「ヘイスタックの中の針を見つける – Jaccard類似度のための検索インデックス」 翻訳結果は以下の通りです: 「ヘイスタックの中の針を見つける – Jaccard類似度のための検索インデックス」
Finding needles in a haystack - search index for Jaccard similarity
基本的な概念から正確なおよび近似的なインデックスまで

ベクトルデータベースは、大規模言語モデル(LLM)の外部メモリとして注目されています。これらのベクトルデータベースは、近似最近傍(ANN)インデックスと呼ばれる10年前の研究を基にした新しいシステムです。これらのインデックスアルゴリズムは、多次元ベクトル(例:float32[])を取り、高次元空間でクエリベクトルの近似近傍を見つけるのをサポートするデータ構造を構築します。これは、Googleマップがあなたの家の緯度と経度を指定すると、あなたの隣人の家を見つけるようなものですが、ANNインデックスははるかに高次元空間で動作します。
この研究分野は数十年前にさかのぼる歴史があります。90年代後半、MLの研究者たちは画像や音声などのマルチメディアデータ用に数値特徴を手作りしていました。これらの特徴ベクトルに基づく類似検索は、自然な問題となりました。しばらくの間、研究者たちはこの領域で混雑しました。この学術的なバブルは、ある画期的な論文「最近傍探索はいつ意味を持つのか?」によって破られました。この論文は、手作り特徴の高次元空間における最近傍はほとんど意味を持たないということを伝えるものであり、興味深いトピックですが、それは別の投稿の対象です。今日でも、私はSIFT-128データセット上のパフォーマンス数値を公開する研究論文やベクトルデータベースのベンチマークを見かけますが、これは意味のない類似性を持つ手作り特徴ベクトルで構成されています。
手作り特徴に関する騒音にもかかわらず、有意義な類似性を持つ1つの高次元データ型に焦点を当てた収穫の多い研究分野があります:集合とJaccardです。
この投稿では、集合に対するJaccard類似性の検索インデックスについて説明します。基本的な概念から始めて、正確なおよび近似的なインデックスに進みます。
- 「プラットプス:データセットのキュレーションとアダプターによる大規模言語モデルの向上」
- 「大規模な言語モデルとベクトルデータベースを使用してビデオ推薦システムを構築した方法」
- 「Amazon Redshift」からのデータを使用して、Amazon SageMaker Feature Storeで大規模なML機能を構築します
集合とJaccard
集合は、単一の要素のコレクションです。Spotifyで気に入った曲は集合です。先週のリツイートしたツイートも集合です。このブログ投稿から抽出された一意のトークンも集合を形成します。集合は、音楽の推薦、ソーシャルネットワーク、および盗作検知などのアプリケーションシナリオでデータポイントを表す自然な方法です。
Spotifyで、私は以下のアーティストをフォローしています:
[the weekend, taylor swift, wasia project]
そして、娘は以下のアーティストをフォローしています:
[the weekend, miley cyrus, sza]
私たちの音楽の趣味の類似性を測る合理的な方法は、私たちが両方ともフォローしているアーティストの数、つまり共通の要素の数を見ることです。この場合、私たちは両方ともthe weekendをフォローしているため、共通の要素の数は1です。
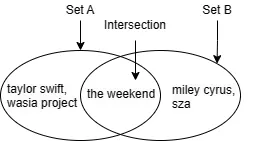
ただし、別のユーザーペアでは、それぞれが100人のアーティストをフォローしていて、共通の要素の数も1ですが、その趣味の類似性は私の娘と私の間の類似性よりもはるかに小さいはずです。異なるユーザーペア間で測定を比較可能にするために、共通部分のサイズを全体のサイズで正規化します。この方法では、私の娘と私のフォローの類似性は1 / 5 = 0.2であり、他のユーザーペアのフォローの類似性は1 / 199 ≈ 0.005です。これがJaccard類似性と呼ばれるものです。
集合Aと集合Bに対するJaccard類似性の式は次のとおりです:
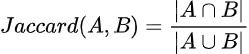
なぜ高次元データ型をセットとするのでしょうか? セットは「ワンホット」ベクトルとしてエンコードすることができます。このベクトルの次元は、すべての可能な要素(例:Spotifyのすべてのアーティスト)に1対1でマップされます。このベクトルの次元には、セットがこの次元に対応する要素を含んでいる場合は値が1、それ以外の場合は0が割り当てられます。したがって、私のフォローしているアーティストのベクトル化されたセットは次のようになります:
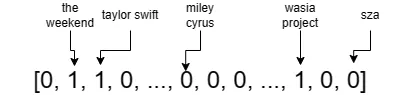
ここで、2番目、3番目、最後から3番目の次元はthe weekend、taylor swift、およびwasia projectです。Spotifyには1000万以上のアーティストがいるため、このようなベクトルは非常に高次元であり、非常に疎です。ほとんどの次元は0です。
Jaccard検索のための逆インデックス
人々は素早く物事を見つけたいので、コンピュータサイエンティストはソフトウェアアプリケーションの検索パフォーマンスを満足させるために、インデックスと呼ばれるデータ構造を考案しました。具体的には、Jaccard検索インデックスはセットのコレクションに基づいて構築され、クエリセットが与えられると、クエリセットとのJaccard係数が最も高いk個のセットを返します。
Jaccardの検索インデックスは、逆インデックスと呼ばれるデータ構造に基づいています。逆インデックスは非常にシンプルなインターフェースを持っています。セットの要素(例:the weekend)を入力すると、入力要素を含むセットのIDのリストを返します(例:[ 32, 231, 432, 1322, ...])。逆インデックスは、キーがすべての可能なセット要素であり、値がセットIDのリストであるルックアップテーブルです。この例では、逆インデックスの各リストはアーティストのフォロワーのIDを表しています。
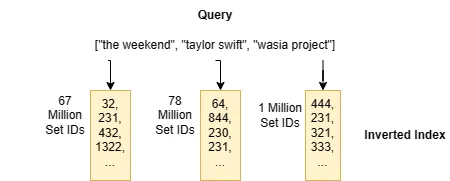

これが「逆インデックス」と呼ばれる理由がわかります:要素を含むセットを見つけるために、要素から逆に進むことができます。
正確な検索アルゴリズム
逆インデックスは、検索の高速化に非常に強力なデータ構造です。逆インデックスを使用すると、検索時にクエリセットと少なくとも1つの要素を共有するセットのIDのみを処理すればよくなります。数百万のセットがある場合、すべてのセットを比較する必要はありません。逆インデックスリストからセットIDを直接取得できます。
このアイデアは、次の検索アルゴリズムによって実装されています:
def search_top_k_merge_list(index, sets, q, k): """逆インデックスを使用したトップ-k Jaccardの検索。 Args: index: 逆インデックス、キーはセットの要素 sets: セットのルックアップテーブル、キーはセットID q: クエリセット k: 検索パラメータk Returns: list: 最大k個のセットID。 """ # 候補のための空のルックアップテーブルを初期化します。 candidates = defaultdict(0) # q内のセット要素を反復処理します。 for x in q: ids = index[x] # インデックスからセットIDのリストを取得します。 for id in ids: candidates[id] += 1 # 重複サイズのインターセクションのためのカウントを増やします。 # これでcandidates[id]には、ID idを持つセットのインターセクションサイズが格納されます。 # Inclusion-Exclusion原理に基づいて、インターセクションサイズとセットサイズを使用してJaccardを計算するための単純なルーチンです。 jaccard = lambda id: candidates[id] / (len(q) + len(sets(id) - candidates[id])) # Jaccardによって順序付けられたトップ-k候補を見つけます。 return sorted(list(candidates.keys()), key=jaccard, reverse=True)[:k]プレーンな英語で言えば、アルゴリズムはクエリセットの要素にマッチする反転インデックスリストごとに進み、候補テーブルを使用して各セットIDが現れる回数を追跡します。セットIDがn回現れる場合、インデックス付けされたセットはクエリセットとn個の重複要素を持ちます。最後に、アルゴリズムは候補テーブルのすべての情報を使用してJaccard類似度を計算し、最も類似したセットのIDを返します。
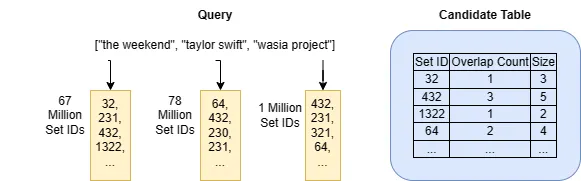
search_top_k_merge_listアルゴリズムは、(1) クエリセットの要素数が少ない場合、および (2) クエリ要素の反転インデックスリストのID数が少ない場合に高速に動作することがあります。Spotifyのシナリオでは、ほとんどの人が数人のアーティストをフォローしている場合(おそらく真実)、すべてのアーティストがほぼ同じ数のフォロワーを持っている場合(真ではありません)。私たちはみんな、ほとんどの人が数人のトップアーティストをフォローし、ほとんどのアーティストが少数のフォロワーを持っているという事実を知っています。結局のところ、音楽業界はパレート分布に従っています。
Taylor SwiftはSpotifyで7800万人のフォロワーを持ち、The Weekendは6700万人のフォロワーを持っています。私のフォローリストに彼らがいると、search_top_k_merge_listアルゴリズムは少なくとも1億4500万個のセットIDを進む必要があり、候補テーブルcandidatesはこの膨大なサイズに成長します。現代のコンピュータは速くてパワフルですが、私のIntel i7マシンでは、このサイズのテーブルを作成するのに少なくとも30秒(Python)かかり、2.5GBのメモリを動的に割り当てます。
ほとんどの人はこれらのスーパースターアーティストのいくつかをフォローしています。したがって、このアルゴリズムを検索アプリケーションで使用する場合、大量のリソースを使用するために膨大なクラウドホスティング料金が発生し、高い検索待ち時間でユーザーエクスペリエンスが悪くなることが確実です。
分枝限定法の最適化
直感的には、前のアルゴリズムsearch_top_k_merge_listは、反転インデックスを使用して交差を計算するため、すべての潜在的な候補を幅優先で処理します。このアルゴリズムは、何百万人ものフォロワーを持つスーパースターアーティストのためにパフォーマンスが低いです。
別のアプローチは、潜在的な候補をより選択的にすることです。求職者の面接を想像してみてください。あなたは採用マネージャーであり、あなたに履歴書を送ってくるすべての潜在的な候補者を面接する余裕はありません。したがって、求人基準に基づいて候補者をバケットに分類し、最も重要な基準を満たす候補者から面接を始めます。一人ずつ面接を行い、それぞれが実際にすべてまたはほとんどの基準を満たしているか評価し、誰かを見つけたら面接を終了します。
同様に、フォローしているアーティストの類似したセットを見つける場合にも、このアプローチは機能します。アイデアは、クエリセット内のフォロワー数が最も少ないアーティストから始めることです。なぜなら、これらのアーティストはあなたが作業する候補セットが少なくなるため、反転インデックスからのアーティストリストの数を少なく処理し、最良のk候補をより速く見つけることができるからです。私のSpotifyのフォローリストでは、wasian projectは100万人のフォロワーしかいません- taylor swiftよりもはるかに少ないです。フォローしている人数がはるかに少ないwasian projectの人々は、taylor swiftをフォローしている人々よりも最良のk候補になる可能性があります。
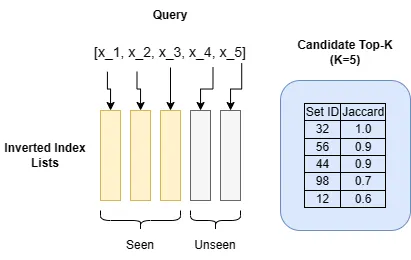
ここでの鍵となる洞察は、すべての潜在的な候補リストを処理するのではなく、十分な処理を行った時点で停止することです。停止するタイミングを知るのは難しい部分です。以下は、このアイデアを実装した前のアルゴリズムの変更版です。
import heapqdef search_top_k_probe_set(index, sets, q, k): # 現在のトップk候補を格納するための優先ヒープを初期化する。 heap = [] # 探査済みの候補を追跡するためのセットを初期化する。 seen_ids = set() # クエリqの要素を、反転インデックスのリストの長さに基づいて最も頻度の少ないものから順に繰り返す。 for i, x in enumerate(sorted(q, key=lambda x: len(index[x]))): ids = index[x] # インデックスからセットIDのリストを取得する。 for id in ids: if id in seen_ids: continue # 既に見た候補をスキップする。 s = sets[id] intersect_size = len(q.intersection(s)) jaccard = intersect_size / (len(q) + len(s) - intersect_size) # 候補を優先ヒープに追加する。 if len(heap) < k: heapq.heappush(heap, (jaccard, id)) else: # この操作では、Jaccardがk番目の現在の候補よりも高い候補のみが追加される。 heapq.heappushpop(heap, (jaccard, id)) seen_ids.add(id) # 残りのリストからの新しい候補のいずれも、現在の最良のk候補のいずれよりも高いJaccardを持つことはできない場合、これ以上の作業は必要ありません。 if (len(q) - i - 1) / len(q) (<= min(heap)[0]: break # 最良のk候補を返す。 return [id for _, id in heapq.nlargest(k, heap)]search_top_k_probe_setアルゴリズムは、見つかったすべての新しい候補に対してJaccard類似度を計算します。常に現在の最良のk個の候補を追跡し、新しい候補の上限Jaccardが現在の最良のk個の候補の最小Jaccardよりも大きくない場合に停止します。
上限Jaccardを計算する方法は?n個の候補リストを処理した後、未知の候補に対して、クエリセットとの最大の共通部分は残りの未処理リストの数、つまり|Q|-n以下であると言えます。そのような候補が残りの|Q|-nリストのすべてに現れる可能性があると仮定しています。このような候補Xの上限Jaccardを計算するために、単純な数学を使用できます。
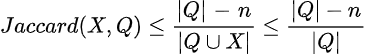
この巧妙な技術は、集合類似度検索の研究文献ではプレフィックスフィルタと呼ばれています。私はそれについて詳しく説明し、さらなるアルゴリズムの最適化も行った論文を書きました。また、PythonライブラリSetSimilaritySearchを作成し、より最適化されたバージョンのsearch_top_k_probe_setアルゴリズムを実装し、コサイン類似度と包含類似度もサポートしています。
Jaccard検索の近似インデックス
前のセクションでは、反転インデックスで動作する2つの検索アルゴリズムを説明しました。これらのアルゴリズムは「正確」であり、返されるk個の最良の候補は真のk個の最良の候補です。陳腐ですか?それなら、大規模なデータで検索アルゴリズムを設計する際に自問するべき質問です。なぜなら、多くの場面では真のk個の最良の候補を取得する必要はないからです。
再びSpotifyの例を考えてみてください:あなたの好みと似た人々を検索結果がいくつか見逃しても本当に気にしますか?ほとんどの人は、日常のアプリケーション(Google、Spotify、Twitterなど)では、検索が完全または正確ではないことを理解しています。これらのアプリケーションは正確な検索を正当化するほどミッションクリティカルではありません。これが、最も広く使用されている検索アルゴリズムがすべて近似的である理由です。
近似検索アルゴリズムを使用することの主な利点は、以下の2つです:
- 高速です。正確な結果が必要なくなるため、多くのコーナーカットができます。
- リソースの消費が予測可能です。これは明らかではありませんが、いくつかの近似アルゴリズムでは、リソースの使用(メモリなど)をデータの分布に依存せず事前に設定することができます。
この記事では、Jaccardの最も広く使用されている近似インデックスについて書いています:Minwise Locality Sensitive Hashing(MinHash LSH)。
LSHとは何ですか?
ローカリティセンシティブハッシング(LSH)インデックスは、コンピュータサイエンスの真の奇跡です。数論によって駆動されたアルゴリズムの魔力です。機械学習の文献では、これらはk-NNモデルですが、典型的な機械学習モデルとは異なり、LSHインデックスはデータに依存しないため、類似性に基づく精度は新しいデータポイントを取り込む前やデータの分布を変更する前に事前に決定することができます。そのため、モデルではなく反転インデックスにより類似しています。
LSHインデックスは、異なるハッシュ関数を持つハッシュテーブルのセットです。通常のハッシュテーブルと同様に、LSHインデックスのハッシュ関数はデータポイント(セット、特徴ベクトル、埋め込みベクトルなど)を入力として受け取り、バイナリハッシュキーを出力します。ただし、これ以外はまったく異なります。
通常のハッシュ関数は、入力データに対して擬似乱数的かつ均等に分布するキーを出力します。たとえば、MurmurHashは、32ビットのキースペース全体に対してほぼ均等かつランダムに出力するよく知られたハッシュ関数です。これは、abcdefgとabcefgなどの2つの入力に対して、異なる場合はそのMurmurHashキーが相関関係を持たず、32ビットのキースペース全体のいずれかのキーになる確率が同じであるということを意味します。これはハッシュ関数の望ましい性質であり、ハッシュバケット上のキーの均等な分布を実現するために、チェイニングやハッシュテーブルのリサイズを避けるためです。
一方、LSHのハッシュ関数は逆のことをします。類似性がある一対の入力に対しては、類似性がない他の一対のハッシュキーよりも同じになる可能性が高くなります。
これはどういう意味ですか?これは、類似度に基づく検索において、データポイントが類似しているほど、LSHのハッシュ関数におけるハッシュキーの衝突確率が高くなるということです。実際には、この高い衝突確率を類似度に基づく検索に活用しています。
MinHash LSH
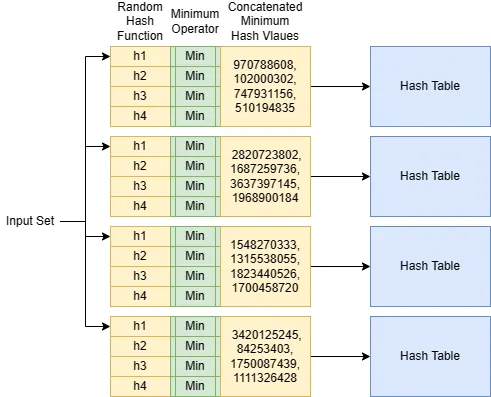
類似度/距離メトリックごとに、LSHハッシュ関数があります。Jaccardの場合、この関数はMinwiseハッシュ関数またはMinHash関数と呼ばれます。入力セットに対して、MinHash関数はランダムなハッシュ関数を使用してすべての要素を処理し、最小ハッシュ値を記録します。単一のMinHash関数を使用してLSHインデックスを構築することができます。以下の図を参照してください。

MinHash関数の数学的理論によれば、2つのセットが同じ最小ハッシュ値(つまり、ハッシュキーの衝突)を持つ確率は、それらのJaccardと同じです。
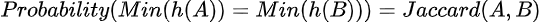
これは魔法のような結果ですが、証明は非常に単純です。
単一のMinHash関数を使用したMinHash LSHインデックスは、Jaccardに比例する衝突確率を持つため、十分な精度は提供しません。なぜかを理解するために、次のプロットをご覧ください。
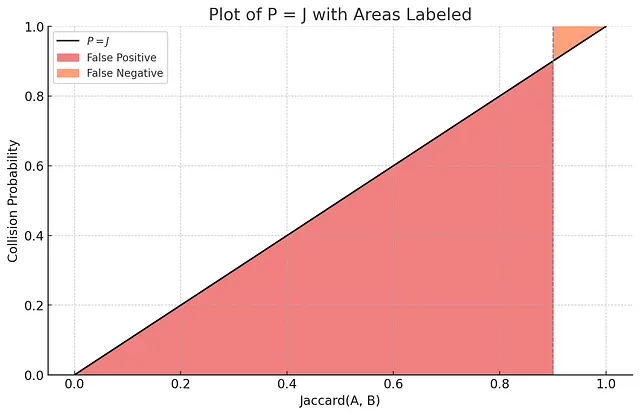
ジャカード指数が0.9の閾値を設定すると想像してください:クエリセットとのジャカード指数が0.9よりも高い結果は関連性があり、0.9よりも低いジャカード指数の結果は関連性がないとされます。検索の文脈では、「偽陽性」という概念は関連性のない結果が返されることを意味し、一方、「偽陰性」という概念は関連性のある結果が返されないことを意味します。上記のプロットを基に、偽陽性に対応する領域を見ると、インデックスが単一のMinHash関数のみを使用する場合、非常に高い確率で偽陽性が発生することがわかります。
MinHash LSHの精度向上
そのために、別のLSHの魔法が必要です。それがブースティングと呼ばれるプロセスです。インデックスを指定された関連性の閾値により適応させることができます。
1つだけではなく、m個のMinHash関数を使用します。これらはUniversal Hashingと呼ばれるプロセスを通じて生成されます。基本的には、32ビットまたは64ビット整数の同じハッシュ関数のm個のランダムな順列です。インデックス化されたセットごとに、ユニバーサルハッシングを使用してm個の最小ハッシュ値を生成します。
インデックス化されたセットのm個の最小ハッシュ値をリストアップすると想像してください。ハッシュ値をr個ずつのハッシュ値のバンドにグループ化し、b個のバンドを作成します。これにはm = b * rが必要です。

2つのセットが「バンドの衝突」を持つ確率、つまり、バンド内のすべてのハッシュ値が2つのセットの間で衝突するか、r個の連続したハッシュの衝突が発生する確率はJaccard(A, B)^rです。これは単一のハッシュ値よりもはるかに小さいです。ただし、2つのセットの間で少なくとも1つの「バンドの衝突」が発生する確率は1 - (1-Jaccard(A, B)^r)^bです。
なぜ1 - (1-Jaccard(A, B)^r)^bに関心を持つのでしょうか?なぜなら、この関数には特別な形状があるからです:
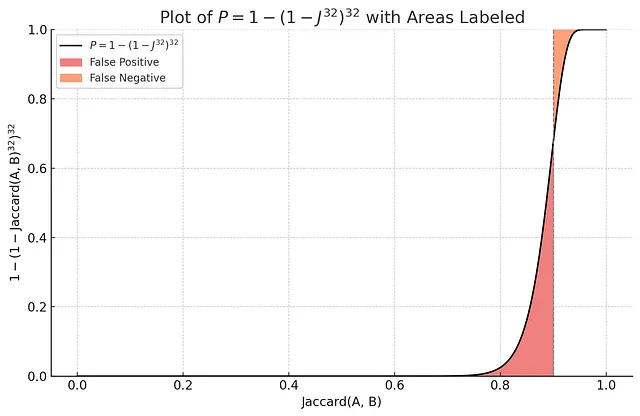
上記のプロットでは、m個のMinHash関数を使用することで、「少なくとも1つのバンドの衝突」確率がSカーブ関数となり、Jaccard = 0.9周辺で急激に上昇していることがわかります。関連性の閾値が0.9であると仮定すると、このインデックスの偽陽性確率は、単一のランダムハッシュ関数のみを使用するインデックスよりもはるかに小さいです。
このため、LSHインデックスは常にb個のバンドとr個のMinHash関数を使用して精度を向上させます。各バンドは、インデックス化されたセットへのポインタを格納するハッシュテーブルです。検索中、クエリセットと任意のバンドでインデックス化されたセットが衝突すると、そのセットが返されます。
MinHash LSHインデックスを構築するには、事前に関連性の閾値とジャカード類似性に基づいた許容される偽陽性および偽陰性の確率を指定し、最適なm、b、およびrを計算します。これは、他の近似インデックスに比べてLSHを使用することの大きな利点です。
Pythonパッケージdatasketchには、MinHash LSHの実装があります。また、LSH ForestやWeighted MinHashなど、他のMinHash関連のアルゴリズムもあります。
最終的な考え
この記事では多くのトピックをカバーしましたが、Jaccard類似度の検索インデックスについてはほんの一部しか触れていません。これらのトピックについてさらに読みたい場合は、以下の追加の参考文献リストがあります:
- Jure Leskovec、Anand Rajaraman、Jeff Ullmanによる「Mining of Massive Datasets」。第3章ではMinHashとLSHについて詳しく説明しています。MinHashの直感を得るための素晴らしい章だと思います。ただし、章で説明されているアプリケーションはn-gramベースのテキストマッチングに焦点を当てています。
- JOSIE:データレイク内の結合可能なテーブルを見つけるためのオーバーラップセット類似度検索。この論文の予備的なセクションでは、
search_top_k_merge_listおよびsearch_top_k_probe_setアルゴリズムの直感的な説明がされています。メインセクションでは、テーブルの列などの入力セットが大きい場合にコストを考慮する方法が説明されています。 - DatasketchとSetSimilaritySearchライブラリは、それぞれ最新の近似および正確なJaccard類似度検索インデックスを実装しています。datasketchプロジェクトの問題リストは、MinHash LSHを適用する際のアプリケーションシナリオや実践的な考慮事項の宝庫です。
埋め込みについてはどうですか?
近年、Transformerなどの深層ニューラルネットワークを使用した表現学習のブレークスルーにより、学習された埋め込みベクトル間の類似度は、入力データが埋め込みモデルの学習に使用されたドメインの一部である場合に意味を持ちます。この記事で説明されている検索シナリオとそのシナリオとの主な違いは次のとおりです:
- 埋め込みベクトルは、通常60から700次元の密なベクトルです。各次元は非ゼロです。一方、セットは、ワンホットベクトルとして表現される場合にはスパースです:1万から数百万の次元がありますが、ほとんどの次元はゼロです。
- 埋め込みベクトルでは、コサイン類似度(または正規化されたベクトル上の内積)が通常使用されます。セットではJaccard類似度を使用します。
- 埋め込みベクトル間の類似度に関しては、ベクトルが画像やテキストなどの元のデータの学習されたブラックボックス表現であるため、関連性のしきい値を指定することは困難です。一方、セットのJaccard類似度のしきい値を指定することははるかに簡単です、なぜならセットは元のデータだからです。
上記の違いにより、埋め込みとセットを比較することは直感的には簡単ではありません。それらは明らかに異なるデータ型ですが、両方を高次元と分類することはできます。それらは異なるアプリケーションシナリオに適しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「正しい方法で新しいデータサイエンスのスキルを学ぶ」
- 「機械学習モデルが医学的診断と治療において不公平を増幅する方法」
- 「初心者のためのPandasを使ったデータフォーマットのナビゲーション」
- 「GPT4のデータなしでコードLLMのインストラクションチューニングを行う方法は? OctoPackに会いましょう:インストラクションチューニングコード大規模言語モデルのためのAIモデルのセット」
- 「データ主導的なアプローチを取るべきか?時にはそうである」
- 「Azure Data Factory(ADF)とは何ですか?特徴とアプリケーション」
- 「pandasのCopy-on-Writeモードの深い探求-パートII」
