より一般的なロボットへのスタッキング
General robot stacking
ビジョンベースのロボット操作の新しいベンチマーク、RGB-スタッキングの紹介
棒を拾って丸太の上にバランスを取る、または石の上に小石を積み重ねることは、人にとっては簡単で似たような行動に見えるかもしれません。しかし、ほとんどのロボットは一度に複数のこのようなタスクを処理するのに苦労します。棒を操作するには、石を積み上げるよりも異なる行動パターンが必要であり、ましてやさまざまな皿を積み重ねたり家具を組み立てたりすることなどはなおさらです。これらのタスクをロボットに教える前に、まずはロボットがより幅広いオブジェクトとの相互作用を学ぶ必要があります。DeepMindのミッションの一環として、より一般的で有用なロボットを実現するための一歩として、私たちは、異なる形状のオブジェクトとの相互作用をロボットがよりよく理解する方法を探求しています。
私たちは、CoRL 2021(ロボット学習の会議)で発表される予定の論文として、またOpenReviewのプレプリントとしてすでに利用可能なものとして、RGB-スタッキングを新たなビジョンベースのロボット操作のベンチマークとして紹介しています。このベンチマークでは、ロボットが異なるオブジェクトを掴んで重ねる方法を学ぶ必要があります。私たちの研究を他の先行研究とは異なるものにするのは、使用されるオブジェクトの多様性と、私たちの結果を検証するために行われた大量の実証評価です。私たちの結果は、シミュレーションと現実世界のデータの組み合わせを使用して、複雑なマルチオブジェクト操作を学ぶための強力な基準を示しており、新しいオブジェクトへの一般化の問題に対する強力なベースラインを提案しています。他の研究者をサポートするために、私たちはシミュレートされた環境のバージョンをオープンソース化し、実際のロボットのRGB-スタッキング環境の設計を公開し、さらにRGBオブジェクトモデルとそれらを3Dプリントするための情報も提供します。また、私たちのロボティクス研究で使用されるライブラリやツールのコレクションもオープンソース化しています。
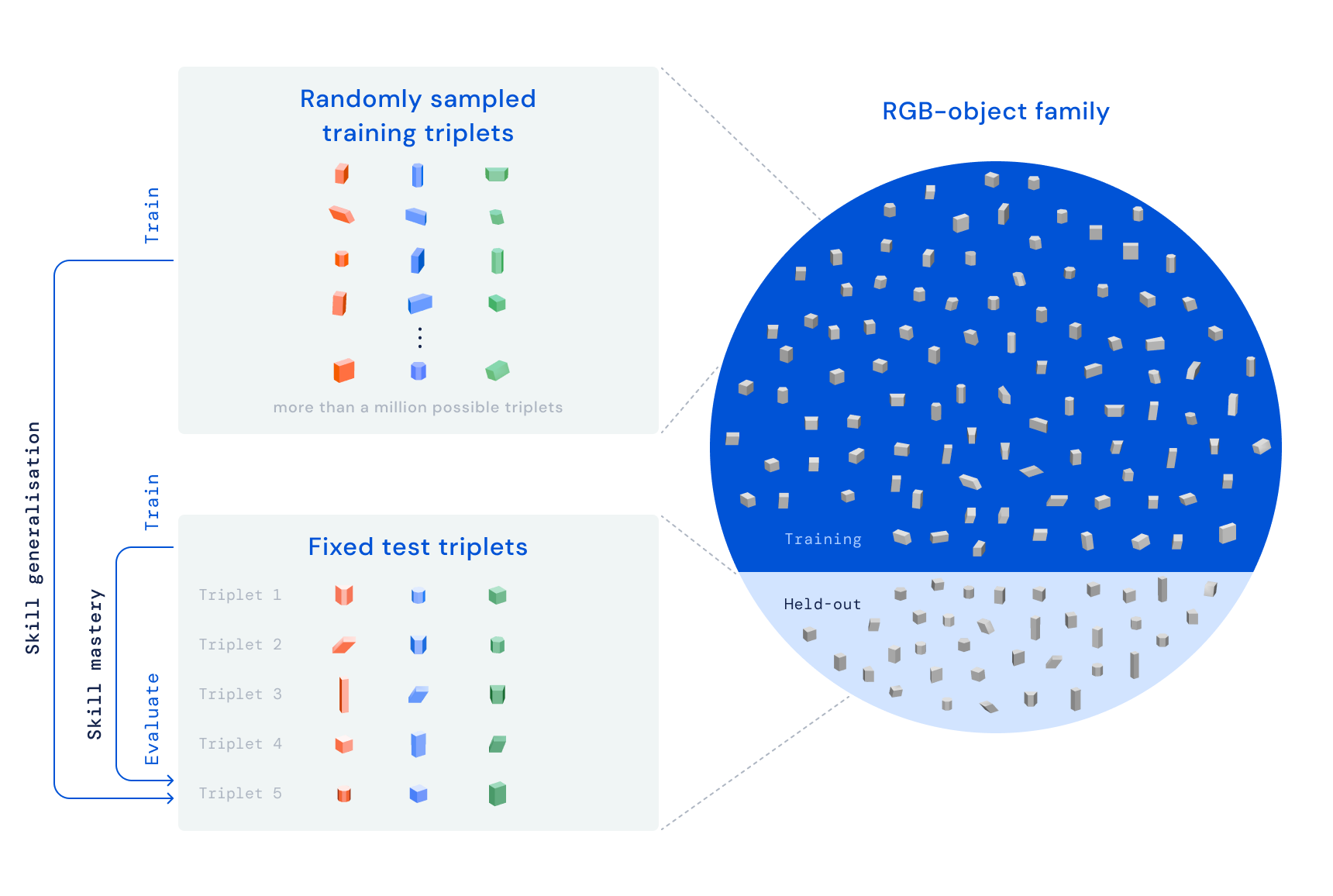
RGB-スタッキングでは、強化学習を通じてロボットアームを訓練し、異なる形状のオブジェクトを積み重ねることを目指しています。バスケットの上に取り付けられた並行グリッパーをロボットアームに配置し、バスケットには3つのオブジェクト(赤、緑、青の各色)を配置します。タスクはシンプルです。20秒以内に赤いオブジェクトを青いオブジェクトの上に積み重ねることであり、緑のオブジェクトは障害物となるため、注意をそらす役割を果たします。学習プロセスでは、エージェントが複数のオブジェクトセットでトレーニングを通じて一般化されたスキルを獲得するようになります。私たちは故意に、グラスプとスタックのアフォーダンス(エージェントが各オブジェクトを掴んだり積み重ねたりするための特性)を変化させています。この設計原則により、エージェントは単純なピックアンドプレイス戦略を超える行動を示す必要があります。
私たちのRGB-スタッキングベンチマークには、難易度の異なる2つのタスクバージョンが含まれています。”Skill Mastery”では、5つのトリプレットをスタッキングすることに熟達した単一のエージェントを訓練することを目標としています。”Skill Generalisation”では、同じトリプレットを評価に使用しますが、訓練オブジェクトはテストトリプレットから選ばれたオブジェクトのファミリーを除外した大量のトレーニングオブジェクトで訓練します。両バージョンでは、学習パイプラインを3つのステージに分割しています。
- 最初に、オフシェルフの強化学習アルゴリズムであるMaximum a Posteriori Policy Optimisation (MPO) を使用してシミュレーションでトレーニングを行います。この段階では、シミュレータの状態を使用し、オブジェクトの位置を画像内で検出する必要がないため、トレーニングが高速に行えます。ただし、このポリシーは実際のロボットに直接適用することはできません。
- 次に、リアルな観測データでシミュレーションで新しいポリシーをトレーニングします。観測データには画像とロボットの固有の状態が含まれます。ドメインランダマイズドシミュレーションを使用して、実世界の画像と動態への転送を改善します。状態ポリシーは教師として機能し、学習エージェントに行動の修正を提供し、これらの修正は新しいポリシーに統合されます。
- 最後に、このポリシーを実際のロボット上で使用してデータを収集し、クリティック正則化回帰(CRR)のような学習済みのQ関数に基づいて良好な遷移を重み付けして改善されたポリシーをオフラインでトレーニングします。これにより、実際のロボット上で時間のかかるオンライントレーニングアルゴリズムを実行する代わりに、プロジェクト中に収集されるパッシブなデータを使用することができます。
このように学習パイプラインを分離することは、2つの主要な理由で重要です。まず、ロボット上でゼロから始めると時間がかかりすぎるため、問題を解決することが可能になります。さらに、異なるメンバーがパイプラインの異なる部分に取り組むことができるため、研究速度が向上します。
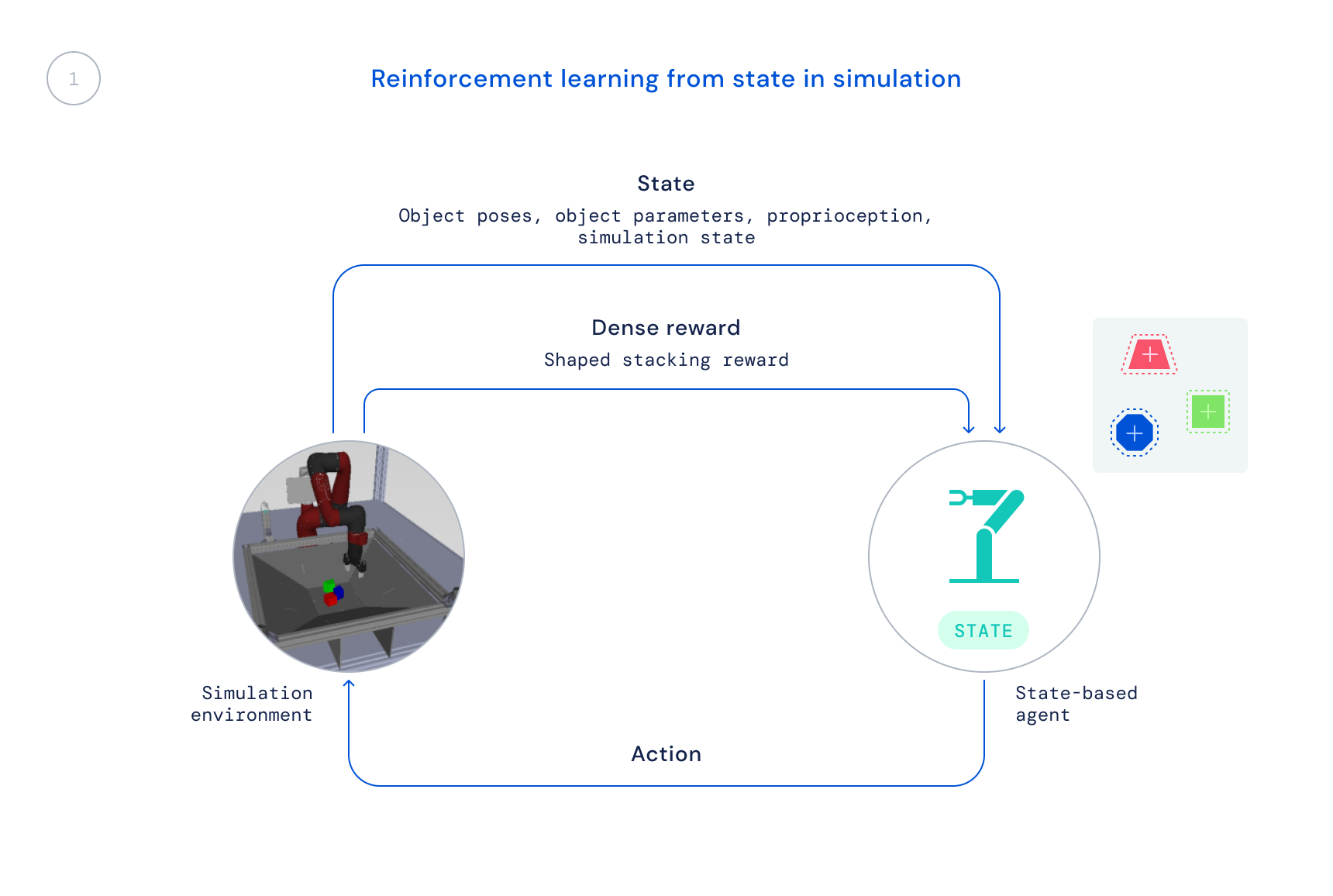
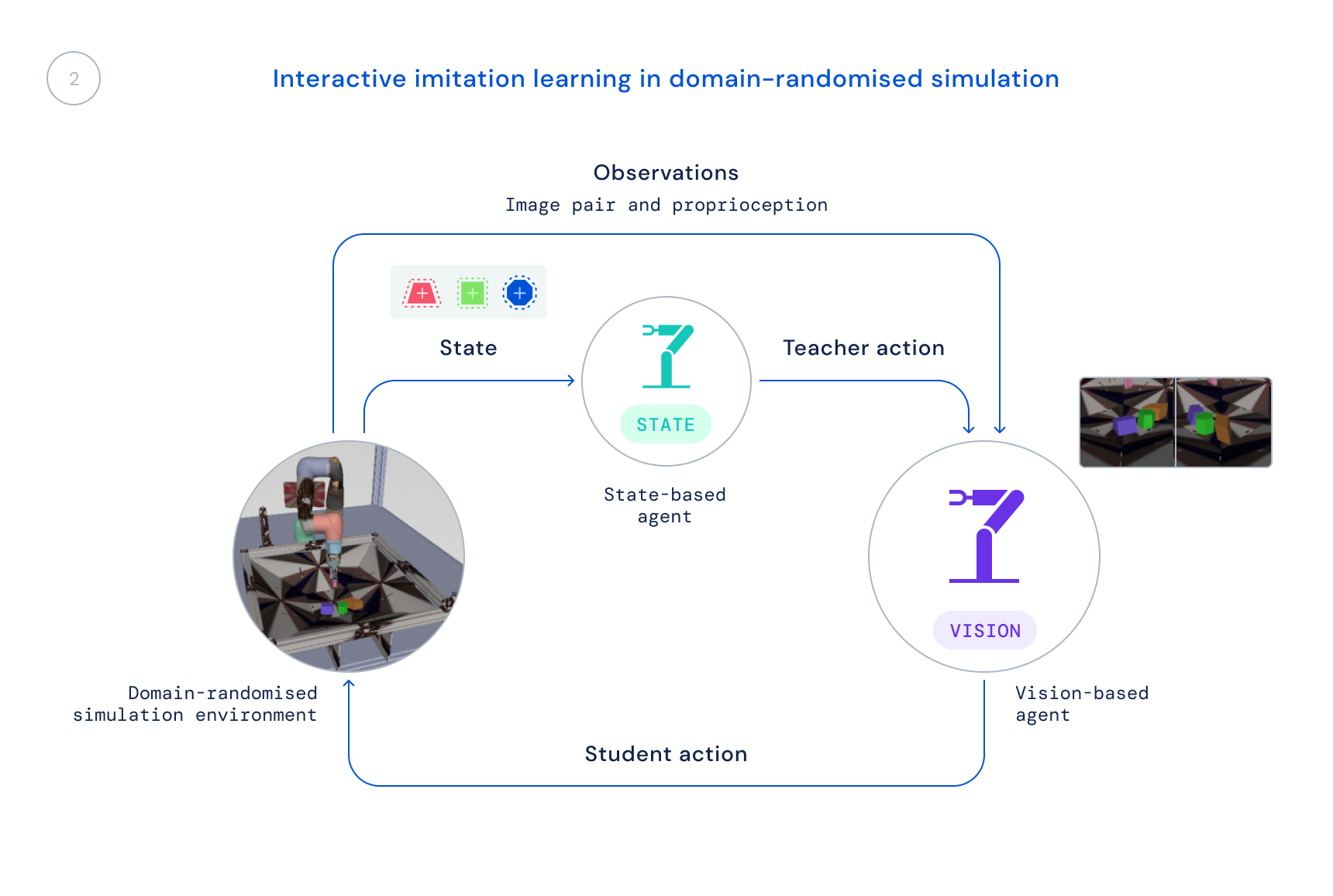
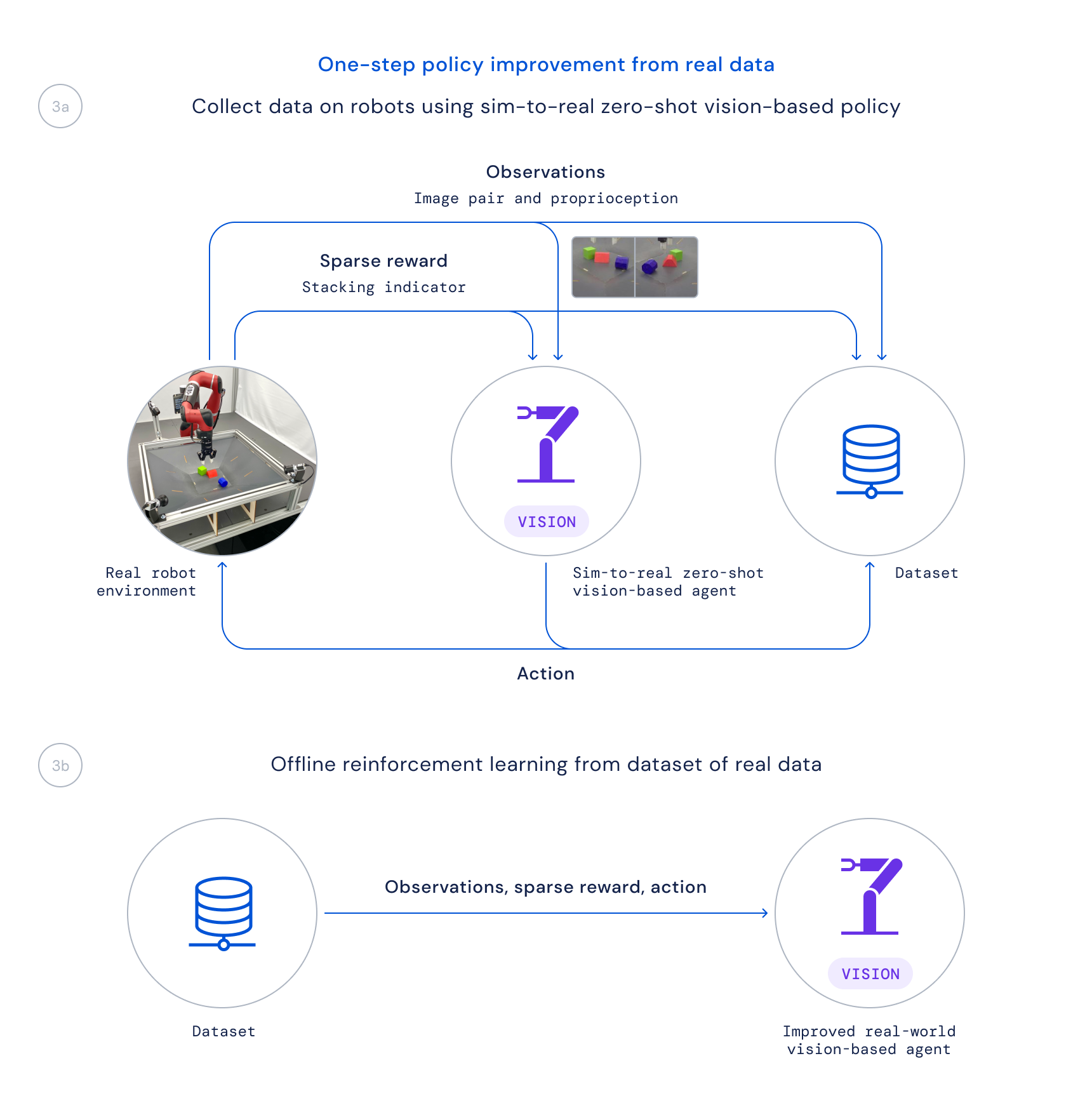

近年、学習アルゴリズムを使用して困難な実際のロボット操作問題を大規模に解決するための研究が多く行われていますが、その多くは掴む、押す、または他の形式の単一のオブジェクトを操作するというタスクに焦点が当てられています。私たちの論文で説明するRGB-Stackingのアプローチは、GitHubで利用可能なロボティクスリソースと共に、驚くほどの積み重ね戦略と積み重ねの一部のマスタリーを実現します。ただし、これは可能性の一部に過ぎず、一般化の課題は完全に解決されていません。研究者がロボット工学における真の一般化の課題を解決し続ける中で、私たちはこの新しいベンチマークと環境、設計、そして公開したツールが、操作をより容易にし、ロボットの能力を高めるための新しいアイデアと手法に貢献することを願っています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





