「生成AIの規制」
Generating AI Regulation
LLMはEU AI法案にどれだけ適合していますか?

生成型人工知能(AI)が中心になる中、この技術の規制が求められるようになってきました。なぜなら、この技術は大勢の人々に迅速に悪影響を及ぼす可能性があるからです。その影響は、差別、固定観念の浸透、プライバシーの侵害、ネガティブなバイアス、基本的な人間の価値を損なうことなどが考えられます。
2023年6月、アンソリック、メタ(Facebook)、Google、Amazon、OpenAI、Microsoftなど、いくつかの有名企業が含まれる複数の企業が、アメリカ政府が発表した一連の自主的なAIガイドラインに同意しました[1]。これはアメリカにとって大きな進歩ですが、AIの規制に関しては、アメリカは常に欧州連合に遅れをとっています。私の前の投稿「生成型AIの倫理:自律コンテンツの時代における重要な考慮事項」では、EUのAI倫理フレームワークについて探求し、大規模な言語モデル(LLM)の使用時にフレームワークを実装するための考慮事項を提供しました。このブログでは、EU AI法案の草案とLLMが草案の法律にどれだけ従っているかに焦点を当てます。
EU AI法案
2023年6月、EUは世界で初めてのAIに関する法案の草案を可決しました。2019年に批准されたAI倫理フレームワークを基に構築されたこのEUの優先事項は、「安全で透明性があり、追跡可能で、差別的でなく、環境に優しい」AIシステムがEUで使用されることを保証することです[2]。EUの枠組みでは、AIシステムには人間が関与し続けることが求められます。つまり、企業は単純にAIと自動化に任せることはできません。
提案された法律では、AIを人々に与える可能性のあるリスクに応じて、AIを3つの異なるカテゴリに分類しています。各リスクレベルには異なるレベルの規制が必要です。この計画が受け入れられれば、これが世界で初めての一連のAI規制となります。EUが特定した3つのリスクレベルは、受け入れられないリスク、高いリスク、制限されたリスクです。
- 受け入れられないリスク:人に害を及ぼし、人間に脅威を与える技術の使用は禁止されます。具体的な例としては、個人や特定の弱者クラスの認知的な影響、社会的地位に基づく人々のランキング、リアルタイムの監視や大量の遠隔識別のための顔認識などが考えられます。さて、世界中の軍隊が自律兵器に注力していることは皆さんもご存知ですが、それは置いておきます。
- 高いリスク:安全性や基本的な権利と自由に対して有害な影響を与える可能性のあるAIシステムは、EUによって2つの異なるカテゴリに分類されます。最初のカテゴリは、EUの製品安全規制に該当する小売製品に組み込まれたAIです。これにはおもちゃ、飛行機、自動車、医療機器、エレベーターなどが含まれます。2番目のカテゴリはEUのデータベースに登録される必要があります。これには生体認証技術、重要なインフラの運用、訓練と教育、雇用に関連する活動、警察活動、国境管理、法律の分析などの技術が含まれます。
- 制限されたリスク:少なくとも低リスクシステムは、透明性と公正性の基準を満たす必要があります。EUは、ユーザーがAIと関わっていることを通知することを義務付けています。また、モデルが違法な素材を作成しないようにするために、モデルメーカーは使用した(あれば)著作権のある素材を開示する必要があります。
EU AI法案は、次に加盟国間で協議され、法律の最終形態に対して投票できるようにする必要があります。EUは、2023年の年末を目指して批准を目指しています。
さて、現在のLLMが草案に従っているかどうかを見てみましょう。
LLMが草案のEU AI法案に適合しているかどうか
スタンフォード大学のFoundation Models研究センター(CRFM)と人間中心の人工知能研究所(HAI)の研究者は、最近、「Foundation ModelsはEU AI法案に適合しているか?」というタイトルの論文を発表しました。彼らは法案から22の要件を抽出し、カテゴリに分類し、そして22の要件のうち12について5段階の評価基準を作成しました。評価基準やスコアなど、すべての研究結果は、MITライセンスのもとでGitHubで入手できます。
研究チームは、法的要件を表1.1で見られるカテゴリにマッピングしました。ただし、チームは特定された22の要件のうち、12つしか評価していません。最終的に、チームは公に利用可能なデータおよびモデルメーカーが提供した文書に基づいて、最も容易にアクセス可能な12つの要件を選択しました。
表1.1:LLMコンプライアンステーブルの要約
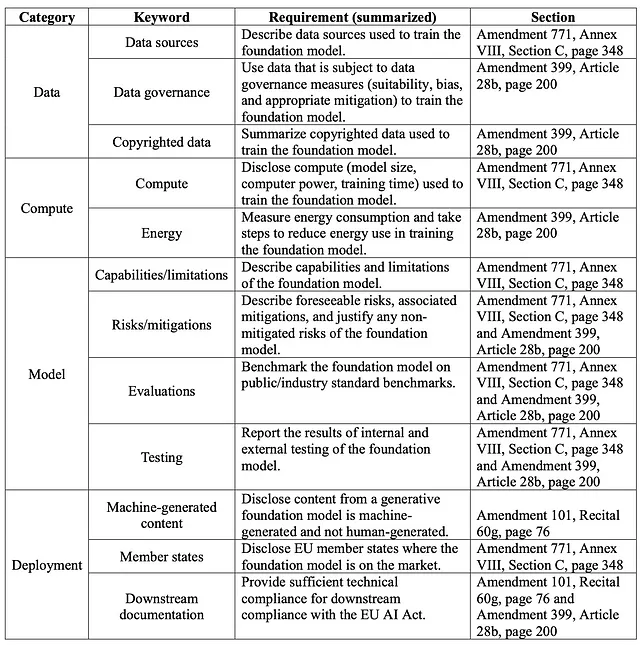
認識がない人々に対して、スタンフォードチームは100以上のLLMデータセット、モデル、アプリケーションを詳細にカタログ化しています。これらは彼らのエコシステムグラフ上で見つけることができます。研究者は、「10の基礎モデルプロバイダーとそれらのフラッグシップ基礎モデルに基づいて、[私たちの]基準に基づいて12の法案の要件を分析しました」と述べています。
研究者は、OpenAI、Anthropic、Google、Meta、Stability.aiなどのモデルを調査しました。彼らの分析に基づいて、以下のスコアカードが作成されました。
図1.2:基礎モデルプロバイダーのEU AI法案へのコンプライアンス評価

全体として、研究者はプロバイダー間でモデルのコンプライアンスにかなりのばらつきがあることを指摘しました(これは22の要件のうちの12つにすぎません)。現在のところ、「一部のプロバイダーは25%未満のスコア(AI21 Labs、Aleph Alpha、Anthropic)を取得し、1つのプロバイダーのみが少なくとも75%のスコア(Hugging Face/BigScience)を取得しています」と述べています。
全文をお読みいただくことをお勧めしますが、研究者はすべてのプロバイダーに改善の余地があると述べています。彼らはまた、次のようないくつかの重要な「持続的な課題」を特定しました:
● 曖昧な著作権問題:ほとんどの基礎モデルはインターネットからのデータを学習していますが、そのうちの多くはおそらく著作権で保護されています。ただし、ほとんどのプロバイダーはトレーニングデータの著作権ステータスを明確にしていません。著作権で保護されたデータを使用および複製することの法的な意味合い、特にライセンス条項を考慮する場合、現在アクティブな訴訟の対象となっています(ワシントン・ポスト – AIが彼らの仕事から学んだ。今、彼らは補償を求めている。ロイター – AI企業に対するアーティストの訴訟に欠陥があると米国の裁判官が判断)。時間の経過に伴い、これがどのように展開されるか見ていかなければなりません。
● リスク軽減の開示の欠如:前述のように、AIは多くの人々に急速に悪影響を与える可能性があるため、LLMのリスクを理解することは重要です。ただし、ほとんどの基礎モデルプロバイダーは、草案の中で特定されたリスク開示を無視しています。多くのプロバイダーがリスクをリストアップしていますが、特定されたリスクを軽減するために取った手順を詳細に説明しているものは非常に少ないです。ジェネレーティブAIのケースではありませんが、最近の訴訟には、米国の健康保険会社Cigna Healthcareに対する訴訟があります。この訴訟では、彼らがAIを使用して支払いを拒否したと主張しています(Axios – AI訴訟が健康分野に広がる)。ビル・ゲイツは素晴らしい記事「AIのリスクは現実的ですが管理可能です」と題して執筆しましたので、お読みいただくことをお勧めします。
● 評価と監査の不足:基礎モデルのパフォーマンスを評価するための一貫した基準が不足しています。特に潜在的な誤用やモデルの堅牢性の分野ではそうです。アメリカ合衆国のCHIPS and Science法は、国立標準技術研究所(NIST)にAIモデルの標準化評価を作成するよう指示しています。モデルの評価と監視の能力は、最近議論した私のGenAIOpsフレームワークの焦点でした。最終的には、GenAIOps、DataOps、DevOpsが共通のフレームワークの下で統合されることになるでしょうが、まだまだ先の話です。
● 一貫性のないエネルギー消費報告:私たちの世界中で最近の熱波を経験した方も多いと思います。LLMの基礎モデルプロバイダーは、エネルギー使用量と関連する排出物の報告においてかなりのばらつきがあります。実際、研究者は、私たちがまだエネルギー使用量を測定および計算する方法さえ知らないという他の研究を引用しています。nnlabs.orgは次のように報告しています。「OpenAIによれば、15億のパラメータを持つGPT-2は、単一プロセッサでの計算時間に355年を要し、トレーニングには28,000 kWhのエネルギーを消費しました。比較のため、1750億のパラメータを持つGPT-3は、単一プロセッサでの計算時間に355年を要し、トレーニングには284,000 kWhのエネルギーを消費しました。これはGPT-2の10倍のエネルギーです。BERTには3億4000万のパラメータがあり、64のTPUで4日間のトレーニングが必要で、1536 kWhのエネルギーを消費しました」。
上記に加えて、組織で生成型AIを実装する際には、多くの他の問題にも対処する必要があります。
要約
研究に基づくと、生成型AI技術の提供者や採用者にはまだ長い道のりがあります。法律制定者、システムデザイナー、政府、組織は、これら重要な問題に取り組むために協力する必要があります。出発点として、AIシステムの設計、実装、利用において透明性を確保することが重要です。規制された産業では、LLM(Large Language Models)はしばしば数十億のパラメータを持っています。何億もの要素を持つシステムがどのように解釈可能で透明性を持つことができるのでしょうか?これらのシステムには明確で曖昧さのないドキュメンテーションが必要であり、知的財産権を尊重する必要があります。環境、社会、企業統治(ESG)を支援するためには、エネルギー消費の計測と報告のための標準化されたフレームワークを設計する必要があります。最も重要なことは、AIシステムが安全であり、プライバシーを尊重し、人間の価値を守ることです。AIには人間中心のアプローチが必要です。
人工知能についてもっと学びたい場合は、私の書籍『人工知能:ビジネスにAIを活用するためのエグゼクティブガイド』をAmazonでご覧ください。または、Google PlayでAIがナレーションされたオーディオブックをチェックしてください。
[1] Shear, Michael D., Cecilia Kang, and David E. Sanger. 2023. “Pressured by Biden, A.I. Companies Agree to Guardrails on New Tools.” The New York Times, July 21, 2023, sec. U.S. https://www.nytimes.com/2023/07/21/us/politics/ai-regulation-biden.html.
[2] European Parliament. 2023. “EU AI Act: First Regulation on Artificial Intelligence | News | European Parliament.” www.europarl.europa.eu. August 6, 2023. https://www.europarl.europa.eu/news/en/headlines/society/20230601STO93804/eu-ai-act-first-regulation-on-artificial-intelligence.
[3] Bommasani, Rishi, Kevin Klyman, Daniel Zhang, and Percy Liang. 2023. “Stanford CRFM.” Crfm.stanford.edu. June 15, 2023. https://crfm.stanford.edu/2023/06/15/eu-ai-act.html.
[4] Bommasani, Rishi, Kevin Klyman, Daniel Zhang, and Percy Liang. 2023. “Stanford CRFM.” Crfm.stanford.edu. June 15, 2023. https://crfm.stanford.edu/2023/06/15/eu-ai-act.html.
[5] ai. 2023. “Power Requirements to Train Modern LLMs.” Nnlabs.org. March 5, 2023. https://www.nnlabs.org/power-requirements-of-large-language-models/.
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






