「GenAIソリューションがビジネス自動化を革新する方法:エグゼクティブ向けLLMアプリケーションの解説」
GenAIソリューション エグゼクティブ向けLLMアプリケーションのビジネス自動化革新
企業がLLMの力を活用してワークフローを自動化し、コストの効率化を図る方法
イントロダクション
最近、バイオファーマ企業の製造幹部との共同作業において、生成型AI、具体的には大規模言語モデル(LLM)を使用して品質調査の迅速化方法を探りました。品質調査は、製品の製造やテストにおいて逸脱が発見された場合にトリガーされます。患者の健康への潜在的なリスクと規制要件により、バッチは保留され、影響に応じて生産さえ中断される場合があります。できるだけ迅速に原因分析を実施し、是正と予防対策計画を実施するために、調査を加速することが重要です。我々の目的は、GenAIを使用してこのプロセスを可能な限り加速させることでした。
最小限の実行可能製品(MVP)について考え始めた時、GenAIがプロセスの異なる段階を自動化する方法のいくつかの選択肢に直面しました。サイクルタイムを改善し、バッチをできるだけ早く解凍するために、GenAIがどの品質調査プロセスの段階を優先すべきかを決定するために、LLMの能力とさまざまなGenAIソリューションパターンについて詳しく調査する必要がありました。幹部は自分たちの分野の専門家であり、GenAIのトレーニングを受けていました。ただし、MVPのためには、短期的なソリューションの実現可能性とサイクルタイムの予想される改善をバランスさせるために、LLMの機能とさまざまなGenAIソリューションパターンについてさらに詳しく調査する必要がありました。
私たちの場合は特定のプロセスに焦点を当てて議論しましたが、同じソリューションパターンは、業界や機能を横断してコストの効率化と成果の加速化に活用されています。では、どのようにしてGenAIソリューションはそのようなプロセスに役立つのでしょうか?
LLMのユニークな機能
GenAIの人気が急上昇する前、企業界の自動化ソリューションは主にルーチンベースのタスクを対象にしたり、ロボティックプロセスオートメーション(RPA)に依存したりしていました。機械学習の応用は主に、セールスボリュームなどの結果を予測するための回帰モデルを使用するなど、分析に関連していました。しかし、最新のLLMは、次のような注目すべき特性を持っています:
- 「Amazon TextractとAmazon OpenSearchを使用してスマートなドキュメント検索インデックスを実装する」
- 「宇宙で初めて人間由来の体の一部が3Dプリントされました」
- 「AIの成長に伴い、ラスベガスの労働者たちは変化に備える」
- コンテンツ理解:LLMはテキストの意味を「理解」することができます
- 即興トレーニング:LLMは、元々のトレーニングに含まれていなかった新しいタスクを実行できます(ゼロショット学習とも呼ばれ、自然言語の指示といくつかの例文(フューショット学習)によってガイドされます)
- 推論:LLMは、一定の限定とリスクがあるものの、潜在的なアクションを「考え」、「推論」することができます
「従来の」機械学習では、モデルを構築して使用するプロセスは、データを収集し、手動で「ターゲット」を定義し、他の特性が与えられた場合に「ターゲット」を予測するようにモデルをトレーニングすることを一般的に含んでいました。したがって、モデルは特定のタスクを実行したり、特定のタイプの質問に答えたりすることができました。それに対して、事前にトレーニングされたLLMに、LLM自体が以前に見たことも、レビューに明示的に記載されていない重要な側面もない顧客レビューを評価するように尋ねることができます。
LLMベースのソリューションの仕組み
業界の多くのLLMソリューションは、詳細な指示を設計し、LLMが特定のタスクを実行するためにそれらにアクセスできるようにすることを中心に展開しています(これはプロンプトエンジニアリングとして知られています)。LLMの影響を増幅させる有力な方法の1つは、企業の独自情報に自動的にアクセスできるようにすることです。情報取得増強生成(RAG)は、これを実現するための最も一般的なソリューションパターンの1つとして浮上しています。
概要 — 10,000フィートの眺め
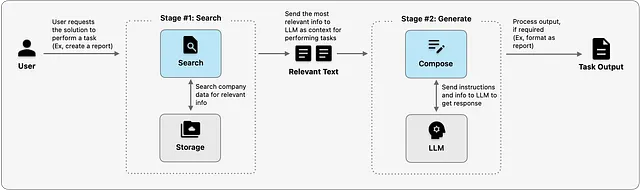
簡単に言えば、このソリューションには2つのステージがあります:
- 検索:ユーザーの要求に関連する企業データを取得します。たとえば、特定の形式やスタイルでレポートを書くように求められた場合、以前のレポートのテキストが取得され、LLMに例として送信されます。
- 生成:前のステージで取得した指示や例(またはその他の関連する情報)をコンパイルし、テキストプロンプトとしてまとめ、望ましい出力を生成するためにLLMに送信します。レポートの場合、プロンプトは次のようになるかもしれません:
提供された例の形式とスタイルを使用して、次の情報をレポートにまとめてください。以下が内容です:[レポートの内容….]。こちらが例です:[前回のレポートのタイトル セクション1… セクション2… 結論]
RAGワークフロー-1000フィートビュー
このソリューションパターンの検索および生成ステージについて少し詳しく見てみましょう。
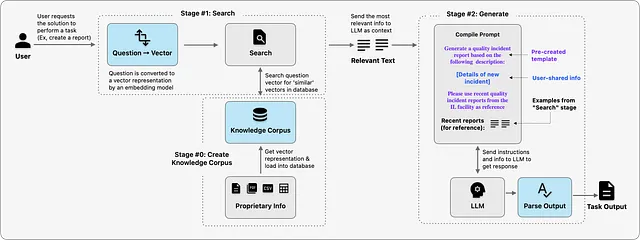
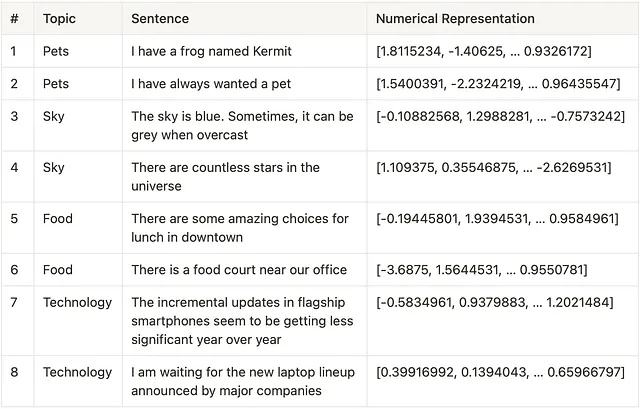
1. ワード埋め込み-言語の「理解」の基盤:自然言語の理解を容易にするために、テキストはアルゴリズムまたはLLMを介して実行され、データの意味と文脈を捉える数値表現(ベクトル埋め込みとして知られる)を取得します。この表現を作成するために使用されるモデルによって長さが決まります。例えば、word2vecなどのモデルは最大で300のベクトル長を持ち、一方、GPT-3は最大12288の長さのベクトルを使用します。例えば、
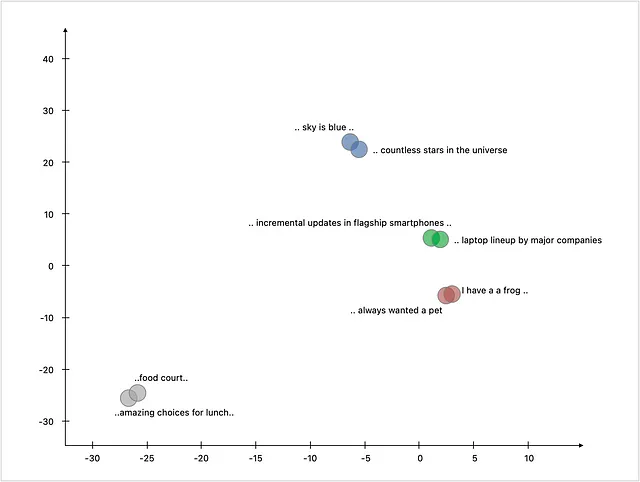
これらの数値表現がどのように二次元空間にマッピングされるかを以下に示します。類似したトピックに関する文が互いに近くマップされることが興味深いです。
2. ナレッジコーパスの作成:ソリューションの検索コンポーネントは、入力された質問を受け取り、セマンティック検索を実行してナレッジコーパス内で利用可能な最も類似した情報を見つけます。では、このナレッジコーパスはどのように作成されるのでしょうか?ナレッジコーパスに含まれるファイルは、埋め込みモデルによって処理され、数値表現が作成されます。これらの数値表現は、このタイプの情報を効率的に保存し、必要な時に迅速に取得するために特別に作られたベクトルデータベースにロードされます。
3. ナレッジコーパス内の類似情報の検索(リトリーバル):ユーザーがソリューションに質問またはタスクを送信すると、ソリューションは埋め込みモデルを使用して質問テキストを数値表現に変換します。この質問ベクトルは、ナレッジコーパス内で最も類似した情報を見つけるために使用されます。返される検索結果は1つ以上あり、次のステージに渡して応答または出力を生成することができます。
4. LLMを使用した出力の生成(ジェネレーション):LLMが意味のある出力を生成できるように関連する情報を見つけることに成功したソリューションは、LMMに送信することができる「プロンプト」として知られるパッケージ全体を送信することができます。このプロンプトには、LLMをガイドする1つ以上の標準的な指示セット、実際のユーザーの質問、および検索ステージで取得した情報の断片が含まれます。ユーザーに返される前に、LLMからの出力は必要に応じて処理されることがあります(たとえば、特定の形式でのワードドキュメントへの出力のロードなど)。
ソリューションコンポーネントの詳細な調査
ソリューションのコンポーネントについてもう少し詳しく見てみましょう

1. ナレッジコーパスの作成: 関連する文書をナレッジコーパスに読み込む場合には、いくつかのニュアンスがあり、いくつかの考慮事項が関わります。
- 文書の読み込み: 異なる関連文書(pdf、ワード、オンラインソースなど)をデータリポジトリにインポートする必要があるかもしれません。使用ケースによっては、一部の文書の一部のセクションのみが関連する場合もあります。たとえば、金融アナリストが企業の10-K報告書をクエリするためのソリューションでは、タイトルページ、目次、規制遵守情報、および一部の展示物などは金融分析には関係ない可能性があります。したがって、これらのセクションはナレッジバンクから省略することができます。LLMモデルから多様で高品質な応答を得るために、ナレッジバンクに冗長な情報を避けることが重要です。
- 文書の分割: ナレッジバンクに含めるために関連する文書のセクションが特定されたら、次のステップはこの情報をどのように分割し、ベクトルデータベースに読み込むかを決定することです。使用ケースによって選択肢は異なる場合があります。効果的なアプローチは、一部のオーバーラップを持つ段落ごとに分割することです。これには、段落全体を保持するための単語(またはテキスト処理に使用されるLLMの単位である「トークン」)の制限を設定することが含まれます。もし段落がこの制限を超える場合は、ベクトルデータベースのために複数のレコードに分割する必要があります。通常、文脈を保持するためにいくらかの単語のオーバーラップが意図的に維持されます。たとえば、1つのベクトルあたりの単語制限を1,000単語で40単語のオーバーラップを使用する場合などです。
- 追加のメタデータ: ナレッジバンクの情報を向上させるために、各レコードに意味のあるメタデータをタグ付けすることが含まれます。基本的なメタデータの例には、情報が抽出された元の文書のタイトルやセクションの階層が含まれます。追加のメタデータは検索と取得の品質をさらに向上させることができます。たとえば、10-K報告書から抽出された貸借対照表データには以下のようなメタデータが付けられるかもしれません:
元の文書のタイトル: 会社XYZの10-K年: 2022セクション: 財務諸表および補足データ | 貸借対照表
- ストレージ: 情報を保存するためにはさまざまな利用可能なオプションがあります。ベクトルデータベースのソリューション(例: Chroma、またはPostgres/MySQLの上に構築されたFaiss)を使用することができます。ただし、SQLデータベース、NoSQLデータベースまたはドキュメントストア、グラフデータベースも使用することができます。また、レイテンシを減少させるためのインメモリストレージやスケーラビリティ、可用性、負荷分散の向上のための水平スケーリングの可能性もあります。
2. ナレッジコーパスから類似情報を検索する(検索): 簡単な使用ケースの場合、前のセクションで説明したように、ナレッジバンク内の類似ベクトルを検索するアプローチで十分です。検索の速度と精度のバランスを取るために、一般的な二段階アプローチが使用されます:
- 密な検索: 初めに、検索クエリに対して高速な近似最近傍探索を使用して広範なナレッジコーパスをスキャンします。これにより、さらなる評価のために数十または数百の結果が得られます。
- 再ランキング: 取得した候補の中から、より計算集約型のアルゴリズムを使用してより関連性の高い結果とそれ以外の結果を区別することができます。追加の関連性スコアは、密な検索ステージで取得した候補に対して二度目のパスを取るか、リンク数(信頼性やトピックの権威性を示す)やTF-IDFスコアなどの追加の特徴量を使用するか、またはすべての候補をLLMに確認して関連性に基づいてランク付けすることによって計算されることがあります。
多様な情報を選択して検索結果の品質を向上させるための高度な機能、平易な自然言語のユーザープロンプトに基づくフィルタの適用など、より洗練されたアプローチが必要な場合もあります。たとえば、ユーザーが「Company XYZの2020年の純利益はいくらでしたか?」という金融クエリの場合、ソリューションはCompany XYZと2020年の文書をフィルタリングする必要があります。1つの可能な解決策は、LLMを使用してリクエストを2020年のメタデータでフィルタリングするフィルタリングコンポーネントに分割し、ナレッジバンク内で「Company XYZの純利益」を見つけるためにセマンティック検索を実行することです。
3. LLMを使用して出力を生成する(生成): プロセスの最終ステップは、LLMを使用して出力を生成することです。
- 直接アプローチ: 簡単なアプローチは、検索ステージから取得したすべての情報をLLMに渡し、人間のプロンプトと指示とともに処理することです。ただし、LLMに渡すことができる情報の量には制限があります。たとえば、Azure OpenAIベースのGPT-4モデルは、1024トークンのコンテキストサイズを持ち、おおよそテキスト2ページに相当します。使用ケースによっては、この制限に対する回避策が必要になる場合があります。
- チェーン: コンテキストサイズの制限を回避するための1つのアプローチは、情報の一部を順次言語モデルに提供し、それを使って回答を構築し、改善するように指示することです。LangChainフレームワークでは、「refine」、「map_reduce」、「map_rerank」などのメソッドを提供して、言語モデルを使用して回答の複数のパーツを生成し、別のLLM呼び出しを使用してそれらを最終的に結合することを容易にします。
結論
データ生成がエスカレートする時代において、GenAIの力を活用することはこれまでにないほど効果的です。この記事で説明されている解決策パターンは、データ処理の自動化と人的リソースの解放により、より複雑なタスクに取り組むことが可能です。大規模言語モデル(LLM)の商業化の進展とソリューションコンポーネントの標準化により、このようなソリューションは近い将来、広く普及することが予想されます。
よくある質問(FAQ)
- 生成されたコンテンツはLLMのメモリの一部となり、将来の出力の品質に影響しますか?例えば、経験の浅いユーザーが生成した悪い出力は他のユーザーの出力品質に影響しますか?いいえ。この解決策では、LLMは生成した内容を「記憶」していません。各リクエストはクリーンな状態から開始されます。LLMが微調整(さらなるトレーニング)されるか、生成された出力が知識ベースに追加される場合を除き、将来の出力には影響を与えません。
- LLMは使用することで学習し、より良いものになりますか?自動的にはありません。RAGソリューションパターンは強化学習システムではありません。ただし、ユーザーが出力の品質にフィードバックを提供できるようにすることで、モデルを微調整することが可能です。知識ベースの更新やアップグレードされたLLMの使用により、ソリューションの出力品質を向上させることもできます。
- ベクトル埋め込みはソースデータウェアハウスに保存されますか?一般的には保存されません。ドキュメントのチャンクのベクトルは理論的にはソースデータウェアハウスに保存することができますが、ソースデータウェアハウスの目的とベクトルデータベース(またはソリューション用に明示的に使用されるSQLデータベース)の目的は異なります。ベクトルをソースデータベースに追加すると、運用上の依存関係やオーバーヘッドが発生する可能性があり、必要でなく報酬にもなりません。
- 新しいデータでソリューションを更新する方法は?データのローディングパイプライン(ロードするドキュメントの特定、処理、チャンキング、ベクトル化、ベクトルデータベースへのロード)を新しいデータが利用可能になるたびに実行する必要があります。これは定期的なバッチプロセスになることができます。更新の頻度はユースケースに合わせることができます。
- ナレッジベースに格納されたドキュメントの機密情報が一般の人やLLMのベンダーにアクセス可能にならないようにするにはどうすればよいですか?企業はAzure OpenAIサービスを使用して、OpenAIのLLMのプライベートインスタンスとしてシングルテナントのソリューションを利用することができます。これにより、データのプライバシーとセキュリティが確保されます。別のソリューションとして、Hugging FaceのLLMを会社のプライベートインフラストラクチャに展開することで、データが企業のセキュリティ範囲外に出ないようにすることができます。
おすすめのリソース
LLMとその応用について深く理解するために、以下のリソースを探索してみてください:
- Generative AI Defined: How It Works, Benefits and Dangers (techrepublic.com)
- What Business Leaders Should Know About Using LLMs Like ChatGPT (forbes.com)
RAGソリューションパターンの詳細を知るには、以下のリソースを参照してください:
- Question answering using Retrieval Augmented Generation with foundation models in Amazon SageMaker JumpStart | AWS Machine Learning Blog
- Deeplearning.ai course: Large Language Models With Semantic Search
- Deeplearning.ai course: LangChain: Chat with Your Data
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






