NLPとエリシットを用いたジェンダー平等に関する研究の探索
Exploring research on gender equality using NLP and elicitation
はじめに
NLP(自然言語処理)は、膨大なテキストデータを理解するのに役立ちます。大量の文書を手作業で読む代わりに、これらの技術を利用して理解を高速化し、主要なメッセージに素早くたどり着くことができます。このブログ記事では、パンダデータフレームとPythonのNLPツールを使用して、Elicitを使用してアフガニスタンのジェンダー平等に関する研究で人々が何を書いたかを把握する可能性について探求します。これらの洞察は、女性や女の子にとって最も困難な場所の1つとされている国で、ジェンダー平等を推進するために何がうまくいき、何がうまくいかなかったかを理解するのに役立つかもしれません(World Economic Forum、2023年)。
学習目標
- CSVファイル内のテキストのテキスト分析の習得
- Pythonでの自然言語処理の方法に関する知識の習得
- 効果的なデータ可視化のためのスキルの開発
- アフガニスタンにおけるジェンダー平等に関する研究が時間とともにどのように進展したかについての洞察の獲得
この記事は、データサイエンスブログマラソンの一環として公開されました。
文献レビューにおけるElicitの使用
基礎となるデータを生成するために、私はAIパワードツールであるElicitを使用して文献レビューを行います(Elicit)。ツールに質問をすることで、アフガニスタンでジェンダー平等が失敗した理由に関連する論文のリストを生成するように依頼します。その後、CSV形式で結果の論文リスト(150以上のランダムな数の論文とみなします)をダウンロードします。このデータはどのように見えるのでしょうか?さあ、見てみましょう!
PythonでElicitからのCSVデータを分析する
まず、CSVファイルをパンダデータフレームとして読み込みます:
- この人工知能の研究は、トランスフォーマーベースの大規模言語モデルが外部メモリを追加して計算的に普遍的であることを確認しています
- スタンフォードの研究者たちは、Parselという人工知能(AI)フレームワークを紹介しましたこのフレームワークは、コードの大規模な言語モデル(LLMs)を使用して、複雑なアルゴリズムの自動実装と検証を可能にします
- 新しい人工知能(AI)の研究アプローチは、統計的な視点からアルゴリズム学習の問題として、プロンプトベースのコンテキスト学習を提示します
import pandas as pd
# ファイルパスとCSVファイルを特定
file_path = './elicit.csv'
# CSVファイルを読み込む
df = pd.read_csv(file_path)
# CSVの形状
df.shape
# 出力:(168, 15)
# データフレームの最初の行を表示する
df.head()df.head() コマンドは、生成されたパンダデータフレームの最初の行を表示します。データフレームは15列と168行で構成されています。df.shape コマンドを使用してこの情報を生成します。では、これらの研究のほとんどがどの年に公表されたかを調査してみましょう。Pythonではいくつかの図を生成するためのツールがありますが、ここでは seaborn と matplotlib ライブラリを使用します。論文が主にどの年に公表されたかを分析するために、カウントプロットと呼ばれるものを活用し、軸ラベルや軸の目盛りをカスタマイズして見栄えを良くします:
公表された論文の時期的な分布の分析
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 図のサイズを設定
plt.figure(figsize=(10,5))
# カウントプロットを生成
chart = sns.countplot(x=df["Year"], color='blue')
# ラベルを設定
chart.set_xlabel('Year')
chart.set_ylabel('Number of published papers')
# x軸のラベルのサイズを変更
# ラベルテキストの取得
_, xlabels = plt.xticks()
# x軸のラベルを設定する
chart.set_xticklabels(xlabels, size=5)
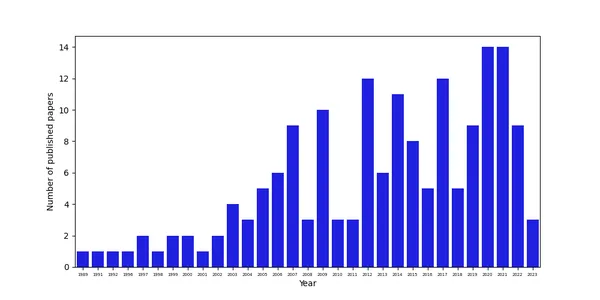
plt.show()データからは、論文の数が時間とともに増加しており、おそらく2001年のタリバン政権崩壊後、アフガニスタンでの研究のためのより大きなデータの利用可能性や研究の可能性の向上によるものであることがわかります。
論文の内容の分析
書かれた単語の数
これにより、アフガニスタンのジェンダー平等に関する研究に関する最初の洞察が得られますが、私たちは主に研究者が実際に何を書いたかに興味があります。これらの論文の内容を把握するために、ElicitがCSVファイルに含めてくれた要約を活用することができます。これを行うために、Jan Kirenzが彼のブログ記事の1つで概説した方法など、テキスト分析の標準的な手順に従うことができます。まず、各要約の単語数を単純に数えることから始めましょう。これには、ラムダメソッドを使用します:
#抄録のテキストを単語のリストに分割し、リストの長さを計算する
df["単語数"] = df["抄録"].apply(lambda n: len(n.split()))
#最初の行を表示する
print(df[["抄録", "単語数"]].head())
#出力:
抄録 単語数
0 従来の社会であるアフガニスタンは常にジェンダーの不平等を抱えてき... 122
1 アフガニスタンのジェンダー不平等指数は、女性の地位や機会に対するジェンダーの不... 203
2 文化的および宗教的な慣行は、アフガニスタンにおけるジェンダーの不平等を強化する... 142
3 ジェンダーの平等は、軽視されがちな問題である。アフガニスタンのジェンダー平等につ... 193
4 最近のタリバン政権の崩壊により、アフガニスタンのジェンダー平等に関する研究は増加し... 357
#単語数の列についての情報を表示する
df["単語数"].describe()
count 168.000000
mean 213.654762
std 178.254746
min 15.000000
25% 126.000000
50% 168.000000
75% 230.000000
max 1541.000000素晴らしいです。ほとんどの抄録は単語が豊富です。平均して213.7単語あります。ただし、最小の抄録は15単語しかなく、最大の抄録は1,541単語です。
研究者は何について書いているのか?
抄録が情報に富んでいることがわかったので、主に何について書かれているのかを尋ねてみましょう。各単語の出現頻度分布を作成することで、それを行うことができます。ただし、ストップワードなどの特定の単語には興味がありません。そのため、テキスト処理を行う必要があります:
#まず、すべてを小文字に変換する
df['抄録(小文字)'] = df['抄録'].astype(str).str.lower()
df.head(3)#csvをインポート
#列をトークン化する
from nltk.tokenize import RegexpTokenizer
regexp = RegexpTokenizer('\w+')
df['text_token']=df['抄録(小文字)'].apply(regexp.tokenize)
#新しいデータセットの最初の行を表示する
df.head(3)
#ストップワードを削除する
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
#英語のストップワードのリストを作成する
stopwords = nltk.corpus.stopwords.words("english")
#カスタムストップワードのリストを拡張する
my_stopwords = ['https']
stopwords.extend(my_stopwords)
#ラムダ関数を使用してストップワードを削除する
df['text_token'] = df['text_token'].apply(lambda x: [item for item in x if item not in stopwords])
#データフレームの最初の行を表示する
df.head(3)
#出現頻度が少ない単語(2文字以下)を削除する
df['text_string'] = df['text_token'].apply(lambda x: ' '.join([item for item in x if len(item)>2]))
#データフレームの最初の行を表示する
df[['抄録(小文字)', 'text_token', 'text_string']].head()ここで行っていることは、まずすべての単語を小文字に変換し、後で自然言語処理のツールを使用してトークン化することです。単語トークン化は自然言語処理の重要なステップであり、テキストを個々の単語(トークン)に分割することを意味します。RegexpTokenizerを使用し、抽象のテキストを英数字の特性に基づいてトークン化します(‘\w+’で示されます)。結果のトークンをtext_token列に保存します。その後、nltkの自然言語処理ツールボックスの辞書を使用して、このトークンのリストからストップワードを削除します。2文字未満の単語を削除します。このタイプのテキスト処理は、より意味のある用語に焦点を当てるための分析を支援します。
ワードクラウドを生成する
処理したテキストから単語のリストを生成し、このリストをトークン化してワードクラウドを生成します:
from wordcloud import WordCloud
#単語のリストを作成する
all_words = ' '.join([word for word in df['text_string']])
#ワードクラウド
wordcloud = WordCloud(width=600,
height=400,
random_state=2,
max_font_size=100).generate(all_words)
plt.figure(figsize=(10, 7))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off');
ワードクラウドは、最も頻繁に言及される単語が検索クエリの一部でもあることを示しています:アフガニスタン、ジェンダー、ジェンダー平等。ただし、その他の代替語も最も言及される単語のリストの一部です:womenとmen。これらの単語自体はあまり情報を提供しませんが、他の単語は提供します:アフガニスタンにおけるジェンダー平等の研究では、研究者は教育、人権、社会、国家に非常に関心を持っているようです。驚くべきことに、パキスタンもリストの一部です。これは、検索クエリによって生成された結果が正確ではなく、アフガニスタンのジェンダー平等に関する研究も含まれている可能性があることを意味するかもしれませんが、それを求めていませんでした。または、アフガニスタンの女性のジェンダー平等も、国内の困難な状況の結果としてパキスタンで重要な研究トピックである可能性もあります。
著者の感情を分析する
理想的には、研究は中立で感情や意見がない状態であるべきです。しかし、人間の本性からくる意見や感情を持っていることは避けられません。研究者が自身の感情をどの程度自身の執筆内容に反映しているか調査するために、感情分析を行うことができます。感情分析は、テキストのセットが肯定的、中立的、または否定的かどうかを分析するための手法です。この例では、VADER Sentiment Analysis Toolを使用します。VADERはValence Aware Dictionary and Sentiment Reasonerの略であり、辞書とルールベースの感情分析ツールです。
VADER感情分析ツールの動作原理は、関連する感情を持つ膨大な数の単語からなる事前構築された感情辞書を使用します。また、文法のルールを考慮して短いテキストの感情極性(肯定的、中立的、否定的)を検出します。このツールは、テキスト内の各単語と文法のルールに基づいて感情スコア(または複合スコアとも呼ばれる)を生成します。このスコアは-1から1までの範囲であり、0より大きい値は肯定的で、0より小さい値は否定的です。このツールは事前構築された感情辞書を使用するため、複雑な機械学習モデルや広範なモデルは必要ありません。
# 必要な感情スコアを含む辞書へのアクセス
nltk.download('vader_lexicon')
# 感情分析オブジェクトの初期化
from nltk.sentiment import SentimentIntensityAnalyzer
# 分析器を使用して感情極性スコアを計算
analyzer = SentimentIntensityAnalyzer()
# 極性スコアメソッド - 極性カラムに結果を割り当てる
df['polarity'] = df['text_string'].apply(lambda x: analyzer.polarity_scores(x))
df.tail(3)
# データ構造を変更 - 元のデータセットと新しいカラムを連結
df = pd.concat(
[df,
df['polarity'].apply(pd.Series)], axis=1)
# 新しいカラムの構造を表示
df.head(3)
# 複合スコアの平均値を計算
df.compound.mean()
# 出力: 0.20964702380952382上記のコードは、著者ごとに-1から1までの範囲である極性スコア(ここでは複合スコアとして表される)を生成します。平均値は0を上回っているため、ほとんどの研究は肯定的な意味合いを持っています。これは時間の経過とともにどのように変化しましたか?シンプルに年ごとの感情をプロットすることができます:
# 折れ線グラフ
g = sns.lineplot(x='Year', y='compound', data=df)
# ラベルとタイトルを調整
g.set(title='アブストラクトの感情')
g.set(xlabel="年")
g.set(ylabel="感情")
# ポジティブとネガティブのスコアを分けるために、中立スコアであるゼロを示す灰色の線を追加
g.axhline(0, ls='--', c = 'grey')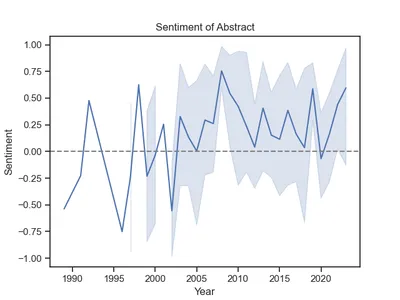
興味深いですね。2003年以降、研究のほとんどは肯定的な意味合いを持っていました。それ以前は、感情がより大きく変動し、平均的にはより否定的でした。おそらく、アフガニスタンの女性の困難な状況によるものです。
結論
自然言語処理は、大量のテキストから価値ある洞察を生成するのに役立ちます。ここで、約170の論文から学んだことは、教育と人権がElicitによって収集された研究論文で最も重要なトピックであり、研究者たちは2003年以降、タリバンが2001年に権力を持ってからアフガニスタンのジェンダー平等についてより肯定的に書くようになりました。
キーポイント
- 自然言語処理ツールを使用して、特定の研究分野で研究されている主要なトピックに対する素早い洞察を得ることができます。
- ワードクラウドは、テキスト内で最もよく使用される単語を理解するための優れた可視化ツールです。
- 感情分析により、研究は予想されるほど中立的ではないことが示されます。
この記事が有益であると思います。LinkedInでお気軽にご連絡ください。データを活用して良い結果を生み出すために協力しましょう!
よくある質問
参考文献
- World Economic Forum. Global Gender Gap Report 2023.
- Elicit. リンク:Why did gender equality fail in afghanistan | Search | Elicit
- Jan Kirenz. PythonにおけるNLTKとpandasを使用したテキストマイニングと感情分析。
- Hutto, C.J. & Gilbert, E.E. (2014). VADER: A Parsimonious Rule-based Model for Sentiment Analysis of Social Media Text. Eighth International Conference on Weblogs and Social Media (ICWSM-14). Ann Arbor, MI, June 2014.
この記事で表示されるメディアはAnalytics Vidhyaが所有しておらず、著者の裁量により使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- Eleuther AI Research Groupが、Classifier-free Guidance(CFG)がLLMsとどのように組み合わされるかを実証しました
- ビンガムトン大学の研究者たちは、社会的な写真共有ネットワークでの自分たちの顔の管理を可能にするプライバシー向上の匿名化システム(私の顔、私の選択)を紹介しました
- CMUの研究者がFROMAGeを紹介:凍結された大規模言語モデル(LLM)を効率的に起動し、画像と交錯した自由形式のテキストを生成するAIモデル
- OpenAIのChatGPTアプリがBingの統合機能を備えたブラウジング機能を導入しました
- ETH ZurichとMax Plankの研究者が提案するHOOD グラフニューラルネットワーク、マルチレベルメッセージパッシング、および教師なし学習を活用して現実的な衣類のダイナミクスを効率的に予測する新しいメソッド
- 研究者たちは、磁気のトリックを使って、量子コンピューティングの進歩を遂げました
- MITの研究者が、生成プロセスの改善のために「リスタートサンプリング」を導入