Amazon SageMakerのHugging Face推定器とモデルパラレルライブラリを使用してGPT-Jを微調整する
Fine-tuning GPT-J using Amazon SageMaker's Hugging Face estimator and model parallel library.
GPT-JはEleuther AIによってリリースされたオープンソースの60億パラメータモデルです。このモデルはPileでトレーニングされ、言語処理の様々なタスクを実行することができます。テキスト分類、トークン分類、テキスト生成、質問応答、エンティティ抽出、要約、感情分析など、幅広い用途に対応することができます。GPT-Jは、Ben WangのMesh Transformer JAXを使用してトレーニングされたTransformerモデルです。
この記事では、Amazon SageMaker分散モデル並列ライブラリを使用して大規模言語モデル(LLMs)をトレーニングするためのガイドとベストプラクティスを紹介します。SageMakerで6億パラメータのGPT-Jモデルを簡単にトレーニングする方法を学びます。最後に、トレーニング時間を短縮するのに役立つSageMaker分散モデル並列性の主な機能を共有します。
Transformerニューラルネットワーク
Transformerニューラルネットワークは、シーケンス・トゥ・シーケンスのタスクを解決するための人気のある深層学習アーキテクチャです。学習メカニズムとしてアテンションを使用し、人間レベルに近いパフォーマンスを実現しています。以前の自然言語処理(NLP)モデルの世代に比べ、アーキテクチャの他の有用な特性には、分散、スケーリング、事前学習の能力があります。Transformerベースのモデルは、検索、チャットボットなどのテキストデータを扱うさまざまなユースケースに適用することができます。Transformerは、大規模なデータセットから知能を獲得するために事前学習の概念を使用します。事前学習されたTransformerはそのまま使用することも、ビジネスに特化したより小さなデータセット上で微調整することもできます。
SageMakerでのHugging Face
Hugging Faceは、Transformerアーキテクチャに基づく最先端のNLP技術を提供する最も人気のあるオープンソースライブラリを開発する会社です。Hugging Face transformers、tokenizers、datasetsライブラリは、複数の言語で事前学習されたモデルをダウンロードし、予測するためのAPIとツールを提供します。SageMakerは、Hugging FaceモデルハブからHugging Face estimatorを使用してHugging Faceモデルを直接トレーニング、微調整、推論実行することができます。この統合により、Hugging Faceモデルをドメイン固有のユースケースにカスタマイズすることが容易になります。SageMaker SDKは、SageMakerが提供するトレーニングおよびモデルサービング用の事前構築されたDockerイメージであるAWS Deep Learning Containers(DLC)を使用しています。DLCはAWSとHugging Faceの協力によって開発されました。この統合は、Hugging Face transformers SDKとSageMaker分散トレーニングライブラリの統合も提供し、GPUクラスタ上でトレーニングジョブを拡大することができます。
- Amazon SageMakerを使用してOpenChatkitモデルを利用したカスタムチャットボットアプリケーションを構築する
- Amazon SageMaker で大規模なモデル推論 DLC を使用して Falcon-40B をデプロイする
- Amazon SageMakerを使用した生成型AIモデルにおいて、Forethoughtがコストを66%以上削減する方法
SageMaker分散モデル並列ライブラリの概要
モデル並列化は、複数のデバイスにわたってまたは内部でディープラーニングモデルをパーティションする分散トレーニング戦略です。より多くのレイヤーとパラメータを持つディープラーニング(DL)モデルは、コンピュータビジョンやNLPなどの複雑なタスクで優れたパフォーマンスを発揮します。ただし、単一のGPUのメモリに格納できる最大モデルサイズには制限があります。GPUメモリの制約は、次のようなDLモデルのトレーニングにおいてボトルネックとなる可能性があります。
- パラメータ数に比例してモデルのメモリフットプリントがスケーリングされるため、トレーニングできるモデルのサイズが制限される
- トレーニング中の1つのGPUあたりのバッチサイズを制限することで、GPUの利用率とトレーニング効率が低下する
SageMakerには、単一のGPU上でモデルをトレーニングする制限に対処するための分散モデル並列ライブラリが含まれています。さらに、ライブラリは、EFAサポートデバイスを利用して最適な分散トレーニングを実現し、低レイテンシ、高スループット、OSバイパスでのノード間通信パフォーマンスを向上させます。
60億パラメータなどの大規模なモデルは、単一のチップを超えるGPUメモリフットプリントを持つため、複数のGPUに分割することが必要になります。SageMakerモデルパラレル(SMP)ライブラリを使用すると、モデルを複数のGPUに自動的に分割することができます。SageMakerモデルパラレルでは、SageMakerがモデルの計算とメモリ要件を分析するための最初のプロファイリングジョブを実行します。この情報を使用して、目的を最大化するために、スピードを最大化またはメモリフットプリントを最小化するなど、モデルをGPUに分割する方法が決定されます。
また、利用可能なGPUの全体的な利用率を最大化するためのオプションのパイプライン実行スケジューリングもサポートしています。順方向パス中のアクティベーションの伝搬と逆方向パス中の勾配の伝搬には、連続的な演算が必要であり、GPUの利用率が制限されます。SageMakerは、パイプライン実行スケジュールを利用して、複数のGPUで並列処理されるマイクロバッチにミニバッチを分割することで、連続的な演算の制約を克服します。SageMakerモデルパラレリズムは、2つのパイプライン実行モードをサポートしています。
- 単純なパイプライン – このモードでは、各マイクロバッチのフォワードパスが完了した後にバックワードパスを開始します。
- 交互パイプライン – このモードでは、可能な限りマイクロバッチのバックワードランが優先されます。これにより、アクティベーションに使用されるメモリをより迅速に解放し、メモリをより効率的に使用できます。
テンソル並列処理
各レイヤーまたは nn.Modules は、テンソル並列処理を使用してデバイス間で分割され、並行して実行されます。4つのレイヤーを持つモデルを2つのGPUで2方向のテンソル並列処理 ("tensor_parallel_degree": 2) を達成するためにライブラリがどのようにモデルを分割するかの最も単純な例は、以下の図に示されています。各モデルレプリカのレイヤーは二等分され、2つのGPUの間で分配されます。この例ではデータ並列の度合いは8で、モデル並列構成にはさらに"pipeline_parallel_degree": 1 および "ddp": Trueが含まれます。ライブラリは、テンソル分散モデルのレプリカ間の通信を管理します。
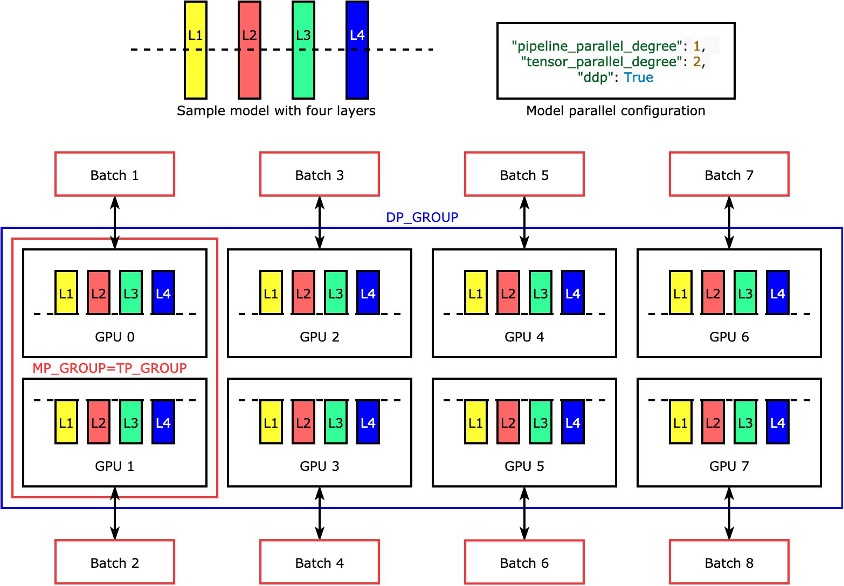
この機能の利点は、どのレイヤーまたはレイヤーのサブセットにテンソル並列処理を適用するか選択できることです。PyTorchのテンソル並列処理およびその他のメモリ節約機能の詳細およびパイプラインおよびテンソル並列処理の組み合わせの設定方法については、「PyTorchのSageMakerモデル並列ライブラリの拡張機能」を参照してください。
SageMakerシャードデータ並列処理
シャードデータ並列処理は、モデルのトレーニング状態(モデルパラメータ、勾配、およびオプティマイザの状態)をデータ並列グループのGPUに分割するメモリ節約型の分散トレーニング技術です。
トレーニングジョブを大規模なGPUクラスターにスケーリングする場合、トレーニング状態を複数のGPUにシャーディングすることで、モデルの1つ当たりのGPUメモリフットプリントを減らすことができます。これには2つの利点があります。1つ目は、通常のデータ並列処理ではメモリ不足になる大型モデルを適合させることができることです。2つ目は、GPUメモリを解放してバッチサイズを増やすことができます。
通常のデータ並列処理技術は、データ並列グループのGPUにトレーニング状態を複製し、AllReduce操作に基づいて勾配集約を実行します。したがって、シャードデータ並列処理は、通信オーバーヘッドとGPUメモリ効率の間のトレードオフを導入します。シャードデータ並列処理を使用すると、通信コストが増加しますが、GPU当たりのメモリフットプリント(アクティベーションのメモリ使用量を除く)は、シャードデータ並列処理度によって分割されるため、GPUクラスターに大型モデルを適合させることができます。
SageMakerは、MiCS実装を介してシャードデータ並列処理を実装しています。詳細については、「AWS上での巨大モデルトレーニングの近似的スケーリング」を参照してください。
トレーニングジョブにシャードデータ並列処理を適用する方法の詳細については、「シャードデータ並列処理」を参照してください。
SageMakerモデル並列ライブラリの使用
SageMakerモデル並列ライブラリは、SageMaker Python SDKに付属しています。ライブラリを使用するには、SageMaker Python SDKをインストールする必要があります。SageMakerノートブックカーネルにはすでにインストールされています。PyTorchトレーニングスクリプトがSMPライブラリの機能を利用するようにするには、以下の変更を行う必要があります。
smp.init()呼び出しを使用して、smpライブラリをインポートおよび初期化します。- 初期化された後、
smp.DistributedModelラッパーでモデルをラップし、返されたDistributedModelオブジェクトをユーザーモデルの代わりに使用します。 - オプティマイザの状態では、モデルオプティマイザの周りに
smp.DistributedOptimizerラッパーを使用し、smpがオプティマイザの状態を保存およびロードできるようにします。フォワードとバックワードパスのロジックは別の関数として抽象化し、その関数にsmp.stepデコレータを追加します。基本的に、フォワードパスとバックプロパゲーションは、smp.stepデコレータを機能に配置して実行する必要があります。これにより、トレーニングジョブを起動する際に指定されたマイクロバッチの数にテンソル入力を分割できます。 - 次に、
torch.cuda.set_deviceAPIに続いて.to()API呼び出しを使用して、現在のプロセスで使用されるGPUに入力テンソルを移動します。 - 最後に、バックプロパゲーションでは、
torch.Tensor.backwardおよびtorch.autograd.backwardを置き換えます。
以下のコードを参照してください:
@smp.step
def train_step(model, data, target):
output = model(data)
loss = F.nll_loss(output, target, reduction="mean")
model.backward(Loss)
return output, loss
with smp.tensor_parallelism():
model = AutoModelForCausalLM.from_config(model_config)
model = smp.DistributedModel (model)
optimizer = smp. DistributedOptimizer(optimizer)SageMakerモデルパラレルライブラリのテンソル並列処理は、以下のHugging Faceトランスフォーマーモデルのすべてをサポートしています:
- GPT-2、BERT、RoBERTa (SMPライブラリ v1.7.0以降で利用可能)
- GPT-J (SMPライブラリ v1.8.0以降で利用可能)
- GPT-Neo (SMPライブラリ v1.10.0以降で利用可能)
SMPライブラリでのパフォーマンスチューニングのベストプラクティス
大型モデルのトレーニングの際は、以下のステップを考慮して、GPUメモリに適切なバッチサイズでモデルを収めるようにしてください:
- p4dやp4deなど、高速GPUメモリと高帯域幅のインターコネクトを備えたインスタンスを使用することをお勧めします。
- オプティマイザの状態シャーディングは、ほとんどの場合で有効にすることができ、モデルのコピーが1つ以上ある場合に役立ちます(データパラレリズムが有効になっています)。
modelparallel構成で"shard_optimizer_state": Trueを設定することで、オプティマイザの状態シャーディングをオンにすることができます。 - アクティベーションチェックポイントを使用すると、モデルの特定のレイヤーのアクティベーションをクリアして、モデルの選択されたモジュールのバックワードパス中に再計算することで、メモリ使用量を削減することができます。
- アクティベーションオフロードを使用すると、さらにメモリ使用量を削減することができる追加の機能です。アクティベーションチェックポイントとパイプライン並列処理がオンになっており、マイクロバッチの数が1より大きい場合に
"offload_activations": Trueをmodelparallel構成で設定して使用してください。 - テンソル並列処理を有効にし、次数を2の累乗で増加させます。通常、パフォーマンス上の理由から、テンソル並列処理はノード内に制限されます。
SMPライブラリを使用してSageMakerでGPT-Jをトレーニングおよびチューニングするための多数の実験を実施しました。エポックあたりのGPT-Jトレーニング時間をSageMakerで58分から10分未満に短縮することに成功しました。初期化、モデルおよびデータセットのAmazon Simple Storage Service(Amazon S3)からのダウンロードには1分未満、GPUをトレースデバイスとし、トレーシングおよび自動パーティショニングには1分未満、1つのml.p4d.24xlargeインスタンスでテンソル並列処理を使用してエポックを8分でトレーニングしました。
トレーニング時間を短縮するためのベストプラクティスとして、SageMakerでGPT-Jをトレーニングする場合は、以下をお勧めします:
- 事前学習済みモデルをAmazon S3に保存する
- FP16精度を使用する
- GPUをトレースデバイスとして使用する
- 自動パーティショニング、アクティベーションチェックポイント、およびオプティマイザの状態シャーディングを使用する:
auto_partition: Trueshard_optimizer_state: True
- テンソル並列処理を使用する
- ml.p3.16xlarge、ml.p3dn.24xlarge、ml.g5.48xlarge、ml.p4d.24xlarge、またはml.p4de.24xlargeのような複数のGPUを備えたSageMakerトレーニングインスタンスを使用する。
SMPライブラリを使用したSageMakerでのGPT-Jモデルのトレーニングとチューニング
Amazon SageMaker Examplesパブリックリポジトリには、機能するステップバイステップのコードサンプルが用意されています。training/distributed_training/pytorch/model_parallel/gpt-jフォルダに移動します。テンソル並列処理の例では、gpt-jフォルダを選択し、train_gptj_smp_tensor_parallel_notebook.jpynb Jupyterノートブックを開き、パイプライン並列処理の例ではtrain_gptj_smp_notebook.ipynbを選択します。Amazon SageMakerワークショップでコードの解説を行っています。
このノートブックでは、SageMakerモデル並列処理ライブラリが提供するテンソル並列機能の使用方法について説明します。GLUE sst2データセットでのGPT-JモデルのFP16トレーニングをテンソル並列とパイプライン並列で実行する方法を学びます。
概要
SageMakerモデル並列ライブラリには、いくつかの機能があります。SageMaker上でLLMのコストを削減し、トレーニングを高速化することができます。また、Amazon SageMaker Examples公開リポジトリでBERT、GPT-2、GPT-Jのサンプルコードを学び、実行することもできます。SMPライブラリを使用したLLMのトレーニングについてのAWSのベストプラクティスについては、以下のリソースを参照してください:
- SageMaker Distributed Model Parallelism Best Practices
- Training large language models on Amazon SageMaker: Best practices
当社の顧客がSageMaker上で低レイテンシーのGPT-J推論を実現した方法については、How Mantium achieves low-latency GPT-J inference with DeepSpeed on Amazon SageMaker を参照してください。
LLMの市場投入までの時間を短縮し、コストを削減するには、SageMakerが役立ちます。何を構築するかお知らせください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




