あなたのGen AIプロジェクトで活用するための10のヒントとトリック
Gen AIプロジェクト活用のための10のヒントとトリック
本番用ジェネレーティブAIアプリケーションからの教訓
本番で使用されているジェネレーティブAIアプリケーションは、現在のところあまりありません。それは、それらがデプロイされ、エンドユーザーによって積極的に使用されていることを意味します。(デモ、POC、およびエキストラクティブAIはカウントされません。)本番で使用されるGen AIアプリケーション(例:Google WorkspaceのDuet、SalesforceのEinstein GPTによる営業メール作成)はクローズドソースであり、それゆえにそれらから学ぶことはできません。
そのため、defog.aiが、彼らの顧客のジェネレーティブAIワークフローを自動化する一環として使用しているNLP-to-SQLモデルであるSqlCoderをオープンソース化したときには興奮しました。彼らはまた、彼らのアプローチと思考を詳細に説明した一連のブログ投稿も書きました。これにより、具体的な例を指摘できます。

この記事では、SqlCoderを使用して、独自のGenAIプロジェクトで行うことができる具体的な例を紹介します。
1. 生成されたテキストの使用方法に基づいて計算される評価指標を考案する。
従来の機械学習と同様に、LLMの最適化に使用される損失指標は、その実世界での有用性を捉えていません。分類モデルは交差エントロピー損失を使用してトレーニングされますが、AUM/Fスコアなどのメトリクスを使用して評価されるか、偽陽性に経済的なコストを割り当てるなどの方法で評価されます。
同様に、基礎となるLLMはBLEUやROUGEなどのメトリクスを最適化するためにトレーニングされます。これらはすべて、生成されたテキストとラベルのトークンのオーバーラップを測定するだけです。明らかに、これはSQL生成には適していません。ラベル「SELECT list_price」と生成されたテキスト「SELECT cost_price」は特に近くありません(LLMのトークンはサブワードですので、ここでは2つの文字列の違いはわずか1つのトークンです)。
defogがこの問題を解決する方法は、彼らが評価方法について説明したこのブログ投稿で説明されています。基本的に、SQLの文字列を直接比較する代わりに、生成されたSQLを小さなデータセットで実行し、結果を比較します。これにより、ラベルと同じことを行う限り、同等のSQLを受け入れることができます。ただし、列のエイリアスが異なる場合はどうなりますか?結果の順序外れをどのように扱いますか?生成されたSQLがラベルのスーパーセットの場合はどうなりますか?多くの特殊なケースやニュアンスを考慮する必要があります。この具体的な問題に興味がある場合は、彼らの評価に関するブログ投稿を読んでください。しかし、大きなポイントは、すべての種類のGen AIの問題に対して有効です。すなわち、生成された文字列ではなく、生成された文字列の使用方法に基づいて計算される評価指標を考案することです。
多くの研究論文では、LLM(通常はGPT-4)を使用して生成されたテキストを「スコアリング」し、これをメトリクスとして使用しています。これは適切な評価指標を考案するほど良い方法ではありません。LLMのスコアはGPTアルゴリズムに強く偏っており、多くのスマートな最適化に対しては不利です。また、Open AIはAIによって生成されたテキストを検出しようとしたサービスを停止せざるを得なかったことを覚えておいてください。彼らがLLMによって生成されたスコアを動作させることができなかったので、なぜあなたができると思いますか?
2. 実験のトラッキングをセットアップする
何をする前に、実験の記録を保持し、結果を共有するシステムを確立してください。多くの実験を行い、試したすべてをキャプチャすることが重要です。
これは、以下の列を持つスプレッドシートのようにシンプルなものであるかもしれません。実験、実験記述子(アプローチ、パラメータ、データセットなど)、トレーニングコスト、推論コスト、メトリクス(サブタスクごとにスライス)、定性的なメモ。または、Vertex AI、Sagemaker、neptune.ai、Databricks、Datarobotなどに組み込まれたML実験トラッキングフレームワークを活用するなど、より複雑なものにすることもできます。
チームのすべてのメンバーで繰り返し可能で一貫性のある方法で実験を記録していない場合、下流の意思決定をするのは難しいでしょう。
3. 問題をサブタスクに分解する
タスクごとにデータセットをサブセットに分割して評価を行いたいことがよくあります。たとえば、defogがさまざまなタイプのクエリに対するパフォーマンスを報告しているのを見てください:
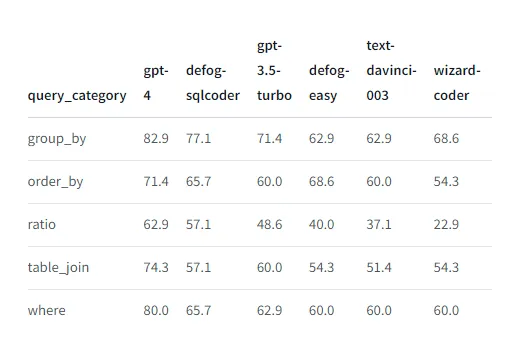
サブセットの評価を行う理由は次の3つあります:
- モデルのサイズ、パフォーマンス、コストの間には制約が生じる可能性があります。その場合、異なるサブタスクに合わせてチューニングされた複数のMLモデルを持つことで制約を打破することができます。多くの人々は、GPT-4自体がGPT 3.5品質のモデルのアンサンブルであると考えています。(ちなみに、これは個々のLLMがGPT-4に対して不利な結果を残す理由の1つです。それを打ち破るためには、モデルのアンサンブルを構築する必要があります。)
- 複数の利害関係者がいる場合、それぞれが異なることに興味を持つかもしれません。その場合、各目標に対応するメトリクスを考案し、追跡する必要があります。これらの異なる目標をサブタスクとして扱い、追跡を開始します。おそらく、各利害関係者ごとにモデルを作成する必要があります。これらのモデルをアンサンブルのメンバーとして扱うことができます。
- サブタスクのスライス評価を行う第三の理由は、ML評価のゴールドスタンダードは人間の専門家のパネルに提示することです。しかし、それはあまりにも高価です。ただし、人間の評価を行う場合は、後で計算されたメトリクスを使用して人間の評価を「予測」できるようにするようにしてください。問題のさらなる属性を持つことは、そのようなキャリブレーションを行うのに役立ちます。
4. プロンプトエンジニアリングのトリックを適用する
Gen AIを使用するすべてのアプローチは、訓練されたLLMにテキストプロンプトを送信することを最終的に必要とします。コミュニティは時間の経過とともに、良いプロンプトを作成するためのさまざまなヒントやトリックを学んできました。通常、LLMのドキュメントにはうまく機能する方法が記載されています(例:OpenAI Cookbook、Lllama2、Google PaLM)- これらを読んで、提案されるテクニックを使用するようにしましょう!
defogのプロンプトは次の通りです:
prompt = """### Instructions:Your task is convert a question into a SQL query, given a Postgres database schema.Adhere to these rules:- **Deliberately go through the question and database schema word by word** to appropriately answer the question- **Use Table Aliases** to prevent ambiguity. For example, `SELECT table1.col1, table2.col1 FROM table1 JOIN table2 ON table1.id = table2.id`.- When creating a ratio, always cast the numerator as float### Input:Generate a SQL query that answers the question `{question}`.This query will run on a database whose schema is represented in this string:CREATE TABLE products ( product_id INTEGER PRIMARY KEY, -- Unique ID for each product name VARCHAR(50), -- Name of the product price DECIMAL(10,2), -- Price of each unit of the product quantity INTEGER -- Current quantity in stock);CREATE TABLE customers ( customer_id INTEGER PRIMARY KEY, -- Unique ID for each customer name VARCHAR(50), -- Name of the customer address VARCHAR(100) -- Mailing address of the customer);...-- sales.product_id can be joined with products.product_id-- sales.customer_id can be joined with customers.customer_id-- sales.salesperson_id can be joined with salespeople.salesperson_id-- product_suppliers.product_id can be joined with products.product_id### Response:Based on your instructions, here is the SQL query I have generated to answer the question `{question}`:```sql"""これにはいくつかのトリックがあります:
- タスク入力。前文(「Your task is to… SQL … Postgres database …」など)はタスク入力と呼ばれます。これはLLMのトレーニング段階の指示モデルの入力です。基本的に、LLMはテキスト補完マシンです。言葉の空間の正しいセクターで単語の確率を上げるためにできることは何でも役立ちます。そのため、前文がLLMを興味のある単語の領域に誘導する場合、多くのLLMはよりよく動作します。defogの前文でSQL、Postgresなどの単語を使用することが重要です。
- システムプロンプト。ルール(「質問とデータベーススキーマを単語ごとに逐次処理し、テーブルのエイリアスを使用して曖昧さを防ぐなど」)はシステムプロンプトと呼ばれます。これは動作をガイドし制約するために使用されます。(defogチームに対する私の提案は、「Adhere」のような10ドルの言葉は避けて、「Always」や「Never」のような10セントの言葉を使用することです。これらの方がより良く機能する傾向があります。)LLMはシステムプロンプトに従うようにトレーニングされています(これにより、有害な振る舞いなどに対処できます)。それらを自分の利益に活用しましょう。
- コンテキストの始まりと終わり。回答する質問は2回現れます。1つは入力のセクションで、もう1つは応答のセクションです。これらの配置- 始まりと終わりに- は偶然ではありません。特にプロンプトが非常に長い場合、LLMはコンテキストの中間部分の重みづけを低く評価する傾向があります。重要なものを始まりと終わりに配置してください。繰り返しは助けになる場合があります(効果があるかどうかを実験してみてください)。
- 構造化入力。LLMの重みは、各「head」と関連する注意機構によって変更されます。そのため、**Input**のような一貫性のあるユニークなトークンシーケンスを使用すると、LLMに続く単語を異なる方法で使用するようにトレーニングすることができます。
- コンテキスト内のルール(?)。defogは、他の列と結合できる列のルールに関するセクションを持っています。このルールを入力コン
さて、Google Workspace Duetでは、#7と#8を確認することができます。バグが修正されていない限り、コンテキストよりも長い段落を選択し、要約を求めてみてください。結果には「Instruction」という単語が含まれます。これはシステムプロンプトの一部です。それを見ることができるのは、出力を示す特殊文字が応答に存在しなかったためです。LLMの赤チームハッキングでは、応答を過剰に詰め込むことから始まります。切り詰めによって多くのバグや予期しない動作が露呈します。
5. アーキテクチャーに異なるアプローチを知恵よく組み合わせる
ジェネレーティブAIの上に構築するための5つのアプローチがあります:
- ゼロショット:単純にLLMにプロンプトを送信します。LLMの訓練データに完全に依存しています。
- フューショット:コンテキストに1〜2の例と応答を含めます。これらの例は固定されているか、クエリに最も関連する例に基づいて取得される場合があります。これは通常、LLMをガイドする方法であり、新しい情報や新しいタスクを教えるものではありません。
- 検索付き生成(RAG):類似検索に基づいて通常はベクトルデータベースから関連データを取得し、コンテキストに含めます。これはLLMに新しい情報を教える方法です(現在のLLMはRAGを使用して新しいスキルを学習することはできません)。
- ファインチューニング。通常、パラメータの効率的な方法で(PEFT)行われ、低ランク適応(LoRA)アプローチを使用して、LLMの重みを変更する別のニューラルネットワークのトレーニングを行い、LLMが新しいタスクを処理できるようにします。ファインチューニングではLLMに新しい情報を学習させることはできません。
- エージェントフレームワーク。LLMに外部APIに渡すパラメータを生成させます。これにより、LLMにスキルと知識を追加することができますが、人間が介在しない場合は危険です。
ご覧のように、各アプローチにはそれぞれの利点と欠点があります。したがって、defogはこれらのアプローチをいくつか組み合わせています。最終的に彼らは#5(データベースに送信されるSQLを生成する)を行っていますが、SQLを人間のユーザーによってガイドされる複雑なワークフローのパスに置いています。クエリに基づいて必要なスキーマと結合規則(#3)を取得します。彼らは効率的にコストを管理するために小さなモデルをファインチューニング(#4)しました。そして、彼らはゼロショットの方法でファインチューニングされたモデルを呼び出しています(#1)。
このようなアプローチの知恵よい組み合わせは、異なるアプローチの利点を最大限に活用し、それらの弱点に対抗するために必要です。
6. データセットの整理と整理
Gen AIでは、データの量と品質の両方が重要であることが明確になっています。Defogは、カスタムモデルをファインチューニングするために10,000のトレーニング例を得ることを目標にしました(おそらく各顧客ごとにモデルをファインチューニングしています:サブタスクに関する前の議論を参照)。彼らの努力の大部分は、データセットのクリーンアップに費やされます。
データセットが最適であることを確認する際のクイックチェックリストは次のとおりです:
- 正確性。ラベルがすべて正しいことを確認します。Defogは、実行して生成されたテキストから作成されたデータフレームと比較できるSQLが必要なことを確認しました。
- データのキュレーション。Platypusは、トレーニングデータセットから重複を削除したり、グレーエリアの質問を削除するなど、Llama2を改善することができました。
- データの多様性。10,000の例を賢く使用し、LLMに本番で見ることになるもののさまざまな側面を示すことが重要です。Platypusが多くのオープンデータセットを使用する方法や、defogが1つのテーブルセットだけでなく10個の別々のスキーマセットでトレーニングする方法に注目してください。
- Evol-instruct。「教科書だけが必要です」という論文は、難易度の増加順にシンプルな例を選ぶことの重要性を示しています。defogは、一連の指示をより複雑なものに適応させるためにLLMを使用します。
- 例に難易度レベルを割り当てる。トレーニングデータセットを難易度ごとにセグメント化することが有用な場合がたくさんあります。スライスされた評価指標(Tip #3を参照)、より簡単なタスクに対してより単純なモデルをトレーニング、効果的なアンサンブルメカニズムとして使用、段階的な難易度でモデルを教えるなどに利用できます。
これまでで最も大きなパフォーマンス向上をもたらすヒントです。
7. ビルド対購入はケースバイケースで決定する
大きなモデルは運用コストが高くなります。選別されたデータセットでより小さなモデルを微調整することで、競争力のある結果を得ることができます。これらのコストは1/10以下になることもあります。さらに、微調整されたモデルはオンプレミスやエッジなどで運用することができます。ROIを計算する際には、モデルの所有に伴う財務的・戦略的なメリットを無視しないでください。
ただし、Open AIのGPT-4は初期設定で優れたパフォーマンスを提供することが多いです。Open AI APIを呼び出す規模を予測できる場合、本番でのコストを見積もることができます。リクエストの数が少ない場合、開発コストの問題から微調整は財務的に合理的ではありません。微調整のアプローチを開始しても、最先端のモデルとベンチマークを行い、必要に応じてアプローチを変更する準備をしておいてください。
必要なすべてのものにカスタムモデルを作成する余裕はないでしょう。購入したモデルと自作のモデルの組み合わせが一般的です。常にビルドするか常に購入するかという罠にははまらないでください。
8. 具体的なLLMを抽象化する
OpenAIは唯一の選択肢ではありません。Googleは、彼らの今後のGeminiモデルがGPT-4よりも優れているとほのめかしています。数ヶ月ごとに新しい最先端のモデルが登場するという状況になる可能性があります。あなたの評価のミックスには、この記事を読む時点で最先端のモデル(GPT-4、Gemini、またはGPT-5)が含まれるべきです。ただし、CohereやAnthropicなどの近い最先端モデルや、GPT 3.5やPaLM2などの以前の世代のモデルとのパフォーマンスやコストを比較することも重要です。
どのLLMを購入するかは主にビジネスの決定です。パフォーマンスのわずかな違いは、コストの大きな違いにはほとんど値しないことが多いです。複数のオプションのパフォーマンスとコストを比較してください。
langchainを使用してLLMを抽象化し、実験フレームワークでコストと利益を捉えることが重要です。これにより、効果的な交渉ができるようになります。
9. APIとして展開する
「小さな」13GBのパラメータを微調整したLLMでも、読み込みに時間がかかり、GPUのバンクが必要です。内部ユーザーにもAPIとして提供し、ゲートウェイサービスを使用して計測と監視を行ってください。
エンドユーザーがアプリケーションプログラマーの場合は、APIインターフェースを文書化し、異なるプロンプトをサポートする場合はそれらを文書化し、特定のプロンプトを使用する下流のワークフローが壊れないようにユニットテストを提供してください。
エンドユーザーが非技術者の場合、APIだけでは不十分です。defogが示すように、streamlitなどを使用してサンプルクエリ(「チップス」)を使用したプレイグラウンドインターフェースを提供することが良いアイデアです。また、エンドユーザーがML開発者の場合は、プレイグラウンド機能にHuggingFaceを使用してください。
10. トレーニングを自動化する
微調整パイプラインが完全に自動化されていることを確認してください。
通常のクラウドMLプラットフォームに使用しているハイパースケーラーをデフォルトにしてくださいが、コストを計算し、リージョンでのGPU/TPUの利用可能性を確保してください。また、スポットインスタンスを使用したり、独自のハードウェアを所有したり、他の人の資金を使用しているため、大手クラウドプロバイダーよりもコスト効果が高い場合がある「LLMops」を提供するいくつかのスタートアップもあります。
ここで選択肢を保持する良い方法は、パイプライン全体をコンテナ化することです。これにより、(再)トレーニングパイプラインをGPUがある場所に簡単に移植できます。
まとめ

参考文献
- https://defog.ai/
- SqlCoder: https://defog.ai/blog/open-sourcing-sqlcoder/
- SQL評価メトリック: https://github.com/defog-ai/sql-eval
- 基盤モデルは人間と同じようにデータをラベル付けできるのか https://huggingface.co/blog/llm-leaderboard
- OpenAIクックブック、Lllama2、Google PaLM
- Lost in the middle: how language models use long contexts. https://arxiv.org/abs/2307.03172
- Platypus AI: https://www.geeky-gadgets.com/platypus-ai/
- WizardLMからのEvol-Instruct: Empowering Large Language Models to Follow Complex Instructions. https://arxiv.org/abs/2304.12244
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





