「ソースフリーなドメイン適応の汎用的な方法を探求する」
Exploring a generic approach to source-free domain adaptation.
Google の研究科学者であるエレニ・トリアンタフィルーと学生研究員であるマリック・ブディアフによって投稿されました。
ディープラーニングは、最近多くの問題とアプリケーションで著しい進歩を遂げていますが、モデルは未知のドメインや分布で展開された場合に予測不能に失敗することがよくあります。ソースフリーなドメイン適応(SFDA)は、事前にトレーニングされたモデル(「ソースドメイン」でトレーニングされたもの)を新しい「ターゲットドメイン」に適応させるための方法を、後者の非ラベルデータのみを使用して設計するための研究分野です。
ディープモデルに対する適応方法の設計は、重要な研究分野です。モデルとトレーニングデータセットの規模の増加が彼らの成功の鍵要素である一方で、この傾向の否定的な結果は、このようなモデルのトレーニングがますます計算コストがかかるということであり、一部の場合では大規模なモデルのトレーニングがアクセスしにくくなり、不必要に炭素フットプリントを増加させることになります。この問題を緩和する方法の一つは、既にトレーニングされたモデルを活用して新しいタスクに対処したり、新しいドメインに一般化するための技術を設計することです。実際、モデルを新しいタスクに適応することは、転移学習の枠組みの下で広く研究されています。
SFDAは、適応が望まれるいくつかの実世界のアプリケーションにおいて、ターゲットドメインからのラベル付きの例が利用できないという問題に直面しています。実際、SFDAは増加している注目を集めています[1, 2, 3, 4]。しかし、野心的な目標に基づいているものの、ほとんどのSFDAの研究は非常に狭い枠組みに基づいており、画像分類タスクでの単純な分布シフトのみを考慮しています。
- 「セマンティックウェブはどうなったのか?」
- なぜシリコンバレーは人工知能の拠点となっているのか
- 究極のGFNサーズデー:41の新しいゲームに加えて、8月には「Baldur’s Gate 3」の完全版リリースと初めてベセスダのタイトルがクラウドに参加します
この傾向から大きく逸脱し、私たちはバイオアコースティクスの分野に注目し、自然発生的な分布シフトが広く存在し、しばしばターゲットドメインのラベル付きデータが不十分で、実践者にとって障害となっていることに着目します。このアプリケーションにおけるSFDAの研究は、既存の方法の一般化可能性を学術界に知らせ、オープンな研究方向を特定するだけでなく、フィールドの実践者に直接的な利益をもたらし、私たちの世紀の最大の課題の一つである生物多様性保全に寄与することができます。
この投稿では、「ソースフリーなドメイン適応の汎用的な手法を探る」と題したICML 2023で発表される論文を紹介します。私たちは、バイオアコースティクスにおける現実的な分布シフトに直面した場合、最先端のSFDAの手法が性能を発揮しない場合や崩壊する場合があることを示します。さらに、既存の手法は、ビジョンベンチマークで観察されるのとは異なる相対的なパフォーマンスを発揮し、驚くべきことに、時には適応なしよりも悪い結果を示す場合もあります。また、私たちはNOTELAという新しいシンプルな手法を提案し、これらのシフトで既存の手法を凌駕しながら、さまざまなビジョンデータセットで強力なパフォーマンスを発揮することを示します。全体として、私たちは、一般に使用されるデータセットと分布シフトのみでSFDAの手法を評価すると、相対的なパフォーマンスと汎化性能について狭視野な視点になると結論付けます。彼らの約束を果たすためには、SFDAの手法はより広範な分布シフトでテストされる必要があり、高い影響を持つアプリケーションに利益をもたらす自然発生的なシフトを考慮することを提唱します。
バイオアコースティクスにおける分布シフト
バイオアコースティクスでは、自然発生的な分布シフトが広く存在します。鳥の鳴き声のための最大のラベル付きデータセットはXeno-Canto(XC)であり、世界中の野生鳥のユーザー投稿の録音のコレクションです。XCの録音は「焦点化」されており、自然環境で捕獲された個体を対象としており、識別された鳥の鳴き声が前景にあります。しかし、連続的なモニタリングや追跡の目的では、実践者はしばしば全周マイクを介して得られる「サウンドスケープ」における鳥の識別に関心を持っています。これは非常に困難であることを最近の研究が示しているよく文書化された問題です。この現実的なアプリケーションに着想を得て、私たちはバイオアコースティクスでSFDAを研究し、ソースモデルとしてXCで事前にトレーニングされた鳥種分類器を使用し、さまざまな地理的位置からの「サウンドスケープ」(シエラネバダ(S.ネバダ)、パウダーミル・ネイチャーリザーブ(ペンシルベニア州、米国)、ハワイ、カプレス・ウォーターシェッド(カリフォルニア州、米国)、サプサッカー・ウッズ(ニューヨーク州、米国)、コロンビア)をターゲットドメインとして使用します。
この焦点化から受動化への変化は大きいです。後者の録音では、しばしば信号対雑音比が低く、複数の鳥が同時に鳴いており、雨や風などの多くの鳥や環境の雑音もあります。さらに、異なるサウンドスケープは異なる地理的位置から発生しており、XCの種の非常に小さな部分しか表示されないため、非常に極端なラベルのシフトを引き起こします。さらに、現実のデータでは、ソースドメインとターゲットドメインの両方が顕著なクラスの不均衡を持っているため、いくつかの種は他の種よりも著しく一般的です。さらに、SFDAが通常研究される標準的な単一ラベルの画像分類シナリオとは異なり、各録音内で複数の鳥が識別される可能性があるため、私たちはマルチラベル分類問題も考慮しています。
 |
| 「フォーカス→サウンドスケープ」のシフトのイラストです。フォーカスされた領域では、録音は通常、シグナル対雑音比(SNR)が高い、単一の鳥の鳴き声が前景に捉えられていますが、背景には他の鳥の鳴き声がある場合もあります。一方、サウンドスケープには全方位マイクロフォンからの録音が含まれ、同時に複数の鳥が鳴き、昆虫や雨、車、飛行機などの環境音も含まれることがあります。 |
| オーディオファイル | フォーカス領域 | サウンドスケープ領域1 | ||
| スペクトログラム画像 |  |
 |
| フォーカス領域(左)からサウンドスケープ領域(右)への分布の変化を、各データセットからの代表的な録音のオーディオファイル(上)とスペクトログラム画像(下)で示したものです。2つ目のオーディオクリップでは、鳥の鳴き声が非常にかすかです。これは、サウンドスケープ録音では鳥の鳴き声が「前景」にないことが一般的な特徴です。クレジット:左:Sue RiffeによるXC録音(CC-BY-NCライセンス)。右:Kahl、Charif、&Klinckによって提供された録音の一部(2022) “A collection of fully-annotated soundscape recordings from the Northeastern United States” [link](CC-BYライセンス)からのSSWサウンドスケープデータセット。 |
最先端のSFDAモデルはバイオアコースティクスの変化に対して性能が低い
まず、我々はバイオアコースティクスのベンチマークで最先端のSFDA手法6つを評価し、非適応ベースライン(ソースモデル)と比較します。私たちの結果は驚くべきものです:例外なく、既存の手法はすべてのターゲットドメインでソースモデルを一貫して上回ることができません。実際、それらはしばしばそれよりも大幅に性能が劣るのです。
例えば、最近の手法であるTentは、モデルの出力確率の不確かさを減らすことにより、モデルが各例に対して自信を持った予測を行うことを目指しています。Tentはさまざまなタスクでうまく機能しますが、私たちのバイオアコースティクスのタスクでは効果的ではありません。単一ラベルのシナリオでは、エントロピーを最小化することで、モデルは各例に対して確信を持って単一のクラスを選択するようになります。しかし、私たちのマルチラベルのシナリオでは、どのクラスも存在すると選択されるべき制約はありません。これに加えて大きな分布のシフトがあると、モデルは崩壊し、すべてのクラスの確率がゼロになる可能性があります。SHOT、AdaBN、Tent、NRC、DUST、Pseudo-Labellingなどの他のベンチマーク手法も、このバイオアコースティクスのタスクに苦戦しています。
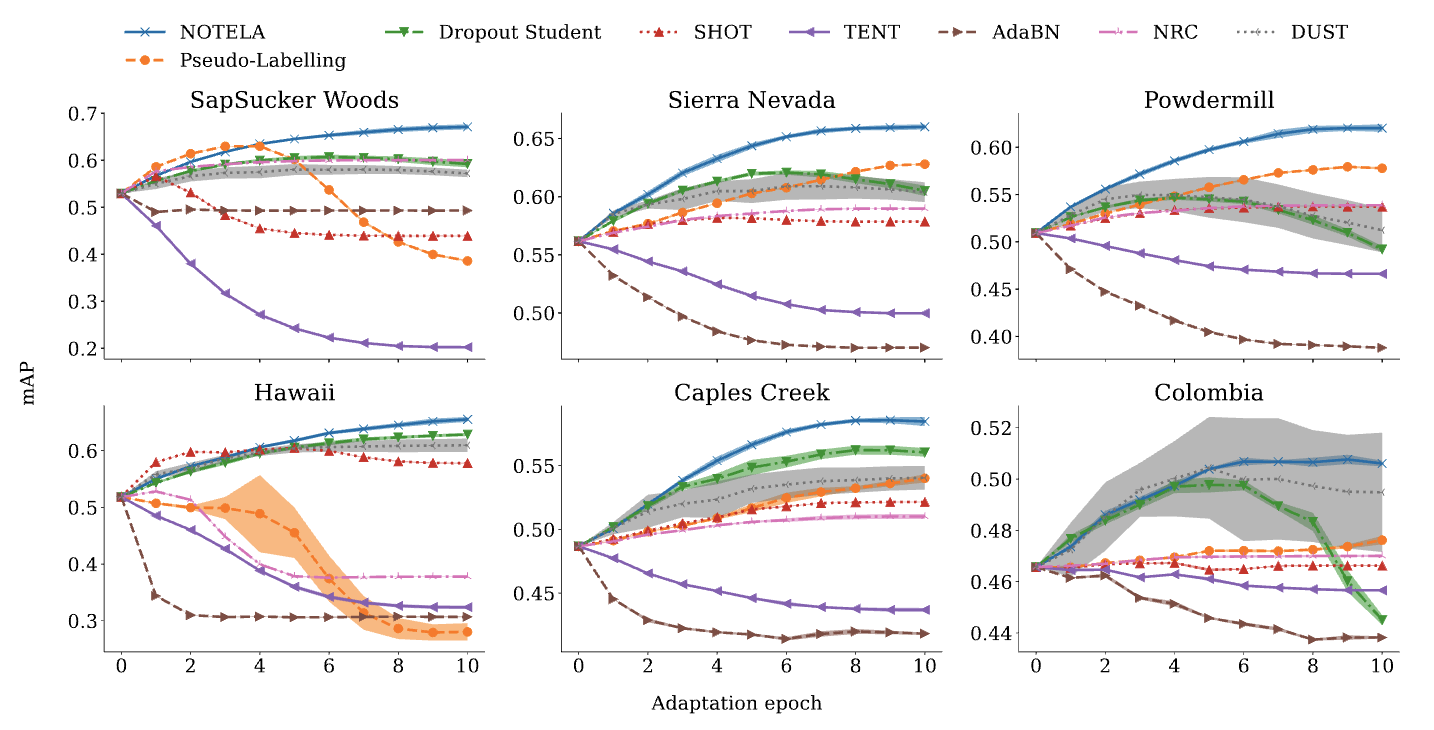 |
| 6つのサウンドスケープデータセットにおける適応手順全体でのテスト平均平均適合度(mAP)の進化。我々の提案するNOTELAとDropout Student、またSHOT、AdaBN、Tent、NRC、DUST、Pseudo-Labellingをベンチマークとして評価しました。NOTELA以外のすべての手法は、ソースモデルを一貫して改善することができません。 |
NOisy student TEacher with Laplacian Adjustment (NOTELA)の紹介
それにもかかわらず、驚くべきポジティブな結果があります。それは、あまり賞賛されていないNoisy Studentの原則が有望であるということです。この教師なしの手法は、モデルに対してランダムノイズを適用しながらターゲットデータセット上で自身の予測を再構築することを促します。ノイズはさまざまな方法で導入することができますが、私たちはシンプルさを重視し、モデルのドロップアウトを唯一のノイズ源として使用します。したがって、この手法をDropout Student(DS)と呼びます。要するに、この手法は、特定のターゲットデータセットにおいて個々のニューロン(またはフィルタ)の影響を制限することをモデルに促します。
DSは効果的ですが、さまざまなターゲットドメインでモデルの崩壊問題に直面しています。私たちは、この問題がソースモデルが最初はそれらのターゲットドメインに対して自信を持っていないために起こると仮説を立てています。私たちは、特徴空間自体を補助的な真理の源として使用することで、DSの安定性を向上させることを提案しています。NOTELAは、NRCの手法とラプラシアン正則化に触発され、特徴空間内の近くの点に対して類似の疑似ラベルを促すことでこれを実現します。このシンプルなアプローチは以下のように視覚化され、音声およびビジュアルのタスクの両方でソースモデルを一貫して大幅に上回る結果を示します。
 |
 |
| NOTELAの実行。音声録音は完全なモデルを通じて転送され、最初の予測セットを得るために使用されます。次に、Laplacian正則化によるクラスタリングに基づく事後処理を行い、予測を洗練させます。最後に、洗練された予測はノイズのあるモデルの再構築のためのターゲットとして使用されます。 |
結論
標準的な人工画像分類ベンチマークは、SFDA(Source-Free Domain Adaptation)手法の真の汎化性と頑健性についての私たちの理解を誤って制限してきました。私たちは、生物音響学からの自然発生的な分布シフトを取り入れた、範囲を広げた新しい評価フレームワークの採用を提唱しています。また、NOTELAが研究を促進するための堅牢なベースラインとなることを期待しています。NOTELAの強力なパフォーマンスは、より汎化性の高いモデルの開発につながる2つの要因を指摘しているかもしれません。第一に、より困難な問題に目を向けた手法の開発、第二に、単純なモデリング原則の優先化です。しかし、より困難な問題における既存の手法の失敗モードを特定し、理解するためには、今後の研究が必要です。私たちの研究は、より高い汎化性を持つSFDA手法の設計の基盤となる重要な一歩であると考えています。
謝辞
この投稿の著者の1人、Eleni Triantafillouは現在Google DeepMindに所属しています。このブログ投稿は、NOTELA論文の著者を代表して投稿しています:Malik Boudiaf、Tom Denton、Bart van Merriënboer、Vincent Dumoulin*、Eleni Triantafillou*(*は等しい貢献を示します)。この論文への共著者には、この論文への熱心な取り組みとPerchチーム全体からのサポートとフィードバックに感謝します。
1この音声クリップでは、鳥の鳴き声は非常にかすかです。これは、鳥の鳴き声が「前景」にない音景録音において一般的な特性です。 ↩︎
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






