レコメンダーシステムにおけるPrecision@NとRecall@Nの解説
'Explanation of Precision@N and Recall@N in Recommender Systems'.
レコメンダーの最適化:適合率と再現率の深い解釈のユースケース
議論の主なトピックは以下の通りです:
- 適合率と再現率の要点
- レコメンドのユースケースに適合率と再現率の定義を適用する
- バイナリな好みの変換の必要性
- 実用的な再現率の問題
- 実用的な再現率の解決策:トップNアイテム
- イラストによる実装例
- コードの実装
はじめに
精度メトリクスは、機械学習の全体的なパフォーマンスを評価するための有用な指標です。データセット内の正しく分類されたインスタンスの割合を表します。精度と組み合わせて評価メトリクスとして使用される適合率と再現率は、モデルのパフォーマンスをより包括的に理解するために使用されます。
一般的に、適合率と再現率は、テストセットの予測クラスと実際のクラスを比較し、正しい予測の割合を全予測数で計算します。
分類問題における適合率と再現率
教師あり分類問題では、対象値(y値)はバイナリである必要があります(ただし、分類問題はマルチバイナリの値に限定されません)。例えば、良性または悪性、良いまたは悪い、スパムまたはスパムではないなどです。これらのバイナリ値により、適合率と再現率を適用して、モデルが予測した値の正確さを測定することができます。
適合率は、正しく予測された陽性インスタンス(真陽性)の割合を、陽性と予測されたすべてのインスタンスで計算します

再現率は、データセット内の実際の陽性インスタンスのすべての正しく予測された陽性インスタンス(真陽性)の割合を計算します
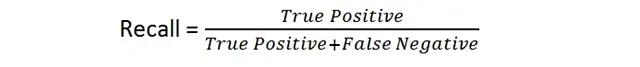
適合率と再現率の両方は、モデルのパフォーマンスについて補完的なインサイトを提供します。適合率は陽性の予測の正確性に焦点を当てていますが、再現率はすべての陽性インスタンスを見つけるモデルの能力に焦点を当てています。
レコメンデーションのユースケースに適合率と再現率の定義を適用する
レコメンダーモデルを構築する際、私たちの期待はモデルが正確なアイテムの推薦を提供できることです。分類の精度メトリクスは、データセット内の正しく予測されたインスタンスの割合を定量化することで、モデルのパフォーマンスを測定します。ただし、レコメンデーションシステムの文脈では、対象値が映画の1〜5つ星の評価などの評価尺度で表されることが一般的です。
したがって、適合率と再現率をレコメンデーションタスクで適切に使用するためには、評価尺度をバイナリな好みに変換する必要があります。これは、評価尺度を「関連する」アイテムと「関連しない」アイテムの区別に変換することによって一般的に達成されます。
バイナリな好みの変換の必要性
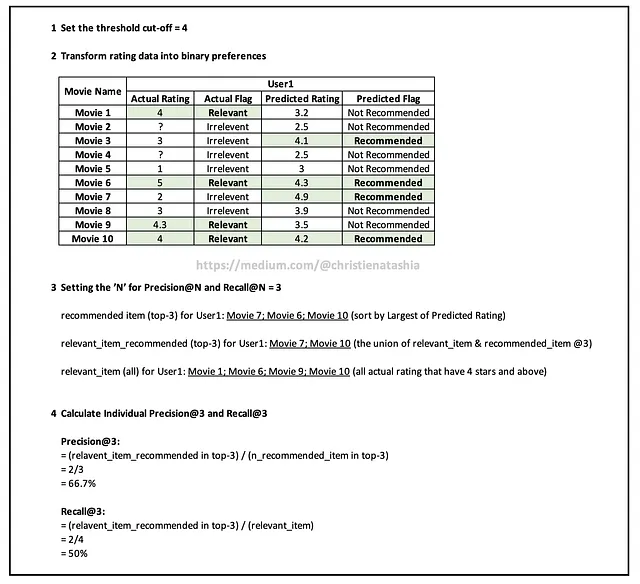
この段階では、明確なカットオフポイントを確立することが重要です。これを行うために、4以上の評価は関連アイテムとみなされ、4未満の評価は関連しないと見なされます(4のカットオフは私が選んだ閾値であり、値は各ユースケースの要件に応じて異なる場合があります)
この段階で、バイナリな好みに変換することで、適合率や再現率のような精度メトリクスがレコメンデーションシステムで実現可能になる理由を包括的に理解するのに役立つイラストです。

実用的な再現率の問題
ただし、この記事[1]によると、
リコメンドシステムでリコールを測定することはほとんど実用的ではありません。厳密には、リコールを測定するには各アイテムが関連しているかどうかを知る必要があります。例えば、映画のリコメンダーの場合、5000本の映画(映画データベース内)をすべてのユーザーに視聴してもらい、各ユーザーに対してどれくらい成功してリコメンドできたかを測定する必要があります。- Herlocker et al.(2004)
上記の文を簡単にするために、例えばNetflixのような映画プラットフォームがすべてのユーザーに5000本の映画を視聴するように要求することは不可能です。各ユーザーが評価したアイテムの数とデータセット全体のアイテム数との間には著しい差があるため、リコール率も比較的低くなります。
したがって、上記の文の解決策は、ユーザーに対して上位5つまたは上位10の映画リストを推奨することに焦点を当てるべきです。データベース内のすべての利用可能な映画を各ユーザーに提案することは、実用的でも実現可能でもありません。
実用的なリコールの解決策:Top-Nアイテム
これが、Top-Nアイテムがリコメンドシステムの精度とリコールの指標を適切に活用する方法です。これによって、ユーザーが評価を付ける上位Nのアイテムを予測することができます。ここで、Nは上位Nのリコメンデーションの目的に対応する整数です。
これは、データセットをトレーニングセットとテストセットに分割することで行うことができます。トレーニングセットはアルゴリズムのトレーニングに使用され、次のステップではテストセットを使用して上位Nのアイテムの予測を行います。このために、precision@Nおよびrecall@Nの指標が使用されます。このアプローチにより、ユーザーに最も関連性の高いアイテムを推奨するシステムのパフォーマンスをより関連性の高い評価と正確に評価することができます。
Precision@N:上位Nの推奨されたアイテムのうち、ユーザーに関連するものがいくつあるか。precision@10の80%とは、モデルが提供された10本の推奨映画のうち、実際にユーザーが好むのは8本です。
Precision = (上位Nの推奨された関連アイテム) / (推奨アイテム数)
Recall@K:データセット内の関連アイテムのうち、上位Nの推奨アイテムに含まれているものはいくつか。recall@10の60%とは、関連アイテムの総数の60%が上位Nの結果に表示されていることを意味します。
Recall = (上位Nの推奨された関連アイテム) / (関連アイテム数)
この段階で、関連アイテムと推奨アイテムの定義(4つ星がカットオフとして設定されているという仮定のもと)を理解していただければと思います。

具体的な実装
前述のように、必要なステップは次のとおりです:
- 閾値のカットオフを設定する(4つ星がカットオフと設定されている場合、4つ星以上の評価は関連アイテムと見なされ、4つ星未満の評価は関連しないと見なされます。リコメンド/非リコメンドも同様)
- 評価データをバイナリの好みに変換する
- Precision@NおよびRecall@Nのための「N」を設定する
- 個別のPrecision@NおよびRecall@Nを計算する
コードの実装
ゼロからリコメンデーションシステムを構築したい場合は、以前の記事を参照してリコメンダーシステムの数学的な概念を理解することができます。ただし、リコメンデーションタスクに精通している場合は、この部分をスキップしてもかまいません。
行列分解を用いたリコメンデーションシステム
Matrix Factorizationの背後にある概念とPythonでの実践的な実装
towardsdatascience.com
daaaのコードに戻ります!!
以下は、Precision@NとRecall@Nを計算するためのPythonのスニペットです。さらに、ここでノートブック全体にアクセスできます。
出力は次のようになります:

ここでのRecall値は、モデルによって推奨された「関連するアイテム」と「各ユーザが評価したアイテムの数」との間の差が非常に大きいため、比較的低い場合があります(0に近い低いRecallに対抗するために、ユーザがかなりの数の評価を行ったデータセットに参加することもできます)。
さらに、推薦システムにおけるRecallに関する重要な注釈について、Herlocker et al.(2004)[1]の結果にも述べたいと思います:
recall@Nメトリックは同じデータセット上での比較的な使用にのみ使用するべきであり、絶対的な尺度として解釈されるべきではありません。
概要
Precision@NおよびRecall@Nの包括的な解釈についての執筆をまとめました。さらに、私の研究に大きく貢献した価値ある論文や記事のリストを参考文献セクションに提供しました。
参考文献
[1] J.L. Herlocker, J.A. Konstan, L.G. Terveen, J.T. Riedl, Evaluating collaborative filtering recommender systems, ACM Trans Inform Syst, 22 (1) (2004), pp. 5–53. アクセスはこちら:https://grouplens.org/site-content/uploads/evaluating-TOIS-20041.pdf
Matrix Factorizationによる推薦システム
Matrix Factorizationの背後にある概念とPythonでの実践的な実装
towardsdatascience.com
Precision-N-and-Recall-N-Recommender-System/Precision_and_Recall_of_Recomender_Systems_Final.ipynb…
推薦システムにおけるPrecision@NとRecall@N。Contribute to…
github.com
FAQ – Surprise 1 documentation
ここには、よくある質問と、他のユースケースの例が含まれています…
surprise.readthedocs.io
推薦システムにおけるkにおけるRecallとPrecision
詳しい説明と例
VoAGI.com
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
