「翼を広げよう:Falcon 180Bがここにあります」
Falcon 180B is here Spread your wings.
はじめに
本日は、TIIのFalcon 180BをHuggingFaceに歓迎します! Falcon 180Bは、オープンモデルの最新技術を提供します。1800億のパラメータを持つ最大の公開言語モデルであり、TIIのRefinedWebデータセットを使用して3.5兆トークンを使用してトレーニングされました。これはオープンモデルにおける最長の単一エポックの事前トレーニングを表しています。
Hugging Face Hub(ベースモデルとチャットモデル)でモデルを見つけることができ、Falcon Chat Demo Spaceでモデルと対話することができます。
Falcon 180Bは、自然言語タスク全体で最先端の結果を実現しています。これは(事前トレーニング済みの)オープンアクセスモデルのリーダーボードをトップし、PaLM-2のようなプロプライエタリモデルと競合しています。まだ明確にランク付けすることは難しいですが、PaLM-2 Largeと同等の性能を持ち、Falcon 180Bは公に知られている最も能力のあるLLMの一つです。
このブログ投稿では、いくつかの評価結果を見ながらFalcon 180Bがなぜ優れているのかを探求し、モデルの使用方法を紹介します。
- オンポリシー対オフポリシーのモンテカルロ、視覚化と共に
- 「2023年9月のソーシャルメディア向けの20の最高のChatGPTプロンプト」
- 「Generative AIの活用:Generative AIツールのサイバーセキュリティへの影響の解明」
- Falcon-180Bとは何ですか?
- Falcon 180Bはどれくらい優れていますか?
- Falcon 180Bの使用方法は?
- デモ
- ハードウェア要件
- プロンプト形式
- Transformers
- 追加リソース
Falcon-180Bとは何ですか?
Falcon 180Bは、Falconファミリーの前のリリースに続いてTIIによってリリースされたモデルです。
アーキテクチャ的には、Falcon 180BはFalcon 40Bの拡大版であり、改良されたスケーラビリティのためのマルチクエリアテンションなどの革新を基にしています。アーキテクチャについては、Falconを紹介する最初のブログ投稿を確認することをおすすめします。Falcon 180Bは、Amazon SageMakerを使用して最大4096のGPUで同時に3.5兆のトークンでトレーニングされ、合計で約7,000,000のGPU時間がかかりました。これはLlama 2よりも2.5倍大きく、4倍の計算リソースを使用してトレーニングされました。
Falcon 180Bのデータセットは、主にRefinedWebからのウェブデータ(約85%)で構成されています。さらに、会話、技術論文、およびコードの一部のようなキュレーションされたデータのミックスでもトレーニングされています(約3%)。この事前トレーニングデータセットは十分に大きく、3.5兆のトークンですらエポック未満です。
リリースされたチャットモデルは、いくつかの大規模な会話データセットのミックスでチャットと命令データセットに微調整されています。
‼️商用利用:Falcon 180bは商用利用が可能ですが、非常に制限された条件の下でのみ利用できます。特に「ホスティング利用」は除外されます。商用目的で使用する場合は、ライセンスを確認し、法務チームに相談することをお勧めします。
Falcon 180Bはどれくらい優れていますか?
Falcon 180Bは、MMLUでLlama 2 70BおよびOpenAIのGPT-3.5を上回り、HellaSwag、LAMBADA、WebQuestions、Winogrande、PIQA、ARC、BoolQ、CB、COPA、RTE、WiC、WSC、ReCoRDでGoogleのPaLM 2-Largeと同等の結果を実現しており、公然とリリースされたLLMの中で最も優れたモデルです。Falcon 180Bは、評価ベンチマークによってはGPT 3.5とGPT4の間に位置することが一般的であり、コミュニティからのさらなる微調整は興味深いものになるでしょう。
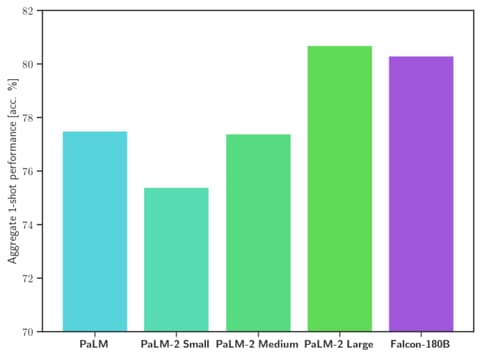
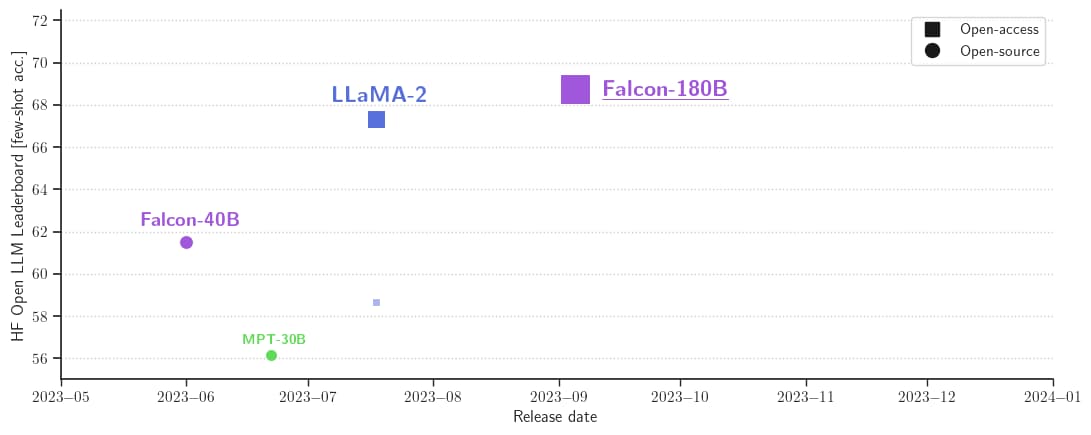
Hugging Face Leaderboardでのスコアは68.74であり、Falcon 180Bは公開されている事前トレーニング済みLLMの中で最も高得点です。MetaのLLaMA 2(67.35)を上回っています。
Falcon 180Bの使用方法は?
Falcon 180Bは、Transformersバージョン4.33以降でHugging Faceエコシステムで利用できます。
デモ
このスペースまたは以下に埋め込まれたプレイグラウンドで、Big Falcon Model(1800億のパラメータ!)を簡単に試すことができます:
ハードウェア要件
プロンプト形式
ベースモデルにはプロンプト形式はありません。会話モデルや指示でトレーニングされていないため、会話応答を生成することは期待しないでください。事前学習済みモデルはさらなる微調整のための優れたプラットフォームですが、そのまま使用することはお勧めしません。チャットモデルには非常にシンプルな会話構造があります。
System: ここにオプションのシステムプロンプトを追加します
User: これはユーザーの入力です
Falcon: モデルが生成する内容です
User: これは2番目のターンの入力かもしれません
Falcon: など、続きますトランスフォーマー
Transformers 4.33のリリースにより、Falcon 180Bを使用し、HFエコシステムのすべてのツールを活用することができます。ツールには以下が含まれます:
- トレーニングと推論のスクリプトと例
- 安全なファイル形式(safetensors)
- bitsandbytes(4ビット量子化)、PEFT(パラメータ効率的な微調整)、GPTQなどのツールとの統合
- 補助生成(または「仮説的デコーディング」とも呼ばれる)
- RoPEスケーリングによるより大きなコンテキスト長のサポート
- 豊富で強力な生成パラメータ
モデルの使用には、ライセンスと利用規約に同意する必要があります。Hugging Faceのアカウントにログインしていることを確認し、最新バージョンのtransformersをインストールしてください:
pip install --upgrade transformers
huggingface-cli loginbfloat16
bfloat16でベースモデルを使用する方法は次のとおりです。Falcon 180Bは大きなモデルなので、上記のテーブルにまとめられたハードウェア要件を考慮してください。
from transformers import AutoTokenizer, AutoModelForCausalLM
import transformers
import torch
model_id = "tiiuae/falcon-180B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
prompt = "私の名前はペドロで、住んでいる場所は"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
output = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
do_sample=True,
temperature=0.6,
top_p=0.9,
max_new_tokens=50,
)
output = output[0].to("cpu")
print(tokenizer.decode(output)これにより、次のような出力が生成される場合があります:
私の名前はペドロで、住んでいる場所はポルトガルで、25歳です。私はグラフィックデザイナーですが、写真やビデオにも情熱を持っています。
旅行が大好きで、常に新しい冒険を探しています。新しい人々に出会い、新しい場所を探索するのが好きです。bitsandbytesでの8ビットと4ビットの使用
Falcon 180Bの8ビットおよび4ビット量子化バージョンは、bfloat16の参照とほとんど差がありません!これは推論にとって非常に良いニュースであり、ハードウェア要件を削減するために量子化バージョンを安心して使用できます。ただし、8ビット推論の方が4ビットでモデルを実行するよりもはるかに高速です。
量子化を使用するには、bitsandbytesライブラリをインストールし、モデルをロードする際に対応するフラグを有効にするだけです:
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
device_map="auto",
)チャットモデル
前述のように、会話に従って微調整されたモデルのバージョンは非常にシンプルなトレーニングテンプレートを使用しています。チャットスタイルの推論を実行するためには同じパターンに従う必要があります。参照のために、以下はChatデモのformat_prompt関数の例です:
def format_prompt(message, history, system_prompt):
prompt = ""
if system_prompt:
prompt += f"System: {system_prompt}\n"
for user_prompt, bot_response in history:
prompt += f"User: {user_prompt}\n"
prompt += f"Falcon: {bot_response}\n"
prompt += f"User: {message}\nFalcon:"
return promptご覧のように、ユーザーからのやり取りとモデルからの応答は、User:とFalcon:の区切り文字によって先行します。これらを連結して、会話の全履歴を含むプロンプトを形成します。生成スタイルを調整するために、システムプロンプトを提供することができます。
追加リソース
- モデル
- デモ
- The Falcon has landed in the Hugging Face ecosystem
- 公式発表
謝辞
このようなエコシステムでのサポートと評価を伴うモデルのリリースは、ClémentineとEleuther Evaluation HarnessによるLLM評価、LoubnaとBigCodeによるコード評価、Nicolasによる推論サポート、Lysandre、Matt、Daniel、Amy、Joao、およびArthurによるFalconのtransformersへの統合を含む多くのコミュニティメンバーの貢献なしには実現しないでしょう。オープンソースのデモにはBaptisteとPatrickに感謝します。Thom、Lewis、TheBloke、Nouamane、Tim Dettmersには、これが実現するための複数の貢献をしていただきました。最後に、LLM評価の実行とモデルの無料のオープンソースデモの推論を提供してくれたHF Clusterに感謝します。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






