GenAIOps:MLOpsフレームワークの進化
GenAIOps Evolution of MLOps Framework
生成AIには新しい展開および監視の能力が必要です

2019年に、私はLinkedInのブログ「なぜ成功するイノベーションにはML Opsが必要か」を公開しました。しかし、時が経っても、多くの組織にとって、分析、機械学習(ML)、人工知能(AI)モデル(またはシステム)を運用化することはまだ課題です。しかし、技術は進化し、新しい企業が誕生して、展開、監視、モデルの更新を製品環境で行うための課題に取り組む手助けをしています。しかし、OpenAIのGPT-4、GoogleのPaLM 2 MetaのLLaMA、GitHub Copilotなどの大規模言語モデル(LLM)を使用した生成AIの最近の進展により、組織はLLMの価値、コスト、実装のタイムライン、リスクを理解するために競い合っています。組織は、LLMの微調整、展開、監視、維持に対してまだ準備が整っていないと言っても過言ではありません。
MLOpsとは何ですか?
マシンラーニングオペレーション(MLOps)とは、次のように定義されます:
MLOpsは、統計、データサイエンス、機械学習モデルを再利用可能で高可用性のソフトウェアアーティファクトとして管理するための、クロス機能で協力的な継続的なプロセスです。これは、モデルの推論、スケーラビリティ、メンテナンス、監査、ガバナンス、および継続的なモデルの監視を含む、一意の管理側面を包括しています。これにより、基盤となる条件が変化するにつれて、モデルがまだポジティブなビジネス価値を提供し続けていることが保証されます[1]。
MLOpsの明確な定義があるので、なぜ組織に重要なのかについて話しましょう。
なぜMLOpsが重要なのですか?
現在のアルゴリズムに基づくビジネス環境では、MLOpsの重要性は過小評価できません。組織は日々の意思決定や業務効率を向上させるために、ますます洗練されたMLモデルに頼るようになっています。これらのモデルを展開、管理、監視、更新するための堅牢でスケーラブルな効率的なシステムの必要性は極めて重要です。MLOpsは、モデルを開発するデータサイエンティストやコンピュータサイエンティストと、それらを展開、管理、保守するITオペレーションチームとの協力のためのフレームワークとプロセスを提供し、モデルが信頼性があり、最新の状態でビジネス価値を提供することを確認します。
MLOpsの主な機能
大まかに言えば、MLOpsには自動化された機械学習のワークフロー、モデルのバージョニング、モデルの監視、およびモデルのガバナンスが含まれます。
● 自動化されたワークフローは、モデルのトレーニング、検証、展開のプロセスを効率化し、手作業の作業を減らしてスピードを向上させます。
● モデルのバージョニングは、変更を追跡し、モデルのイテレーションの登録を維持することができます。
● モデルの監視は、モデルが製品システムで期待どおりに動作していることを確認するために重要です。
● モデルのガバナンスは、規制や組織のポリシーを遵守するためのものです。
これらの機能を組み合わせることで、組織はMLとAIをスケールできるようにし、ビジネス価値と競争上の優位性を推進することができます。
MLOps:メトリクスとKPI
モデルが製品システムで期待どおりに動作し、最適な予測を提供していることを確認するために、いくつかのタイプのメトリクスと主要パフォーマンス指標(KPI)が使用されます。データサイエンティストに話を聞くと、次のようなメトリクスがよく強調されます:
● モデルのパフォーマンスメトリクス:これらはモデルの予測パフォーマンスを測定するメトリクスです。これには、正確さ、精度、再現率、F1スコア、ROC曲線下の面積(AUC-ROC)、平均絶対誤差(MAE)、平均二乗誤差(MSE)などが含まれます。メトリクスの選択は、問題のタイプ(分類、回帰など)とビジネスコンテキストに依存します。
● データドリフト:これは、製品ワークフローの入力データがモデルのトレーニングに使用されたデータからどれだけ逸脱しているかを測定します。重要なデータドリフトは、モデルの予測が時間の経過とともに信頼性を失う可能性を示すことがあります。私たちはCOVIDという小さな「ブリップ」でこれの素晴らしい例を見ました。消費者の習慣やビジネスの慣行が一夜にして変わり、すべてのモデルが壊れました!
● モデルドリフト: データドリフトと同様に、これはデータ分布が通常と異なる方向に逸脱しているかどうかではなく、モデルのパフォーマンスが時間とともにどれだけ変化するか(しばしば低下するか)を測定します。これは、基礎となるデータ分布が変化し、モデルの前提条件がより正確でなくなる場合に発生する可能性があります。
● 予測分布: モデルの予測の分布を追跡することで、異常を検出することができます。例えば、二値分類モデルが突然通常よりも多くの陽性を予測し始める場合、問題がある可能性があります。これらは通常、ビジネスメトリクスと最も一致します。
● リソース使用量: ITリソースの使用量には、CPU使用量、メモリ使用量、レイテンシなどのメトリクスが含まれます。これらのメトリクスは、モデルが効率的に実行され、システムのインフラストラクチャとアーキテクチャの制約内で実行されていることを確認するために重要です。
● ビジネスメトリクス: すべてのメトリクスの中で最も重要なもので、これらのメトリクスはモデルがビジネスの成果に与える影響を測定します。収益、顧客の離反率、コンバージョン率、一般的には応答率などのメトリクスが含まれる可能性があります。これらのメトリクスは、モデルが期待されるビジネス価値を提供しているかどうかを評価するのに役立ちます。
それでは、MLOpsの概要、重要性、主な機能、およびメトリクスについての理解ができたので、これは生成AIとどのように関連しているのでしょうか?
生成AI: 主なクロスファンクショナルのユースケース
生成AIが主流になる前、組織は主に構造化および半構造化データに作用するAIシステムを実装していました。これらのシステムは主に数値に基づいてトレーニングされ、数値の出力(予測、確率、グループの割り当てなど)を生成しました(セグメンテーションやクラスタリングを考えてください)。言い換えれば、私たちはトランザクション、行動、人口統計、技術統計、企業統計、地理空間、および機械生成データなどの歴史的な数値データでAIモデルをトレーニングし、離反、応答、またはオファーとの相互作用の可能性を出力しました。テキスト、音声、ビデオデータを使用しなかったわけではありませんが、これらのユースケースは数値ベースのアプローチよりもはるかに少なかったです。生成AIには、テキスト、音声、およびビデオデータをこれまで無視してきたデータを活用するための新しい能力があります。
使用方法やアプリケーションは多岐にわたりますが、私は生成AIの主なクロスファンクショナルのユースケースを要約しました(現時点でのもの)。
コンテンツ生成
生成AIは、音声、映像/画像、およびテキストから人間らしい品質のコンテンツを生成することができます。
● 音声コンテンツ生成: 生成AIは、YouTubeなどのソーシャルメディアプラットフォームに適したオーディオトラックを作成したり、書かれたコンテンツにAIパワーのボイスオーバーを追加したりすることができます。実際に、私の最初の2冊のTinyTechGuidesは、完全にAIによって生成されたGoogle Play上のボイスオーバーが付いたオーディオブックです。アクセント、性別、年齢、テンポなどのキー属性を選ぶことができます。AIによるナレーション付きオーディオブックはこちらでご覧いただけます。
○ 人工知能: ビジネスにAIを活用するためのエグゼクティブガイド
○ 現代のB2Bマーケティング: マーケティングの卓越性を追求する実践者ガイド
● テキストコンテンツ生成: これは現時点でおそらく最も人気のある生成AIの形式です。ブログ記事、ソーシャルメディアの更新、製品説明、下書きのメール、顧客への手紙、RFP提案など、さまざまなテキストコンテンツを簡単に生成することができます。ただし、生成されたコンテンツが信頼性があり、権威を持っているということは、必ずしも事実に基づいているわけではありませんのでご注意ください。
● 画像およびビデオ生成: AIによって生成されたキャラクターがスターウォーズシリーズで人気を博したり、最新の「インディアナ・ジョーンズ」の映画でハリソン・フォードの若返りが行われたりするなど、ハリウッドで徐々に成熟してきました。AIは現実的な画像や映画を作成することができます。生成AIは、広告、プレゼンテーション、ブログのコンテンツを生成することでクリエイティブサービスを加速することができます。AdobeやCanvaなどの企業がクリエイティブサービスに積極的に取り組んでいるのを見てきました。
● ソフトウェアコードの生成: 生成AIはソフトウェアコード(Pythonなど)やSQLを生成し、分析およびBIシステム、およびAIアプリケーション自体に統合することができます。実際、Microsoftは、より正確なソフトウェアコードを作成するために「テキストブック」をトレーニングするLLMの研究を続けています。
コンテンツの要約とパーソナライゼーション
企業に新たなリアルなコンテンツを作成するだけでなく、生成AIはコンテンツの要約とパーソナライゼーションにも使用することができます。ChatGPTをはじめとする企業は、マーケティング機能や組織向けにコンテンツの要約とパーソナライゼーションをターゲットにしています。これにより、マーケティング組織は、よく考えられたコンテンツカレンダーやプロセスを作成するための時間を確保し、これらのさまざまなサービスを微調整して、無限のバリエーションの承認済みコンテンツを作成し、適切な人に適切なチャネルで適切なタイミングで配信することができます。
コンテンツの発見とQ&A
生成AIが進展している第三の領域は、コンテンツの発見とQ&Aです。データと分析ソフトウェアの観点から見ると、さまざまなベンダーが生成AIの機能を組み込んで、組織内の新しいデータセットの自動的な発見や既存のデータセットのクエリや式の作成を容易にするために、より自然なインターフェース(自然言語)を作成しています。これにより、非専門のビジネスインテリジェンス(BI)ユーザーは、「北東地域での売上はどれくらいですか?」といった簡単な質問をすることができ、それからより洗練された質問をすることができます。BIと分析ツールは、クエリに基づいて関連するグラフや図を自動的に生成します。
また、医療業界や法務業界でもこのような使用法の増加が見られます。医療セクターでは、生成AIが大量のデータを処理し、医師のメモを要約したり、チャットボット、メールなどを通じて患者とのコミュニケーションを個別化したりするのに役立ちます。診断能力については生成AIの単独使用には慎重な姿勢がありますが、人間を介することでこの使用法が増えるでしょう。法律の専門分野でも生成AIの使用法が増えるでしょう。文書中心の業界である法律業界では、生成AIが契約書内の重要な用語を迅速に見つけ出したり、法的調査を助けたり、契約書を要約したり、弁護士のためにカスタムの法的文書を作成したりすることができます。マッキンゼーはこれを「法的な副操縦士」と呼んでいます。
生成AIの主な使用法を理解したところで、次に重要な懸念点について考えてみましょう。
生成AI:主な課題と考慮事項
有望ながら、生成AIにはさまざまな障壁と潜在的な落とし穴があります。組織は、生成AI技術をビジネスプロセスに統合する前に、いくつかの要素を慎重に考慮する必要があります。主な課題は以下のとおりです:
● 精度の問題(幻覚): LLM(大規模言語モデル)はしばしば誤った情報や完全に虚偽の情報を生成することがあります。これらの応答は信憑性があるように見えるかもしれませんが、完全にでっち上げられたものです。企業は、この誤情報を検出し予防するためにどのような保護策を確立できるでしょうか?
● バイアス:組織はモデルのバイアスの源を理解し、それを制御するための緩和策を実施する必要があります。潜在的な体系的なバイアスに対処するために、どのような企業の方針や法的な要件が存在していますか?
● 透明性の欠如:特に金融サービス、保険、医療などのセクターでは、多くのアプリケーションにおいてモデルの透明性はビジネス上の要件です。しかし、LLMは本質的に説明可能性や予測可能性がないため、「幻覚」やその他の潜在的なトラブルが生じることがあります。監査人や規制当局の要求を満たす必要がある場合、LLMを使用できるでしょうか?
● 知的財産(IP)リスク:基盤となるLLMのトレーニングに使用されるデータには、しばしば公開されている情報が含まれています。イメージの不適切な使用(例:HBR – Generative AI Has an Intellectual Property Problem)、音楽の使用(The Verge – AI Drake Just Set an Impossible Legal Trap for Google)、書籍の使用(LA Times – Sara Silverman and Other Bestselling Authors Sue MEta and OpenAI for Copyright Infringement)に関する訴訟が見られました。多くの場合、トレーニングプロセスは利用可能なすべてのデータを無差別に吸収するため、IPの露出や著作権侵害に関する訴訟の可能性が生じます。ここで問われるのは、基盤となるモデルのトレーニングに使用されたデータと、それを微調整するために使用されたデータは何かということです。
● サイバーセキュリティと詐欺:生成AIサービスの広範な利用に伴い、組織は悪意ある行為者による悪用の可能性に備える必要があります。生成AIは社会工作攻撃のためのディープフェイクの作成に利用されることがあります。組織は、トレーニングに使用されるデータが詐欺師や悪意ある行為者によって改ざんされていないことをどのように保証できるでしょうか?
● 環境への影響:大規模なAIモデルのトレーニングには膨大な計算リソースが必要であり、それに伴い大量のエネルギー消費が発生します。これは環境に影響を与えます。使用されるエネルギーは再生可能な源ではなく、二酸化炭素の排出に寄与します。環境、社会、ガバナンス(ESG)のイニシアチブを持つ組織は、LLMの使用をどのように考慮するのでしょうか?
これ以外にも考慮すべきことはたくさんありますが、主な課題は把握しました。次の質問は、生成AIモデルをどのように運用するのかということです。
GenAIOps:新しい能力の必要性
生成AI、主な使用法、課題、考慮事項についてより良い理解を得たので、次にMLOpsフレームワークがどのように進化する必要があるかについて考えてみましょう。私はこれを「GenAIOps」と名付けましたが、私の知る限りでは初めての命名です。
LLMの作成における高レベルのプロセスを見てみましょう。以下の図は「Foundation Modelsの機会とリスクについて」から修正されたものです。
図1.1:LLMのトレーニングと展開のプロセス
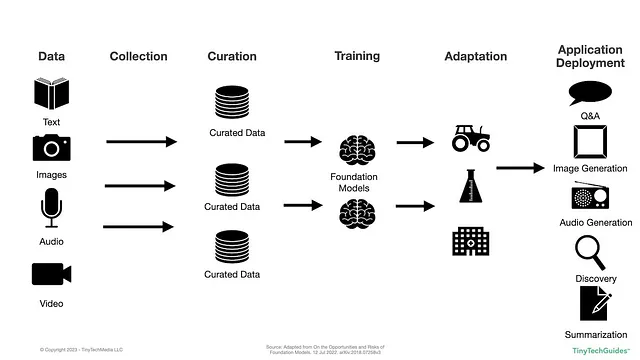
上記の図では、データが作成され、収集され、整理され、モデルがトレーニングされ、適応され、展開されていることがわかります。このような状況の下で、包括的なGenAIOpsフレームワークにはどのような考慮事項が必要でしょうか?
GenAIOps:チェックリスト
最近、スタンフォード大学は「Foundation Models Providers Comply with the Draft EU AI Act?」という論文を発表しました。それを読んだ後、私はそれを基に以下のGenAIOpsフレームワークチェックリストを作成しました。
データ:
○ モデルのトレーニングに使用されたデータソースは何ですか?
○ モデルのトレーニングに使用されたデータはどのように生成されましたか?
○ トレーナーはそのデータをコンテキストで使用する許可を得ていましたか?
○ データには著作権物資料が含まれていますか?
○ データには機密情報や個人情報が含まれていますか?
○ データには個人情報または個人識別情報(PII)が含まれていますか?
○ データは毒されていますか?毒づけの対象になりますか?
○ データは本物ですか、それともAIによって生成されたコンテンツが含まれていますか?
モデリング:
○ モデルにはどのような制限がありますか?
○ モデルにはリスクがありますか?
○ モデルのパフォーマンスのベンチマークは何ですか?
○ 必要な場合、モデルを再作成できますか?
○ モデルは透明ですか?
○ 現在のモデルを作成するために他の基礎となるモデルはどれが使用されましたか?
○ モデルのトレーニングにはどれだけのエネルギーと計算リソースが使用されましたか?
展開:
○ モデルはどこに展開されますか?
○ 対象の展開アプリケーションは生成AIを使用していることを理解していますか?
○ 監査人や規制当局の要求を満たすための適切な文書はありますか?
出発点ができたので、メトリクスを詳しく見てみましょう。
GenAIOps:メトリクスとプロセスの考慮事項
MLOpsのメトリクスとKPIを出発点として、生成AIのメトリクスにこれらがどのように適用されるかを検討してみましょう。GenAIOpsが、偽の情報、フェイク、誤った情報、バイアスのあるコンテンツの生成といった生成AIの特定の課題に対処するのに役立つことを願っています。
モデルパフォーマンスメトリクス
生成AIの文脈で、組織はどのようにモデルのパフォーマンスを測定することができるでしょうか?おそらく、多くの組織は商用で利用可能な事前トレーニング済みのLLMを使用し、自分たちのデータを微調整してモデルを適応させるでしょう。
テキストベースのLLMにはBLEU、ROUGE、METEORなどの技術的なパフォーマンスメトリクスがありますが、偽の情報、フェイク、誤った情報、バイアスのあるコンテンツの生成についてはどうでしょうか。組織は、これらの発生を監視、検出、軽減するためにどのような管理策を講じることができるでしょうか?
過去にはプロパガンダの拡散を目撃してきましたが、FacebookやGoogle、Twitterなどのソーシャルメディア巨大企業は、これを一貫して確実に防止するツールを導入できませんでした。もしもそれが事実なら、組織は生成AIのモデルパフォーマンスをどのように測定するのでしょうか?ファクトチェッカーはいますか?画像、音声、ビデオについてはどうでしょうか?これらのモデルのパフォーマンスをどのように測定できるのでしょうか?
データドリフト
モデルの作成には多くのリソースと時間がかかりますが、世界のデータが変化し、新しいモデルが必要になる場合、モデル作成者はどのように判断するのでしょうか?組織は、自身のデータが再キャリブレーションが必要なレベルに進化しているかどうか理解することができるでしょうか?これは数値データの場合は比較的簡単ですが、テキスト、画像、音声、ビデオなどの非構造化データについてはまだ学びながら取り組んでいると思います。
定期的にモデルを調整する仕組みを作成できると仮定すると、データのドリフトが本物のイベントの結果なのか、AI生成コンテンツの増殖なのかを検出するための制御も必要です。AIエントロピーという私の投稿では、AIをAIにトレーニングすると時間の経過とともにAIは愚かになるという事実について議論しました。
モデルのドリフト
モデルのパフォーマンスやデータのドリフトの懸念と同様に、モデルのパフォーマンスがドリフトし始めた場合、組織はどのように検出し理解するのでしょうか?出力のヒューマンモニタリングやエンドユーザーへのアンケート調査を行いますか?おそらく、モデルの技術的なパフォーマンスを監視するための制御を設けるだけでなく、会社は常にモデルの出力を追跡するべきです。当然のことですが、特定のビジネスの課題を解決するためにモデルを使用しており、ビジネスのメトリクスを監視する必要があります。カートの放棄率の増加、お客様のサービス要求の増加/減少、または顧客満足度の変化などはありますか?
予測分布
再び、数値予測に対してはそれなりのツールと技術があると思います。しかし、テキスト、画像、音声、動画の扱いになると、予測分布をどのように監視するか考える必要があります。モデルのデプロイ先で出力される結果が虚偽の相関を生成していないかを理解できるでしょうか?もしそうなら、この現象を測定するために何を行えるでしょうか?
リソース使用量
一見比較的直感的なものに思えますが、企業内での生成的な使用が増えるにつれて、組織はその使用量を追跡し管理するシステムを用意する必要があります。価格モデルはまだ生成的AIセグメントで進化を遂げているため、注意が必要です。クラウドデータウェアハウスの領域で見られるように、コストが制御を失うことが始まっています。したがって、会社が使用料に基づいた価格設定を採用している場合、どのように財務的な制御とガバナンスの仕組みを整え、予測可能なコストに保つことができるでしょうか?
ビジネスメトリクス
以前にも述べたように、導入したLLMが実際にビジネスにどのような影響を与えているかを監視するために置かれるモニターや制御が最も重要です。重要なビジネスプロセスにこれを使用している場合、稼働時間を確保するためにどのようなSLA保証を持っていますか?
バイアスは任意のAIモデルにおいて大きな懸念事項ですが、生成的AIではさらに深刻な可能性があります。モデルの出力がバイアスを持っている場合、それを検出する方法はありますか?また、それが不平等を助長している場合、それを検出する方法はありますか?Tim O’Reillyの「We Have Already Let the Genie Out of the Bottle」という素晴らしいブログを読むことをお勧めします。
知的財産の観点から、プロプライエタリな機密情報や個人情報が組織から漏れ出さないようにするためにはどのように保証しますか?現在、著作権侵害に関する訴訟が進行中であることを考えると、組織はこれらの重要な要素に取り組む必要があります。ベンダーにこれらがモデルに含まれていないことを保証してもらうべきでしょうか?(FastCompany – Adobe is so confident its Firefly generative AI won’t breach copyright that it’ll cover your legal bills)彼らがあなたの法的費用をカバーすることは素晴らしいことですが、それによって会社の評判リスクはどのようになるでしょうか?顧客の信頼を失えば、二度と取り戻すことはできないかもしれません。
最後に、データの汚染は確かに注目すべきトピックです。組織のデータを使用してモデルを適応させ、微調整する場合、データが有害ではないことをどのように保証できますか?基礎モデルのトレーニングに使用されたデータが毒されていないことを保証する方法はありますか?
まとめ
結局のところ、この記事の目的はGenAIOpsに対処するための具体的な方法や指標を提供することではなく、LLMを導入する前に組織が考慮する必要がある一連の質問を提示することでした。どんなものでも、生成的AIは組織が競争上の優位性を獲得するのに大いに役立つ潜在能力を持っていますが、同時に取り組む必要のある一連の課題とリスクも存在します。最終的に、GenAIOpsは導入組織とLLMを提供するベンダーの両方にまたがる原則と能力を持つ必要があります。スパイダーマンの言葉によれば、偉大な力には偉大な責任が伴います。
人工知能についてもっと学びたい場合は、私の著書「Artificial Intelligence: An Executive Guide to Make AI Work for Your Business」をAmazonでご覧ください。
[1]Sweenor、David、Steven Hillion、Dan Rope、Dev Kannabiran、Thomas Hill、およびMichael O’Connell。2020。ML Ops:データサイエンスの運用化。O’Reilly Media。https://www.oreilly.com/library/view/ml-ops-operationalizing/9781492074663/。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





