「SimCLRの最大の問題を修正する〜BYOL論文の解説」
Fixing the biggest problem of SimCLR Explanation of the BYOL paper
BYOLが全ての最新の自己教師あり学習フレームワークに新たなSOTAのアイデアを導入した方法
SimCLRは対照的学習のアイデアを成功裏に実装し、当時新たな最先端のパフォーマンスを達成しました!しかし、このアイデアには根本的な弱点があります!特定の拡張に対する感度と、大量のネガティブな例を提供するために非常に大きなバッチサイズが必要です。つまり、それらの負のサンプルへの依存は迷惑です。Bootstrap Your Own Latent(略称BYOL)は、DeepMindの研究者によって開発された自己教師ありモデルのトレーニングに完全に新しいアプローチを実装しており、恐らく表現の崩壊を回避しています!そして、それが最初から機能するということは完全に奇妙です…
では、デュアルビューパイプラインに戻り、崩壊を回避する別のアイデアを考えましょう。
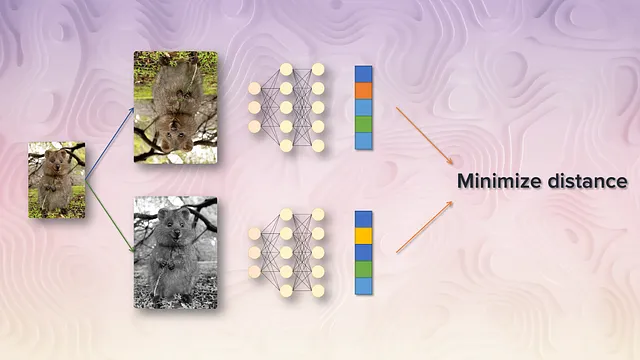
問題は、両方のパスで同じネットワークをトレーニングしていることで、それは単にすべての入力に対して同じ定数ベクトルを予測することを学ぶことができます。これは表現の崩壊と呼ばれます。
- 「信頼性の高い医療用AIツールの開発」
- ETHチューリッヒとマイクロソフトの研究者らが提案したX-Avatarは、人間の体の姿勢と顔の表情をキャプチャできるアニメーション可能な暗黙の人間アバターモデルです
- GoogleがNotebookLMを導入:あなた専用の仮想研究アシスタント
ここに狂ったアイデアがあります! 1つのネットワークのみをトレーニングし、2つ目のネットワークをランダムに初期化して重みを固定するだけだったらどうでしょう?!
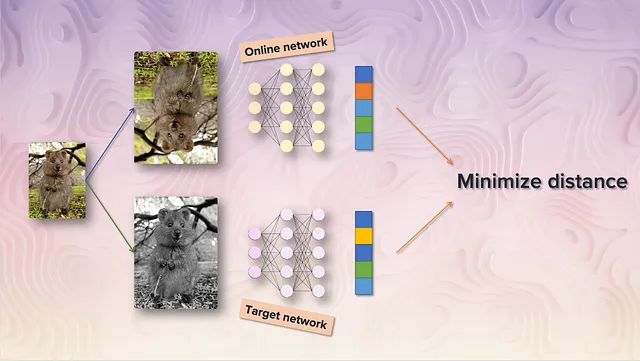
これは、生徒-教師モデルや知識蒸留と同じアイデアです。訓練可能なネットワークはオンラインネットワークと呼ばれ、ここでは固定されたネットワークがターゲットネットワークと呼ばれます。その方法で、オンラインネットワークは固定されたターゲットネットワークによって予測されるターゲットを近似することを学びます。
しかし、一体何が起こっているのでしょうか? これは無意味です! はい、これは崩壊を回避しますが、オンラインネットワークはランダムに初期化されたネットワークの予測を単にコピーすることを学んでいます!生成された表現は良くない可能性があります!これは真実です!BYOLの著者たちはこれを試して、オンラインネットワークでImageNetの線形評価プロトコルで18.8%のトップ1の精度を達成しましたが、ここでクレイジーな部分がやって来ます、ランダムに初期化されたターゲットネットワークは単独で1.4%しか達成しません!つまり、このような意味もないことが、ある表現から、ターゲットと呼ばれるものを予測するだけで新しい、潜在的に向上した表現をトレーニングすることができるということです。
この実験結果はBYOLの中核的な動機であり、それは現在の「自己蒸留ファミリー」と呼ばれる一部である自己教師あり学習の新しいアプローチでした。再び、BYOLは、異なる拡張ビューの下で同じ画像のオンラインネットワークがターゲットネットワークの表現を予測するようにオンラインネットワークをトレーニングします。
それについては、もちろん、18.8%のトップ1の精度よりも優れた結果を出すためにこの実験結果を基に構築する必要があります。オンラインネットワークとは異なる一連の重みを使用しながら、ターゲットネットワークを同じアーキテクチャにすることを著者は提案しています。ターゲットのパラメータは、オンラインのパラメータの指数移動平均です。それにもかかわらず、よく見ると、崩壊を防ぐものは何もありません!そして、著者自身も論文でそれを認めています。オンラインネットワークとターゲットネットワークは依然として時間とともに崩壊した表現に収束する可能性があります!
“While this objective admits collapsed solutions, e.g., outputting the same vector for all images, we empirically show that BYOL does not converge to such solutions.”
アーキテクチャ
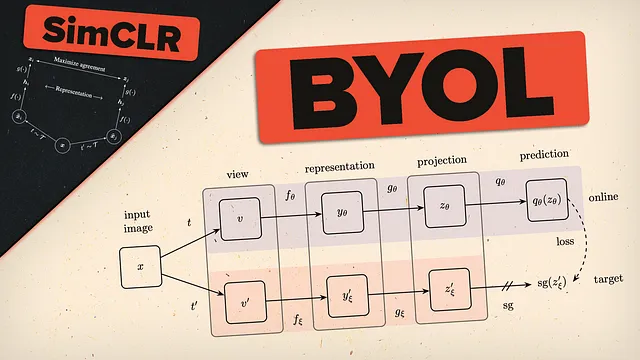
この魔法から一歩引いて、BYOLで使用される正確な構成図を見てみましょう。
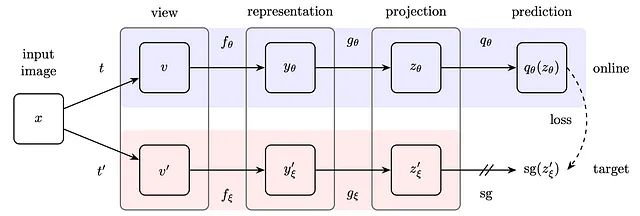
ここで、私たちがこれまでに議論してきたアイデアを具体的に見ることができます! 入力画像があり、2つの異なる視点を再度生成するために2つの異なるランダムな変換セットを適用します。オンラインパスとターゲットパスの2つの異なる予測パスを使用します。これらは同じネットワークアーキテクチャを使用しますが、異なるパラメータセットを使用します。ターゲットネットワークのパラメータは、オンラインネットワークの指数移動平均です。具体的には、τをスケーリングした以前のパラメータにオンラインネットワークのパラメータを1−τでスケーリングして追加することにより、ターゲットパラメータを更新します。
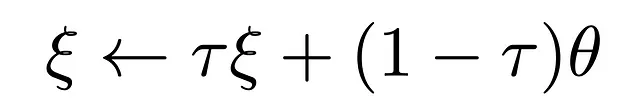
著者たちは、たとえばτ=0.99と設定しており、ターゲットパラメータをオンラインパラメータを0.01でスケーリングしてわずかに変更しています。
損失
最終的には対照的な例がなくなっているため、対照的な損失は必要ありません。BYOLの損失は、正規化された予測と正規化されたターゲットプロジェクション間の平均二乗誤差にすぎません。
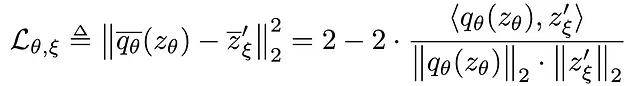
これがほとんどの損失です。見ての通り、各ブランチの2つの異なるレベルの出力間の損失を取っています。オンラインパイプラインとターゲットパイプラインは、次のネットワークで構成されています。下流タスクで使用する表現ネットワークfと、すでにSimCLRで見たプロジェクションネットワークg!オンラインブランチにはさらに予測ヘッドqが含まれており、オンラインパイプラインとターゲットパイプラインの間でアーキテクチャ全体が非対称になっています。この損失については、著者はビューvをオンラインネットワークを介して、ビューv’をターゲットネットワークを介して一度フィードし、2回目には2つのビューを入れ替えることで対称化しています。
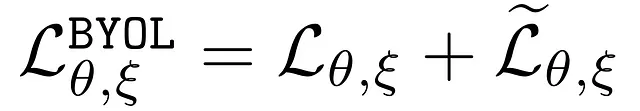
これがBYOLで提案された完全なアプローチです!
結果と直感
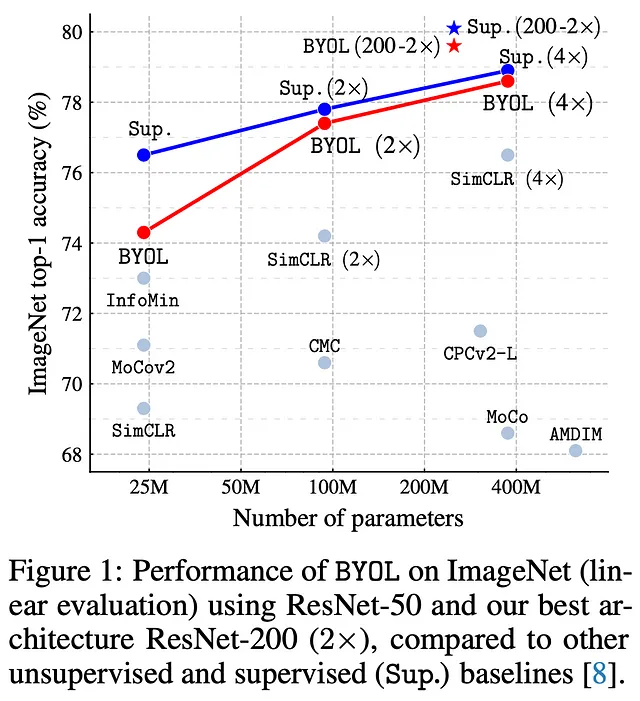
BYOLを使用してResNet50をトレーニングし、ImageNetで評価すると、もちろん、SimCLRなどの他の教師なしベースラインを上回り、完全に教師ありモデルに驚くほど近づきます!
これは、BYOLが常に他のモデルを上回ることを意味するわけではありません。
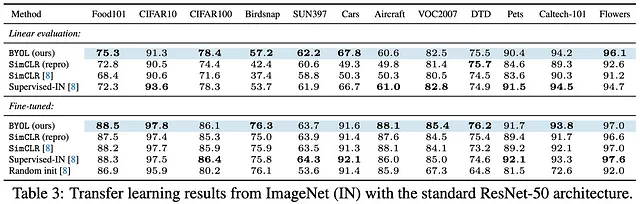
ImageNetで事前学習し、さまざまなベンチマーク間の転移学習結果を見ると、BYOLが常に最も優れているわけではありません!また、興味深いことに、著者の報告では、再現されたSimCLRの結果が元の論文から単に引用されたSimCLRの結果よりも優れていることがわかります。著者はこれらの結果について詳しく説明せず、再現されたSimCLRと単に参照されたSimCLRの結果を使用するタイミングについては非常に一貫性がありません。
しかし、それを置いておいて、彼らはSimCLRとのより深い比較を行っています! SimCLRなどの対照的なアプローチに対する代替手段が必要だった最も重要な理由は、ネガティブサンプルへの依存性に伴う感度を減らすことです。
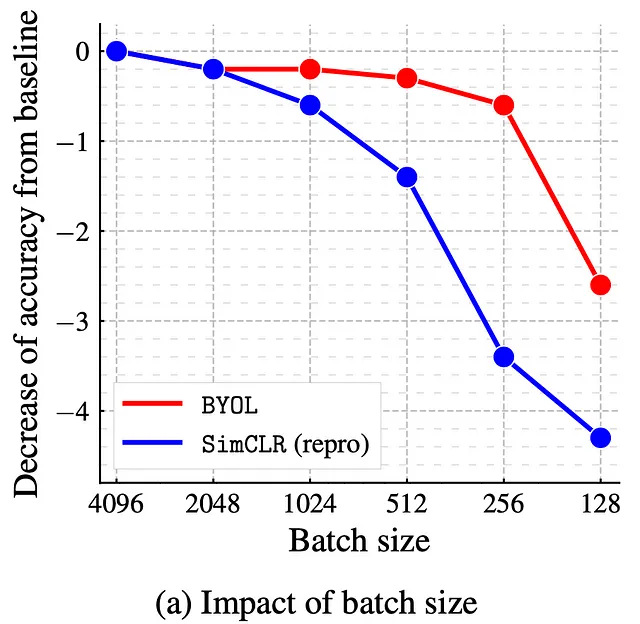
バッチサイズの効果に関して言えば、BYOLの優位性はSimCLRに比べて明らかです! BYOLは、SimCLRよりも小さなバッチサイズに対してはるかに敏感ではありません。それは理にかなっています!バッチサイズをわずか256サンプルに減らすと、BYOLのトップ1の正答率はわずか0.6%減少するだけですが、SimCLRでは3.4%減少します!バッチサイズを128サンプルに減らすことで生じる大きな減少は、バッチ正規化層への影響によるものです。
また、適用される拡張セットに対してSimCLRがどれだけ敏感であるかについてもすでに議論してきました!
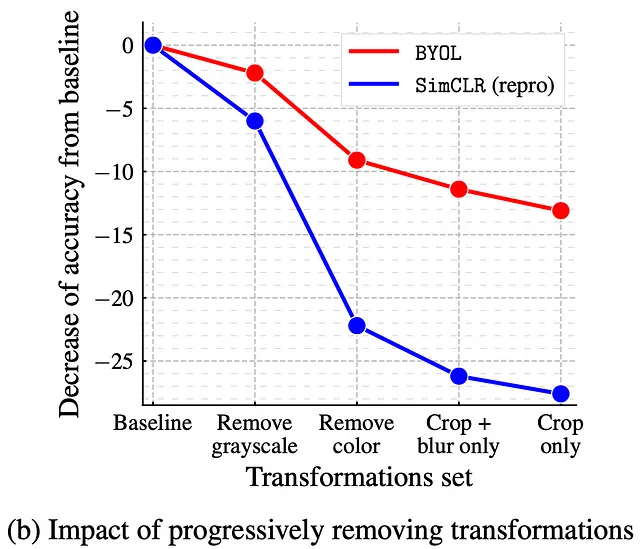
重要な拡張の除去に対しても、BYOLははるかに敏感ではありません。最終的に、クロッピングのみを行った場合、BYOLのトップ1の正答率は約13%減少しますが、SimCLRでは約28%減少します!SimCLRの場合、クロッピングとカラージッターの組み合わせに重要な依存があるとすでに述べたように、カラー拡張がない場合、モデルは単純にヒストグラムを区別することを学習します。代わりに、BYOLは、オンラインネットワークによって捉えられた情報を予測の改善に活かすために、ターゲット表現に保持するように動機付けられます。言い換えれば、同じ画像の拡張ビューが同じカラーヒストグラムを共有していても、BYOLは表現に追加の特徴を保持するように動機付けられます。そのため、少なくとも著者は、対照的な手法に比べてBYOLが画像拡張の選択に対してより堅牢であると信じています。
著者はそう信じているのですか?それは本当にクールですし、明らかに経験的に非常にうまく機能しています。しかし、なぜそれが機能するのでしょうか?なぜそれが崩壊しないのでしょうか?著者は、このアプローチが崩壊を回避する数学的な証明を持っていないが、何がうまくいき、何がうまくいかないかについていくつかの経験的な観察を行い、なぜBYOLが機能するのかについていくつかのアイデアを仮説化しています。
おおまかな直感をつかんでみましょう!BYOLは、オンラインネットワークの重みの指数移動平均であるターゲットネットワークの射影表現zを使用し、追加の予測子を使用してオンライン予測のターゲットとしています!これにより、ターゲットネットワークの重みはオンラインネットワークの重みの遅延およびより安定したバージョンを表します。著者は、EMAターゲットネットワークと予測子の適切な組み合わせの重要性を直感的に理解するためにいくつかの除去研究を実施しています。
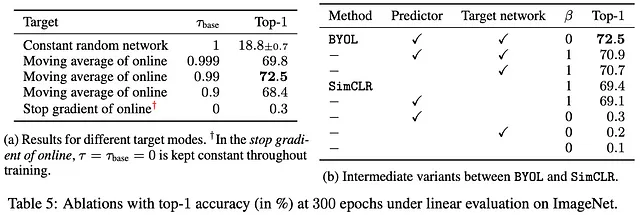
左の表では、異なるEMA計算下でモデルのパフォーマンスがどのように変化するかを示しています。最初の場合、τ = 1では、ターゲットネットワークは決して更新されないランダムに初期化されたネットワークです。最後の場合、τ = 0では、ターゲットモデルはオンラインネットワークの正確なコピーであり、直接的に崩壊した表現をもたらします。その他の場合は、最適なτパラメータの検索を表しています。しかし、後に指数移動平均は必要ないことが確認されました。ターゲットネットワークをオンラインネットワークの直接的なコピーとすることができます。つまり、予測子がより頻繁に更新されるか、バックボーンと比較して学習率が大きい場合でもです。しかし、それはそれによってトレーニングの安定性を提供し、実際にSimCLRを使用してパフォーマンスを向上させることができます。
よし、右の表は負のサンプルの追加(2行目)の効果を示していますが、これはパフォーマンスを低下させます(!)、および予測子の除去(3行目)によって、オンラインとターゲットネットワークの射影表現間の損失を直接計算します。それにもかかわらず、これらの操作は理論的には崩壊を完全に回避するわけではありません。それは単に「非常に困難」で「不安定な状態にする」だけです。
しかし、まあ、本題に戻りましょう。もうすぐ終わりです。この新しい自己教師あり学習の仕組みを理解しました。オンラインネットワークとターゲットネットワークと呼ばれる2つのニューラルネットワークを使用し、相互作用してお互いから学習するSelf-Distillationファミリーの一部であるBYOLを見てきました。このアプローチの素晴らしい利点は、負のペアに依存せずに優れた性能を達成することです!
では、このアイデアをさらに改善するにはどうすればよいでしょうか?どの技術が機械学習のあらゆる領域を支配し、素晴らしい結果をもたらしているのでしょうか?
[一時停止]
正解です。トランスフォーマーです。
ついにこの可視化の背後にあるアプローチを理解できるようになりました!

最新の最先端モデルの動作方法や、そこから得られる洞察について知りたい場合は、次の投稿をご覧ください!Facebook AI ResearchのMathilde Caron et. al.による有名なDINO論文を紹介します!
もしまだアップされていない場合は、アップロードを見逃さないようにフォローしてくださいね!
P.S.:もしこのコンテンツやビジュアルが気に入った場合は、私のYouTubeチャンネルもご覧いただけます。そこでは同様のコンテンツをより美しいアニメーションとともに公開しています!
すべての画像は、著者が使用権を持つ画像または参照元によって作成されたBYOL論文から取られています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- DeepMindからの新しいAI研究では、有向グラフに対して二つの方向と構造に敏感な位置符号化を提案しています
- 新たな人工知能の研究が、言語モデルの中でマルチモーダルな連鎖思考推論を提案し、ScienceQAにおいてGPT-3.5を16%上回る結果を示しました(75.17% → 91.68%)
- 「UTオースティン大学の研究者が、安定した拡散を用いたAI手法「PSLD」を紹介追加のトレーニングなしにすべての線形問題を解決する」
- UCバークレーの研究者たちは、FastRLAPを提案していますこれは、深層強化学習(Deep RL)と自律練習を通じて高速運転を学ぶためのシステムです
- マサチューセッツ州ローウェル大学の研究者たちは、高ランクのトレーニングに低ランクの更新を使用する新しいAIメソッドであるReLoRAを提案しています
- オックスフォードの研究者たちは、「Farm3D」というAIフレームワークを提案していますこのフレームワークは、2D拡散を蒸留して学習し、ビデオゲームなどのリアルタイムアプリケーションで利用できる関節のある3Dアニマルを生成することができます
- コロンビア大学とDeepMindの研究者が、GPATというトランスフォーマーベースのモデルアーキテクチャを紹介しましたこのモデルは、各パーツの形状が目標の形状にどのように対応しているかを推測し、パーツのポーズを正確に予測します





