「大規模なラスター人口データの探索」
Exploring large-scale raster population data

Pythonを使用して、グローバル、国、都市レベルの地理空間人口データを視覚化する
オンラインで見かける美しい人口地図をよく見ますが、チュートリアルに表示されているマップセグメント以外を視覚化したり、大規模なラスターデータを計算に適したベクターフォーマットに変換したりするなど、いくつかの技術的な問題に直面することがあります。この記事では、主要なグローバル人口データソースに関する実践的なガイドを提供し、これらの課題のいくつかを克服します。
人口データとそれらを表示するマップは、都市開発や位置情報タスクにおいて収集し組み込むための基本的かつ貴重な情報です。新しい施設の計画、サイト選択とキャッチメント分析、都市製品のスケールの推定、または異なる地域のプロファイリングなど、さまざまな用途で役立ちます。
1. データソース
以下の2つの詳細な人口推定データソースを使用します。関連ファイルは、以下のリンクからダウンロードできます(記事の公開時点でのリンク)。
- 欧州委員会のGHSL(Global Human Settlement Layer)- 各グリッドセルの人口レベルを測定します。全体の説明はこちら、2023年の報告書で使用した特定のセットはこちら(空間分解能は100m)。
- WorldPopハブ – 制約付きの個々の国のデータセットを使用して、ドイツを例に取り上げます(解像度は100m)。一覧はこちら、ドイツのデータはこちら。
2. グローバル人口データの視覚化
2.1. データのインポート!
私は最初にこのデータセットについて、Architecture PerformanceのDatashaderチュートリアルで知りました。彼らの視覚化を再現した後、グローバルマップに拡張しようとしていくつかの障害に遭遇しました。そのため、この作業を開始するきっかけとなりました。今、私はそれをどのように行うかについての解決策を紹介します。
まず、xarrayパッケージを使用してラスターファイルを解析します。
import rioxarrayfile_path = "GHS_POP_E2030_GLOBE_R2023A_54009_100_V1_0/GHS_POP_E2030_GLOBE_R2023A_54009_100_V1_0.tif" data_array = rioxarray.open_rasterio(file_path, chunks=True, lock=False)data_arrayこのセルの出力は、データセットの詳細な説明です:

2.2. データのセグメントを視覚化する
これは、ほとんどの標準的なノートパソコンにとって非常に多量のデータです。それでも、このような大規模な地理空間データセットを視覚化するために非常に便利なツールであるDatashaderを使用して、視覚化してみましょう。
# 警告:このコードブロックはおそらくメモリオーバーフローエラーを引き起こしますimport datashader as dsimport xarray as xrfrom colorcet import palettefrom datashader import transfer_functions as tf# プロットの準備data_array_p = xr.DataArray(data_array)[0]data_array_p = data_array_p.where(data_array_p > 0)data_array_p = data_array_p.compute()# 画像サイズを取得size = 1200asp = data_array_p.shape[0] / data_array_p.shape[1]# データシェーダーキャンバスを作成cvs = ds.Canvas(plot_width=size, plot_height=int(asp*size))raster = cvs.raster(data_array_p)# 画像を描画cmap = palette["fire"]img = tf.shade(raster, how="eq_hist", cmap=cmap)imgこのコードは技術的には正常に見えますが、私の2021年製のM1 Macbook Pro(RAM容量16GB)では、メモリオーバーフローエラーが発生します。そのため、画像を切り抜いてデータを確認しましょう!そのために、Architecture Performanceに従い、現時点ではヨーロッパに焦点を当てます。
ただし、後で答える主な質問は、どのようにしてメモリの制限があるにもかかわらず、ローカルマシンを使用して全体のデータを視覚化できるかですか?お待ちください!
import datashader as ds
import xarray as xr
from colorcet import palette
from datashader import transfer_functions as tf
import numpy as np
# データ配列を切り取る
data_array_c = data_array.rio.clip_box(minx=-1_000_000.0, miny=4_250_000.0, maxx=2_500_000.0, maxy=7_750_000.0)
data_array_c = xr.DataArray(data_array_c)
# プロットの準備
data_array_c = xr.DataArray(data_array_c)[0]
data_array_c = data_array_c.where(data_array_c > 0)
data_array_c = data_array_c.compute()
data_array_c = np.flip(data_array_c, 0)
# 画像サイズを取得
size = 1200
asp = data_array_c.shape[0] / data_array_c.shape[1]
# データシェーダーキャンバスを作成
cvs = ds.Canvas(plot_width=size, plot_height=int(asp*size))
raster = cvs.raster(data_array_c)
# 画像を描画
cmap = palette["fire"]
img = tf.shade(raster, how="eq_hist", cmap=cmap)
img = tf.set_background(img, "black")
imgこのコードブロックは次のビジュアルを出力します:

‘fire’カラーマップを使用することは、業界での標準的な理由のためのようですが、もし変化を加えたい場合は、ここで他のカラーマップを見つけて以下に適用することができます:
# データシェーダーキャンバスを作成
cvs = ds.Canvas(plot_width=size, plot_height=int(asp*size))
raster = cvs.raster(data_array_c)
# 画像を描画
cmap = palette["bmw"]
img = tf.shade(raster, how="eq_hist", cmap=cmap)
img = tf.set_background(img, "black")
imgこのコードブロックは次のビジュアルを出力します:

2.3. 全世界の視覚化
データはそこにありますが、通常のコンピュータを手に入れても、解像度が100mの全世界を視覚化したい場合はどうでしょうか?ここで紹介する回避策は比較的簡単です。ラスタイメージ全体を約100個の小さなタイルに分割し、コンピュータが1つずつ処理できるようにし、それから画像操作のトリックを使って1つの画像ファイルに統合します。
ただし、次に進む前に、XArray配列を次のようにダウンサンプリングするオプションもありますが、データセット全体を処理できる適切なダウンスケーリング方法を見つけることができませんでした。さらに、精度を失いたくなく、データセット全体を完全な形で表示したかったのです。
# データをダウンサンプリングする方法
downsampling_factor = 20
downsampled_data_array = data_array.coarsen(x=downsampling_factor, y=downsampling_factor).mean()
downsampled_data_arrayそして、出力は以前にプロットされたdata_arrayに縮小する価値があるものです:

全体のラスタイメージをグリッドセグメントに分割するために、まずその境界を取得し、ステップサイズNとして定義します。次に、画像セグメントの境界のリストを作成します。
minx = float(data_array.x.min().values)
maxx = float(data_array.x.max().values)
miny = float(data_array.y.min().values)
maxy = float(data_array.y.max().values)
N = 10
xstep = (maxx-minx) / N
ystep = (maxy-miny) / N
xsteps = list(np.arange(minx, maxx, xstep))
ysteps = list(np.arange(miny, maxy, ystep))今、各xステップとyステップごとに繰り返し処理を行い、各画像セグメントを作成します。各画像ファイルは元のグリッド内の位置に基づいて名前が付けられます。このループは時間がかかる場合があります。
import osfoldout = 'world_map_image_segments'if not os.path.exists(foldout): os.makedirs(foldout)for idx_x, x_coord in enumerate(xsteps): for idx_y, y_coord in enumerate(ysteps): if not os.path.exists(foldout+'/'+str(idx_x)+'_'+str(idx_y)+'.png'): data_array_c = data_array.rio.clip_box( minx=x_coord, miny=y_coord, maxx=x_coord+xstep, maxy=y_coord+ystep) data_array_c = xr.DataArray(data_array_c)[0] data_array_c = data_array_c.fillna(0) data_array_c = data_array_c.where(data_array_c > 0) data_array_c = data_array_c.compute() data_array_c = np.flip(data_array_c, 0) size = 2000 asp = data_array_c.shape[0] / data_array_c.shape[1] cvs = ds.Canvas(plot_width=size, plot_height=int(asp*size)) raster = cvs.raster(data_array_c) cmap = palette["fire"] img = tf.shade(raster, how="eq_hist", cmap=cmap) img = tf.set_background(img, "black") pil_image = img.to_pil() pil_image.save(foldout+'/'+str(idx_x)+'_'+str(idx_y)+ '.png') print('SAVED: ', x_coord, y_coord, y_coord+xstep,y_coord+ystep)最後に、すべての画像セグメントがある場合、次の関数を使用してそれらを迅速に組み立てることができます。このコードの一部については、ChatGPTにもヒントを求めて処理を高速化しましたが、通常どおり、手動で微調整が必要でした。
from PIL import Imagedef find_dimensions(image_dir): max_x = 0 max_y = 0 for filename in os.listdir(image_dir): if filename.endswith(".png"): x, y = map(int, os.path.splitext(filename)[0].split("_")) max_x = max(max_x, x) max_y = max(max_y, y) return max_x + 1, max_y + 1 image_dir = foldoutsegment_width = sizesegment_height = int(asp*size)# 大きな画像の寸法を決定するlarge_image_width, large_image_height = find_dimensions(image_dir)# 空の大きな画像(白地)を作成するlarge_image = Image.new("RGB", (large_image_width * segment_width, large_image_height * segment_height), "black")# 個々の画像セグメントをループして大きな画像に貼り付けるfor filename in sorted(os.listdir(image_dir)): if filename.endswith(".png"): x, y = map(int, os.path.splitext(filename)[0].split("_")) segment_image = Image.open(os.path.join(image_dir, filename)) x_offset = x * segment_width y_offset = large_image_height * segment_height-1*y * segment_height large_image.paste(segment_image, (x_offset, y_offset))# 結合された大きな画像を保存するlarge_image.save("global_population_map.png") そして最終の結果はこちら、地球全体のマップ:

3. ワールドポップデータの可視化と変換
次に示すデータソースは、ワールドポップの人口データベースであり、大陸と国を別々に様々な解像度で提供しています。この例では、前節の大陸と全球レベルに加えて、国と都市のレベルを取り上げます。例えば、ドイツと2020年の解像度100mを使用し、GeoPandasを使用して都市を国全体から切り出し、使いやすいベクトル形式に変換する方法も紹介します。
3.1. ワールドポップデータの可視化
前の方法を使用して、このラスターファイルを再び簡単に可視化できます:
# データを解析するdata_file = 'deu_ppp_2020_constrained.tif'data_array = rioxarray.open_rasterio(data_file, chunks=True, lock=False)# データを準備するdata_array = xr.DataArray(data_array)[0]data_array = data_array.where(data_array > 0)data_array = data_array.compute()data_array = np.flip(data_array, 0)# 画像のサイズを取得するsize = 1200asp = data_array.shape[0] / data_array.shape[1]# データシェーダーキャンバスを作成するcvs = ds.Canvas(plot_width=size, plot_height=int(asp*size))raster = cvs.raster(data_array)# 画像を描画するcmap = palette["fire"]img = tf.shade(raster, how="eq_hist", cmap=cmap)img = tf.set_background(img, "black")imgこのコードブロックは、次のビジュアルを出力します:
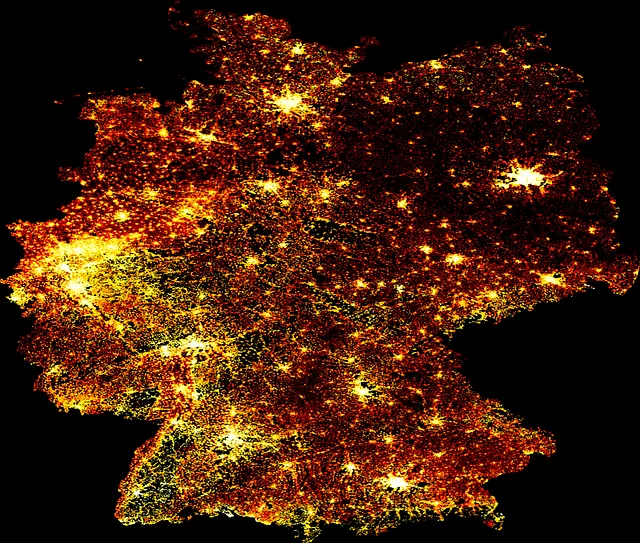
3.2. WorldPopデータの変換
地球全体、ヨーロッパ大陸、ドイツの国を視覚化した後、ベルリン市のより具体的なデータに手を入れ、そのようなラスタデータをベクトル形式に変換し、GeoPandasを使用して簡単に操作する方法を紹介します。このために、ここでgeojson形式のベルリンの行政境界にアクセスします。
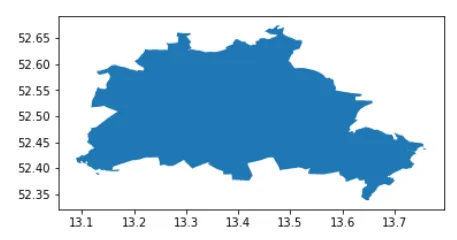
この行政ファイルには、ベルリンの行政区が含まれているため、まず、それらを都市全体として統合します。
from shapely.ops import cascaded_unionimport geopandas as gpdadmin = gpd.read_file('tufts-berlin-bezirke-boroughs01-geojson.json')admin = gpd.GeoDataFrame(cascaded_union(admin.geometry.to_list()), columns = ['geometry']).head(1)admin.plot()このコードブロックは、次のビジュアルを出力します:
今度はxarrayをPandas DataFrameに変換し、ジオメトリ情報を抽出し、GeoPandas GeoDataFrameを作成します。これを行う方法の一つは次の通りです:
import pandas as pddf_berlin = pd.DataFrame(data_array.to_series(), columns = ['population']).dropna()これから、ベルリンに焦点を当てて、このデータからGeoDataFrameを作成します:
from shapely.geometry import Point# より簡単な座標選択のために制限境界ボックスを見つけるminx、miny、maxx、maxy = admin.bounds.T[0].to_list()points = []population = df_berlin.population.to_list()indicies = list(df_berlin.index)# この制限境界ボックスに含まれるポイントからPointジオメトリを作成するgeodata = []for ijk, (lon, lat) in enumerate(indicies): if minx <= lat <= maxx and miny <= lon <= maxy: geodata.append({'geometry' : Point(lat, lon), 'population' : population[ijk]}) # GeoDataFrameを作成するgdf_berlin = gpd.GeoDataFrame(geodata)gdf_berlin = gpd.overlay(gdf_berlin, admin)次に、人口をベクトルデータとして視覚化します:
import matplotlib.pyplot as pltf, ax = plt.subplots(1,1,figsize=(15,15))admin.plot(ax=ax, color = 'k', edgecolor = 'orange', linewidth = 3)gdf_berlin.plot(column = 'population', cmap = 'inferno', ax=ax, alpha = 0.9, markersize = 0.25)ax.axis('off')f.patch.set_facecolor('black')このコードブロックは、次のビジュアルを出力します:
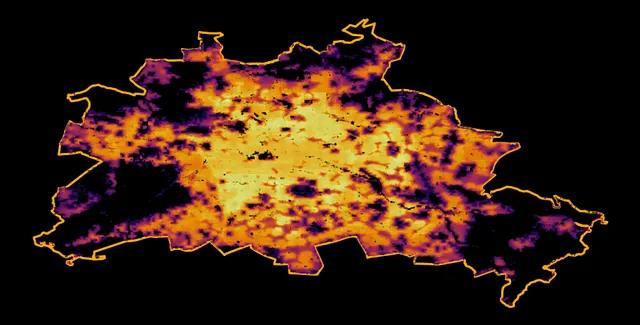
最後に、ラスタファイルの各ピクセルに対応する各ポイントジオメトリに割り当てられた100mの解像度の人口レベルを持つ標準的なGeoDataFrameができました。
要約
この記事では、異なる近似、測定、およびモデリング手法を組み合わせて、100mの非常に高い空間分解能を持つラスタグリッドを使用して人口レベルを推定するさまざまなグローバル人口データセットを探求しました。このタイプの情報は、都市開発や場所情報など、都市開発や場所情報など、さまざまなアプリケーションにおいて非常に貴重です。技術的な面からは、全世界をカバーし、国にズームインし、最後に都市に焦点を当てた3つの空間レベルで例を示しました。方法論はより小さな解像度でも対応できますが、これらはすべて、Xarray、DataShader、およびGeoPandasといった強力なPythonライブラリを使用して、単一のノートパソコン上で実行されました。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
