「視覚化された実装と共に、Graph Attention Network(GAT)の解説」
Explanation of Graph Attention Network (GAT) with visual implementation
グラフニューラルネットワーク(GNN)の理解は、変換器がグラフ問題(Open Graph Benchmarkからのものを含む)に取り組み続けるにつれ、ますます重要になってきています。自然言語だけでグラフが必要な場合でも、GNNは将来の手法の有望なインスピレーションの源となります。
この記事では、まずバニラのGNNレイヤーの実装を紹介し、次にICLR論文「Graph Attention Networks」で説明されているバニラのグラフアテンションレイヤーの修正を示します。

まず、テキストドキュメントのグラフを有向非循環グラフ(DAG)として表現したものを想像してください。ドキュメント0はドキュメント1、2、および3へのエッジを持っているため、それらの列には0行目に1があります。
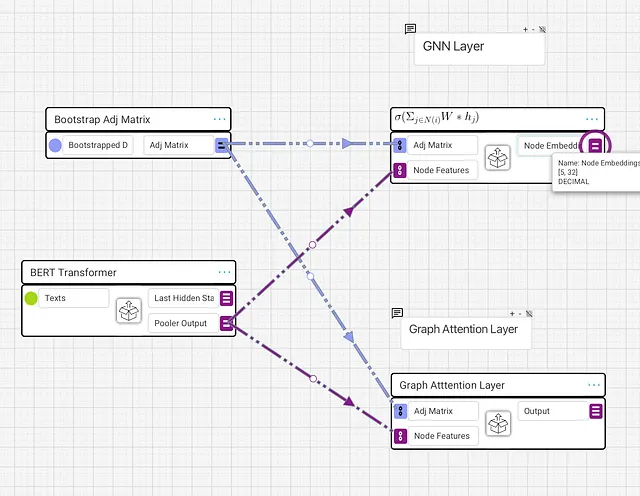
可視化された実装を行うために、ビジュアルAIモデリングツールであるGraphbookを使用します。Graphbookでのビジュアル表現の理解方法については、私の他の記事をご覧ください。

また、各ドキュメントにはいくつかのノード特徴があります。私は各ドキュメントをBERTに単一の[5]次元のテキストの1次元配列として入力し、プーラー出力で[5, 768]の埋め込み形状を生成しました。

教育目的のために、BERTの出力の最初の8次元だけをノード特徴として取得し、データの形状をより簡単に追うことができるようにします。これで、隣接行列とノード特徴が揃いました。

GNNレイヤー
GNNレイヤーの一般的な式は、各ノードについて、各ノードの隣接ノードを取り、特徴量に重み行列を掛けて加算し、その後に活性化関数を通すというものです。私はこの式をタイトルとして持つ空のブロックを作成し、その式をブロックの内部で実装します。

この式を実装する際には、実際にループを実行したくありません。これを完全にベクトル化できれば、GPUを使用したトレーニングと推論は計算ステップが単一になるため、はるかに高速になります。そのため、ノード特徴を3D形状にタイル(つまりブロードキャスト)して、元々のノード特徴の[5, 8]形状から[5, 5, 8]形状に変換します。最後の次元を「隣接ノード」の特徴と考えることができます。各ノードには5つの可能な隣接ノードがあります。

ノード特徴を[5, 8]から[5, 5, 8]の形状に直接ブロードキャストすることはできません。代わりに、まず[25, 8]にブロードキャストする必要があります。ブロードキャストする際には、形状の各次元は元の次元以上である必要があります。そのため、形状の5と8の部分を取得して、最初の部分を25倍に乗じ、すべてを結合します。最後に、結果の[25, 8]を[5, 5, 8]に戻し、Graphbookで最終的な2つの次元の各ノード特徴が同一であることを確認できます。

次に、隣接行列を同じ形にブロードキャストしたいです。これは、行iと列jの隣接行列の各1に対して、次元[i, j]にnum_feats個の1.0がある行があるということです。つまり、この隣接行列では、0行目には1つ目、2つ目、および3つ目の列に1がありますので、0番目のセル(つまり、[0, 1:3, :])にはnum_feats個の1.0が1行、2行、および3行にあります。

ここでは実装は非常にシンプルです。隣接行列を10進数に解析して、[5, 5]の形状から[5, 5, 8]の形状にブロードキャストします。これで、この隣接行列のマスクとタイル化されたノードの隣接機能を要素ごとに乗算できます。

また、隣接行列に自己ループも追加したいです。これにより、隣接機能を合計する際に、そのノード自体のノード機能も含まれます。

要素ごとの乗算(および自己ループの追加)を行うと、各ノードの隣接機能とエッジで接続されていないノード(隣接していないノード)のためのゼロが得られます。0番目のノードには、0から3のノードの機能が含まれます。3番目のノードには、3番目と4番目のノードが含まれます。

次に、[25, 8]の形状に変形し、それを所望の隠れサイズを持つパラメータ化された線形層を通過させます。ここでは、32という値を選び、グローバル定数として保存して再利用できるようにしました。線形層の出力は[25, hidden_size]になります。単純にその出力を再形成し、[5, 5, hidden_size]の形状を作成し、これでついに式の総和部分に移行できます!

ノードごとの隣接機能を合計するために、中間次元(次元インデックス1)に合計を行います。その結果は、1層を通過した[5, hidden_size]のノード埋め込みのセットです。これらの層を単純に連結させると、GNNネットワークが得られ、トレーニング方法についてはhttps://www.youtube.com/@Graphbookのガイドに従います。
グラフ注意層

論文からわかるように、グラフ注意層の秘密の要素は、上記の式で与えられる注意係数です。基本的に、エッジ内にあるノードの埋め込みを連結し、別の線形層を通過させてからソフトマックスを適用します。

これらの注意係数は、元のノード機能に対応する機能の線形結合を計算するために使用されます。

する必要があるのは、各ノードの機能を各隣接ノードにタイル化し、それをノードの隣接機能と連結することです。

秘密のソースは、各隣人ごとにノードの特徴をタイル状にすることです。そのために、マスク前にタイル化されたノードの特徴の0次元と1次元を入れ替えます。

結果は依然として[5, 5, 8]の形状の配列ですが、[i, :, :]の各行が同じであり、ノードiの特徴に対応しています。これで、要素ごとの乗算を使用して、隣人を含む場合にのみノードの特徴を繰り返し作成できます。最後に、GNNのために作成した隣人の特徴と連結して、連結された特徴を生成します。

あと少しです!連結された特徴があるので、これらを線形層に通すことができます。[5, 5, hidden_size]に戻して、中間次元でソフトマックスを実行して注意係数を生成します。

これで、[5, 5, hidden_size]の形状を持つ注意係数が得られました。これは、nノードグラフごとにグラフのエッジごとに1つの埋め込みを表します。論文では、これらを転置(寸法を交換)する必要があると言っているので、それを行い、ReLUの前に最後の次元でソフトマックスを実行して、hidden_size次元に沿って次元インデックスごとに正規化されるようにしています。これらの係数を元のノード埋め込みと乗算します。元のノード埋め込みは、[5, 5, 8]の形状であり、8はテキストドキュメントのBERTエンコーディングから最初の8つの特徴をスライスしたものです。
[5, hidden_size, 5]の形状と[5, 5, 8]の形状を乗算すると、[5, hidden_size, 8]の形状が得られます。その後、hidden_size次元を足し合わせて、最終的な出力の形状である[5, 8]を出力します。この出力は、入力の形状に一致します。また、このレイヤーを非線形性(例えばもう1つのReLU)に通し、このレイヤーを複数回連鎖させることもできます。
結論
これまで、単一のGNNレイヤーとGATレイヤーの視覚的な実装について説明しました。このGitHubリポジトリでプロジェクトを見つけることができます。論文では、この手法をマルチヘッドアテンションに拡張する方法も説明しています。もしもそれについても説明してほしい、またはGraphbookを使用して他の内容をカバーしてほしい場合は、コメントで教えてください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





