済みのViTモデルを使用した画像キャプショニングにおけるVision Transformer(ViT)
- TensorFlowを使用して責任あるAIを構築する方法は?
- Microsoft AIは、バッチサイズや帯域幅の制限に阻まれることなく、効率的な大規模モデルのトレーニングにZeROを搭載した高度な通信最適化戦略を導入しています
- CoDiに会おう:任意対任意合成のための新しいクロスモーダル拡散モデル
- AIがYouTubeの多言語吹替を開始します
- vLLMについて HuggingFace Transformersの推論とサービングを加速化するオープンソースLLM推論ライブラリで、最大24倍高速化します