「生データから洗練されたデータへ:データの前処理の旅 — パート3:重複データ」
From Raw Data to Refined Data Data Preprocessing Journey - Part 3 Duplicate Data
この記事では、データ内の重複レコードを特定する方法と、重複レコードの問題を解決するための異なる方法について説明します。
データ内の重複レコードの存在は問題ですか?
データ内の重複値は、多くのプログラマによって無視されることがしばしばあります。しかし、データ内の重複レコードを取り扱うことは非常に重要です。
重複レコードを持つことは、正確なデータ分析や意思決定に影響を与える可能性があります。
たとえば、重複レコードのあるデータにおいて、欠損値(補完)を平均値で置き換える場合、どのようなことが起こるでしょうか?
このシナリオでは、誤った平均値が補完に使用される可能性があります。以下に例を示します。
次のデータを考えてみましょう。データには「名前」と「体重」の2つの列が含まれています。なお、『ジョン』の体重値は繰り返されています。また、『スティーブ』の体重値が欠損しています。
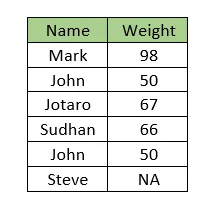
スティーブの体重の欠損値を、全体の体重値の平均で補完する場合、誤った平均値が使用されます。つまり、
(98 + 50 + 67 + 66 + 50)/5 = 66.2
しかし、重複値を無視したデータの実際の平均値は
(98 + 50 + 67 + 66)/4 = 70.25
したがって、重複レコードについて何も対策を取らない場合、欠損値は誤って補完されます。
さらに、重複値は、このような誤ったデータを使用して行われるビジネス上の意思決定にも影響を与える可能性があります。
まとめると、データから重複レコードを取り扱うことで、データを問題から解放することが重要です。
それでは、データ内の重複レコードを取り扱うための異なる方法を見てみましょう。
データ内の重複値の特定
パンダのduplicatedメソッドを使用して、データ内の重複した行を特定することができます。
では、例を使って重複値を理解しましょう。
## 必要なライブラリのインポートimport numpy as npimport pandas as pdimport warningswarnings.filterwarnings('ignore')## データフレームの作成Name = ['マーク', 'ジョン', 'ジョジョ', 'マーク', 'ジョン', 'スティーブ']Weight = [98, 50, 67, 66, 50, np.nan]Height = [170, 175, 172, 170, 175, 166]df = pd.DataFrame()df['名前'] = Namedf['体重'] = Weightdf['身長'] = Heightdf
重複値の特定:
## 重複値の特定(デフォルトの動作)df.duplicated()
重複レコードが存在する場所では値がTrue、一意のレコードが存在する場所ではFalseを取得します。
デフォルトでは、duplicated()メソッドはすべての列を使用して重複レコードを見つけます。しかし、重複を見つけるために使用する列の部分集合を指定することもできます。これには、duplicated()メソッドのsubsetというパラメータがあります。subsetパラメータには、重複を検索するために使用したい列名のリストを指定します。
## duplicated()メソッドのsubsetパラメータdf.duplicated(subset=['名前','身長'])
さらに、duplicated()メソッドにはkeepという重要なパラメータがあります。keepパラメータの値によって、重複したレコードの中で最初のレコードをユニークとするか、最後のレコードをユニークとするかを決定します。また、重複したレコードをすべて非ユニークとするオプションもあります。
keep = ‘first’:重複したレコードの中で最初のレコードがユニークとされます
keep = ‘last’:重複したレコードの中で最後のレコードがユニークとされます
keep = False:全ての重複したレコードが非ユニークとされます。
## keepパラメータの使用例df.duplicated(keep='first')
ここでは、最初の重複した値(インデックス1)がユニークとみなされ、他のすべての値(インデックス4)が重複とみなされることに注意してください。
## keepパラメータの使用例df.duplicated(keep='last')
ここでは、最後の重複した値(インデックス4)がユニークとみなされ、他のすべての値(インデックス1)が重複とみなされることに注意してください。
## keepパラメータの使用例df.duplicated(keep=False)
ここでは、すべての重複したレコード(インデックス1とインデックス4)が表示されることに注意してください。
データ内の重複したレコードの処理方法
重複したレコードを特定した後の次のステップは、それらを処理することです。
データ内の重複したレコードを処理する方法は2つあります。
重複したレコードの削除
まず、重複したレコードを削除する方法から始めましょう。
これには、pandasのdrop_duplicates()メソッドを使用することができます。
デフォルトで、drop_duplicates()メソッドは、すべての重複したレコードのセットから最初のレコードを保持し、残りのレコードをデータから削除します。また、デフォルトでは、drop_duplicates()メソッドはすべての列を使用して重複したレコードを特定します。
ただし、このデフォルトの動作は、drop_duplicates()メソッドの2つのパラメータを使用して変更することができます。それらは
- keep
- subset
drop_duplicates()メソッドのkeepとsubsetパラメータは、duplicated()メソッドのkeepとsubsetパラメータと同様に機能します。
"""pandasのdrop_duplicates()メソッドを使用して重複した値を削除する(デフォルトの動作)"""df1 = df.drop_duplicates()df1
"""pandasのdrop_duplicates()メソッドを使用して重複した値を削除する(subsetとkeepパラメータを使用したカスタムの動作)"""df2 = df.drop_duplicates(subset=['Weight'], keep='last')df2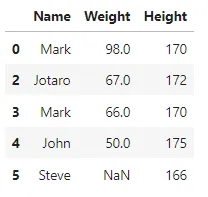
重複したレコードの更新
場合によっては、重複したレコードをある値で置き換えたいことがあります。例えば、2つの重複したレコードを見つけた後、データを取得した人が誤って1つの重複したレコードに間違った名前を入れてしまったことがわかったとします。その場合、正しい人の名前を入れたいと思うでしょう。これにより、重複した値の問題が解決されます。
df.duplicated(keep=False)
ここでは、インデックス1と4の重複したレコードがあります。さて、インデックス1の「Name」列の値を変更すると、もはや重複した値はありません。
## インデックス1の最初の重複レコードの「Name」値を変更するdf.iloc[1, 0] = 'Dio' df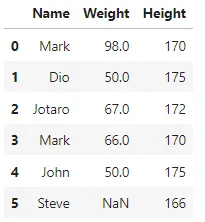
最初の重複レコードの「Name」値を変更しました。さて、データに重複したレコードが存在するかどうか再度確認してみましょう。
df.duplicated()
今は重複したレコードはありません。
読んでくれてありがとう!記事についてのご意見があれば、教えてください。
次に何を読むか迷っていますか?心配しないで、あなたが興味を持つだろうと思われる記事を知っています。
生データから洗練されたデータへ:データ前処理の旅 – パート2:欠損値
欠損値の対処方法はなぜ重要ですか?
pub.towardsai.net
さらにもう1つ…
生データから洗練されたデータへ:データ前処理の旅 – パート1:特徴のスケーリング
機械学習のタスクに使用するデータは、Scikit-Learnでコーディングするために適切な形式ではないことがあります…
pub.towardsai.net
Shivam Shinde
- LinkedInで私とつながる
- 同様に、VoAGIで私をフォローすることもできます
素晴らしい一日を!
参考文献:
Pandas DataFrameでの重複値の処理
データアナリストとして、正確で信頼性のある洞察を得るためにデータの整合性を確保することは私たちの責任です。データ…
stackabuse.com
すべてまたは選択した列に基づいてデータフレームで重複した行を検索する – GeeksforGeeks
Geeksのためのコンピューターサイエンスポータル。コンピューターサイエンスと…
www.geeksforgeeks.or
Pandas DataFrameのduplicated()メソッド
W3Schoolsは、ウェブ上の主要な言語すべてで無料のオンラインチュートリアル、リファレンス、演習を提供しています。…
www.w3schools.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
