FHEを用いた暗号化された大規模言語モデルに向けて
FHEを用いた暗号化された言語モデルに向けて
大規模言語モデル(LLM)は最近、プログラミング、コンテンツ作成、テキスト分析、ウェブ検索、遠隔学習などの多くの分野で生産性を向上させるための信頼性のあるツールとして証明されています。
大規模言語モデルがユーザーのプライバシーに与える影響
LLMの魅力にもかかわらず、これらのモデルによって処理されるユーザークエリに関するプライバシーの懸念が残っています。一方で、LLMの能力を活用することは望ましいですが、他方で、LLMサービスプロバイダーに対して機密情報が漏洩するリスクがあります。医療、金融、法律などの一部の分野では、このプライバシーリスクは問題の原因となります。
この問題への1つの解決策は、オンプレミス展開です。オンプレミス展開では、LLMの所有者がクライアントのマシンにモデルを展開します。これは、LLMの構築に数百万ドル(GPT3の場合は4.6Mドル)かかるため、最適な解決策ではありません。また、オンプレミス展開では、モデルの知的財産(IP)が漏洩するリスクがあります。
Zamaは、ユーザーのプライバシーとモデルのIPの両方を保護できると考えています。このブログでは、Hugging Face transformersライブラリを活用して、モデルの一部を暗号化されたデータ上で実行する方法を紹介します。完全なコードは、このユースケースの例で見つけることができます。
- 「機械学習におけるモデルの解釈性においてSHAP値の使用」
- 「AWSとAccelが「ML Elevate 2023」を立ち上げ、インドのAIスタートアップエコシステムを力強く支援」
- 「業界アプリケーションにおける大規模言語モデルを評価するための4つの重要な要素」
完全同型暗号(FHE)はLLMのプライバシーの課題を解決できます
ZamaのLLM展開の課題に対する解決策は、完全同型暗号(FHE)を使用することです。これにより、暗号化されたデータ上で関数の実行が可能となります。モデルの所有者のIPを保護しながら、ユーザーのデータのプライバシーを維持することが可能です。このデモでは、FHEで実装されたLLMモデルが元のモデルの予測の品質を維持していることを示しています。これを行うためには、Hugging Face transformersライブラリのGPT2の実装を適応し、Concrete-Pythonを使用してPython関数をそのFHE相当に変換する必要があります。
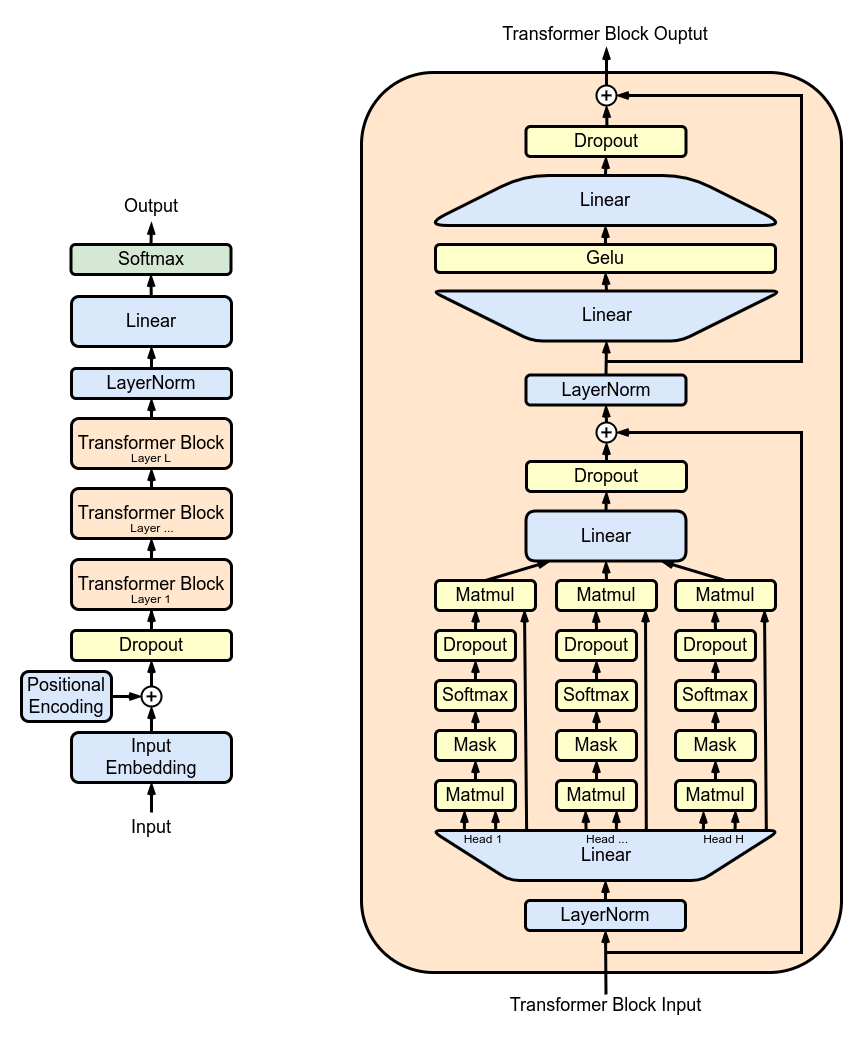
図1は、GPT2のアーキテクチャを示しています。これは繰り返し構造を持ち、連続的に適用される複数のマルチヘッドアテンション(MHA)レイヤーから成り立っています。各MHAレイヤーは、モデルの重みを使用して入力をプロジェクションし、アテンションメカニズムを計算し、アテンションの出力を新しいテンソルに再プロジェクションします。
TFHEでは、モデルの重みと活性化は整数で表現されます。非線形関数はプログラマブルブートストラッピング(PBS)演算で実装する必要があります。PBSは、暗号化されたデータ上でのテーブルルックアップ(TLU)演算を実装し、同時に暗号文をリフレッシュして任意の計算を可能にします。一方で、PBSの計算時間は線形演算の計算時間を上回ります。これらの2つの演算を活用することで、FHEでLLMの任意のサブパート、または、全体の計算を表現することができます。
FHEを使用したLLMレイヤーの実装
次に、マルチヘッドアテンション(MHA)ブロックの単一のアテンションヘッドを暗号化する方法を見ていきます。また、このユースケースの例では、完全なMHAブロックの例も見つけることができます。

図2は、基礎となる実装の簡略化された概要を示しています。クライアントは、共有モデルから削除された最初のレイヤーまでの推論をローカルで開始します。ユーザーは中間操作を暗号化してサーバーに送信します。サーバーは一部のアテンションメカニズムを適用し、その結果をクライアントに返します。クライアントはそれらを復号化してローカルの推論を続けることができます。
量子化
まず、暗号化された値上でモデルの推論を実行するために、モデルの重みと活性化を量子化し、整数に変換する必要があります。理想的には、モデルの再トレーニングを必要としない事後トレーニング量子化を使用します。このプロセスでは、FHE互換のアテンションメカニズムを実装し、整数とPBSを使用し、LLMの精度への影響を検証します。
量子化の影響を評価するために、暗号化されたデータ上で1つのLLMヘッドが動作する完全なGPT2モデルを実行します。そして、重みと活性化の量子化ビット数を変化させた場合の精度を評価します。
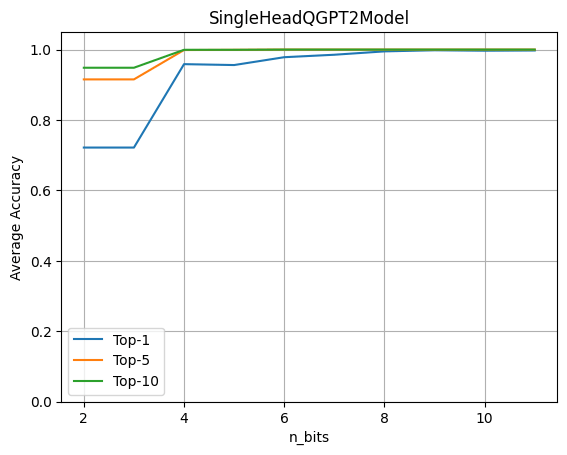
このグラフは、4ビットの量子化が元の精度の96%を維持していることを示しています。この実験は、約80の文章からなるデータセットを使用して行われます。メトリクスは、元のモデルのロジット予測と量子化されたヘッドモデルを比較して計算されます。
Hugging Face GPT2モデルにFHEを適用する
Hugging Faceのtransformersライブラリをベースにして、量子化されたオペレータを含めるために暗号化したいモジュールの順方向パスを書き直します。最初にGPT2LMHeadModelをロードし、次にQGPT2SingleHeadAttentionモジュールを使用して最初のマルチヘッドアテンションモジュールを置き換えることで、SingleHeadQGPT2Modelのインスタンスを構築します。完全な実装はこちらで見つけることができます。
self.transformer.h[0].attn = QGPT2SingleHeadAttention(config, n_bits=n_bits)その後、順方向パスは上書きされ、FHEに適したオペレータでマルチヘッドアテンションメカニズムの最初のヘッド、およびクエリ、キー、値行列の構築に使用されるプロジェクションが実行されます。次のQGPT2モジュールはこちらで見つけることができます。
class SingleHeadAttention(QGPT2):
"""量子化メソッドを使用した単一のアテンションヘッドを表すクラス。"""
def run_numpy(self, q_hidden_states: np.ndarray):
# 入力をDualArrayインスタンスに変換する
q_x = DualArray(
float_array=self.x_calib,
int_array=q_hidden_states,
quantizer=self.quantizer
)
# アテンションベースモジュールの名前を抽出する
mha_weights_name = f"transformer.h.{self.layer}.attn."
# クエリ、キー、値の重みとバイアスの値を適切なインデックスを使用して抽出する
head_0_indices = [
list(range(i * self.n_embd, i * self.n_embd + self.head_dim))
for i in range(3)
]
q_qkv_weights = ...
q_qkv_bias = ...
# 最初のプロジェクションを適用して、Q、K、Vを単一の配列として抽出する
q_qkv = q_x.linear(
weight=q_qkv_weights,
bias=q_qkv_bias,
key=f"attention_qkv_proj_layer_{self.layer}",
)
# クエリ、キー、値を抽出する
q_qkv = q_qkv.expand_dims(axis=1, key=f"unsqueeze_{self.layer}")
q_q, q_k, q_v = q_qkv.enc_split(
3,
axis=-1,
key=f"qkv_split_layer_{self.layer}"
)
# アテンションメカニズムを計算する
q_y = self.attention(q_q, q_k, q_v)
return self.finalize(q_y)モデル内の他の計算は浮動小数点のままで、非暗号化されており、クライアントでオンプレミスで実行されることが想定されています。
このように変更されたGPT2モデルに事前学習済みの重みをロードした後、generateメソッドを呼び出すことができます:
qgpt2_model = SingleHeadQGPT2Model.from_pretrained(
"gpt2_model", n_bits=4, use_cache=False
)
output_ids = qgpt2_model.generate(input_ids)例えば、量子化モデルにフレーズ「Cryptography is a」の完了を依頼することができます。FHEでモデルを実行する際に十分な量子化精度がある場合、生成の出力は次のようになります:
「Cryptography is a very important part of the security of your computer」
量子化精度が低すぎる場合は、次のようになります:
「Cryptography is a great way to learn about the world around you」
FHEへのコンパイル
次のConcrete-MLコードを使用してアテンションヘッドをコンパイルすることができます:
circuit_head = qgpt2_model.compile(input_ids)これを実行すると、「Circuit compiled with 8 bit-width」という表示が表示されます。これはFHEと互換性のある構成であり、FHEでの操作に必要な最大ビット幅を示しています。
複雑さ
トランスフォーマーモデルでは、最も計算負荷の高い操作はクエリ、キー、値の乗算を行うアテンションメカニズムです。FHEでは、暗号化されたドメインでの乗算の特異性により、コストが複雑になります。さらに、シーケンスの長さが増えると、これらの難しい乗算の数も二次的に増加します。
暗号化されたヘッドの場合、長さ6のシーケンスには11,622のPBS操作が必要です。これは、パフォーマンスに最適化されていない最初の実験です。数秒で実行できますが、かなりの計算能力が必要です。幸いなことに、ハードウェアの進歩により、数年後に利用可能になると、CPUで数分かかることが、ASICでは100ms未満に改善されます。これらの予測の詳細については、このブログ投稿をご覧ください。
結論
大規模言語モデルは、さまざまなユースケースで優れた支援ツールですが、その実装はユーザーのプライバシーに関する重大な問題を提起しています。このブログでは、ユーザーのプライバシーが完全に尊重される中で、全体のLLMが暗号化されたデータ上で動作する第一歩を紹介しました。
このステップには、GPT2のようなモデルの特定の部分をFHE領域に変換することが含まれます。この実装はtransformersライブラリを活用し、モデルの一部が暗号化されたデータ上で動作する場合の精度への影響を評価することができます。ユーザーのプライバシーを保護するだけでなく、このアプローチはモデルの所有者が主要な部分を秘密に保ち続けることも可能にします。完全なコードはこのユースケースの例で見つけることができます。
ZamaライブラリのConcreteとConcrete-ML(GitHubのリポジトリにスターを付けるのを忘れないでください⭐️💛)は、簡単なMLモデルの構築とFHEに変換することを可能にし、暗号化されたデータ上での計算と予測ができます。
この投稿がお楽しみいただければ幸いです。ご意見やフィードバックをお気軽にお寄せください!
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「7月24日から7月31日までの週間でのトップのコンピュータビジョン論文」
- 2023年に知っておくべきトップ13の自然言語処理プロジェクト
- このAIニュースレターは、あなたが必要なもの全てです#58
- 「UniDetectorであなたが望むものを検出しましょう」
- 「QLORAとは:効率的なファインチューニング手法で、メモリ使用量を削減し、単一の48GB GPUで65Bパラメーターモデルをファインチューニングできるだけでなく、完全な16ビットのファインチューニングタスクのパフォーマンスも保持します」
- 「LLMは強化学習を上回る- SPRINGと出会う LLM向けの革新的なプロンプティングフレームワークで、コンテキスト内での思考計画と推論を可能にするために設計されました」
- 「DeepMind AIが数百万の動画のために自動生成された説明を作成することで、YouTube Shortsの露出を大幅に向上させる」