「生データから洗練されたデータへ:データの前処理を通じた旅 – パート2:欠損値」
From Raw Data to Refined Data Journey through Data Preprocessing - Part 2 Missing Values
この記事を読む前に、特徴量エンジニアリングに関するシリーズの前の記事をご覧ください。
生データから洗練されたデータへの旅:データ前処理の一環としての特徴スケーリング — パート1
時には、機械学習のタスクに適した形式で提供されないデータもあります…
pub.towardsai.net
欠損値を扱う理由はなんですか?
ほとんどの現実のデータセットには、少なくともいくつかの欠損値が含まれています。しかし、Scikit-Learnの推定器はそのようなデータでは動作しません。したがって、Scikit-Learnの推定器の要件と互換性のあるデータにするためには、データ内の欠損値を処理する必要があります。
- ジオスペーシャルデータ分析のための5つのPythonパッケージ
- システムエンジニアからデータアナリストへのキャリア転換
- 「Jupyter AIに会おう Jupyterノートブックで人工知能の力を解き放つ」
欠損値を持つデータレコードを完全に削除することは良いアイデアではありませんか?
欠損値を扱うことはデータの前処理の重要な部分です。しばしば、欠損データは削除されるか、補完されてこの問題を処理します。しかし、データセットが小さい場合、欠損値を完全に削除することは常に最良の解決策ではありません。このアプローチではデータセットのサイズがさらに減少する可能性があります。さらに、欠損データはデータ収集中に特定の条件が存在したため存在する場合もありますし、特定のパターンで欠損データが存在する場合もあります。したがって、欠損データを処理するための代替手法を考慮することが重要です。
例を挙げて説明しましょう。大学生を対象に調査を行っており、そのうちの一つの質問は体重に関するものです。このシナリオでは、一部の女性学生は社会的な期待により、自分の体重を公開することに不快感を抱くかもしれません。その結果、女性参加者の間で体重の回答が多く欠損していることがあります。これは特定のパターンに従う欠損データの例です。
さらに、調査から別のシナリオを見てみましょう。筋力や腕力に関連する質問をすると、多くの大学生男子が回答をためらうかもしれません。これは自分の身体能力や力に対して自意識を持っているためかもしれません。その結果、男性参加者から多くの回答が欠損する可能性があります。
したがって、ほとんどの場合、欠損値を持つレコードを削除することは良いアイデアではありません。これは、このようにすることでデータに存在する有用な情報を失う可能性があるためです。欠損値を処理するより洗練された方法は、他の欠損していないデータから得られた値で欠損データのギャップを埋めることです。
欠損値を持つ列を削除することは、大きなデータではまだまともな精度を得ることができます。では、コードを使用してこれをどのように行うか見てみましょう。
欠損値の問題を、欠損値を含む特徴量を削除することで解決する方法
デモンストレーションのために、KaggleからMelbourne Housing Snapshotデータセットを使用します。単純にするために、データの数値特徴量のみを使用します。
## 必要なライブラリのインポートimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.tree import DecisionTreeRegressorfrom sklearn.metrics import mean_absolute_errorfrom sklearn.experimental import enable_iterative_imputerfrom sklearn.impute import SimpleImputer, IterativeImputer, KNNImputerimport warningswarnings.filterwarnings('ignore')
## データの読み込みdf = pd.read_csv('データのパス')## データの基本情報の確認df.info()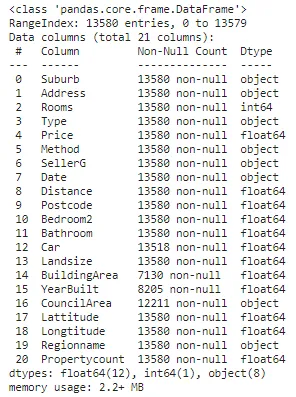
## 数値とカテゴリ特徴量の名前を見つけるnum_feat = [feature for feature in df.columns if df[feature].dtypes != 'O']cat_feat = [feature for feature in df.columns if feature not in num_feat]print(f"数値特徴量: {num_feat}.\n")print(f"カテゴリ特徴量: {cat_feat}.")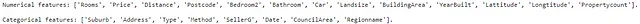
## データを依存特徴量('Price')と独立特徴量X、yに分割する
X, y = df.drop('Price', axis=1), df['Price']
## 簡単のため、データからカテゴリ特徴量を削除する
X.drop(cat_feat, axis=1, inplace=True)
X.info()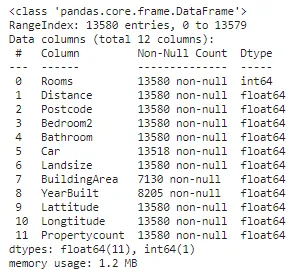
## データを訓練データと検証データに分割する
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2, random_state=0)
## 各特徴量の欠損値の数をチェックする
missing_values_df = pd.DataFrame()
missing_values_df['Features'] = X_train.columns
missing_values_df['Number_of_missing_values'] = X.isnull().sum().to_numpy()
missing_values_df['Percentage_of_missing_values (%)'] = missing_values_df['Number_of_missing_values'].apply(lambda x: np.round((x/X_train.shape[0])*100),2)
missing_values_df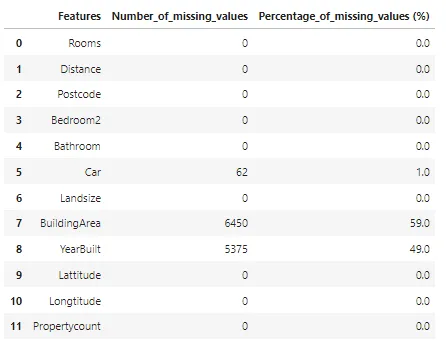
楽しみのために、データの欠損値を可視化しましょう。
import missingno as msgnmsgn.matrix(X_train)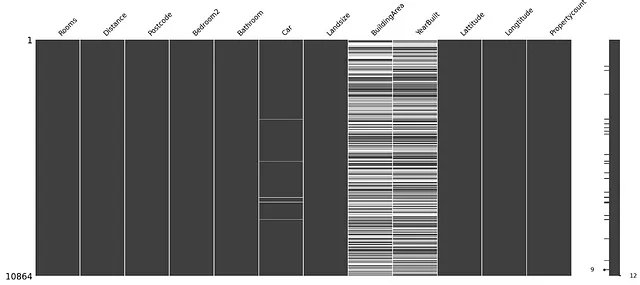
上記の図では、白い線は欠損値を表し、黒い線は欠損していない値を表します。
上記の図から、Car、BuildArea、YearBuiltという特徴量に欠損値が含まれていることが分かります。
次に、欠損値の処理方法の評価を行うための関数を作成しましょう。欠損値を補完したデータで回帰器を訓練し、その平均絶対誤差値を評価します。
# 異なるアプローチを比較するための関数
def score_dataset(X_train, X_valid, y_train, y_valid):
model = RandomForestRegressor(n_estimators=10, random_state=0)
model.fit(X_train, y_train)
preds = model.predict(X_valid)
return mean_absolute_error(y_valid, preds)最後に、欠損値を持つ特徴量を削除しましょう。
# 欠損値のある列の名前を取得する
cols_with_missing = [col for col in X_train.columns
if X_train[col].isnull().any()]
# 訓練データと検証データから列を削除する
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print(f"欠損値の列を削除するアプローチのMAE: {np.round(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid),2)}")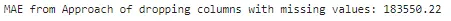
欠損値の問題に対処する別のアプローチは、欠損値をある値で埋めることです。
欠損値を補完する方法
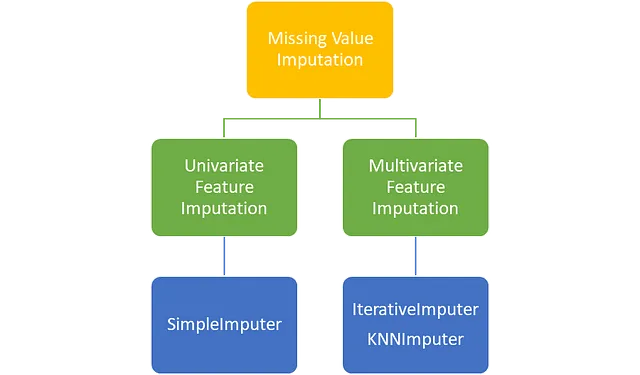
Scikit-Learnライブラリのクラスを使用して、欠損値を補完する方法は主に2つあります。それは、単変量特徴の補完と多変量特徴の補完です。
単変量特徴の補完では、補完に必要な値は単一の特徴量のデータを使用して計算されます。たとえば、体重の列の欠損値を補完する場合、体重列の非欠損値を使用して補完の値が計算されます。
多変量特徴の補完では、補完に必要な値は複数の特徴量のデータを使用して計算されます。たとえば、体重列の欠損値を補完する場合、身長や上腕のサイズなどの他の列の非欠損値も使用することができます。
単変量特徴補完
Scikit-LearnのSimpleImputerクラスを使用して、単変量特徴補完を実行します。SimpleImputerクラスを使用すると、欠損値を選択した定数値または平均、中央値、または同じ列の非欠損データの最頻値などの統計値で置き換えることができます。
SimpleImputerのパラメータ
Scikit-LearnのSimpleImputerには、missing_values、strategy、fill_value、およびadd_indicatorという4つの重要なパラメータがあります。
missing_values: このパラメータは、データ内の欠損値のプレースホルダを示します。通常、numpy.nanとして設定されます。
strategy: このパラメータは、補完に使用される戦略を示します。SimpleImputerクラスには、mean、median、most_frequent(モード)、およびconstantの4つの戦略があります。
fill_value: strategy = ‘most_frequent’の場合、fill_valueパラメータに定数値を割り当てる必要があります。
add_indicator: このパラメータは、欠損値がある種のパターンを示す場合に便利です。add_indicator = Trueの場合、欠損値を含む各列ごとに新しい列が作成されます。新しい列ごとに、元の列で欠損値が見つかるインデックスには値1が、それ以外の場所には値0が配置されます。
SimpleImputerコードデモンストレーション
では、SimpleImputerクラスを使用して補完を行う方法を見てみましょう。
si = SimpleImputer(missing_values=np.nan, strategy='mean', add_indicator=True)print(f"X_trainの欠損値補完前のデータ:\n\n {X_train.head()}\n\n")print(f"欠損値補完前のX_trainの列名:\n\n {X_train.columns.values}\n\n")filled_X_train = pd.DataFrame(si.fit_transform(X_train), columns=si.get_feature_names_out())filled_X_valid = pd.DataFrame(si.transform(X_valid), columns=si.get_feature_names_out())print(f"X_trainの欠損値補完後のデータ:\n\n {filled_X_train.head()}\n\n")print(f"欠損値補完後のX_trainの列名:\n\n {filled_X_train.columns.values}\n\n")print(f"SimpleImputerを使用した補完手法のMAE: {np.round(score_dataset(filled_X_train, filled_X_valid, y_train, y_valid),2)}")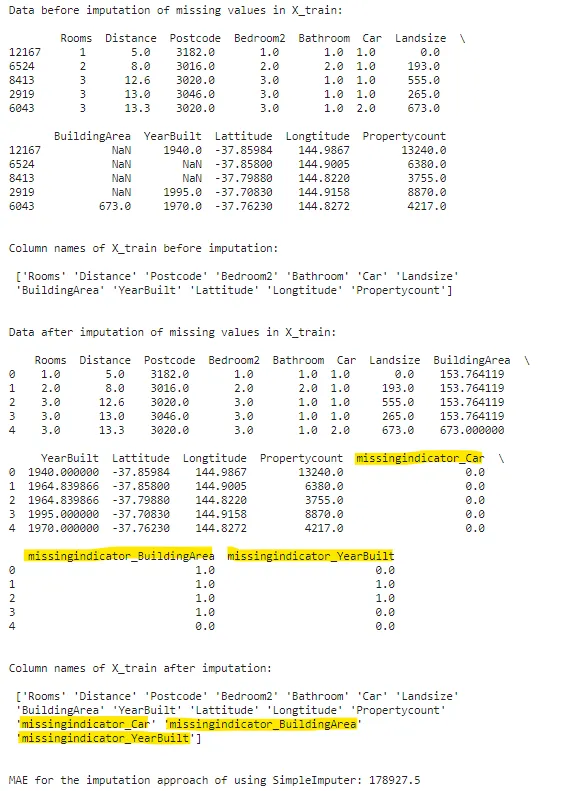
なお、補完後のデータセットには3つの追加の列(黄色でマーキング)が追加されていることに注意してください。add_indicator = Trueに設定したため、元々欠損値があった3つの列があり、それぞれの列内の欠損値パターンを保持するために、3つの新しい列が作成されました。
どの戦略を使用するか
また、SimpleImputerに関連するもう一つの重要な要素は、どの戦略を使用するかを把握することです。戦略は主にデータのタイプとデータ内の外れ値の存在に基づいています。
strategy = ‘mean’は、データが数値であり、外れ値がない場合に使用されます。
strategy = ‘median’は、データが数値であり、外れ値がある場合に使用されます。
strategy = ‘most_frequent’は、カテゴリカルデータに使用されます。
strategy = ‘constant’は、データがカテゴリカルであるか、欠損値をカスタム値で埋めたい場合に使用されます。
多変量特徴補完
Scikit-Learnの多変量特徴補完には、IterativeImputerとKNNImputerの2つの選択肢があります。
まず、IterativeImputerについて理解しましょう。
IterativeImputer
この推定器は現在実験的な状態ですので、IterativeImputerを使用したコードは将来的に破損する可能性があります。
IterativeImputerでは、欠損値を持つ特徴を従属特徴とし、他のすべての列を独立特徴として考えます。その後、従属特徴の欠損値を持たない値で回帰器をトレーニングします。トレーニングされたモデルは、従属列内の欠損値を予測します。これは、欠損値を含む各列に対して繰り返されます。
これをより明確に理解するために、次の例を見てみましょう。トレーニングデータとテストデータが以下のような場合を考えてみましょう。
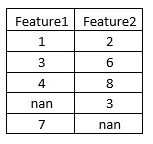
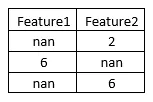
Feature2の欠損値を補完したい場合、IterativeImputerは次のような関数を作成します:
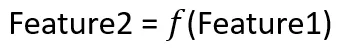
したがって、IterativeImputerはFeature2を「y」として、Feature1を「X」として回帰器を作成します。このようにモデルが訓練されると、Feature2の値がFeature1の値の2倍であることがわかります。このロジックを使用して、Feature2の欠損値が補完されます。
同様に、Feature1の値を補完するためにもう1つのモデルが訓練されます。
さて、IterativeImputerの実装方法を見てみましょう。
iterimputer = IterativeImputer(estimator=DecisionTreeRegressor(), missing_values=np.nan, add_indicator=True)print(f"X_trainの欠損値補完前のデータ:\n\n {X_train.head()}\n\n")print(f"欠損値補完前のX_trainの列名:\n\n {X_train.columns.values}\n\n")filled_X_train = pd.DataFrame(iterimputer.fit_transform(X_train), columns=iterimputer.get_feature_names_out())filled_X_valid = pd.DataFrame(iterimputer.transform(X_valid), columns=iterimputer.get_feature_names_out())print(f"X_trainの欠損値補完後のデータ:\n\n {filled_X_train.head()}\n\n")print(f"欠損値補完後のX_trainの列名:\n\n {filled_X_train.columns.values}\n\n")print(f"IterativeImputerを使用した欠損値補完のMAE: {np.round(score_dataset(filled_X_train, filled_X_valid, y_train, y_valid),2)}")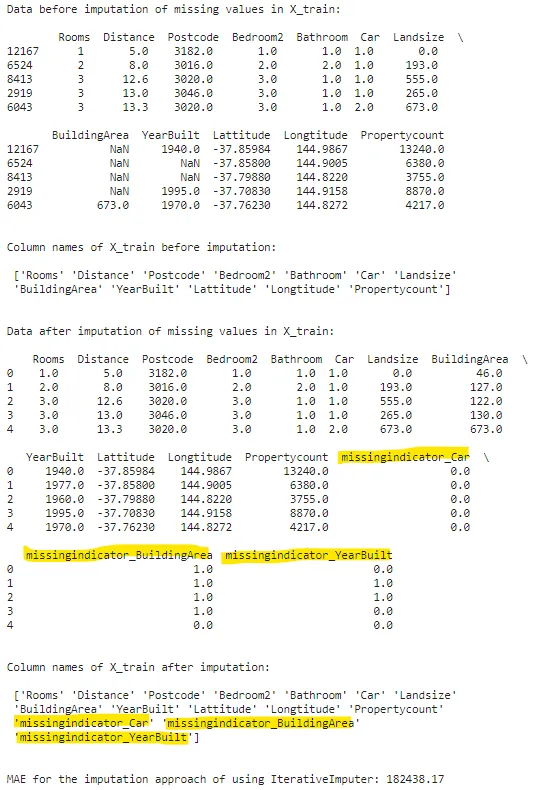
なお、IterativeImputerのestimatorパラメータを使用して、補完に使用する回帰器を指定することもできます。また、IterativeImputerにはadd_indicatorパラメータがあり、SimpleImputerと同様に機能します。
KNNImputer
このイムピュータはK最近傍法の概念を使用します。欠損値をサポートするnan_euclidean_distancesというユークリッド距離が使用されます。
nan_euclidean_distancesの動作を見てみましょう。サンプルのペア間の距離を計算する際、この式ではどちらかのサンプルの特徴座標が欠損している場合は無視し、残りの座標の重みを大きくします。

距離を計算する際には、欠損していない値であるa1、a2、…およびb1、b2、…を使用します。
では、このアルゴリズムの動作を理解するために例を見てみましょう。
次のデータを考えましょう。
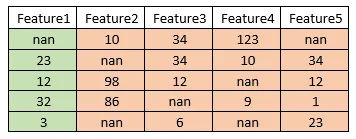
Feature1の最初のインデックスにある欠損値を補完したいとします。
STEP 1:
各行レコードとインデックス1の行レコードとの間のnan_euclidean_distanceを求めます。
インデックス1のレコードとインデックス2のレコード間のnan_euclidean_distance:

同様に、
インデックス1のレコードとインデックス3のレコード間のnanユークリッド距離:
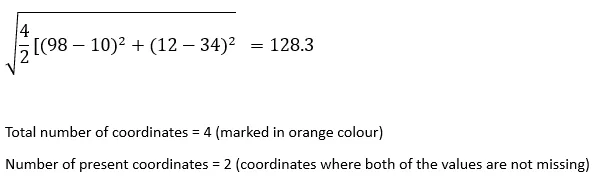
インデックス1のレコードとインデックス4のレコード間のnanユークリッド距離:
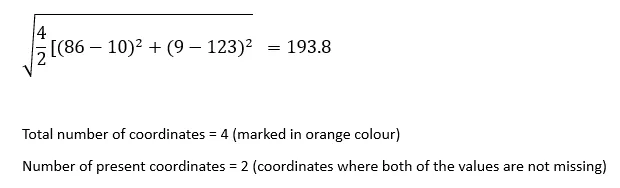
インデックス1のレコードとインデックス5のレコード間のnanユークリッド距離:
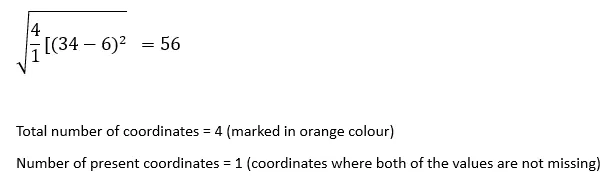
【STEP 2】:
このステップでは、これらの距離を昇順でソートします。
56、128.3、159.8、193.8
【STEP 3】:
このステップでは、注文における最初のK(K最近傍法のK値)個の値を取得します。
Kが2の場合、欠損値は注文の最初の2つの値の平均で補完されます。つまり、(56 + 128.3)/ 2 = 92.15
Kが3の場合、欠損値は注文の最初の3つの値の平均で補完されます。つまり、(56 + 128.3 + 159.8)/ 3 = 114.7
以降も同様です。
アルゴリズムの仕組みを学んだので、実装方法を見てみましょう。
knnimputer = KNNImputer(n_neighbors=3, missing_values=np.nan, add_indicator=True)print(f"X_trainの欠損値補完前のデータ:\n\n {X_train.head()}\n\n")print(f"欠損値補完前のX_trainの列名:\n\n {X_train.columns.values}\n\n")knn_filled_X_train = pd.DataFrame(knnimputer.fit_transform(X_train), columns=knnimputer.get_feature_names_out())knn_filled_X_valid = pd.DataFrame(knnimputer.transform(X_valid), columns=knnimputer.get_feature_names_out())print(f"X_trainの欠損値補完後のデータ:\n\n {knn_filled_X_train.head()}\n\n")print(f"欠損値補完後のX_trainの列名:\n\n {knn_filled_X_train.columns.values}\n\n")print(f"KNNImputerを使用した欠損値補完のMAE: {np.round(score_dataset(knn_filled_X_train, knn_filled_X_valid, y_train, y_valid),2)}")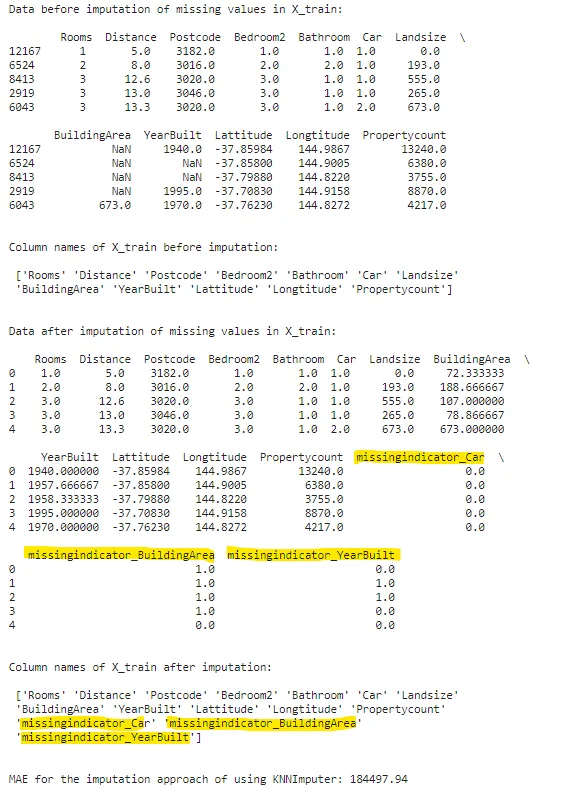
IterativeImputerもadd_indicatorパラメーターを持っており、SimpleImputerと同じように機能します。
読んでくれてありがとう!もし記事についての考えがあれば、ぜひ教えてください。
次に何を読むべきか迷っていませんか?心配しないでください、興味深い記事があります。
交差検証を使って機械学習モデルに自信を持とう
交差検証は、機械学習モデルが新しいデータで信頼性があるかどうかをチェックするための重要なツールです。
pub.towardsai.net
もう1つですが…
カオスから秩序へ:データクラスタリングを活用した意思決定の向上
この記事では、データクラスタリング方法の重要なユースケース、これらの方法の使用方法、およびどのように使用するかを紹介します。
pub.towardsai.net
シヴァム シンデ
- 私とつながる LinkedIn
- 同様に、私をフォローすることができます VoAGI
素晴らしい一日を!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
