「フラミンゴとDALL-Eはお互いを理解しているのか?イメージキャプションとテキストから画像生成モデルの相互共生を探る」
Exploring the symbiotic relationship between Flamingo and DALL-E Do they understand each other? Image caption and text-based image generation models.


テキストとビジュアルのコンピュータ理解を向上させるマルチモーダル研究は、最近大きな進歩を遂げています。DALL-EやStable Diffusion(SD)などのテキストからイメージを生成するモデルや、FlamingoやBLIPのようなイメージからテキストを生成するモデルは、現実の状況からの複雑な言語的記述を高精度のビジュアルに変換することができます。しかし、テキストからイメージを生成するモデルと画像キャプション生成モデルの間には近接性がありながらも、独立して研究されることが多く、これらのモデルの相互作用は探求される必要があります。テキストからイメージを生成するモデルと画像からテキストを生成するモデルがお互いを理解できるかどうかという問題は興味深いものです。
この問題に取り組むために、特定の画像に対してテキストの説明を生成するためにBLIPという画像からテキストのモデルを使用します。このテキストの説明は、SDというテキストからイメージを生成するモデルに供給され、新しい画像が作成されます。彼らは、作成された画像が元の画像に似ている場合、BLIPとSDがコミュニケーションできると主張しています。共有された理解によって、各モデルの基本的なアイデアを理解する能力が向上し、キャプションの作成と画像合成がより良くなる可能性があります。このコンセプトは図1に示されており、上のキャプションは元の画像のより正確な再構成を導き、下のキャプションよりも入力画像をよりよく表現しています。
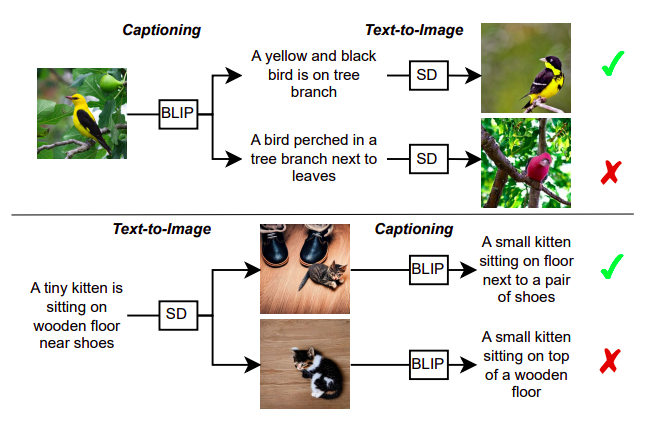
LMU Munich、Siemens AG、およびUniversity of Oxfordの研究者は、DALL-EがFlamingoが特定の画像に対して生成する説明を使用して新しい画像を合成する再構成タスクを開発しました。この仮定をテストするために、テキスト-イメージ-テキストとイメージ-テキスト-イメージの2つの再構成タスクを作成します(図1を参照)。最初の再構成タスクでは、事前学習済みのCLIPイメージエンコーダで抽出された画像の特徴の距離を計算し、再構成された画像と入力画像の意味がどれだけ似ているかを判断します。次に、生成されたテキストの品質を人間によって注釈付けされたキャプションと比較します。彼らの研究は、生成されたテキストの品質が再構成のパフォーマンスにどのように影響するかを示しています。これにより、彼らの最初の発見が導かれます:生成モデルが元の画像を再構成するための説明は、画像に最も適した説明であるということです。
- 自動小売りチェックアウトは、ラベルのない農産物をどのように認識するのか? PseudoAugmentコンピュータビジョンアプローチとの出会い
- 専門家モデルを用いた機械学習:入門
- 「Amazon SageMakerでのRayを使用した効果的な負荷分散」
同様に、SDがテキストの入力から画像を作成し、その作成された画像からBLIPがテキストを作成する逆のタスクを作成します。彼らは、元のテキストを生成した画像がテキストにとって最も優れたイラストであることを発見します。彼らは、再構成プロセス中に入力画像からの情報がテキストの記述に正確に保持されると仮定しています。この意味のある説明は、画像モダリティへの忠実な回復につながります。彼らの研究は、テキストからイメージやイメージからテキストのモデルがお互いとコミュニケーションするのを容易にする独自のフレームワークを示唆しています。
具体的には、彼らのパラダイムでは、生成モデルは再構成損失と人間のラベルからトレーニング信号を受け取ります。1つのモデルは、他のモダリティの特定の画像またはテキストの入力の表現を最初に作成し、異なるモデルはこの表現を入力モダリティに戻します。再構成コンポーネントは、初期モデルの微調整を指示する正則化損失を作成します。このようにして、彼らは自己および人間の監督を得て、生成がより正確な再構成に結果をもたらす可能性を高めます。たとえば、画像キャプションモデルは、ラベル付きの画像テキストのペアに対応するだけでなく、信頼性のある再構成につながるキャプションを好む必要があります。
エージェント間の通信は彼らの仕事と密接に関連しています。エージェント間の主要な情報交換手段は言語です。しかし、最初のエージェントと2番目のエージェントが猫や犬の定義を同じく持っていることを確信することはできますか?この研究では、最初のエージェントに画像を調査し、それを説明する文を生成するように求めます。テキストを受け取った後、2番目のエージェントはそれに基づいて画像をシミュレーションします。後者の段階は具現化プロセスです。彼らの仮説によれば、通信は効果的である場合、2番目のエージェントの入力画像のシミュレーションが最初のエージェントが受け取った入力画像に近い場合です。本質的には、彼らは人間の主要なコミュニケーション手段である言語の有用性を評価しています。特に、新たに確立された大規模な事前学習済みの画像キャプションモデルと画像生成モデルが彼らの研究で使用されています。さまざまな生成モデルに対して、トレーニングフリーおよび微調整の状況の両方で彼らの提案されたフレームワークの利点が証明されました。特に、トレーニングフリーのパラダイムでは、キャプションと画像の作成が大幅に改善されました。一方、微調整では、両方の生成モデルに対してより良い結果が得られました。
以下は彼らの主な貢献の要点です:
• フレームワーク:従来の単独の画像からテキストへの生成モデルとテキストから画像への生成モデルが、簡単に理解できるテキストと画像の表現を介して通信する方法について初めて調査したと彼らは最もよく知っています。一方、同様の研究ではテキストと画像の作成を埋め込み空間を介して暗黙的に統合します。
• 結果:彼らは、テキストから画像へのモデルによって作成された画像の再構成を評価することが、キャプションの品質を判断するのに役立つことを発見しました。元の画像の最も正確な再構成を可能にするキャプションが、その画像に使用すべきキャプションです。同様に、元のテキストの最も正確な再構成を可能にするキャプションが最良のキャプション画像です。
• 改善:彼らの研究に基づいて、テキストから画像へのモデルと画像からテキストへのモデルの両方を改善する包括的なフレームワークを提案しました。テキストから画像へのモデルによって計算された再構成損失は、画像からテキストへのモデルの微調整に正則化として使用され、画像からテキストへのモデルによって計算された再構成損失は、テキストから画像へのモデルの微調整に使用されます。彼らは自身のアプローチの有効性を調査し、確認しました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





