FMOps / LLMOps:生成型AIの運用化とMLOpsとの違い
FMOps / LLMOps Differences between operationalizing generative AI and MLOps
現在、私たちのほとんどの顧客は大規模言語モデル(LLM)に興味を持ち、生成型AIがビジネスを変革する方法について考えています。しかし、このようなソリューションやモデルを通常の業務に組み込むことは簡単なことではありません。この投稿では、MLOpsの原則を活用して生成型AIアプリケーションを運用化する方法について説明します。また、テキストからテキストへのアプリケーションやLLMの運用(LLMOps)といった、最も一般的な生成型AIのユースケースについて詳しく説明します。以下の図は、私たちが議論するトピックを示しています。
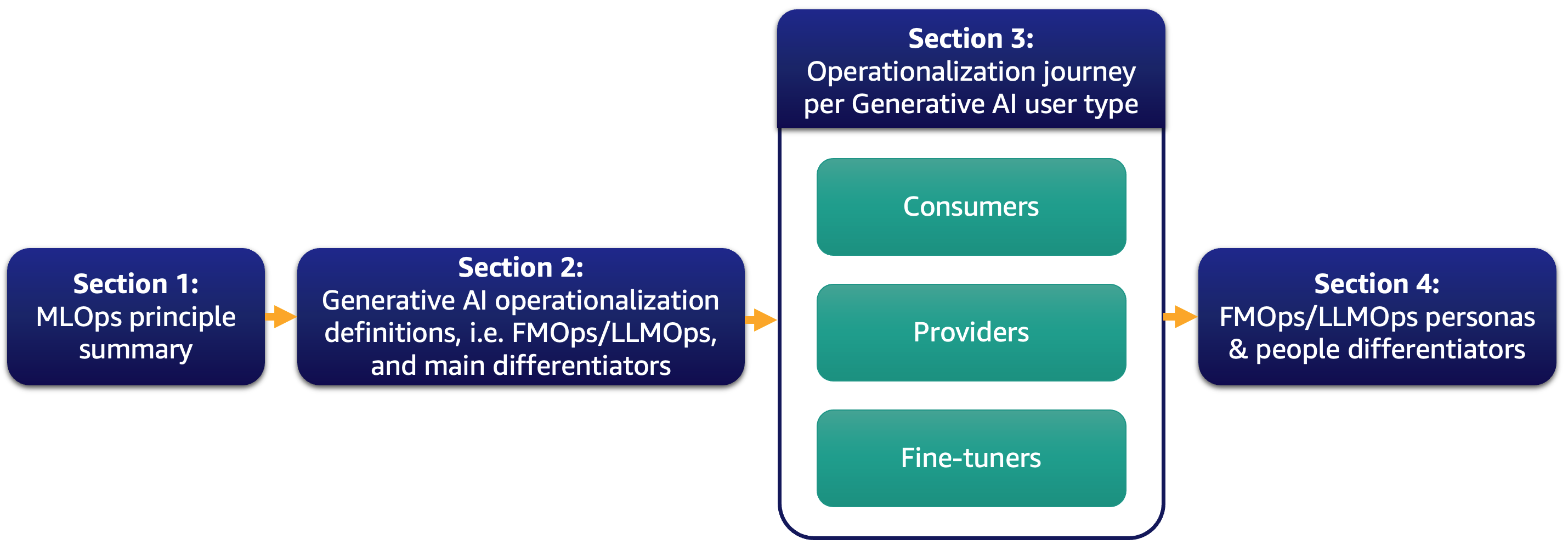
具体的には、MLOpsの原則を簡単に紹介し、プロセス、人々、モデルの選択と評価、データプライバシー、モデルの展開に関してFMOpsとLLMOpsとの主な違いに焦点を当てます。これは、既存のモデルを使用する顧客、ゼロから基礎モデルを作成する顧客、または微調整する顧客に適用されます。私たちのアプローチは、オープンソースモデルとプロプライエタリモデルの両方に対して同様に適用されます。
ML運用化の概要
Amazon SageMakerによるエンタープライズ向けMLOpsの基盤ロードマップで定義されているように、MLとオペレーション(MLOps)は、人々、プロセス、技術の組み合わせによって機械学習(ML)ソリューションを効率的に製品化するものです。これを実現するためには、以下の図に示すように、チームと個人が協力する必要があります。
- AIの生成体験を向上させる Amazon SageMakerホスティングでのストリーミングサポートの導入
- 「VoAGI創設者グレゴリー・ピアテツキーシャピロとの30周年記念インタビュー」
- 「VoAGIの30周年おめでとう!」
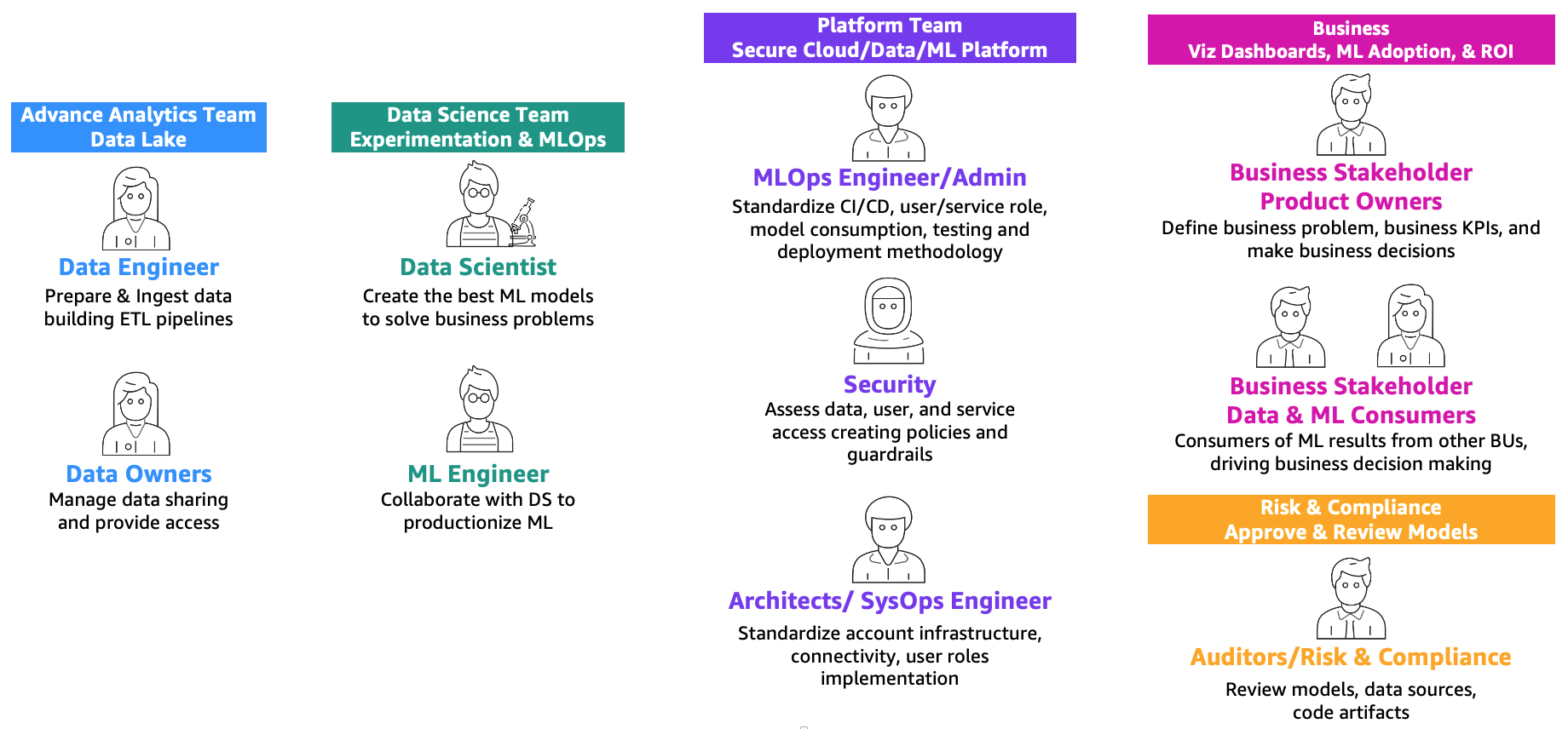
これらのチームは以下の通りです:
- 高度な分析チーム(データレイクとデータメッシュ) – データエンジニアは、複数のソースからデータを準備し取り込み、データを整理しカタログ化するETL(抽出、変換、ロード)パイプラインを構築し、MLのユースケースに必要な適切な履歴データを準備する責任があります。これらのデータ所有者は、複数のビジネスユニットやチームにデータへのアクセスを提供することに焦点を当てています。
- データサイエンスチーム – データサイエンティストは、ノートブックで作業し、事前定義された主要パフォーマンス指標(KPI)に基づいて最適なモデルを作成する必要があります。研究フェーズの完了後、データサイエンティストはMLエンジニアと協力して、CI/CDパイプラインを使用してモデルを構築(MLパイプライン)し、本番環境に展開するための自動化を作成する必要があります。
- ビジネスチーム – プロダクトオーナーは、ビジネスケース、要件、およびモデルのパフォーマンス評価に使用されるKPIを定義する責任があります。MLの消費者は、推論結果(予測)を使用して意思決定を行う他のビジネスステークホルダーです。
- プラットフォームチーム – アーキテクトは、ビジネス全体のクラウドアーキテクチャと、すべての異なるサービスがどのように接続されるかに責任を持っています。セキュリティSMEは、ビジネスのセキュリティポリシーやニーズに基づいてアーキテクチャをレビューします。MLOpsエンジニアは、データサイエンティストとMLエンジニアがMLのユースケースを製品化するための安全な環境を提供する責任があります。具体的には、ビジネスとセキュリティの要件に基づいて、CI/CDパイプライン、ユーザーおよびサービスの役割、コンテナの作成、モデルの利用、テスト、展開手法の標準化に責任を持ちます。
- リスクとコンプライアンスチーム – より制約のある環境では、監査人がデータ、コード、およびモデルのアーティファクトを評価し、ビジネスがデータプライバシーなどの規制に準拠していることを確認します。
スケーリングとMLOpsの成熟度に応じて、複数の役割を同じ人が担当する場合もあることに注意してください。
これらの役割には、異なるプロセスを実行するための専用の環境が必要です。以下の図に示すように。
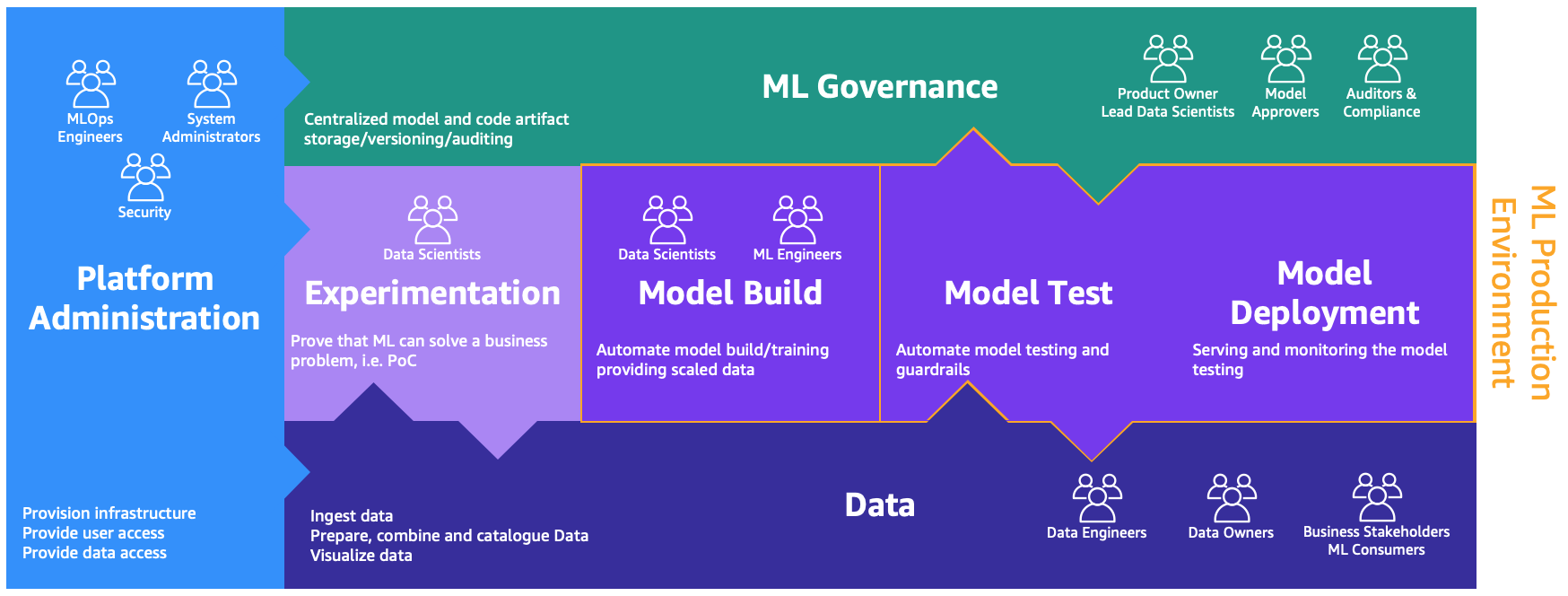
環境は以下の通りです:
- プラットフォーム管理 – プラットフォーム管理環境は、プラットフォームチームがAWSアカウントを作成し、適切なユーザーとデータをリンクするためのアクセス権を持つ場所です
- データ – データレイヤーは、データエンジニアやデータ所有者、ビジネスステークホルダーがデータの準備、相互作用、可視化を行うために使用する場所です
- 実験 – データサイエンティストは、サンドボックスや実験環境を使用して、新しいライブラリやMLのテクニックをテストし、自分たちの概念実証がビジネスの問題を解決できることを証明する必要があります
- モデルの構築、モデルのテスト、モデルの展開 – モデルの構築、テスト、展開環境は、データサイエンティストとMLエンジニアが協力して研究を本番環境に自動化するためのMLOpsの層です
- MLガバナンス – 最後のピースは、MLガバナンス環境で、すべてのモデルとコードのアーティファクトが保存され、対応する役割によってレビューおよび監査される場所です
以下の図は、Amazon SageMakerを使用したエンタープライズ向けのMLOps基盤のロードマップで既に議論されている、参照アーキテクチャを示しています。
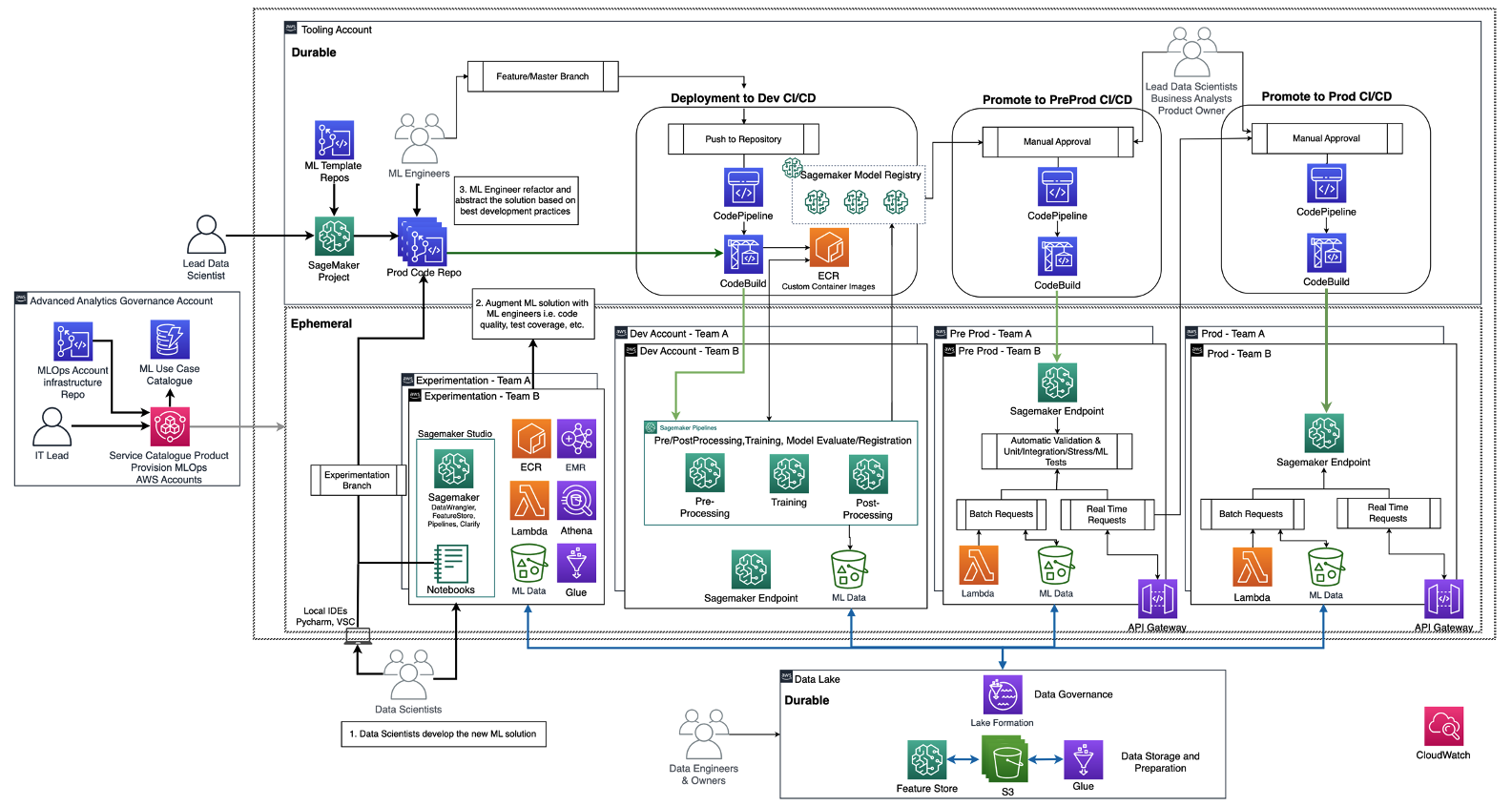
各ビジネスユニットは、それぞれ独自の開発(自動モデルトレーニングと構築)、プレプロダクション(自動テスト)、プロダクション(モデルの展開と提供)のアカウントを持ち、データはそれぞれ集中型または分散型のデータレイクまたはデータメッシュから取得されます。生成されたモデルとコードの自動化は、モデルレジストリの機能を使用して、集中型のツールアカウントに格納されます。これらのアカウントのインフラストラクチャコードは、プラットフォームチームが新しいチームのMLOpsプラットフォームへのオンボーディングに対して抽象化、テンプレート化、メンテナンス、再利用ができるように、共有サービスアカウント(高度な分析ガバナンスアカウント)でバージョン管理されます。
生成型AIの定義とMLOpsとの違い
クラシックな機械学習では、人々、プロセス、テクノロジーの組み合わせによってMLのユースケースを製品化することができます。しかし、生成型AIでは、ユースケースの性質上、これらの能力を拡張するか新しい能力が必要です。その中でも新しい概念の1つがファウンデーションモデル(FM)です。以下の図で示されているように、FMは他の様々なAIモデルを作成するために使用できるため、そのように呼ばれています。
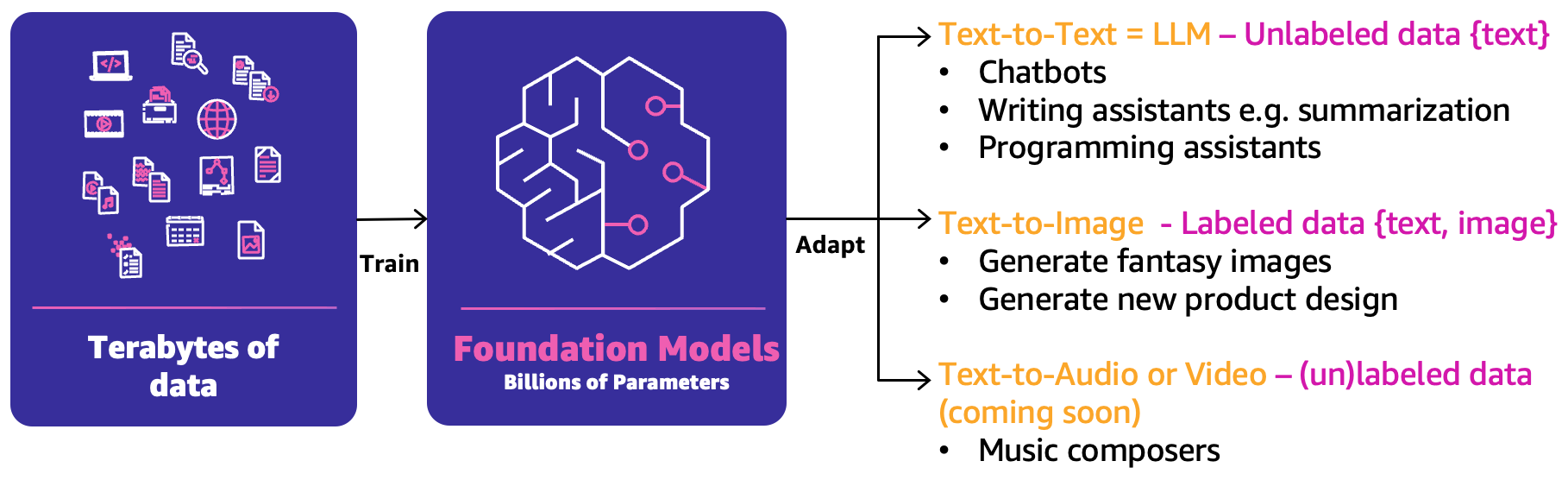
FMは、テラバイト単位のデータに基づいてトレーニングされ、数百億のパラメータを持っています。このため、主に以下の3つの主要な生成型AIユースケースに基づいて次の最適な回答を予測することができます:
- テキストからテキストへ – FM(LLM)は非ラベル付きデータ(フリーテキストなど)に基づいてトレーニングされ、次の最適な単語または単語のシーケンス(段落または長文エッセイ)を予測することができます。主なユースケースは、人間らしいチャットボット、要約、またはプログラミングコードなどのコンテンツ作成です。
- テキストからイメージへ – ラベル付きのデータ(テキストと画像のペアなど)を使用してFMをトレーニングし、最適なピクセルの組み合わせを予測することができます。例えば、衣料品のデザイン生成や架空のパーソナライズされたイメージなどのユースケースがあります。
- テキストからオーディオまたはビデオへ – ラベル付きおよび非ラベル付きデータの両方がFMのトレーニングに使用されることができます。主な生成型AIのユースケースの例としては、音楽の作曲があります。
これらの生成型AIユースケースを製品化するためには、以下の要素を含めてMLOpsドメインを拡張する必要があります:
- FMオペレーション(FMOps) – これにより、生成型AIソリューションを製品化することができます
- LLMオペレーション(LLMOps) – これは、テキストからテキストへなどのLLMベースのソリューションを製品化するためのFMOpsの一部です
以下の図は、これらのユースケースの重なりを示しています。
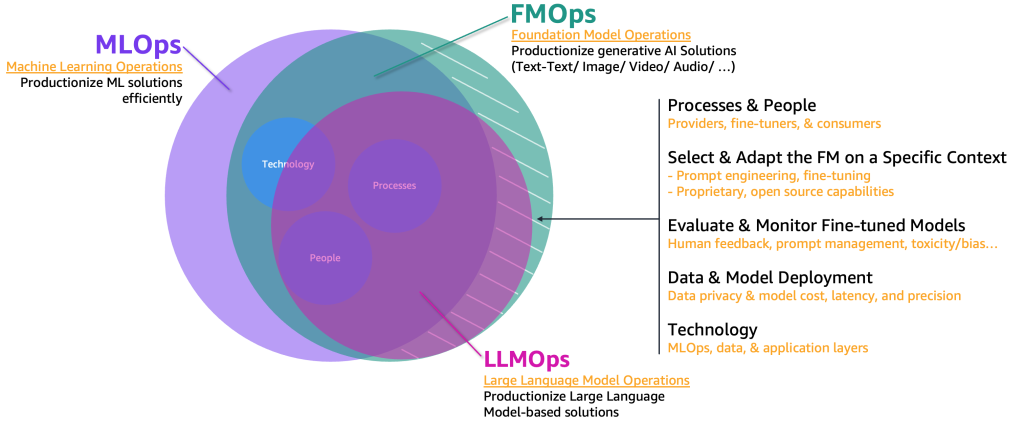
クラシックなMLとMLOpsと比較して、FMOpsとLLMOpsは、人々とプロセス、FMの選択と適応、FMの評価とモニタリング、データプライバシーとモデルの展開、および技術ニーズの4つの主要なカテゴリで異なります。モニタリングについては別の投稿で説明します。
生成型AIユーザータイプごとの運用化の旅
プロセスの説明を簡略化するために、以下の図に示すように、主要な生成型AIユーザータイプをカテゴリ分けする必要があります。
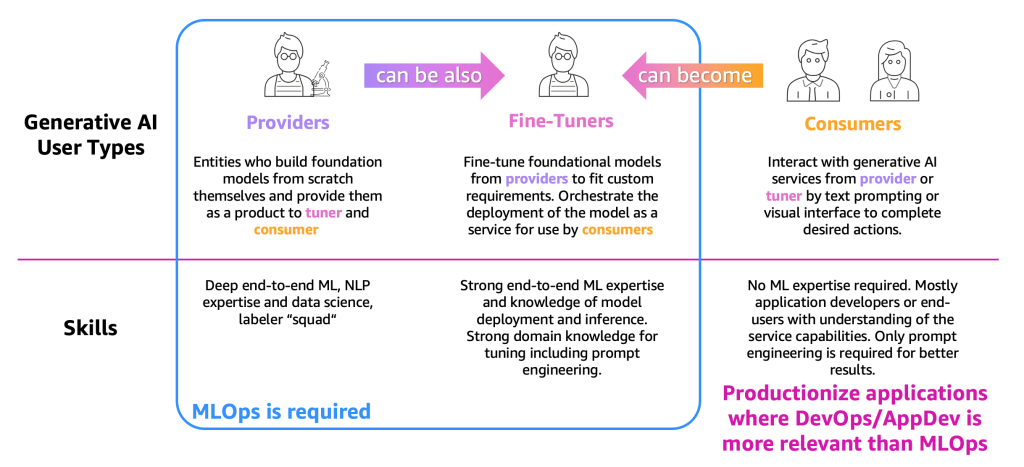
ユーザータイプは次のとおりです:
- プロバイダ – スクラッチからFMを構築し、他のユーザー(ファインチューナーおよびコンシューマ)に製品として提供するユーザー。エンドツーエンドのMLおよび自然言語処理(NLP)の専門知識、データサイエンスのスキル、大量のデータラベラーおよびエディターチームを持っています。
- ファインチューナー – プロバイダから提供されたFMを再トレーニング(ファインチューニング)してカスタム要件に合わせるユーザー。モデルをサービスとして展開し、コンシューマが使用するためのオーケストレーションを行います。これらのユーザーはエンドツーエンドのMLおよびデータサイエンスの専門知識と、モデルの展開と推論の知識が必要です。プロンプトエンジニアリングを含めたチューニングのための強力なドメイン知識も必要です。
- コンシューマ – プロバイダまたはファインチューナーから提供される生成AIサービスと対話し、テキストプロンプティングまたはビジュアルインターフェースを使用して必要なアクションを完了するユーザー。MLの専門知識は必要ありませんが、主にサービスの能力を理解したアプリケーション開発者またはエンドユーザーです。より良い結果のためにはプロンプトエンジニアリングのみが必要です。
定義と必要なMLの専門知識に基づき、プロバイダとファインチューナーには主にMLOpsが必要ですが、コンシューマはDevOpsやAppDevなどのアプリケーションの本番化原則を使用して生成AIアプリケーションを作成することができます。さらに、プロバイダは特定の垂直(金融部門など)に基づいたユースケースをサポートするためにファインチューナーになる場合や、コンシューマはより正確な結果を得るためにファインチューナーになる場合があるという動きも観察されています。しかし、まずはユーザータイプごとの主要なプロセスを見てみましょう。
コンシューマの旅
以下の図は、コンシューマの旅を示しています。
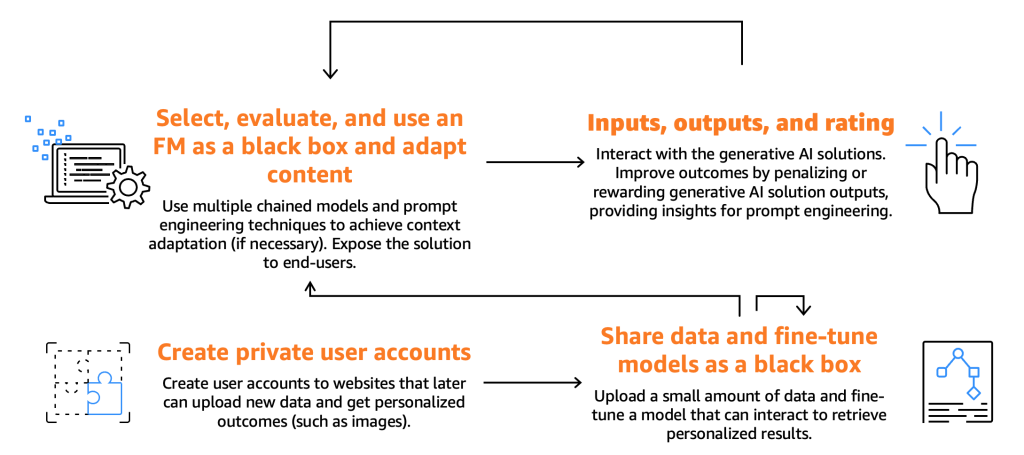
先に述べたように、コンシューマはFMを選択し、テストし、使用する必要があります。これは、特定の入力(プロンプトとも呼ばれる)を提供してそれと対話することによって行われます。コンピュータプログラミングとAIの文脈では、プロンプトはモデルまたはシステムに与えられる入力を指し、応答を生成します。これは、テキスト、コマンド、または質問の形式であり、システムはそれを処理して出力を生成します。FMによって生成された出力は、エンドユーザーが利用できるようになります。エンドユーザーはこれらの出力に評価を行い、モデルの将来の応答を向上させることができるはずです。
これらの基本的なプロセスの他に、コンシューマはファインチューナーが提供する機能を活用してモデルをファインチューニングしたいという希望を表明していることに気付きました。たとえば、画像を生成するウェブサイトを考えてみましょう。ここでは、エンドユーザーはプライベートアカウントを設定し、個人の写真をアップロードし、それに関連するコンテンツを生成することができます(たとえば、エンドユーザーがバイクに乗り、剣を持ち、またはエキゾチックな場所にいるようなイメージを生成する)。このシナリオでは、コンシューマが設計した生成AIアプリケーションは、エンドユーザーにこの機能を提供するために、APIを介してファインチューナーバックエンドと対話する必要があります。
ただし、それについて詳しく説明する前に、次の図に示すように、モデルの選択、テスト、使用、入出力の相互作用、および評価に集中しましょう。
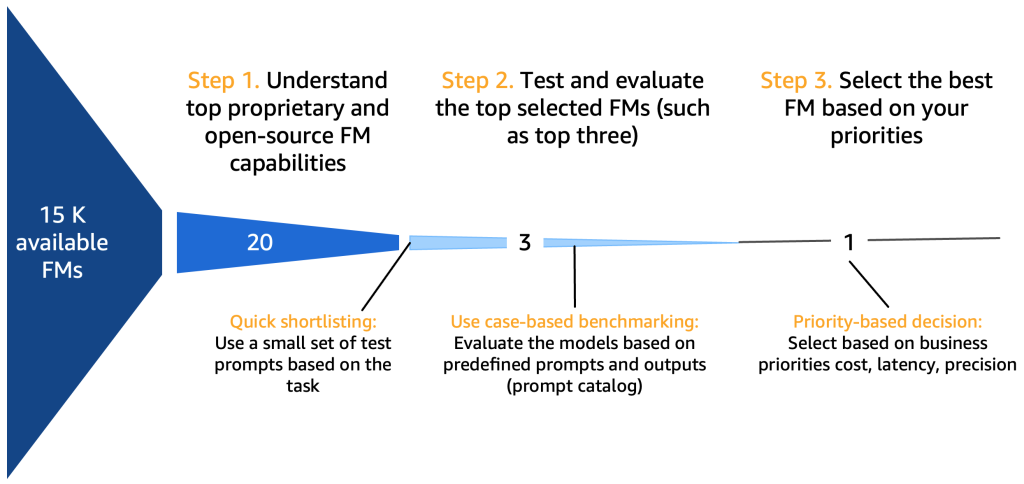
*利用可能なFMの参照先15K
ステップ1. トップFMの機能を理解する
基礎モデルを選択する際には、ユースケース、利用可能なデータ、規制など、さまざまな要素を考慮する必要があります。包括的ではありませんが、以下のチェックリストが参考になるでしょう:
- プロプライエタリまたはオープンソースのFM – プロプライエタリモデルは通常、財務上のコストがかかりますが、一般に生成されるテキストや画像の品質の面で優れたパフォーマンスを提供します。これらのモデルは、最適なパフォーマンスと信頼性を確保するために専門のモデルプロバイダチームによって開発および維持されることが多いです。一方、オープンソースモデルも採用されており、無料であるだけでなく、アクセス可能で柔軟性があります(たとえば、すべてのオープンソースモデルはファインチューニング可能です)。プロプライエタリモデルの例としては、AnthropicのClaudeモデルがあります。また、高性能なオープンソースモデルの例としては、2023年7月
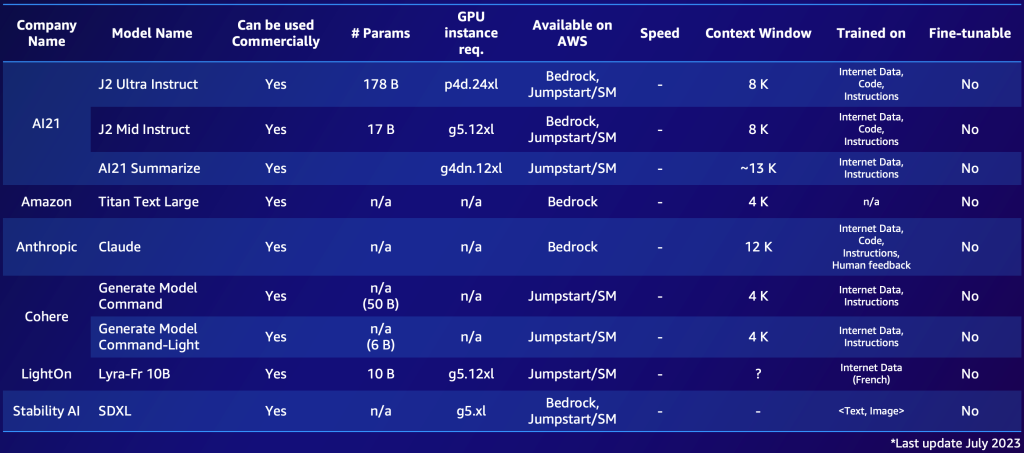
以下は、プロプライエタリモデルとオープンソースモデルの2つのショートリストの例です。利用可能なオプションを簡単に把握するため、特定のニーズに基づいて同様のテーブルを作成することができます。ただし、これらのモデルの性能やパラメータは急速に変化する可能性があり、読む時点で時代遅れになっているかもしれません。また、サポートされる言語など、特定の顧客にとって重要な機能もあります。
以下は、AWSで利用可能な注目すべきプロプライエタリFMsの例です(2023年7月)。
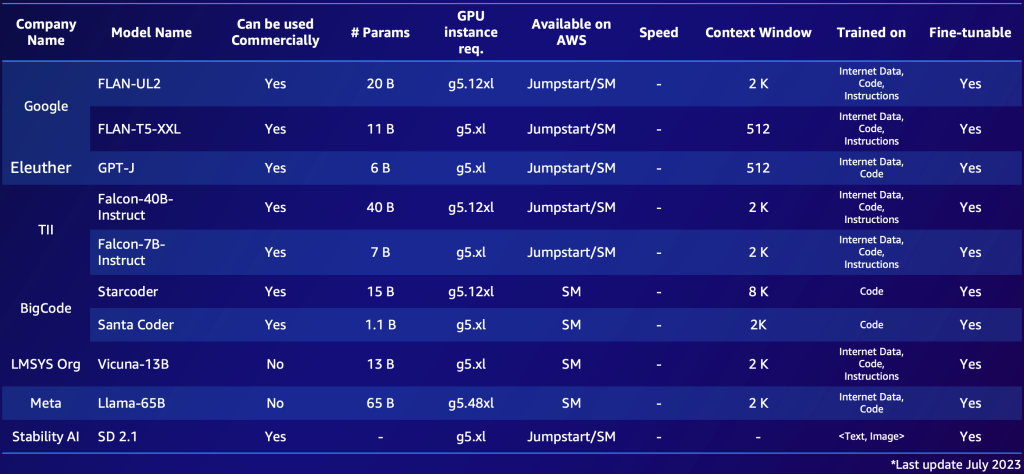
以下は、AWSで利用可能な注目すべきオープンソースFMの例です(2023年7月)。
10〜20の潜在的な候補モデルの概要をまとめた後、このショートリストをさらに絞り込む必要が生じます。このセクションでは、次のラウンドのための2〜3つの有望な最終モデルを提案する迅速なメカニズムを提案しています。
以下の図は、初期のショートリスト作成プロセスを示しています。
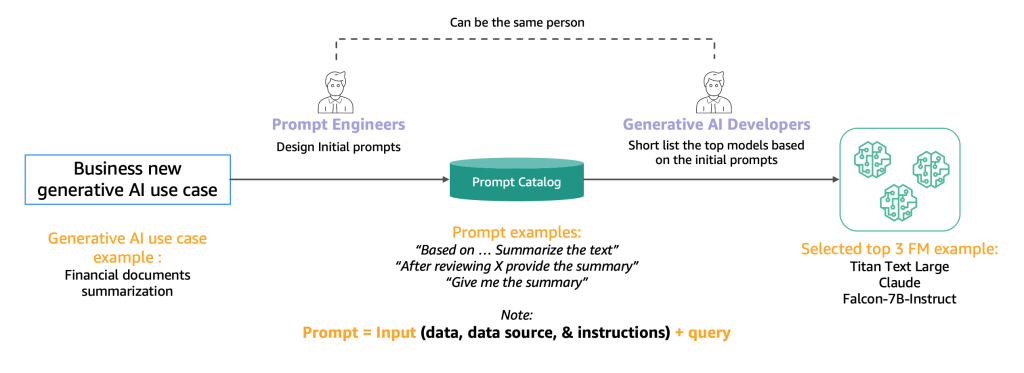
通常、AIモデルがユーザーの入力を理解し処理するための高品質なプロンプトを作成するエンジニア(プロンプトエンジニア)によって、同じタスク(要約など)を実行するためのさまざまな方法を試すための専門家であるプロンプトエンジニアによって、プロンプトエンジニアがプロンプトを即座に作成するのではなく、プロンプトカタログからシステム的に抽出されるべきであると提案します。このプロンプトカタログは、プロンプトの複製を避け、バージョン管理を可能にし、チーム内でプロンプトを共有することで、異なる開発段階の異なるプロンプトテスター間の一貫性を確保するための、プロンプトの保存場所として機能します。このプロンプトカタログは、フィーチャーストアのGitリポジトリに類似したものです。その後、生成AI開発者(おそらくプロンプトエンジニアと同じ人)は、生成AIアプリケーションの開発に適しているかどうかを評価するために出力を評価する必要があります。
ステップ2. トップFMのテストと評価
ショートリストが約3つのFMに絞り込まれた後、使用ケースの要件に応じてFMの能力と適合性をさらに評価するステップを推奨します。評価データの可用性と性質に応じて、次の図に示すように異なる方法を提案しています。
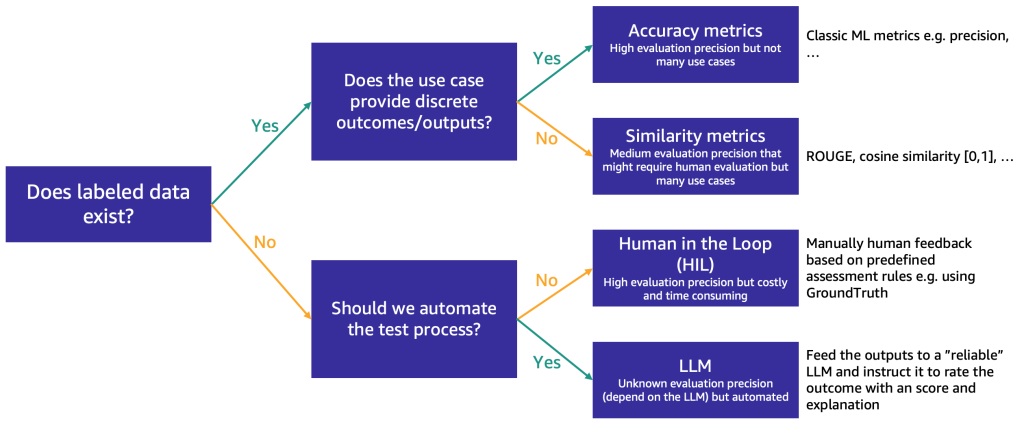
最初に使用する方法は、ラベル付きのテストデータの有無によります。
ラベル付きデータがある場合は、それを使用してモデルの評価を行うことができます(サンプルを入力し、出力をラベルと比較する)。テストデータに離散的なラベル(ポジティブ、ネガティブ、または中立的な感情分析など)があるか、または非構造化テキスト(要約など)であるかによって、評価のための異なる方法を提案します:
- 精度指標 – 離散的な出力の場合(感情分析など)、精度、再現率、F1スコアなどの標準的な精度指標を使用できます
- 類似性指標 – 出力が非構造化(要約など)の場合、ROUGEやコサイン類似度などの類似性指標を提案します
一部の使用ケースでは真の回答が一つ存在しない可能性もあります(たとえば、「5歳の娘のための短い子供向けストーリーを作成してください」など)。そのような場合、モデルの評価がより困難になります。ラベル付きのテストデータがないため、モデルの応答を評価するためには2つのアプローチがあります。人間のレビューと自動評価の重要性に応じて、次の2つのアプローチがあります:
- 人間による審査(HIL) – この場合、プロンプトテスターのチームがモデルの応答をレビューします。アプリケーションの重要性に応じて、プロンプトテスターはモデルの出力の100%またはサンプルのみをレビューする場合があります。
- LLMによる評価 – このシナリオでは、プロンプトテスターの代わりに、テストされているモデルよりも強力なLLMを使用します。LLMは、すべてのモデル生成応答をレビューし、スコアをつけます。この方法は品質が低くなる可能性がありますが、モデルのパフォーマンスについての初期のゲージとなる、より安価かつ迅速な評価オプションです。
たとえば、以下のサンプルプロンプトをLLMに使用することができます。このプロンプトには、入力クエリ、LLMの応答、および指示が含まれています。「上記に表示されたユーザーの質問に対するAIアシスタントのパフォーマンスについてフィードバックをお願いします。アシスタントの応答の役立ち度、関連性、正確性、詳細レベルを評価してください。アシスタントは1から10のスケールで総合スコアを受け取ります。スコアが高いほど総合的なパフォーマンスが良いことを示します。」
このプロンプトは、評価のために別のLLM(EvalLLM)に送信されます。以下は、Falcon-40Bモデルの応答がEvalLLM(この場合はClaude)によって評価された例です。質問は「スエズ運河が建設されていなかった場合はどうなるのか?」です。応答は以下の通りです:
質問: スエズ運河が建設されていなかった場合はどうなるのか?
falcon-40b-instruct
スエズ運河が建設されていなかった場合、船舶は地中海と紅海の間を航行するためにアフリカの周りを航行する必要があります。これにより、航海にはかなりの時間と距離がかかり、効率が低下し、費用が増加します。また、スエズ運河がなければ、中東や北アフリカの多くの国々は世界との接続がはるかに弱くなり、経済的および文化的な発展が妨げられるでしょう。
レビュー(スコア: 9/10)
アシスタントの応答は非常に関連性が高く、正確で詳細です。スエズ運河の存在しない仮想的な質問に対する優れた回答を提供しています。アシスタントは、海事旅行への影響や中東や北アフリカへの経済的および文化的な影響を正しく指摘しています。ただし、より包括的な回答のために、地政学的な影響や世界の貿易パターンへの影響についてさらに詳しく説明することができました。
次の図は、エンドツーエンドの評価プロセスの例を示しています。
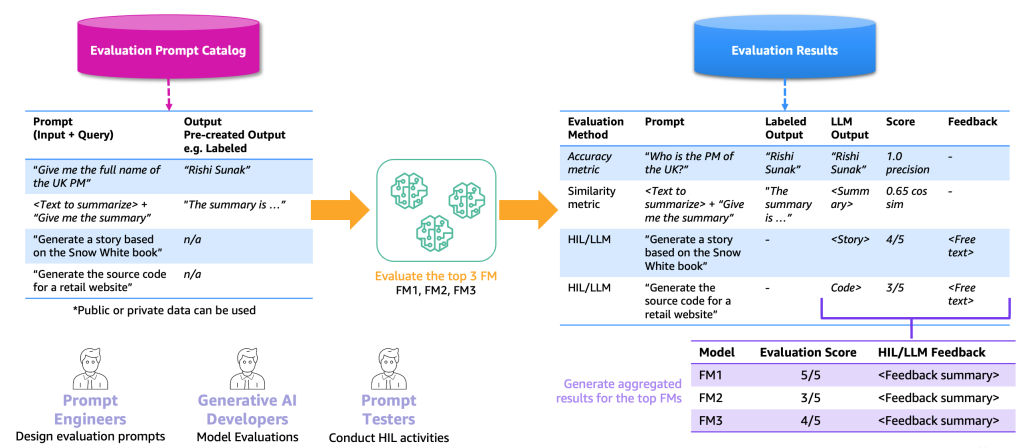
この例に基づいて、評価を実施するために、プロンプトカタログにサンプルプロンプトを提供し、特定のアプリケーションに基づいて評価されたラベル付きまたはラベルなしのデータセットを提供する必要があります。例えば、ラベル付きの評価データセットでは、「2023年の英国首相のフルネームを教えてください」といったプロンプト(入力とクエリ)と「リシ・スナック」といった出力と回答を提供することができます。ラベルなしのデータセットでは、「小売ウェブサイトのソースコードを生成してください」といった質問または指示のみを提供します。プロンプトカタログと評価データセットの組み合わせを評価プロンプトカタログと呼びます。プロンプトカタログと評価プロンプトカタログを区別する理由は、前者が一般的なプロンプトや指示(質問応答など)を含むのに対して、後者は特定のユースケースに特化しているためです。
この評価プロンプトカタログを使用して、次のステップはトップFMsに評価プロンプトを提供することです。その結果、評価結果データセットが生成されます。このデータセットには、各FMのプロンプト、出力、およびラベル付き出力が含まれ、スコア(存在する場合)も含まれます。ラベルなしの評価プロンプトカタログの場合、HILまたはLLMが結果をレビューし、スコアとフィードバックを提供するための追加のステップがあります(前述の通り)。最終的な結果は、すべての出力のスコアを組み合わせた集計結果(平均精度または人間の評価を計算)であり、ユーザーがモデルの品質をベンチマークすることができます。
評価結果が収集された後、いくつかの次元に基づいてモデルを選択することを提案します。これらは通常、精度、速度、コストなどの要素に帰結します。次の図はその例を示しています。
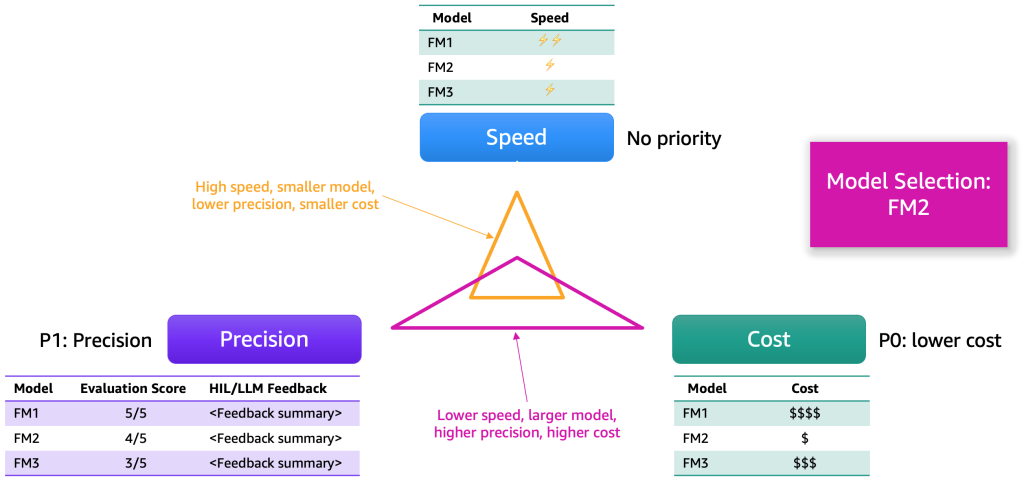
各モデルには、これらの次元に沿った強みとトレードオフがあります。使用ケースによっては、これらの次元に異なる優先順位を付ける必要があります。前述の例では、コストを最も重要な要素とし、次に精度、そして速度を優先しました。FM1よりも遅く効率的ではありませんが、十分に効果的で、ホストするためにはかなり安価です。そのため、私たちはFM2を最上位の選択肢とするかもしれません。
ステップ3. ジェネレーティブAIアプリケーションのバックエンドとフロントエンドを開発する
現時点では、生成型AIの開発者は、プロンプトエンジニアとテスターの助けを借りて、特定のアプリケーションに適したFMを選択しました。次のステップは、生成型AIアプリケーションの開発を開始することです。私たちは、生成型AIアプリケーションの開発をバックエンドとフロントエンドの2つのレイヤーに分けています。以下の図に示すように。
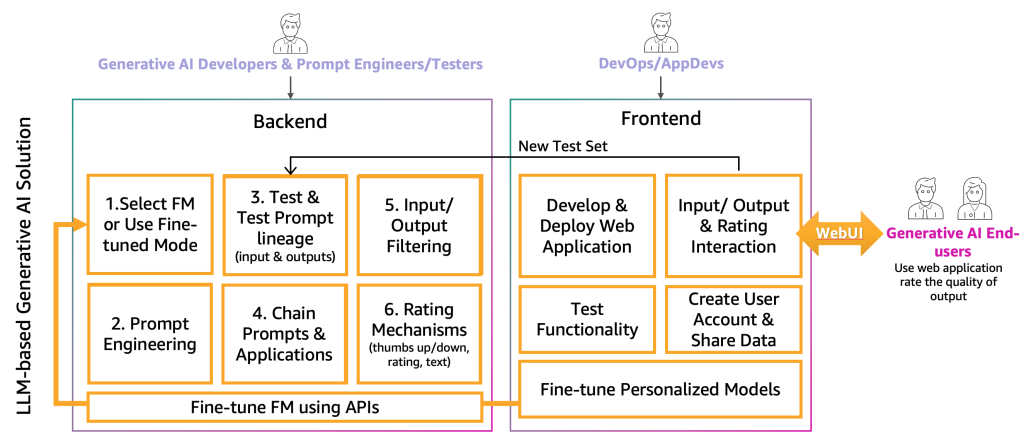
バックエンドでは、生成型AIの開発者は選択したFMをソリューションに組み込み、プロンプトエンジニアと協力して、エンドユーザーの入力を適切なFMプロンプトに変換するための自動化を作成します。プロンプトテスターは、自動または手動(HILまたはLLM)テストのために、プロンプトカタログに必要なエントリを作成します。その後、生成型AIの開発者は、最終的な出力を提供するためのプロンプトチェイニングとアプリケーションメカニズムを作成します。この文脈でのプロンプトチェイニングは、より動的かつ文脈に対応したLLMアプリケーションを作成するための技術です。これは、複雑なタスクをより小さな、より管理しやすいサブタスクに分割することで機能します。例えば、「イギリスの首相はどこで生まれ、その場所はロンドンからどのくらい離れていますか」という質問をLLMにする場合、このタスクは個々のプロンプトに分割されます。前のプロンプト評価の回答に基づいてプロンプトが構築される場合があります。「イギリスの首相は誰ですか」「彼らの出生地はどこですか」「その場所はロンドンからどのくらい離れていますか」などです。特定の入力と出力の品質を確保するために、生成型AIの開発者はエンドユーザーの入力とアプリケーションの出力を監視およびフィルタリングするメカニズムも作成する必要があります。例えば、LLMアプリケーションが有害な要求と応答を避ける必要がある場合、入力と出力に毒性検出器を適用してそれらをフィルタリングできます。最後に、生成型AIの開発者は、評価プロンプトカタログを良い例と悪い例で補完するための評価メカニズムを提供する必要があります。これらのメカニズムのより詳細な表現については、将来の投稿で説明します。
生成型AIのエンドユーザーに機能を提供するために、バックエンドと対話するフロントエンドのウェブサイトの開発が必要です。したがって、DevOpsおよびAppDevs(クラウド上のアプリケーション開発者)のパーソナルは、入力/出力と評価の機能を実装するために、最良の開発プラクティスに従う必要があります。
この基本的な機能に加えて、フロントエンドとバックエンドは、パーソナルユーザーアカウントの作成、データのアップロード、ブラックボックスとしてのファインチューニングの開始、基本的なFMの代わりに個別のモデルの使用といった機能を組み込む必要があります。生成型AIアプリケーションのプロダクション化は通常のアプリケーションと同様です。以下の図は、例のアーキテクチャを示しています。
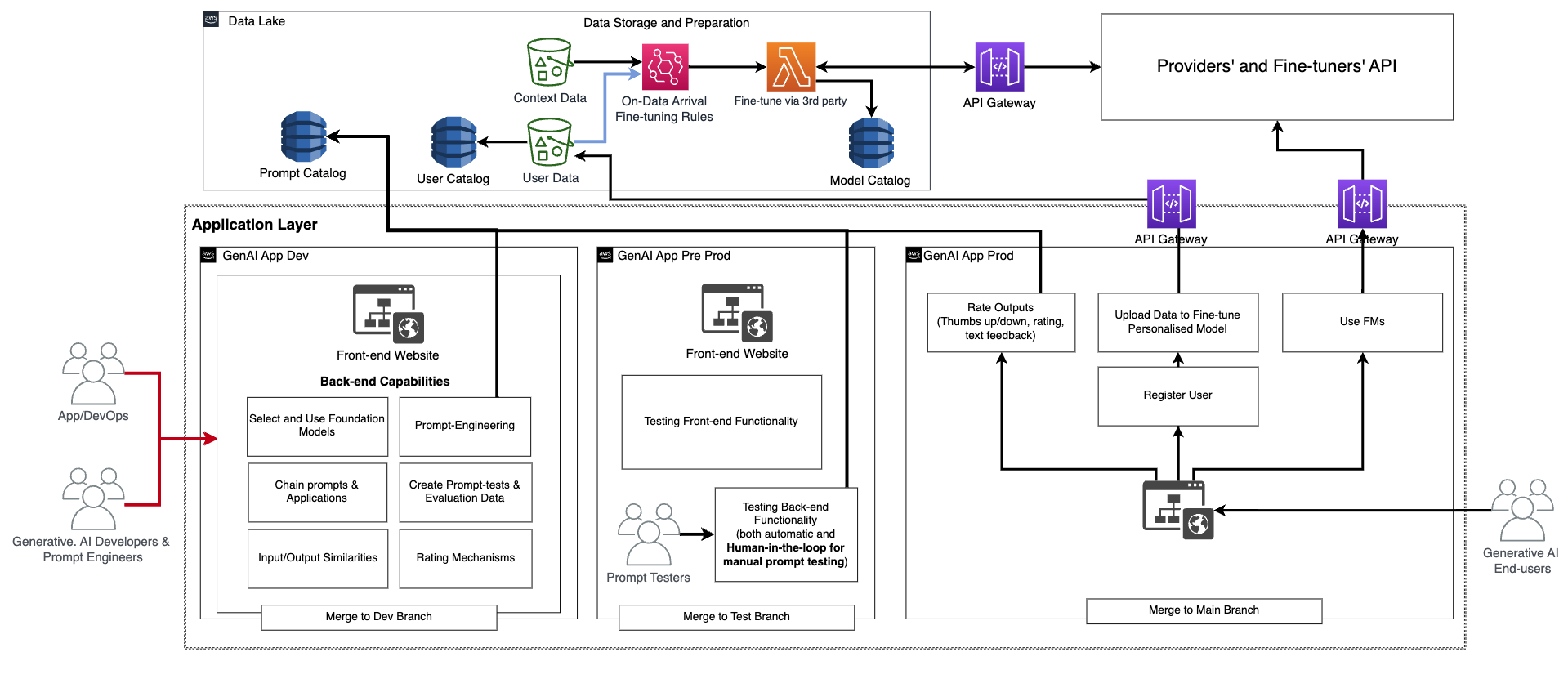
このアーキテクチャでは、生成型AIの開発者、プロンプトエンジニア、DevOpsまたはAppDevsは、専用のコードリポジトリを使用して開発環境(前の図の生成型AI App Dev)にCI/CDを介して展開することで、アプリケーションを手動で作成およびテストします。この段階では、生成型AIの開発者は、ファインチューナーのFMプロバイダーが提供するAPIを呼び出すことで、対応するFMを使用します。その後、アプリケーションを徹底的にテストするために、コードをテストブランチにプロモートする必要があります。これにより、CI/CDを介してプリプロダクション環境(生成型AI App Pre-prod)に展開がトリガーされます。この環境では、プロンプトテスターは大量のプロンプトの組み合わせを試し、結果をレビューする必要があります。プロンプトの組み合わせ、出力、およびレビューは、将来のテストプロセスを自動化するために評価プロンプトカタログに移動する必要があります。この徹底的なテストの後、最後のステップは、メインブランチとのマージによってCI/CDを介して生成型AIアプリケーションを本番環境にプロモートすることです(生成型AI App Prod)。すべてのデータ、プロンプトカタログ、評価データと結果、エンドユーザーデータとメタデータ、ファインチューニングされたモデルのメタデータを含むすべてのデータは、データレイクまたはデータメッシュレイヤーに保存する必要があります。CI/CDパイプラインとリポジトリは、MLOps用に説明されたものと同様に、別のツールアカウントに保存する必要があります。
プロバイダーの旅
FMプロバイダーは、ディープラーニングモデルなどのFMをトレーニングする必要があります。彼らにとっては、エンドツーエンドのMLOpsライフサイクルとインフラストラクチャが必要です。過去のデータの準備、モデルの評価、およびモニタリングに追加が必要です。以下の図は、彼らの旅を示しています。
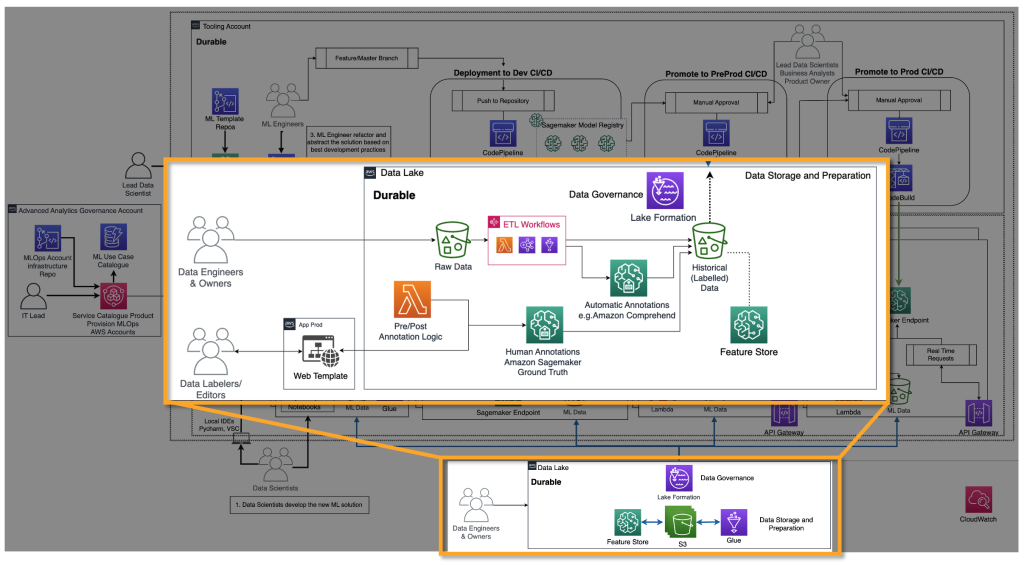
クラシックな機械学習では、過去のデータは通常、グラウンドトゥルースをETLパイプラインを介してフィードすることで作成されます。たとえば、離反予測のユースケースでは、自動化が顧客の新しいステータスに基づいてデータベーステーブルを更新し、自動的に離反する/しないを示します。FMsの場合、数十億のラベル付きまたはラベルなしのデータポイントが必要です。テキストから画像への使用例では、データラベラーのチームが<テキスト、画像>のペアを手動でラベル付けする必要があります。これは多くの人材リソースを必要とする高価な作業です。Amazon SageMaker Ground Truth Plusは、この作業を実行するためのデータラベラーチームを提供できます。一部のユースケースでは、このプロセスを部分的に自動化することも可能です。たとえば、CLIPのようなモデルを使用することで実現できます。テキストからテキストへのLLMの場合、データはラベルが付いていませんが、既存のラベルが付いていないデータの形式に従って準備する必要があります。したがって、データエディタが必要であり、必要なデータの準備と一貫性の確保を行います。
準備された過去のデータを使用して、次のステップはモデルのトレーニングとプロダクション化です。消費者向けに説明した評価技術と同様の技術が使用できることに注意してください。
ファインチューナーの旅
ファインチューナーは、既存のFMを特定のコンテキストに適応させることを目指しています。たとえば、FMモデルは一般的なテキストを要約することができますが、財務レポートを正確に要約することはできず、非一般的なプログラミング言語のソースコードを生成することもできません。これらの場合、ファインチューナーはデータにラベルを付け、トレーニングジョブを実行してモデルをファインチューニングし、モデルをデプロイし、消費者プロセスに基づいてテストし、モデルを監視する必要があります。次の図は、このプロセスを示しています。
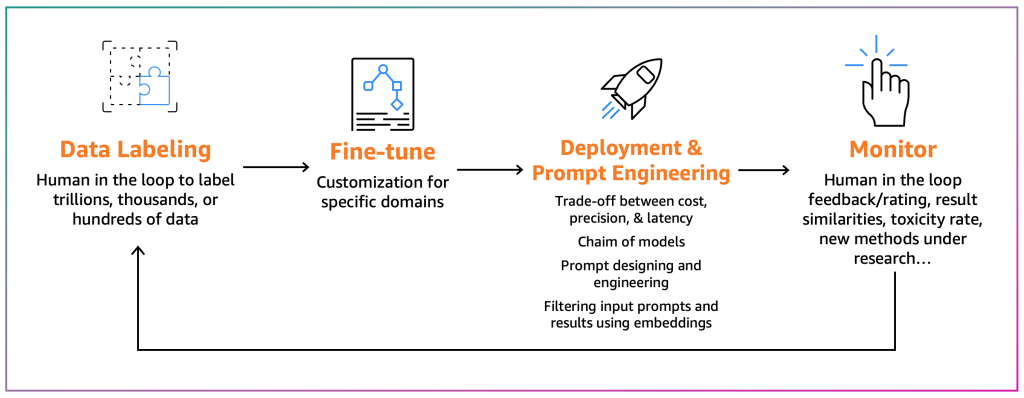
現時点では、2つのファインチューニングメカニズムがあります:
- ファインチューニング – FMとラベル付きデータを使用して、トレーニングジョブはディープラーニングモデルの重みとバイアスを再計算します。このプロセスは計算量が多く、十分な量のデータが必要ですが、正確な結果を生成できます。
- パラメータ効率の良いファインチューニング(PEFT) – すべての重みとバイアスを再計算する代わりに、研究者は、追加の小さなレイヤーをディープラーニングモデルに追加することで、満足のいく結果を得ることができることを示しています(たとえば、LoRAなど)。PEFTは、ディープファインチューニングよりも低い計算能力と少ない入力データでトレーニングジョブが必要です。欠点は、潜在的な低い精度です。
次の図は、これらのメカニズムを示しています。
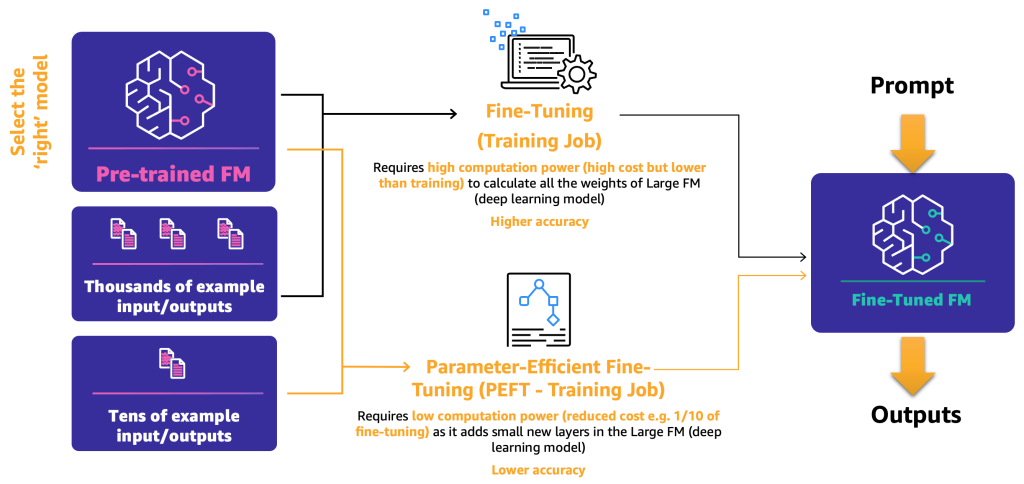
2つの主要なファインチューニング方法を定義したので、次のステップはオープンソースとプロプライエタリなFMを展開して使用する方法を決定することです。
オープンソースのFMでは、ファインチューナーはモデルアーティファクトとソースコードをウェブからダウンロードすることができます。たとえば、Hugging Face Model Hubを使用することができます。これにより、モデルをディープファインチューニングする柔軟性があり、ローカルモデルレジストリに保存し、Amazon SageMakerエンドポイントにデプロイすることができます。このプロセスにはインターネット接続が必要です。より安全な環境(金融業界の顧客など)をサポートするために、モデルをオンプレミスでダウンロードし、必要なすべてのセキュリティチェックを実行し、それらをAWSアカウントのローカルバケットにアップロードすることもできます。その後、ファインチューナーはインターネット接続なしでローカルバケットからFMを使用します。これによりデータのプライバシーが保護され、データはインターネットを経由せずに渡されます。次の図は、この方法を示しています。
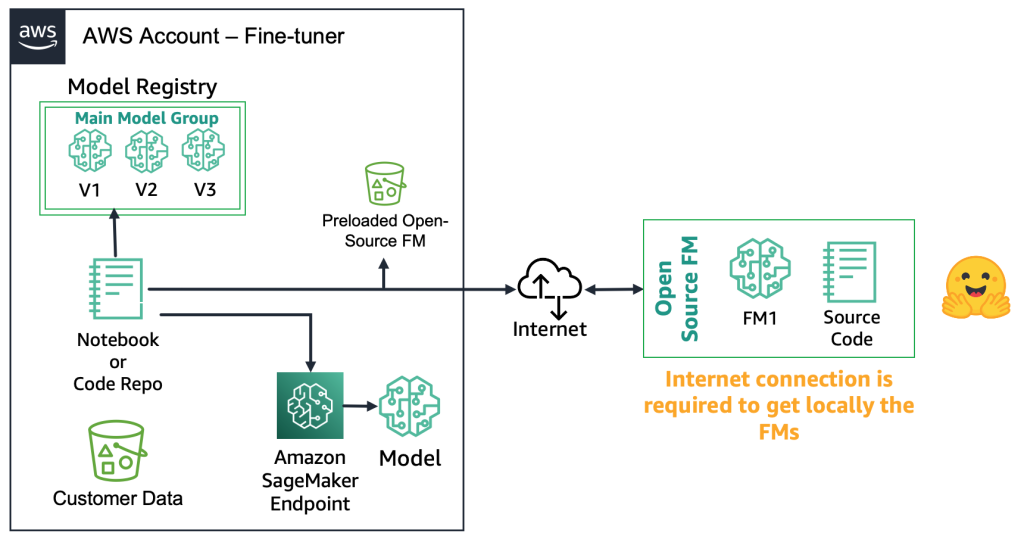
独自のFMsでは、展開プロセスが異なります。ファインチューナーはモデルのアーティファクトやソースコードにアクセスすることができません。モデルは独自のFMプロバイダーのAWSアカウントおよびモデルレジストリに格納されています。このようなモデルをSageMakerエンドポイントに展開するために、ファインチューナーはエンドポイントに直接展開されるモデルパッケージのみをリクエストすることができます。このプロセスでは、顧客データが独自のFMプロバイダーのアカウントで使用されるため、リモートアカウントでのファインチューニングに顧客の機密データが使用されることに関する疑問が生じます。また、複数の顧客間で共有されるモデルレジストリにホストされるモデルもあります。これにより、独自のFMプロバイダーがこれらのモデルを提供する必要がある場合、マルチテナンシの問題が発生します。ファインチューナーがAmazon Bedrockを使用する場合、これらの課題は解決されます。データはインターネットを介して移動せず、FMプロバイダーはファインチューナーのデータにアクセスすることはありません。先ほどのウェブサイトの例のように、ファインチューナーが複数の顧客からモデルを提供する場合、オープンソースのモデルにも同じ課題が存在します。ただし、これらのシナリオは制御可能と見なすことができます。ファインチューナーのみが関与するためです。次の図は、この方法を示しています。
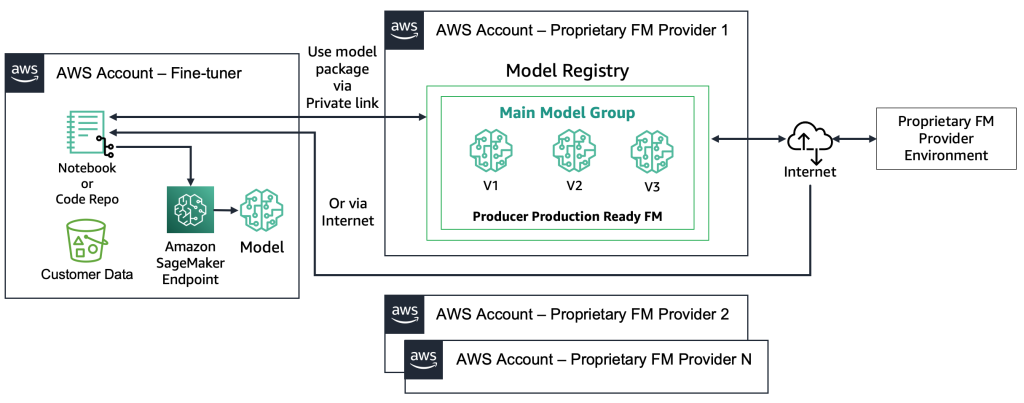
技術的な観点からは、ファインチューナーがサポートする必要があるアーキテクチャは、MLOpsのものに似ています(以下の図を参照)。ファインチューニングは、Amazon SageMaker Pipelinesを使用して、devでMLパイプラインを作成し、前処理、ファインチューニング(トレーニングジョブ)、ポスト処理を実行し、オープンソースのFMの場合はローカルモデルレジストリにファインチューニングされたモデルを送信する必要があります(それ以外の場合は、新しいモデルは独自のFMプロバイダー環境に保存されます)。その後、本番環境では、消費者のシナリオについて説明したようにモデルをテストする必要があります。最後に、モデルは本番環境で提供および監視されます。現在の(ファインチューニングされた)FMにはGPUインスタンスのエンドポイントが必要です。数百のモデルの場合、各ファインチューニングされたモデルを個別のエンドポイントに展開する必要がある場合、これはコストを増やす可能性があります。そのため、マルチモデルエンドポイントを使用してマルチテナンシの課題を解決する必要があります。
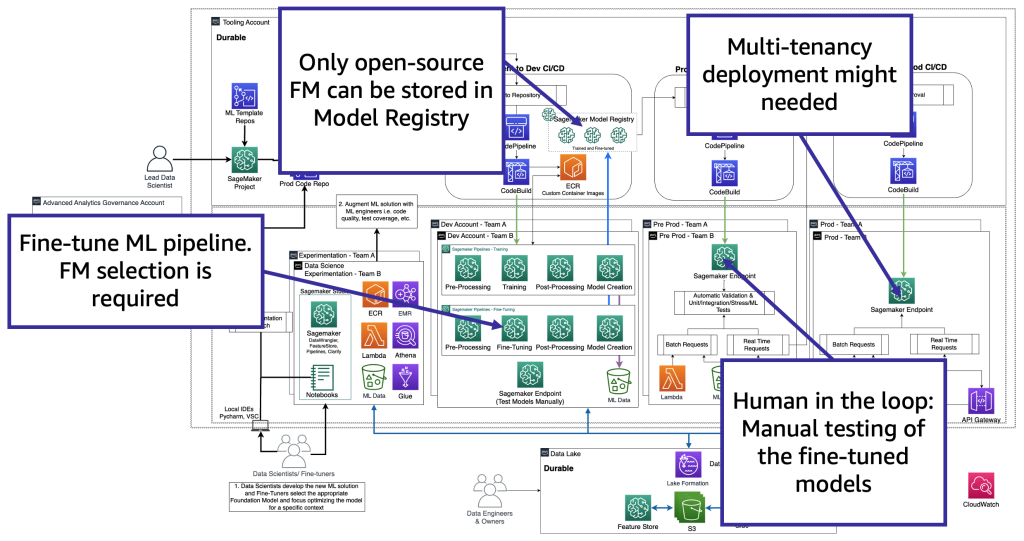
ファインチューナーは、特定のコンテキストに基づいてFMモデルを適応させ、ビジネス目的に使用します。つまり、ファインチューナーは、前のセクションで説明したように、生成的AIアプリケーションの開発、データレイクとデータメッシュ、およびMLOpsを含むすべてのレイヤーをサポートする必要がある消費者でもあります。
次の図は、ファインチューナーが生成的AIエンドユーザー向けに提供する必要のある完全なFMファインチューニングライフサイクルを示しています。
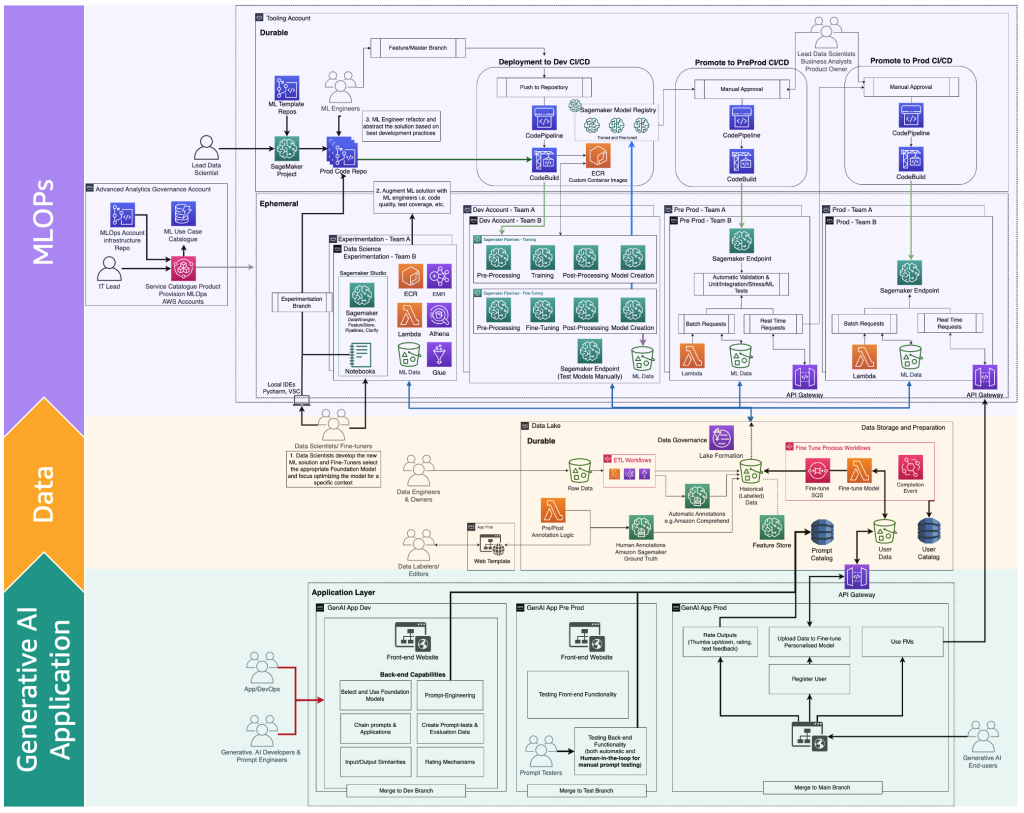
次の図は、主要なステップを示しています。
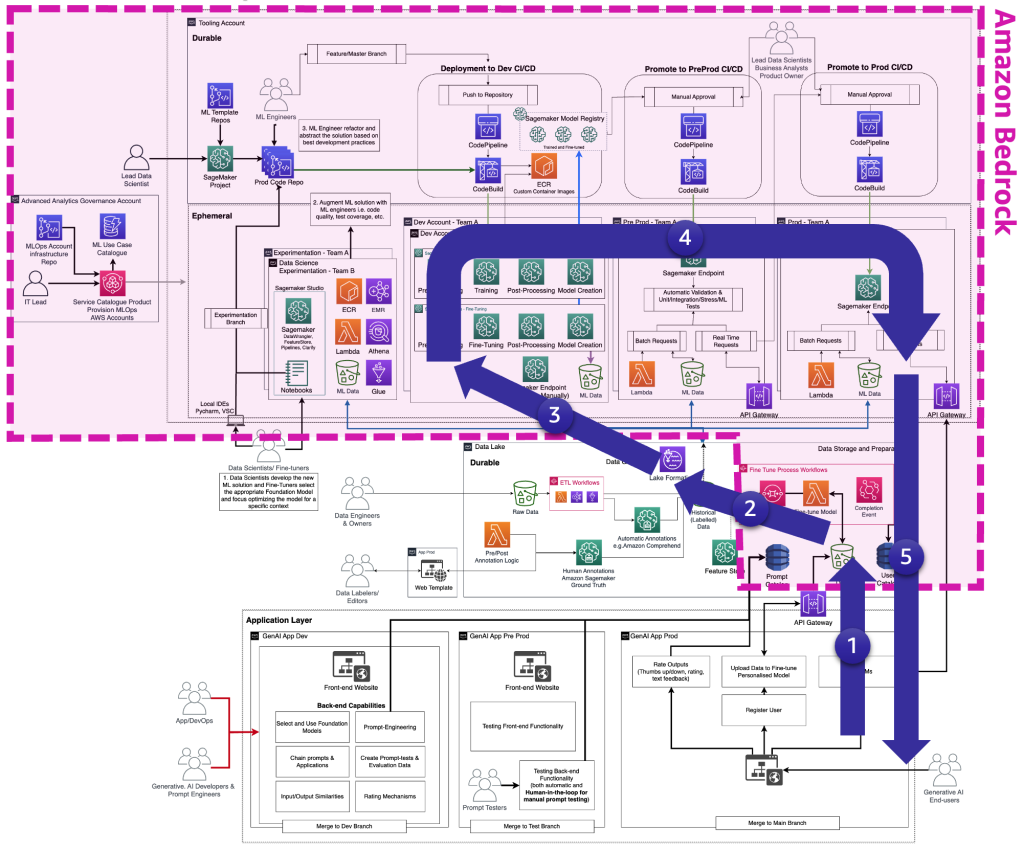
主なステップは次のとおりです。
- エンドユーザーが個人アカウントを作成し、プライベートデータをアップロードします。
- データはデータレイクに保存され、FMが期待する形式に前処理されます。
- これにより、ファインチューニングMLパイプラインがトリガーされ、モデルがモデルレジストリに追加されます。
- そこから、モデルは最小限のテストで本番環境に展開されるか、HILと手動承認ゲートで詳細なテストが行われます。
- ファインチューニングされたモデルがエンドユーザーに利用可能になります。
このインフラストラクチャは、非エンタープライズの顧客にとって複雑です。そのため、AWSはAmazon Bedrockをリリースし、このようなアーキテクチャの作成作業をオフロードし、ファインチューニングされたFMsを本番環境に近づける努力を行っています。
FMOpsとLLMOpsのペルソナとプロセスの違い
前述のユーザータイプのジャーニー(消費者、プロデューサー、ファインチューナー)に基づいて、以下の図に示すように、特定のスキルを持つ新しいペルソナが必要です。
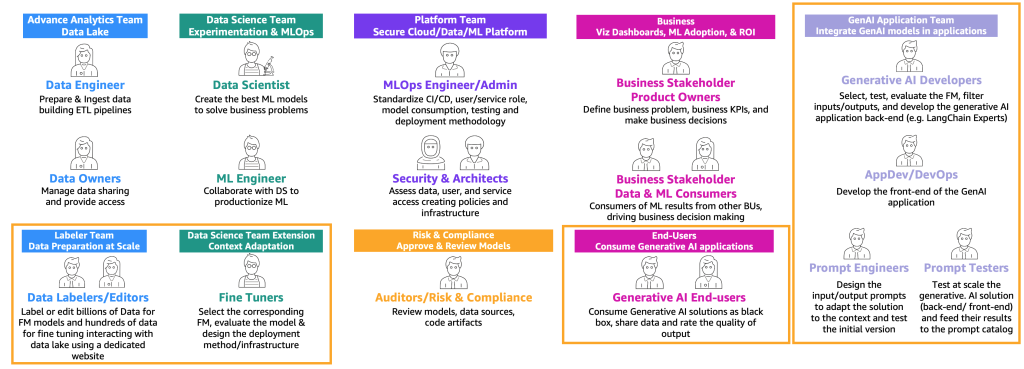
新しいペルソナは以下の通りです:
- データラベラーおよびエディター – これらのユーザーはテキスト、画像のペアなどのデータをラベル付けしたり、フリーテキストなどのラベル付けされていないデータを準備したりし、高度な分析チームやデータレイク環境を拡張します。
- ファインチューナー – これらのユーザーはFMsに関する深い知識を持ち、それらをチューニングする方法を知っており、クラシックなMLに焦点を当てるデータサイエンスチームを拡張します。
- 生成AI開発者 – 彼らはFMsの選択、プロンプトとアプリケーションの連鎖、および入力と出力のフィルタリングに関する深い知識を持っています。彼らは新しいチームである生成AIアプリケーションチームに所属しています。
- プロンプトエンジニア – これらのユーザーは入力と出力のプロンプトを設計し、ソリューションをコンテキストに適応させ、プロンプトカタログの初期バージョンをテストおよび作成します。彼らのチームは生成AIアプリケーションチームです。
- プロンプトテスター – 彼らは生成AIソリューション(バックエンドおよびフロントエンド)を大規模にテストし、その結果をプロンプトカタログと評価データセットの拡充にフィードします。彼らのチームは生成AIアプリケーションチームです。
- AppDevおよびDevOps – 彼らは生成AIアプリケーションのフロントエンド(ウェブサイトなど)を開発します。彼らのチームは生成AIアプリケーションチームです。
- 生成AIエンドユーザー – これらのユーザーは生成AIアプリケーションをブラックボックスとして使用し、データを共有し、出力の品質を評価します。
生成AIを組み込んだMLOpsプロセスマップの拡張版は、以下の図で示すことができます。
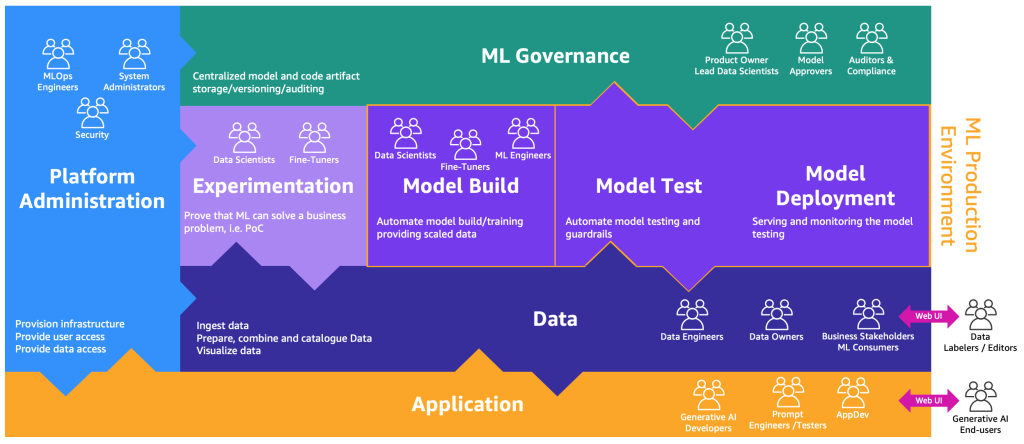
新しいアプリケーションレイヤーは、生成AI開発者、プロンプトエンジニア、テスター、およびAppDevが生成AIアプリケーションのバックエンドとフロントエンドを作成する環境です。生成AIエンドユーザーはインターネット(Web UIなど)を介して生成AIアプリケーションのフロントエンドとやり取りします。一方、データラベラーやエディターはデータレイクやデータメッシュのバックエンドにアクセスすることなくデータを前処理する必要があります。そのため、データと安全にやり取りするためのWeb UI(ウェブサイト)とエディターが必要です。SageMaker Ground Truthは、これらの機能を提供しています。
結論
MLOpsはMLモデルを効率的に本番化するのに役立ちます。ただし、生成AIアプリケーションを運用化するには、追加のスキル、プロセス、およびテクノロジーが必要であり、それがFMOpsとLLMOpsにつながります。この記事では、FMOpsとLLMOpsの主要な概念を定義し、人々、プロセス、テクノロジー、FMモデルの選択、評価という観点でMLOpsの機能との主な違いを説明しました。さらに、生成AI開発者の思考プロセスと生成AIアプリケーションの開発ライフサイクルを示しました。
今後は、今回議論したドメインごとのソリューションを提供し、FMモニタリング(毒性、偏り、幻覚など)やリトリーバルオーグメンテーションジェネレーション(RAG)などのサードパーティまたはプライベートデータソースのアーキテクチャパターンをFMOps/LLMOpsに統合する方法について、さらに詳細を提供します。
詳細については、Amazon SageMakerを使用した企業向けMLOps基盤のロードマップや、Amazon SageMaker JumpStartの事前学習モデルを使用したエンドツーエンドのソリューションの実装に関する情報を参照してください。
ご質問やコメントがありましたら、コメント欄にお願いします。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






