「F1スコア:視覚的ガイド – そしてなぜそれが偏ったデータから救ってくれないのか」
F1スコア:視覚的ガイド - 偏ったデータからの救い方
結論は最後に
私たちの仕事は、人々が健康か病気かを分類するモデルを作成することです。私たちは、彼らに関するデータを与えられ、複数の分類モデルを作成しました。そして、最も優れたモデルを選択する時が来ました。

適合率と再現率
モデルのパフォーマンスを推定する一般的な方法は、その適合率と再現率を測定することです。
適合率 — 予測された陽性のうち、実際に陽性だったものの割合。
- 画像中のテーブルの行と列をトランスフォーマーを使用して検出する
- 「データサイエンティストには試してみるべきジェンAIプロンプト」
- 「MicrosoftがExcelにPythonを導入:分析能力と親しみやすさを結びつけ、データ洞察を向上させる」
再現率 — データ全体の実際の陽性のうち、正しく予測したものの割合。

適合率と再現率は素晴らしい指標ですが、それでも2つの数値です。異なる2つのモデルを比較してどちらが優れているかを判断するためには、単一の数値を持つ方が便利でしょう。
算術平均
適合率と再現率を結合する方法の一つは、それらの平均(算術平均)を取ることです。

この方法は、2つの指標を1つの値に結合します。しかし、ここで注意が必要です。
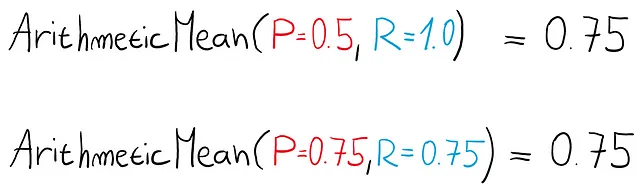
ここでは、同じ平均を持っています。しかし、これらのモデルは同じくらい優れていますか?
最初のモデルは、データセット内のすべてを陽性と呼んでいるだけで、何のロジックもありませんが、2番目のモデルはより有用に見えます。
良いモデルを探す際には、適合率または再現率が低いモデルは避けたいものです。これらはおそらく有用なモデルではありません。そして、片方の数値が他よりもかなり小さい場合には、「スコア」を下げたいと考えるでしょう。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
