「データメッシュを探索する:データアーキテクチャのパラダイムシフト」
「データメッシュを追求する:データアーキテクチャの次世代」

技術的な、組織的な、およびビジネスのニーズの変化に応えて、過去10年ほどでデータアーキテクチャは進化してきました。しかし、この進化は十分に重要だったのでしょうか?ほとんどの組織は通常、集中型のデータアーキテクチャを持っています。このアーキテクチャはデータを一つの傘の下に集約し、しばしば専任のデータチームによって管理されます。
セキュリティやより良いガバナンスを確保するために効果的ですが、集中型のデータアーキテクチャにはスケーラビリティ、柔軟性、アクセシビリティなどの制約があります。
ここでデータメッシュが登場します。これはソフトウェアアーキテクチャにおけるマイクロサービスにほぼ類似したコンセプトです。データメッシュは、データの所有権と責任をドメイン固有のチームに分散させることで、データを戦略的な資産と見なし、ソースで最良に管理することを認めます。
この記事では、データメッシュ、その主要な原則、考慮すべき要素、データメッシュアーキテクチャの採用に関連する課題について探っていきます。
データメッシュとは何ですか?
データメッシュの概念は、Zhamak Dehghaniによって最初に紹介されました。その記事でデータメッシュの原則や概念が説明されています。この記事とデータコミュニティ内での議論は、データメッシュアーキテクチャの普及に大きな役割を果たしました。
データメッシュは、従来の集中型のデータモデルとは異なる現代的なデータアーキテクチャと管理のアプローチです。データメッシュは、組織のデータ資産を組織化、配布、利用するための分散型の構造を導入します。
データメッシュでは、データの所有権と責任をドメイン固有のチームまたはデータ製品チームに分散させ、各ドメイン内で独自にデータを管理する権限を与えます。
この分散型のアプローチは、集中型のデータモデルに関連する制約、スケーラビリティの課題、データの隔離、データニーズの変更に対する応答時間の遅さなどに対応することを目指しています。ドメイン固有のチームにデータの独立した管理権限を与えることで、データメッシュは組織内のデータの自治、適応性、責任を促進します。多様なデータソースの効率的な取り扱いを可能にし、データの品質と適合性に重点を置いた同時にデータメッシュを実現します。
データメッシュアーキテクチャの主要な原則
データメッシュアーキテクチャは、組織内および組織間のデータのスケーリングと管理の課題に対処するために設計された一連の原則に基づいて構築されています。これらの原則は、分散型でよりスケーラブルなデータ管理のアプローチの基盤を提供します。
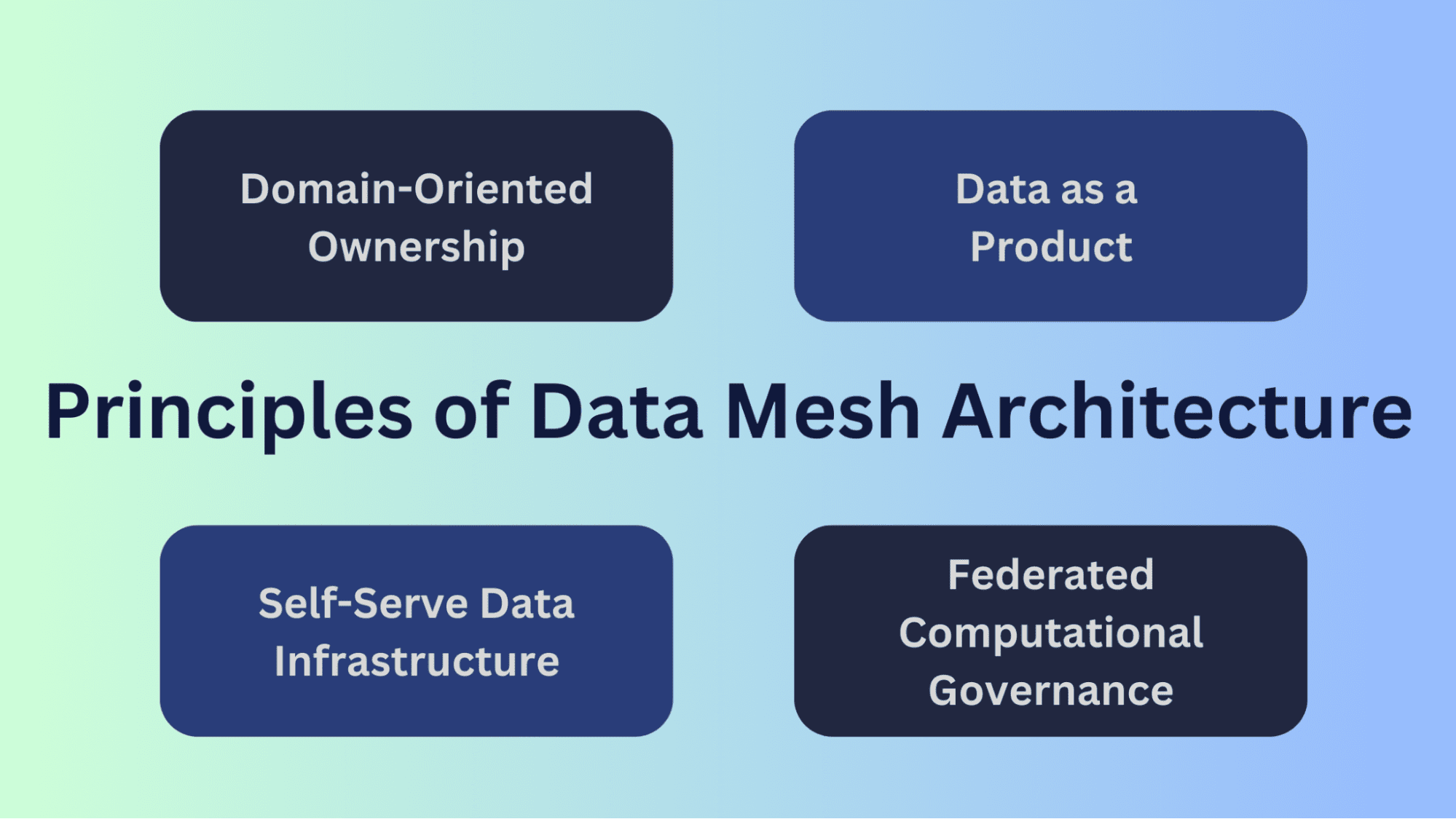
ドメイン指向の所有権
データメッシュでは、データの所有権が組織内のさまざまなドメインまたはビジネスユニットに分散しています。各ドメインは、専門領域や機能内で生成および使用されるデータに責任を持ちます。この原則は、ドメインの専門家が自身のドメイン内のデータのコンテキストを深く理解し、その完全性を確保できるという事実を認識しています。
ドメイン指向の所有権はデータの品質と正確さを向上させます。データソースに最も近い人々がそのコンテキストを深く理解しているため、データの保全を確実にします。また、ドメインチームに対してデータに対する所有感と責任感を促進し、データの高い基準を維持するよう促します。
データを製品として扱うこと
データメッシュでは、データはビジネスの運用の副産物ではなく製品として扱われます。各ドメインは、他のドメイン内で消費されるために設計され、パッケージ化され、利用可能になるような定義されたデータ製品の提供に責任を持ちます。これらのデータ製品には明確な定義、アクセスメカニズム、サービスレベル契約(SLA)があります。
データを製品として扱うことにより、データプロデューサーは高品質で価値のあるデータを提供することに焦点を当てることができます。また、データ製品がユーザーのニーズを考慮して設計されるため、データはより幅広い関係者にとってよりアクセス可能で使いやすくなります。
自己サービス型データインフラストラクチャ
データメッシュは、データアナリスト、データサイエンティスト、ビジネスユーザなどのデータコンシューマがデータに独立してアクセスし、処理することを可能にする、自己サービス型のデータインフラストラクチャの開発を推進しています。このインフラストラクチャには、データカタログ、データ探索メカニズム、データ処理パイプラインなどが含まれ、中央集権的なデータエンジニアリングチームへの強い依存を回避しながら、コンシューマがデータを見つけ、理解し、利用することができるようにします。
自己サービス型データインフラストラクチャは、ボトルネックを減らし、データアクセスを加速させ、より幅広いユーザがデータを扱えるようになります。これにより、組織内でデータを民主化し、よりアクセスしやすくし、迅速な洞察と意思決定を可能にします。
連邦的計算ガバナンス
分散型データアーキテクチャにおいてデータの品質、セキュリティ、コンプライアンスを維持するために、データメッシュは連邦的計算ガバナンスを採用しています。各ドメインは、そのデータの特定のニーズに合わせた独自のガバナンスポリシーを定義し、適用します。グローバルな標準やガイドラインが存在するかもしれませんが、個々のドメインは独自のデータ資産を管理する自律性を持ちます。
これにより、グローバルなデータ基準の必要性と個々のドメインの柔軟性をバランスさせることができます。これにより、ドメインはユニークなデータの課題に対してガバナンスの実践を適応させながら、データが安全でコンプライアンスがあり、品質の高い状態を維持します。
データメッシュのこれらの4つのキー原則は、大規模組織におけるデータオペレーションのスケーリングの課題に対処するため、以下を推進することを目的としています:
- 分散化
- データプロダクトの考え方
- 自己サービス
- 効果的なガバナンス
これらの原則を実施することで、組織はデータ資産のフルポテンシャルを引き出し、ドメインチーム間のコラボレーションを改善し、データをあらゆる利害関係者にとって価値のある、アクセスしやすい資源にすることができます。
データメッシュの導入を検討中ですか? 以下の要素を考慮してください
データメッシュへの移行は、組織内での文化的な変革を伴うことが多いです。データメッシュは、協力、共有オーナーシップ、およびデータプロダクトの考え方を促進し、データの実践を組織の進化する文化と価値観により密接に結び付けます。データメッシュを実装する際に組織が考慮すべき要素を以下に示します。
ビジネスの目標と戦略
データアーキテクチャの大幅な変更は、組織の広範なビジネスの目標と戦略的な目的と一致する必要があります。
データメッシュの導入は、組織がデータを効果的に活用して全体の目標と目的を達成する能力を向上させるための戦略的な支援手段として捉えられるべきです。
既存のインフラストラクチャ
データメッシュの導入に際しては、組織が現在のデータインフラストラクチャと投資を評価し考慮する必要があります。
データメッシュへの移行には、既存のテクノロジースタックとインフラストラクチャに対する調整が必要となる場合がありますので、これらの側面を新しいアプローチに合わせることが重要です。
データの複雑さとスケール
組織が増大するデータの複雑さとスケールに直面する際には、代替のデータ管理アプローチを考慮する必要があります。データメッシュは、複雑で大規模なデータ環境に対してスケーラビリティと適応性を提供します。
したがって、データのボリューム、バラエティ、速度が中央集権的な管理が困難になる場合や、異なるビジネスユニットやドメイン間でデータ要件が多岐にわたる場合には、データメッシュが適切な選択肢です。
データガバナンスとコンプライアンス
データの品質、プライバシー、セキュリティ、コンプライアンスの維持は、分散型環境におけるデータ管理の難しい側面です。
データメッシュの戦略は、これらの複雑さに効果的に対処し、データガバナンスの実践と法的要件を満たすことを確認する必要があります。
データのアクセシビリティとオーナーシップ
分散したデータソースと多様なドメインを持つ組織では、従来の中央集権型データ管理では十分ではありません。データメッシュの導入により、データのオーナーシップをドメイン固有のチームに合わせることができます。これにより、彼らは自身のデータに責任を持ち、特にそのような環境では特に価値があります。
また、組織全体でデータに基づく意思決定を促進するためには、データをよりアクセスしやすくすることが重要です。データメッシュはデータアクセスを民主化し、さまざまな部門やチームをまたいで意思決定が改善されることにつながります。
データメッシュアーキテクチャの採用における課題
中央集権的なデータアーキテクチャからデータメッシュへの移行には課題があります。このセクションでは、ガバナンスから監視まで、いくつかの課題について探求します。
データガバナンス
データメッシュでは、データが複数のドメインとチームに分散しているため、データガバナンスはより複雑になります。これらのドメイン全体で一貫したデータ品質、プライバシー、セキュリティ、コンプライアンス基準を確保することは課題となります:
- 複数のチームが関与する場合、データスキーマやアクセス制御の定義などのデータガバナンスタスクについて、明確なデータ所有権と責任を確立することは課題となります。
- データメッシュの分散性に合わせて、データガバナンスポリシーと実践を開発および強制するためには、注意深い計画が必要です。
データの発見性
分散型のデータメッシュでは、データの発見とアクセスは課題となる場合があります。データの適切なカタログ化、タグ付け、ドキュメント化が必要です。以下にいくつかの戦略を示します:
- 効果的なメタデータ管理手法の実装により、データセットのコンテキストと説明を提供し、利用可能なデータリソースをユーザーが理解しやすくします。
- ユーザーが効率的に関連するデータセットを検索できるデータカタログまたはメタデータリポジトリの開発と維持。
データ所有権
データメッシュでは、各データドメインとデータ製品について明確で一貫したデータ所有権と責任の定義が重要です。特に、複数の利害関係者がいる場合、データの維持、更新、およびキュレーションを担当する責任者を特定することは課題となります。組織は以下のような方法でこの課題に取り組むことができます:
- データオーナーが自分のデータドメインを効果的に管理するために必要な権限とリソースを持っていることを確保する。
- データ所有権と責任に関連する紛争や問題の解決のためのメカニズムを確立する。
モニタリングと観測
データメッシュでは、データパイプラインとデータ製品の健全性、パフォーマンス、信頼性を監視することは複雑です。以下にいくつかの戦略を示します:
- 異なるドメイン間でデータの品質、遅延、使用状況を追跡するための堅牢なモニタリングと観測ツールと実践の実装。
- データの可用性や信頼性に影響を及ぼす可能性のある問題を迅速に識別し対応するためのアラートとレポートのメカニズムの開発。
データメッシュの実装におけるいくつかの課題を強調しました。これらは、中央集権型のデータメッシュアーキテクチャへの移行時に組織が意識すべき要点です。
結論
データメッシュは、中央集権モデルの課題に対する解決策を提供する、データアーキテクチャの基本的な変革です。データの所有権の分散、データ製品の考え方の促進、セルフサービスアクセスの可能性を紹介しました。しかし、成功した実装には、文化的、技術的要素の慎重な考慮と、データガバナンスに対する積極的なアプローチが必要です。Bala Priya Cは、インド出身の開発者兼技術ライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点で働くことが好きです。彼女の関心と専門知識の領域には、DevOps、データサイエンス、自然言語処理があります。彼女は読書、執筆、コーディング、コーヒーが好きです!現在は、チュートリアル、ハウツーガイド、意見記事などを執筆することにより、開発者コミュニティとの学習と知識共有に取り組んでいます。
[Bala Priya C](https://twitter.com/balawc27)は、インド出身の開発者兼技術ライターです。彼女は数学、プログラミング、データサイエンス、コンテンツ作成の交差点で働くことが好きです。彼女の関心と専門知識の領域には、DevOps、データサイエンス、自然言語処理があります。彼女は読書、執筆、コーディング、コーヒーが好きです!現在は、チュートリアル、ハウツーガイド、意見記事などを執筆することにより、開発者コミュニティとの学習と知識共有に取り組んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
