「最も強力な機械学習モデルの解説(トランスフォーマー、CNN、RNN、GANなど)」
Explanation of the most powerful machine learning models (Transformer, CNN, RNN, GAN, etc.)

機械学習は非常に広範な分野であり、現在の最先端のモデルや技術について概要を提供する情報源を見つけることは理解できる限り困難です。とは言っても、この記事は各モデルの具体的な科学的分析ではなく、概念的な探求となります。実際には、可能であればそれぞれのモデルにもっと深く立ち入ることをお勧めします。また、これらのモデルがどのように使用されているかの例を提供したいと思っています。理論は常に実践と結びついているべきです。もし情報が抜けている場合は、フィードバックを提供して追加情報をリクエストしてください。
始める前に、カバーされるモデルのリストを以下に示します。
- CNN(畳み込みニューラルネットワーク)
- RNN(再帰型ニューラルネットワーク)
- トランスフォーマー
- GAN(敵対的生成ネットワーク)
CNN(畳み込みニューラルネットワーク)
CNN(畳み込みニューラルネットワーク)は、位相的なデータに非常に優れており、パターン検出において優れているように改良されています。では、それはどのように異なるのでしょうか?まず、ニューラルネットワークが一般的にどのようなものかについて簡単に概説しましょう。
- 「SelFeeに会いましょう:自己フィードバック生成によって強化された反復的自己修正LLM」
- 「岩石とAIの衝突:鉱物学とゼロショットコンピュータビジョンの交差点」
- 高度な言語モデルの世界における倫理とプライバシーの探求
ニューラルネットワークは、入力データを処理し出力を生成するノードの「マップ」です。これは、一連のノードを別の一連のノードにマッピングするレイヤーから構成され、入力を結果に伝播させ変換します。伝播は、各伝播ステップで入力を変更する重みによって行われます。各伝播ステップの後には、バイアスが適用されます。重みとバイアスが実際に求めているものです。これらは、ネットワークのトレーニング時に変更される数値です。

では、CNNはどう特別なのでしょうか?CNNの特徴は、畳み込みレイヤーを利用していることです。これは、他のタイプのレイヤーを持つことはできるが、畳み込みが特別になります。このレイヤーの動作方法について説明します。
画像の各ピクセルを輝度値と考えると、画像は数値の2次元行列になります。畳み込みは、この行列にカーネルを適用して出力行列を生成します。カーネルは、画像の各領域に対してフィルターのように機能する小さな行列です。
小さな行列が大きな行列の画像を「ステップ」して、出力行列を生成します。
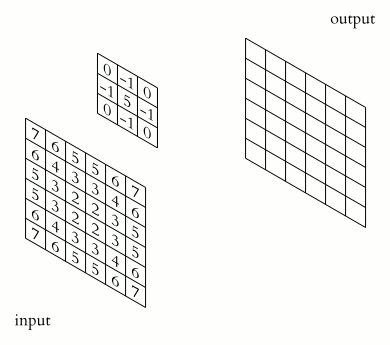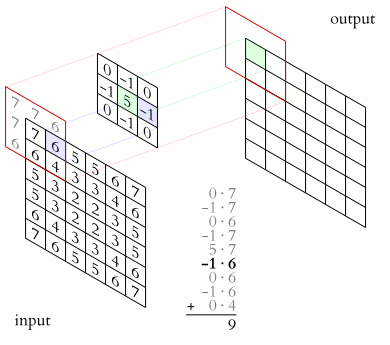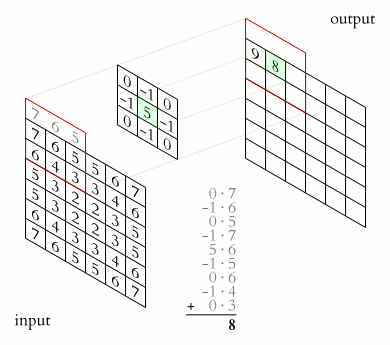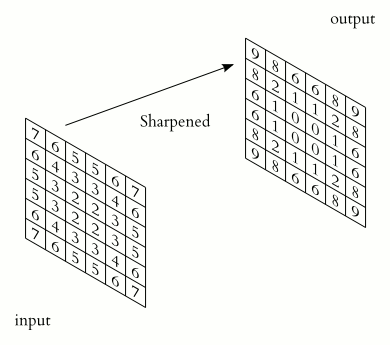
ここにはいくつかの重要なアイデアがあります。
- カーネルは、画像の各ピクセルとその周囲領域に適用されますが、領域内のパターンや特徴を検出するためには一定となります。
- カーネルは通常、画像自体よりもはるかに小さいため、トレーニングに非常に役立ちます。
- カーネルのアイデアは、任意の画像を分解できるパターンのセットであるということです。例えば、顔があるとしましょう。円を検出できるカーネルがあると仮定してください。その出力には、明るいスポットが2つ含まれています(検出した目)。次に、2つの線を近くに検出できる別のカーネルがあると仮定してください。出力には、明るいスポットが1つ含まれます(検出した口)。最後に、2つの円と下部の2つの線の形成を検出できる最終的なカーネルがあると仮定してください。その場合、顔を認識することができます。
- 畳み込みレイヤーでは、これらのカーネルを複数適用して複数の新しい画像を生成することができます。これらはスタックされてネットワーク内で前進させられます。次に、別の畳み込みレイヤーには別のセットのカーネルが適用されます。
- CNNには通常、画像サイズと複雑さを減らすためのプーリングレイヤーも含まれています。
明らかに、ここでは詳細や数学的な部分は省かれていますが、CNNの主な直感はカーネルにあります。
CNNを使用する一部の人気のあるツールや製品には、Googleフォト、DeepMindのAlphaGo、およびTeslaのAutopilotシステムがあります。
RNN
ご覧のように、CNNは主に画像処理に使用されます。一方、RNNは主にNLP(自然言語処理)や時系列解析などの他の領域に使用されます。RNNのアーキテクチャを理解するために、まず単純なニューラルネットワークをNLPに使用する際のいくつかの問題を強調しましょう。標準的なNLPの問題であるテキストオートコンプリートを見てみましょう。モデルへの入力はテキストであり、出力は別のテキストです。問題は、入力が可変サイズ(いくつかの単語または多くの単語)であることと、単純なニューラルネットワークには通常固定された入力サイズがあることです。もう1つの問題は、入力内の単語間の複雑な関係をキャプチャして正しい出力を生成することです。英語には何千もの単語があり、文中のこれらの単語の順序は必ずしも意味を変えません。では、「The fluffy cat came here on Sunday」と「On Sunday, the cat which was fluffy came here」という文が「The Sunday came here on a fluffy cat」とは異なることをどのように確認しますか?
RNNの直感は、情報がどのようにそれらを通過するかです。例として文を取り上げ、RNNがどのように処理するかを見てみましょう。「The cat eats」という文を取り上げましょう。
文を単語のシーケンスとして見てみましょう – 「The」、「cat」、「eats」(実際には数値またはベクトルのシーケンスとして表現される可能性があります)。RNNはこのシーケンスを順次処理します(これが名前の「Recurrent」の部分の由来です)。まず、単語「The」を受け取り、独自の重みとバイアスを通して「The」をパイプしていくことで、何らかの出力x1を生成します。次に、x1とシーケンスの次の単語 – 「cat」を受け取り、同じ重みとバイアスを通してパイプして、次の出力x2を取得します。そして、x2とシーケンスの次の単語 – 「eats」を受け取り、次の出力x3を取得します。このように、RNNは前の出力と次の入力を取り、新しい出力を生成します。RNNの現在の「状態」は隠れ状態と呼ばれます。ここには、Michael Phi氏が書いた素晴らしい記事からこの直感を構築するのに役立つアニメーションがあります。

これを使用して質問の次の単語を予測する方法はどうでしょうか?各出力 – x1、x2、x3が実際に新しい単語を表すと想像してください。出力が実際に次に来る単語の予測であるようにネットワークをトレーニングできます。したがって、もう一度私たちの文がどのように処理されるか見てみましょう。
「The」 -> モデルにパイプ -> x0を生成します。x0は正しく「cat」に外挿できるようにモデルをトレーニングします
「cat」と前の出力x0 -> モデルにパイプ -> x1を生成します。トレーニング後、x1は正しく「eats」に外挿できます
「eats」と前の出力x1 -> モデルにパイプ -> x2を生成します。x2は今、「tuna」という単語を表すことがわかりました!これを次の「入力」として使用できます
「tuna」と前の出力x2 -> モデルにパイプ -> x3を生成します… そして続きます
RNNの主な直感は、
- RNNは常にこの隠れ状態を介して以前に見られたものを追跡し、単語間の関係または他の順次データを捉えます。
- すべてのシーケンスの一部に同じモデルが繰り返し適用されるため、RNNはトレーニングが可能になります(一度に全体の入力を処理する巨大なモデルを持つのとは対照的です)
おそらくこのアプローチにはいくつかの問題があることが予想できるでしょう。テキストが長くなると、最初の数語は現在の隠れ状態にほとんど貢献しないため、理想的ではありません。さらに、この処理を逐次的に行わなければならないため、処理とトレーニングの速度はアルゴリズム自体に制限されます。
それでも、これらの強力なモデルにはさらに多くの要素がありますので、もっと深く探求することをお勧めします!
RNNを使用する一部の人気のあるツールや製品には、Google翻訳、OpenAIのGPT2、Spotifyの推薦システムなどがあります。
トランスフォーマー
トランスフォーマー!現在、機械学習の世界で話題沸騰です。GPT4やBERT(Google独自の高度な言語モデル)は、トランスフォーマーアーキテクチャに基づいています。では、それらは何なのでしょうか?
トランスフォーマーは、RNNと同様に自然言語処理の問題に主に使用されるため、以前に説明した言語処理に関連する類似の問題を解決する必要があります。ただし、いくつかのキーポイントがあり、これらはRNNとは異なる方法でこれらの問題を軽減します。
- 位置エンコーディング- RNNの隠れ状態を通じて言語のシーケンスの重要性は自然に保持されますが、トランスフォーマーではこの情報を入力に直接組み込みます。位置エンコーディングは単語の埋め込み(単語のベクトル表現)に追加され、文の中での各単語の位置が捉えられます。したがって、”犬”の表現はテキスト内の位置に基づいて変更されます。
- 巨大なトレーニングデータセットのサイズ- 位置エンコーディングの利点を活用するために、トランスフォーマーは巨大なデータセットでトレーニングする必要があります。これらの単語順序の違いはデータに取り込まれるため、順序や単語の種類に関するさまざまな可能性を見ないと、モデルは最適に機能しません。
- セルフアテンション- モデルは、入力の他のすべての単語との関係について、特定の単語により “重要” に “関心” を持つように学習します。何しろ、いくつかの単語は特に予測や翻訳において多くの意味と力を持ちます。これをどのように学習するのでしょうか?再び、それは巨大なトレーニングデータセットサイズとそのアーキテクチャによるものです。
ただし、トランスフォーマーのアーキテクチャは少し複雑で、このような短い記事で説明するのは難しいです。それでも、非常に高レベルなイメージを描こうと思います。トランスフォーマーはデコーダとエンコーダで構成されています。エンコーダは、テキストを処理し、テキストの最も重要な情報をキャプチャする役割を果たす同一の層のスタックで構成されています。デコーダの役割は、この入力を取り、同様のプロセスで同一の層のスタックを使用して、望む出力を生成することです。下記は、このアーキテクチャを示す図で、このトピックについて詳しく説明している素晴らしい記事(Ketan Doshiによる)へのリンクも含まれています。
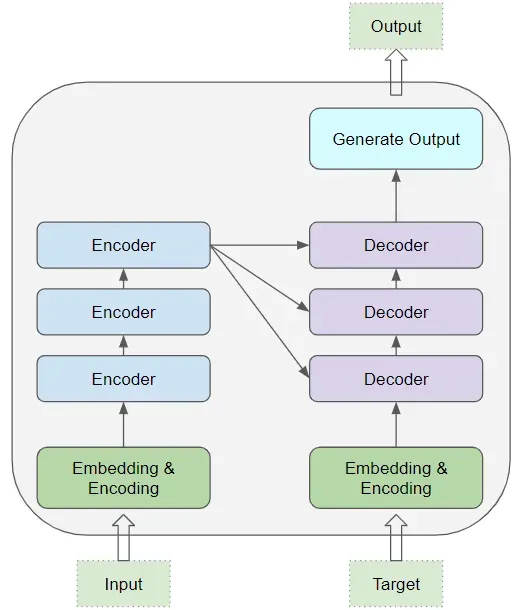
トランスフォーマーの背後にあるアーキテクチャは、しかし、少し複雑で説明が難しいです。それでも、私はあなたに非常に高レベルなイメージを描こうと思います。トランスフォーマーは、デコーダとエンコーダから構成されています。エンコーダは、テキストを処理し、テキストの最も重要な情報をキャプチャする役割を果たす同一の層のスタックで構成されています。デコーダの役割は、この入力を取り、同様のプロセスで同一の層のスタックを使用して、望む出力を生成することです。下図は、このアーキテクチャを示しています。このトピックについて詳しく説明している素晴らしい記事(Ketan Doshiによる)へのリンクも含まれています。
トランスフォーマーについて、特にトランスフォーマーの核心である “セルフアテンション” メカニズムについて、もっと深く掘り下げることを強くお勧めします。
GANs
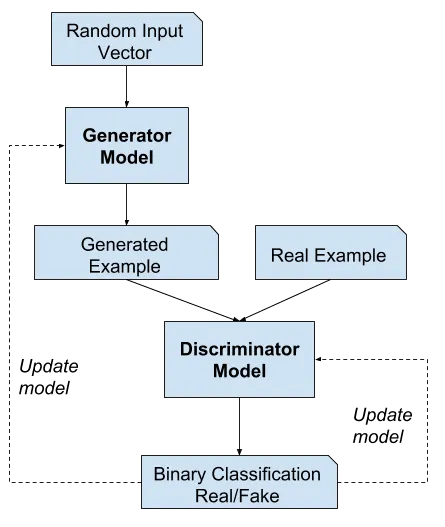
GAN(敵対的生成ネットワーク)は、お互いに競い合う2つの対立するモデルについての基本的な考え方です。GANは、モデル自体よりもこれらのモデルをトレーニングするための学習方法を指すことが最も一般的です。実際、2つのモデルのアーキテクチャは概念自体にとって特に重要ではありません。ただし、一方が生成的であり、もう一方が分類器である限りです。
例えば、画像を生成するジェネレータモデルを考えてみましょう。このモデルにいくつかの偽の画像を生成するように指示し、実際の画像も見つけます。次に、これらのすべての画像の組み合わせをディスクリミネータモデルにフィードし、それらを実際のものまたは偽物として分類します。ジェネレータモデルがうまくいけば、ディスクリミネータモデルは混乱し、半分の時間で正しい答えを出すでしょう。もちろん、最初はそうではない(通常、ディスクリミネータは少し事前トレーニングされています)ため、私たちは教師あり学習のように(私たち自身がどの画像が実際のものか偽物かを知っている)ディスクリミネータモデルを次回より良くするためにトレーニングします。私たちはまた、ジェネレータモデルをトレーニングすることもできます。それがどれほどうまくディスクリミネータモデルを騙せたかを知っています。トレーニングは、ディスクリミネータモデルを50%の確率で騙せる画像を生成できるようになるまで繰り返されます。
GANを現実世界で活用している一部の例には、Runway ML、Midjourney Art generation(アートに関する以前の記事をチェックしてください!)、およびOpenAIのDALL * Eがあります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「AIとML開発言語としてのPythonの利点」
- 「AIを活用した言語学習のためのパーソナルボイスボット」
- 「DenseDiffusionとの出会い:テキストから画像生成における密なキャプションとレイアウト操作に対処するためのトレーニング不要のAI技術」
- 「Amazon LexとAmazon Kendra、そして大規模な言語モデルを搭載したAWSソリューションのQnABotを使用して、セルフサービス型の質問応答を展開してください」
- 「クラスの不均衡:ランダムオーバーサンプリングからROSEへ」
- 深層学習フレームワークの比較
- 「IoT企業のインテリジェントビデオアナリティクスプラットフォームを搭載したAIがベンガルール空港に到着」





