「グラフ注意ネットワーク論文のイラストとPyTorchによる実装の説明」
Explanation of graph attention network paper illustration and PyTorch implementation
ヴェリチコビッチらによる「グラフ注意ネットワーク」論文の詳細でイラスト付きのウォークスルーと、提案モデルのPyTorch実装
はじめに
グラフニューラルネットワーク(GNN)は、グラフ構造データ上で動作する強力なニューラルネットワークの一種です。GNNは、ノードのローカルな近傍から情報を集約することでノードの表現(埋め込み)を学習します。この概念は、グラフ表現学習の文献では「メッセージパッシング」として知られています。
メッセージ(埋め込み)は、GNNの複数のレイヤーを通じてグラフ内のノード間で渡されます。各ノードは、その近傍のノードからのメッセージを集約し、自身の表現を更新します。このプロセスはレイヤーごとに繰り返され、ノードはグラフに関するより豊かな情報をエンコードした表現を獲得することができます。GNNの重要なバリアントには、GraphSAGE [2]、Graph Convolution Network [3]などがあります。ここでさらにGNNのバリアントを探索することができます。

グラフ注意ネットワーク(GAT) [1]は、このメッセージパッシングの方法を改善するために提案された特別なGNNの一種です。彼らは学習可能な注意機構を導入し、ノードがローカル近傍からのメッセージを集約する際に、各ソースノードとターゲットノードの間に重みを割り当てることにより、どの近傍ノードがより重要かを決定することができます。
実証的に、グラフ注意ネットワークは、ノード分類、リンク予測、グラフ分類などのタスクにおいて、他の多くのGNNモデルよりも優れたパフォーマンスを示すことが示されています。彼らはいくつかのベンチマークグラフデータセットで最先端のパフォーマンスを実証しました。
- 「AIの力を解き放つ – VoAGIとMachine Learning Masteryによる特別リリース」
- 「DreamPose」というAIフレームワークを使用して、ファッション画像を見事な写真のようなビデオに変換します
- 遺伝的アルゴリズムを使用したPythonによるTV番組スケジューリングの最適化
この記事では、Veličkovićらによるオリジナルの「グラフ注意ネットワーク」論文の重要な部分を解説し、同時にGATメソッドの直感をより理解するために、PyTorchフレームワークを使用して論文で提案された概念を実装していきます。
また、この記事で使用されるトレーニングと検証のコードを含む完全なコードは、このGitHubリポジトリでアクセスすることもできます
論文の内容
セクション1 — はじめに
セクション1「はじめに」では、グラフ表現学習の文献における既存の手法を広く見直した後、グラフ注意ネットワーク(GAT)が紹介されます。著者は以下のことを言及しています:
- 組み込まれた注意機構の全体像。
- GATの3つの特性、すなわち効率的な計算、すべてのノードへの一般的な適用可能性、および帰納的学習への利用可能性。
- GATのパフォーマンスを評価したベンチマークとデータセット。

その後、彼らは自身のアプローチをいくつかの既存の手法と比較し、一般的な類似点と相違点を述べた後、論文の次のセクションに進みます。
セクション2 — GATのアーキテクチャ
本セクションでは、論文の主要な部分であるグラフ注意ネットワークのアーキテクチャが詳細に説明されています。説明を進めるために、提案されたアーキテクチャがN個のノード(V = {vᵢ}; i=1,…,N)を持つグラフ上で動作し、各ノードがF要素のベクトルhᵢで表され、ノード間に任意の設定のエッジが存在すると仮定します。

著者はまず、単一のグラフ注意層(Graph Attention Layer)とその動作方法を特徴付け、それがグラフ注意ネットワークの構成要素となることを示します。一般的に、単一のGAT層は、与えられたノード埋め込み(表現)を持つグラフを入力として受け取り、情報をローカルな隣接ノードに伝播し、ノードの更新された表現を出力することが期待されています。

上記のように、これを行うためにまず、すべての入力ノード特徴ベクトル(hᵢ)がGA層に線形変換される(つまり、重み行列Wによって乗算)ことを述べています。PyTorchでは、通常、次のように行われます:
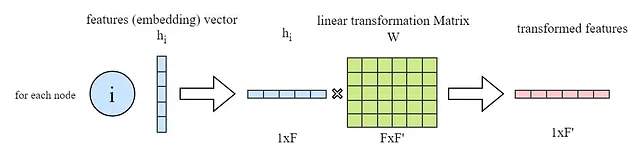
import torchfrom torch import nn# in_features -> F and out_feature -> F'in_features = ...out_feature = ...# 学習可能な重み行列W(FxF')をインスタンス化W = nn.Parameter(torch.empty(size=(in_features, out_feature)))# 重み行列Wを初期化nn.init.xavier_normal_(W)# Wとhを乗算(hはすべてのノードの入力特徴量 -> NxF行列)h_transformed = torch.mm(h, W)ここで、入力ノード特徴(埋め込み)の変換バージョンを取得したことを念頭に置いて、GAT層における最終的な目標を観察し理解します。
論文によれば、グラフ注意層の最後で、各ノードiについて、その近傍からより構造的かつコンテキストに対応した新しい特徴ベクトルを取得する必要があります。
これは、隣接ノードの特徴量の重み付き和を計算し、非線形活性化関数σに続けて適用することによって行われます。この重み付き和は、一般的なGNN層操作における「集約ステップ」としても知られています。
これらの重みαᵢⱼ ∈ [0, 1]は学習され、メッセージパッシングと集約の過程でノードiにとって隣接ノードjの特徴の重要性を示す注意機構によって計算されます。


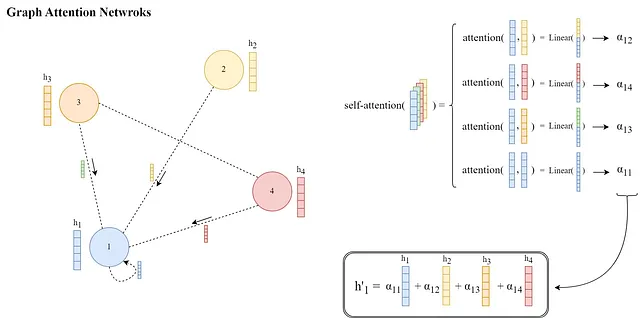
では、各ノードiとその隣接ノードjのペアごとにこれらの注意重みαᵢⱼがどのように計算されるか見てみましょう:
要するに、注意重みαᵢⱼは以下のように計算されます
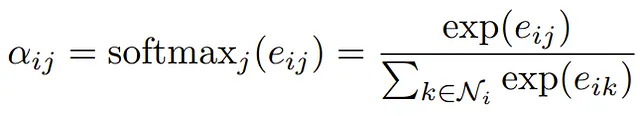
ここで、eᵢⱼは注意スコアであり、Softmax関数が適用されるため、すべての重みは[0, 1]の範囲にあり、合計が1になります。
注目スコアeᵢⱼは、各ノードiとその隣接ノードj ∈ Nᵢの間で注目関数a(…)を用いて計算されます:

ここで、||は2つの変換されたノード埋め込みの連結を示し、aは学習可能なパラメータ(つまり、変換された埋め込みのサイズの2倍)である注意パラメータのベクトルです。
そして、(aᵀ)はベクトルaの転置であり、変換された埋め込みの連結との内積を表すaᵀ [Whᵢ|| Whⱼ]は、「a」と変換された埋め込みの連結との間のドット積となります。
全体の操作は以下の通りです:

PyTorchでは、これらのスコアを得るためにやや異なるアプローチを取ります。ノードの全ての組み合わせに対してeᵢⱼを計算し、ノード間の既存のエッジを表すもののみを選択する方が効率的です。全てのeᵢⱼを計算するためには:
# 学習可能な注意パラメータベクトル `a`を生成a = nn.Parameter(torch.empty(size=(2 * out_feature, 1)))# パラメータベクトル `a`を初期化nn.init.xavier_normal_(a)# 先ほどのコードスニペットで `h_transformed` を取得したとする# 全てのノード埋め込みのドット積を計算し、注意ベクトルパラメータの前半(隣接ノードのメッセージに対応する部分)を使用してスコアを求めるsource_scores = torch.matmul(h_transformed, self.a[:out_feature, :])# 全てのノード埋め込みのドット積を計算し、注意ベクトルパラメータの後半(ターゲットノードに対応する部分)を使用してスコアを求めるtarget_scores = torch.matmul(h_transformed, self.a[out_feature:, :])# ブロードキャスト加算e = source_scores + target_scores.Te = self.leakyrelu(e)コードスニペットの最後の部分(# ブロードキャスト加算)は、1対1のソースとターゲットのスコアを全て加算し、eᵢⱼスコアを含むNxN行列を生成します(以下に示します)。

ここまで、グラフが完全に接続されていると仮定し、全ての可能なノードの組み合わせの注目スコアを計算しました。これに対応するため、LeakyReLU活性化関数が注目スコアに適用された後、注目スコアはグラフ内の既存のエッジに基づいてマスクされます。つまり、存在するエッジに対応するスコアのみを保持します。
これは、グラフの隣接行列を使用して実現することができます。隣接行列は、行iと列jにエッジが存在する場合は1であり、それ以外は0であるNxN行列です。したがって、マスクを作成するために、隣接行列の0要素に-∞を割り当て、それ以外の要素に0を割り当てます。そして、マスクをスコア行列に追加し、その行ごとにsoftmax関数を適用します。
connectivity_mask = -9e16 * torch.ones_like(e)# adj_mat is the N by N adjacency matrixe = torch.where(adj_mat > 0, e, connectivity_mask) # マスクされた注意スコア # 注意係数は行ごとにsoftmaxで計算される# attention scores matrix eの各列jについてsoftmaxを計算attention = F.softmax(e, dim=-1)最後に、論文によると、注意スコアを取得し既存のエッジでマスクし、注意重みαᵢⱼを取得するために、スコア行列の各行に対してsoftmaxを実行します。
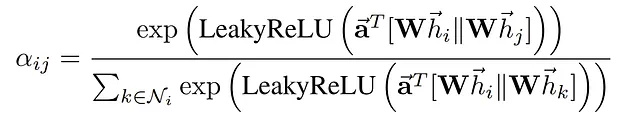
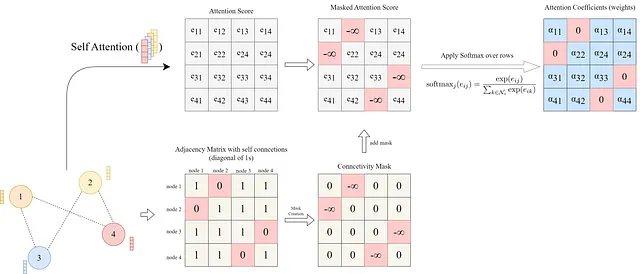
そして、前述のように、ノードの埋め込みの重み付き和を計算します:
# 最終的なノードの埋め込みは、隣接ノードの特徴の重み付き平均として計算されるh_prime = torch.matmul(attention, h_transformed)最後に、論文ではマルチヘッドアテンションという概念が導入されており、すべての操作を複数の並列ストリームで行い、最終結果のヘッドを平均化または連結することができます。

マルチヘッドアテンションと集約プロセスは以下のように示されています:
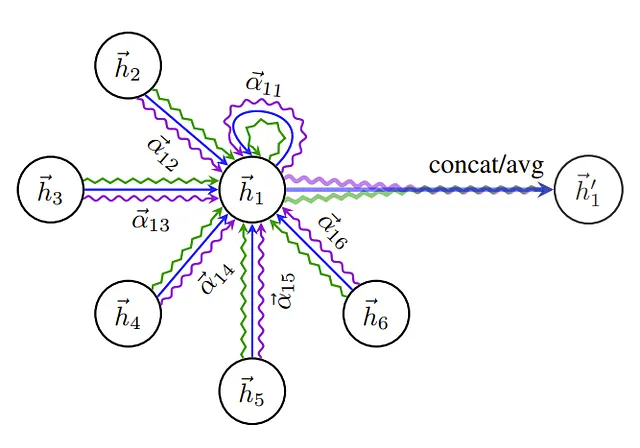
実装をより整理されたモジュラー形式(PyTorchモジュールとして)でまとめ、マルチヘッドアテンション機能を組み込むために、Graph Attention Layerの実装全体は以下のように行われます:
import torchfrom torch import nnimport torch.nn.functional as F################################### GAT LAYER DEFINITION ###################################class GraphAttentionLayer(nn.Module): def __init__(self, in_features: int, out_features: int, n_heads: int, concat: bool = False, dropout: float = 0.4, leaky_relu_slope: float = 0.2): super(GraphAttentionLayer, self).__init__() self.n_heads = n_heads # 注意ヘッドの数 self.concat = concat # 最終的な注意ヘッドを連結するかどうか self.dropout = dropout # ドロップアウト率 if concat: # 注意ヘッドを連結する場合 self.out_features = out_features # ノードごとの出力特徴数 assert out_features % n_heads == 0 # out_featuresがn_headsの倍数であることを確認する self.n_hidden = out_features // n_heads else: # 注意ヘッドごとに出力を平均化する(メインの論文で使用) self.n_hidden = out_features # 各ノードに適用される共有線形変換、重み行列Wによってパラメータ化される # 重み行列Wを初期化する self.W = nn.Parameter(torch.empty(size=(in_features, self.n_hidden * n_heads))) # 注意重みaを初期化する self.a = nn.Parameter(torch.empty(size=(n_heads, 2 * self.n_hidden, 1))) self.leakyrelu = nn.LeakyReLU(leaky_relu_slope) # LeakyReLU活性化関数 self.softmax = nn.Softmax(dim=1) # 注意係数のsoftmax活性化関数 self.reset_parameters() # パラメータをリセットする def reset_parameters(self): nn.init.xavier_normal_(self.W) nn.init.xavier_normal_(self.a) def _get_attention_scores(self, h_transformed: torch.Tensor): source_scores = torch.matmul(h_transformed, self.a[:, :self.n_hidden, :]) target_scores = torch.matmul(h_transformed, self.a[:, self.n_hidden:, :]) # ブロードキャスト加算 # (n_heads, n_nodes, 1) + (n_heads, 1, n_nodes) = (n_heads, n_nodes, n_nodes) e = source_scores + target_scores.mT return self.leakyrelu(e) def forward(self, h: torch.Tensor, adj_mat: torch.Tensor): n_nodes = h.shape[0] # ノードの特徴に線形変換を適用する -> W h # 出力形状 (n_nodes, n_hidden * n_heads) h_transformed = torch.mm(h, self.W) h_transformed = F.dropout(h_transformed, self.dropout, training=self.training) # テンソルを再形成し、ヘッドの次元を最初に配置してヘッドを分割する # 出力形状 (n_heads, n_nodes, n_hidden) h_transformed = h_transformed.view(n_nodes, self.n_heads, self.n_hidden).permute(1, 0, 2) # 注意スコアを取得する # 出力形状 (n_heads, n_nodes, n_nodes) e = self._get_attention_scores(h_transformed) # 存在しないエッジの注意スコアを-9e15に設定する(エッジのマスキング) connectivity_mask = -9e16 * torch.ones_like(e) e = torch.where(adj_mat > 0, e, connectivity_mask) # マスクされた注意スコア # 注意係数は行ごとにsoftmaxで計算される # attention score matrix eの各列jについて attention = F.softmax(e, dim=-1) attention = F.dropout(attention, self.dropout, training=self.training) # 最終的なノードの埋め込みは、隣接ノードの特徴の重み付き平均として計算される h_prime = torch.matmul(attention, h_transformed) # 注意ヘッドの連結/平均化 # 出力形状 (n_nodes, out_features) if self.concat: h_prime = h_prime.permute(1, 0, 2).contiguous().view(n_nodes, self.out_features) else: h_prime = h_prime.mean(dim=0) return h_prime次に、著者はGAT(Graph Attention Networks)と他の既存のGNN(Graph Neural Network)の手法/アーキテクチャの比較を行います。彼らは次のように主張しています:
- GATは、注意重みを計算しローカル集約を並列に実行できるため、一部の既存の手法よりも計算効率が高いです。
- GATは、メッセージの集約中にノードの近傍に異なる重要性を割り当てることができます。これにより、モデルの容量が向上し、解釈性が高まります。
- GATは、ノードの完全な近傍を考慮します(近隣からのサンプリングは必要ありません)し、ノード内の順序は仮定しません。
- GATは、疑似座標関数をu(x, y) = f(x)||f(y)(ここで、f(x)はノードxの(MLPで変換された可能性のある)特徴を表し、||は連結を意味します)に設定し、重み関数をwj(u) = softmax(MLP(u))に設定することで、MoNet(Monti et al.、2016)の特定のインスタンスとして再定式化できます。
セクション3 — 評価
論文の第3セクションでは、まず、GATが評価されるベンチマーク、データセット、およびタスクについて説明しています。その後、モデルの評価結果を提示しています。
推移学習 vs. 帰納学習この論文でベンチマークとして使用されるデータセットは、推移学習と帰納学習の2つのタスクのタイプに分けられます。
- 帰納学習:これは、モデルがラベル付きのトレーニング例のセットのみで訓練され、トレーニング中に完全に観測されなかった例に対してモデルが評価およびテストされる監視付き学習タスクの一種です。一般的な監視付き学習として知られています。
- 推移学習:このタイプのタスクでは、トレーニング、検証、およびテストのインスタンスを含むすべてのデータがトレーニング中に使用されます。ただし、各フェーズでは、モデルによって対応するセットのラベルのみがアクセスされます。つまり、トレーニング中、モデルはトレーニングインスタンスとラベルから生じる損失のみを使用して訓練されますが、テストおよび検証の特徴はメッセージパッシングに使用されます。これは、例に存在する構造的およびコンテキスト情報のためです。
データセット論文では、GATの評価のために4つのベンチマークデータセットが使用されており、そのうち3つは推移学習に対応し、もう1つは帰納学習のタスクに使用されます。
推移学習のデータセットであるCora、Citeseer、およびPubmed(Sen et al.、2008)データセットは、ノードが公開ドキュメントであり、エッジ(接続)がそれらの間の引用である引用グラフです。ノードの特徴は、ドキュメントの袋の単語表現の要素です。帰納学習のデータセットは、異なる人間の組織(Zitnik & Leskovec、2017)のグラフを含むタンパク質間相互作用(PPI)データセットです。データセットの詳細は以下に示します:
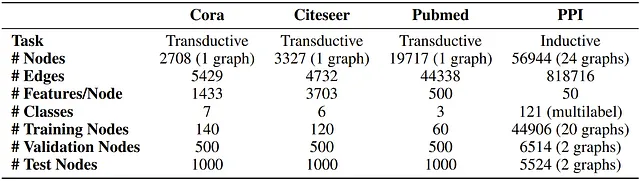
セットアップと結果
- 3つの推移学習タスクに対して、トレーニングに使用される設定は次のとおりです:2つのGATレイヤー —レイヤー1は- K = 8注意ヘッド- F’ = 8ヘッドごとの出力特徴次元- ELU活性化関数および2番目のレイヤー[Cora&Citeseer | Pubmed]用に- [1 | 8]注意ヘッドとCクラス出力次元- 分類確率出力のためのSoftmax活性化関数および全体のネットワークには- p = 0.6のDropout– λ = [0.0005 | 0.001]のL2正則化が使用されます。
- 3つの推移学習タスクに対して、トレーニングに使用される設定は次のとおりです:3つのレイヤー — – レイヤー1と2:K = 4 | F’ = 256 | ELU – レイヤー3:K = 6 | F’ = Cクラス | シグモイド(マルチラベル)正則化とドロップアウトはありません
以下に、PyTorchを使用した最初の設定の実装が示されています。これは、前に定義したレイヤーを使用して行われます:
class GAT(nn.Module): def __init__(self, in_features, n_hidden, n_heads, num_classes, concat=False, dropout=0.4, leaky_relu_slope=0.2): super(GAT, self).__init__() # グラフ注意層を定義する self.gat1 = GraphAttentionLayer( in_features=in_features, out_features=n_hidden, n_heads=n_heads, concat=concat, dropout=dropout, leaky_relu_slope=leaky_relu_slope ) self.gat2 = GraphAttentionLayer( in_features=n_hidden, out_features=num_classes, n_heads=1, concat=False, dropout=dropout, leaky_relu_slope=leaky_relu_slope ) def forward(self, input_tensor: torch.Tensor , adj_mat: torch.Tensor): # 最初のグラフ注意層を適用する x = self.gat1(input_tensor, adj_mat) x = F.elu(x) # 最初の層の出力にELU活性化関数を適用する # 2番目のグラフ注意層を適用する x = self.gat2(x, adj_mat) return F.softmax(x, dim=1) # softmax活性化関数を適用するテストの結果、著者はGATと既存のGNN手法との比較可能な結果を示す4つのベンチマークについて、次のパフォーマンスを報告しています。

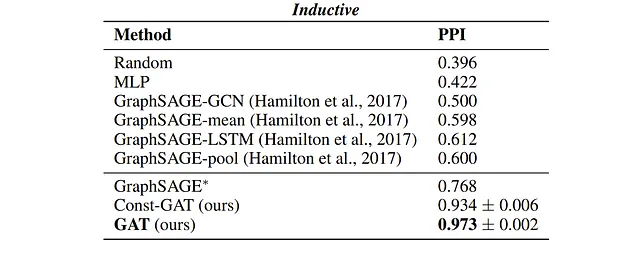
結論
まとめると、このブログ投稿では、Veličkovićらによる「Graph Attention Networks」論文を、イラストを使ってメインのアイデアや複雑なグラフ構造データ(例:ソーシャルネットワークや分子)との作業でなぜ重要なのかを理解するのに役立つ詳細でわかりやすいアプローチで説明しました。さらに、この投稿には、人気のあるプログラミングフレームワークであるPyTorchを使用したモデルの実用的な実装も含まれています。ブログ投稿を読みながらコードを試していただくことで、GATの動作方法や実世界のシナリオでの適用方法について、しっかりと理解していただけることを願っています。この投稿が役に立ち、研究の興味深い分野をさらに探求することに対して励みになれば幸いです。
さらに、この投稿で使用されたトレーニングとバリデーションのコードを含む完全なコードには、このGitHubリポジトリでアクセスできます。
投稿に関するご意見やご提案・変更点など、お聞かせいただければ幸いです。
参考文献
[1] — Graph Attention Networks (2017), Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, Yoshua Bengio. arXiv:1710.10903v3
[2] — Inductive Representation Learning on Large Graphs (2017), William L. Hamilton, Rex Ying, Jure Leskovec. arXiv:1706.02216v4
[3] — Semi-Supervised Classification with Graph Convolutional Networks (2016), Thomas N. Kipf, Max Welling. arXiv:1609.02907v4
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「MACTAに会いましょう:キャッシュタイミング攻撃と検出のためのオープンソースのマルチエージェント強化学習手法」
- 「クラスタリング解放:K-Meansクラスタリングの理解」
- 「夢を先に見て、後で学ぶ:DECKARDは強化学習(RL)エージェントのトレーニングにLLMsを使用するAIアプローチです」
- 「トランスフォーマベースのLLMがパラメータから知識を抽出する方法」
- 「TR0Nに会ってください:事前学習済み生成モデルに任意のコンディショニングを追加するためのシンプルで効率的な方法」
- 「合成キャプションはマルチモーダルトレーニングに役立つのか?このAI論文は、合成キャプションがマルチモーダルトレーニングにおけるキャプションの品質向上に効果的であることを示しています」
- 「もしも、視覚のみのモデルを、わずかな未ラベル化画像を使って線形層のみを訓練することで、ビジョン言語モデル(VLM)に変換できたらどうでしょうか? テキストから概念へ(そしてその逆)のクロスモデルアラインメントによる、Text-to-Conceptの紹介」






