「Colabノートブックで自分のLlama 2モデルを微調整する」
Fine-tuning your Llama 2 model in a Colab notebook.
LLMファインチューニングの実践的な紹介

LLaMA v1のリリースに伴い、アルパカ、ビクーニャ、ウィザードLMなど、ファインチューニングされたモデルのカンブリア爆発が見られました。このトレンドは、OpenLLaMA、ファルコン、XGenなどの商業利用に適したライセンスを持つ独自のベースモデルを立ち上げるさまざまな企業によるリリースを促しました。Llama 2のリリースでは、両方の側面のベストな要素が組み合わされ、効率的なベースモデルとより許容性の高いライセンスが提供されています。
2023年の前半には、API(OpenAI APIなど)を使用して、大規模言語モデル(LLM)に基づくインフラストラクチャを作成するための広範な使用が広まりました。LangChainやLlamaIndexなどのライブラリがこのトレンドに重要な役割を果たしました。年の後半に移るにつれて、これらのモデルのファインチューニングが標準的な手順となる見込みです。このトレンドは、様々な要因によって推進されています:コスト削減の可能性、機密データの処理能力、ChatGPTやGPT-4などの有名なモデルを特定のタスクで超える性能を開発する可能性など。
この記事では、なぜファインチューニングが機能するのか、Google Colabノートブックで実装して独自のLlama 2モデルを作成する方法について見ていきます。通常通り、コードはColabとGitHubで利用できます。
🔧 LLMファインチューニングの背景
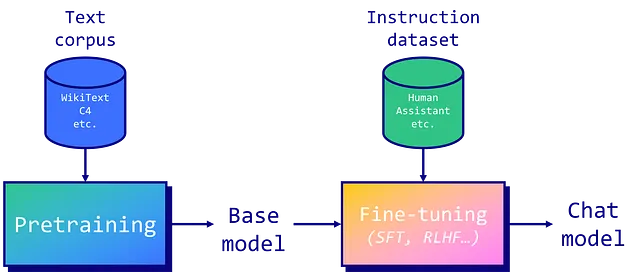
LLMは、大量のテキストコーパスに対して事前学習されます。Llama 2の場合、トレーニングセットの構成については、トークンの2兆個という長さ以外にはほとんど知られていません。比較すると、BERT(2018年)は「ただ」BookCorpus(8億単語)と英語のWikipedia(25億単語)で訓練されました。経験から言えば、これは非常に費用がかかり、時間のかかるプロセスで、ハードウェアの問題も多いです。詳細については、OPT-175Bモデルの事前訓練に関するMetaのログブックを読むことをおすすめします。
事前学習が完了すると、Llama 2などの自己回帰モデルは、シーケンス内の次のトークンを予測することができます。しかし、これだけでは…
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





