再帰型ニューラルネットワークの基礎からの説明と視覚化
Explanation and Visualization of Recurrent Neural Networks Fundamentals.
機械翻訳への応用
再帰型ニューラルネットワーク(RNN)は、順次操作できるニューラルネットワークです。数年前に比べて人気が落ち着いていますが、深層学習の進展において重要な発展を表し、フィードフォワードネットワークの自然な拡張です。
この記事では、以下の内容について説明します:
- フィードフォワードから再帰型ネットワークへのステップ
- マルチレイヤー再帰型ネットワーク
- 長短期記憶ネットワーク(LSTM)
- 順次出力(「テキスト出力」)
- 双方向性
- 自己回帰生成
- 機械翻訳への応用(Google翻訳の2016年のモデルアーキテクチャの高レベル理解)
この記事の目的は、RNNの動作原理を説明することだけではなく、イラストを用いて設計選択肢と高レベルな直感的論理を探求することです。この記事が、この特定の技術トピックの理解だけでなく、深層学習設計の柔軟性についても独自の価値を提供することを願っています。
再帰型ニューラルネットワークの設計(1985)は、シーケンシャル情報を処理する理想的なモデル(例えば、テキストを読む人間)が2つの観察に基づいていることに基づいています:
- AIは自己を食べるのか?このAI論文では、モデルの崩壊と呼ばれる現象が紹介されており、モデルが時間の経過とともに起こり得ないイベントを忘れ始める退行的な学習プロセスを指します
- より小さい相手による言語モデルからの知識蒸留に深く潜入する:MINILLMによるAIのポテンシャルの解放
- 50以上の最新の最先端AIツール(2023年7月)
- これまでに「学習した」情報を追跡して、新しい情報を以前に見た情報に関連付ける必要があります。例えば、「quick brown fox jumped over the lazy dog」という文を理解するには、「quick」と「brown」という単語を追跡して、これらが「fox」に適用されることを後で理解する必要があります。この情報を「短期記憶」として保持しない場合は、情報の順序的な重要性を理解できません。「lazy dog」で文を終えると、以前に遭遇した「quick brown fox」との関係でこの名詞を読みます。
- 後続の情報は常に前の情報の文脈で読まれますが、位置に関係なく各単語(トークン)を同様の方法で処理したい。第3の位置の単語を第1の位置の単語と異なる方法で変換する理由はないため、後者を前者の光で読むかもしれませんが、前提条件である、各トークンの埋め込みが並べられて同時にモデルに提供される方法は、この性質を持たないことに注意してください。つまり、最初の単語に対応する埋め込みが、3番目に対応する埋め込みと同じルールで読まれることを保証する方法はありません。この一般的な性質は、位置不変性としても知られています。
再帰型ニューラルネットワークは、再帰レイヤーで構成されます。再帰レイヤーは、フィードフォワードレイヤーと同様に、学習可能な数学的変換のセットです。再帰レイヤーは、マルチレイヤーパーセプトロンの用語で近似的に理解できることがわかりました。
再帰レイヤーの「短期記憶」は、その隠れ状態として参照されます。これは、ネットワークがこれまでに学習した重要な情報を伝達するベクトルです。その後、標準化されたテキストの各トークンに対して、新しい情報を隠れ状態に組み込みます。これには、2つのMLPを使用します。1つのMLPは現在の埋め込みを変換し、もう1つのMLPは現在の隠れ状態を変換します。これら2つのMLPの出力は加算され、更新された隠れ状態、つまり「更新された短期記憶」を形成します。
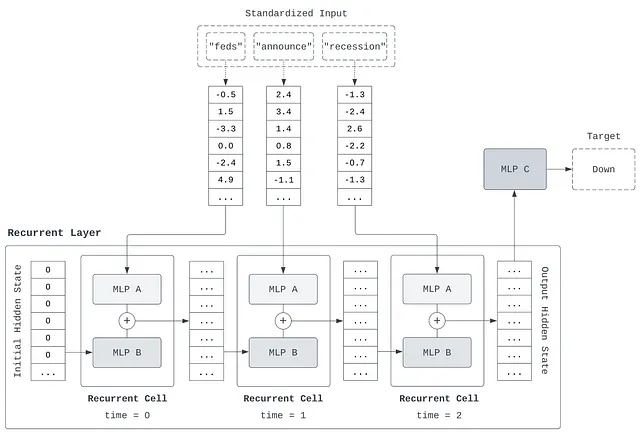
次のトークンに対しても同様に繰り返します。埋め込みはMLPに渡され、更新された隠れ状態は別のMLPに渡されます。これらの両方の出力は加算されます。これは、シーケンスの各トークンで繰り返されます:1つのMLPは、入力を短期記憶(隠れ状態)に組み込むための形式に変換し、別のMLPは短期記憶(隠れ状態)を更新するために準備します。これにより、新しい情報を既存の情報の文脈で読み取る必要があるという最初の要件が満たされます。さらに、これら2つのMLPは各タイムステップで同じです。つまり、現在の隠れ状態を新しい情報と統合する方法について同じルールを使用します。これにより、各タイムステップで同じルールを使用する必要があるという2番目の要件が満たされます。
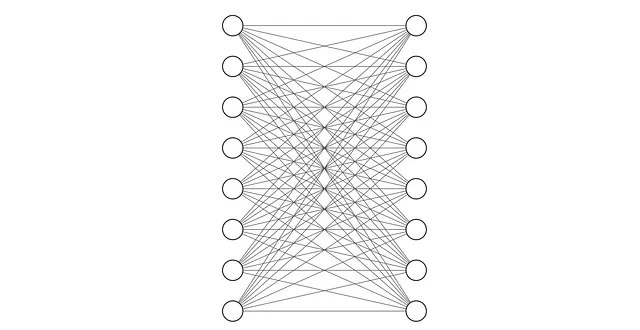
これら2つのMLPは一般的に1層深い実装されています。つまり、ロジスティック回帰の大きなスタックで構成されています。たとえば、次の図は、各埋め込みが8つの数字であり、隠れ状態も8つの数字で構成されると仮定した場合、MLP Aのアーキテクチャがどのようになるかを示しています。これは、埋め込みベクトルを隠れ状態とマージするための単純で効果的な変換です。
最後のトークンを隠れ層に組み込み終わった時、再帰層の役目は終わります。それは、トークン列を順序通りに読み取り、蓄積された情報を表す数値のリストであるベクトルを生成しました。その後、このベクトルを第3のMLPに通して、 ‘現在のメモリの状態’と予測課題(この場合、株価が下がったか上がったか)の関係を学習します。
重みの更新機構は、この本で詳細に議論するには複雑すぎますが、バックプロパゲーションアルゴリズムの論理と似ています。追加の複雑さは、各パラメータが自分自身の出力に繰り返し作用することによる複合効果を追跡する必要があることです(このため、モデルの’再帰’性質)。これは、 ‘時間を経てのバックプロパゲーション’と呼ばれる修正されたアルゴリズムを使って数学的に対処できます。
再帰ニューラルネットワークは、順序データのモデリングにアプローチするかなり直感的な方法です。これは、線形回帰モデルの複雑な配列の別の場合であり、かなり強力です。これにより、言語などの困難な順序学習問題にシステマティックにアプローチできます。
ダイアグラム化と単純化のために、再帰層は入力の一連のブロックとして表されることがよくあります。
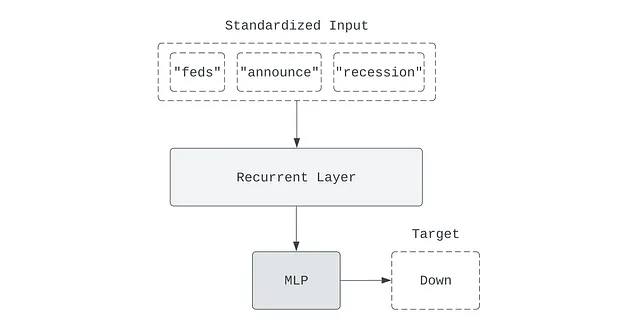
これは、テキストの再帰ニューラルネットワークの最も単純な形です。標準化された入力トークンは埋め込みにマップされ、再帰層に送信されます。再帰層の出力( ‘最新のメモリ状態’)は、MLPによって処理され、予測されたターゲットにマップされます。
再帰ネットワークの複雑なフレーバー
再帰層を使用すると、ネットワークが順序問題に取り組むことができます。ただし、現在の再帰ニューラルネットワークのモデルにはいくつかの問題があります。困難な問題をモデル化するために実際のアプリケーションで再帰ニューラルネットワークがどのように使用されるかを理解するには、いくつかの機能を追加する必要があります。
これらの問題の1つは深さの欠如です。再帰層はテキストを一度だけ通過するため、表層的で概略的な読み取りを行います。哲学者イマヌエル・カントの「幸福は理性の理想ではなく、想像力の理想である」という文を考えてみましょう。この文を真の深さで理解するには、単に言葉を通過するだけでは不十分です。代わりに、単語を読み取り、そして – これが重要なステップです – 自分の考えを読み取ります。文の即時の解釈が適切かどうかを評価し、深い意味を持つように変更することもあります。私たちは自分自身の考えについての考えを読み取るかもしれません。これはすべて非常に迅速に、そしてしばしば私たちの意識的な知識なしに起こるプロセスですが、それはテキストの内容から複数の深さのレイヤーを抽出することを可能にするプロセスです。
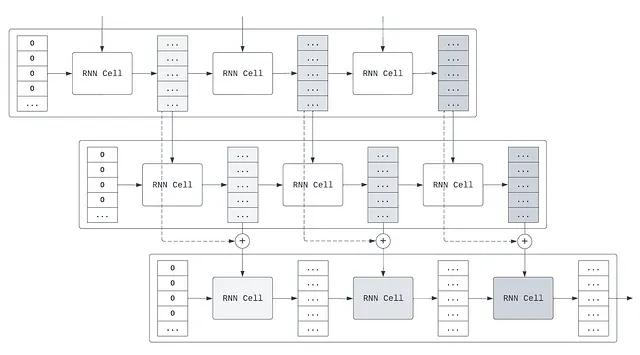
それに応じて、理解の深さを増すために複数の再帰層を追加できます。最初の再帰層はテキストの表層的な情報を取得し、2番目の再帰層は最初の再帰層の ‘考え’を読み取ります。2番目の層の二重通知 ‘最新のメモリ状態’は、最終的な決定を下すために使用されます。また、2つ以上の再帰層を追加することもできます。

このスタッキングメカニズムがどのように機能するかを具体的に説明するには、次の図を参照してください。各隠れ層の状態を単純に更新するだけでなく、この入力状態を次の再帰層に与えます。最初の再帰層への最初の入力は埋め込みであるのに対し、2番目の再帰層への最初の入力は「最初の入力について最初の再帰層が考えたこと」です。

現実の言語モデリング問題に使用されるほとんどの再帰ニューラルネットワークは、深さの理解と言語推論の増加のために、単一の再帰層ではなく、スタックされた再帰層を使用します。大きな再帰層スタックでは、再帰残差接続を使用することがよくあります。情報の以前のバージョンが後のバージョンに追加される残差接続の概念を思い出してください。同様に、各層の隠れ層の間に残差接続を配置して、層がさまざまな ‘思考の深さ’に参照できるようにすることができます。
再帰モデルは、「連邦政府が景気後退を発表」といった短く単純な文章ではうまく機能するかもしれませんが、金融文書やニュース記事はしばしば数語よりもはるかに長く、長いシーケンスに対しては、標準的な再帰モデルは持続的な長期記憶損失の問題に遭遇します。シーケンスの前半部分の信号や重要性が、後半部分の単語によって希釈されて影響を受けることがよくあります。各タイムステップが隠れた状態に影響を与えるため、それは前の情報の一部を部分的に破壊します。そのため、シーケンスの終わりには、一番最初の情報の大部分が回復不可能になります。再帰モデルには、狭い視野の集中力/メモリがあります。人間と同じ理解度と深さでドキュメントを見て分析するモデルを作りたい場合、このメモリ問題を解決する必要があります。
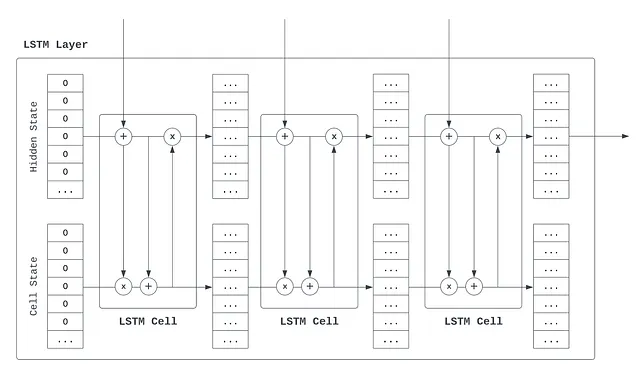
長短期記憶(LSTM)(1997)レイヤーは、より複雑な再帰レイヤーです。その具体的なメカニックは、この本では正確かつ完全に議論するには複雑すぎますが、「長期記憶」と「短期記憶」を分離する試みとして理解できます。シーケンスを「読む」には、両方のコンポーネントが関連しています。時間的に大きな距離を超えて情報を追跡するために長期記憶が必要ですが、特定の局所的な情報に焦点を当てるために短期記憶も必要です。そのため、単一の隠れた状態を保存するだけでなく、LSTMレイヤーは「セル状態」(「長期記憶」を表す)も使用します。
各ステップでは、入力は標準の再帰レイヤーと同じ方法で隠れた状態に統合されます。その後、3つのステップが続きます。
- 長期記憶のクリア。長期記憶は貴重です。時間をかけて保持する情報を持っています。現在の短期記憶状態を使用して、不要な長期記憶の部分を決定し、新しいメモリのために「切り取り」ます。
- 長期記憶の更新。長期記憶でスペースがクリアされたので、短期記憶を使用して長期記憶を更新(追加)し、新しい情報を長期記憶にコミットします。
- 短期記憶の通知。この時点で、長期記憶状態は現在のタイムステップに対して完全に更新されています。短期記憶がどのように機能するかを長期記憶が通知するため、長期記憶は短期記憶をカットして変更するのに役立ちます。理想的には、長期記憶には重要でない情報を短期記憶に保持するかどうかの監督があります。
そのため、短期記憶と長期記憶(両方とも数値のリストであることを忘れないでください)は、各タイムステップで互いにやり取りし、入力シーケンスを読むために、重大な忘却を防ぎながら相互作用します。この3つのステップは、次の図でグラフィカルに示されています。+は情報の追加を示し、xは情報の削除またはクレンジングを示します。(これらのアイデアを実装するために使用される数学的操作は、加算と乗算です。隠れた状態の現在の値が10であるとしましょう。それを0.1で乗算すると、1になります。したがって、隠れた状態の情報を「カットダウン」しました。)
LSTMを積み重ねて残余接続を使用することで、段落や記事全体を「理解」できる強力な言語解釈モデルを構築できます。大量の金融報告やニュースを精査するために使用されるだけでなく、このようなモデルは、ソーシャルメディアの投稿テキストやメッセージから潜在的に自殺やテロ行為を行う可能性がある個人を予測し、顧客が以前の製品レビューに基づいて購入する可能性が高い新しい製品を推奨し、オンラインプラットフォームでの有害なコメントや投稿を検出するためにも使用できます。
このようなアプリケーションには、物質的哲学的影響について批判的に考える必要があります。政府は潜在的なテロリストを検出することに強い関心を持っており、最近の虐殺の背後にはしばしば問題のある公共のソーシャルメディア記録があることが示されていますが、海の情報の中から見つけられなかったのは悲劇でした。再帰モデルのような言語モデルは、純粋に数学的に機能することがわかりました。つまり、入力テキストと出力テキストの間の関係を最もよくモデル化する重みとバイアスを見つけようとします。しかし、これらの重みとバイアスが意味を持っている場合、効果的かつ非常に速く情報を「読む」ことができます。人間の読者よりもはるかに速く、おそらくより効果的に。これらのモデルは、政府がテロリストを発見、追跡、停止することを可能にするかもしれません。もちろん、これはプライバシーのコストがかかる可能性があります。また、言語モデルがデータ内のパターンや関係を機械的に追跡することができることを見てきましたが、実際には間違いを comitする数学的アルゴリズムにすぎません。モデルが個人を潜在的なテロリストとして誤ってラベル付けする場合、どのように調整すればよいでしょうか?
ソーシャルメディアプラットフォームは、ユーザーと政府からの圧力の下、オンラインフォーラムでの嫌がらせや有害な投稿を減らしたいと考えています。これは、概念的にはごく単純なタスクのように思えるかもしれません。社会的メディアのコメントのコーパスを有害かどうかにラベル付けし、次に言語モデルをトレーニングして、特定のテキストサンプルの有害性を予測します。ただし、デジタルディスコースは、迅速に変化する参照(ミーム)、内輪ネタ、巧みに隠された皮肉、および前提条件のコンテキスト知識に依存するため、非常に困難です。しかし、より興味深い哲学的問題は、数学モデル(「客観的」モデル)を本当に訓練して「主観的」なターゲットである有害性を予測できるかどうか、ということです。なぜなら、一人にとって有害なものが、別の人にとっては有害ではないかもしれないからです。
私たちがますます個人的な形式のデータを扱うモデルに取り組むにつれて、言語が私たちがほとんどすべての知識を伝達および吸収するVoAGIであるため、これらの問題について考え、取り組むことがますます重要になってきています。この研究分野に興味がある場合は、アライメント、ジュリーラーニング、憲法AI、RLHF、価値多元主義について調べることをお勧めします。
ニューラル機械翻訳
概念:多出力再帰モデル、双方向性、アテンション
機械翻訳は素晴らしい技術です。これにより、以前は重要な困難なしにまったくコミュニケーションできなかった人々が、自由な対話を行うことができるようになりました。ヒンディー語を話す人は、クリックするだけでスペイン語で書かれたウェブサイトを読むことができ、その逆も同様です。ロシア映画を見ている英語話者は、ライブ翻訳された字幕を有効にすることができます。フランスにいる中国人観光客は、メニューの写真に基づいた翻訳を取得して食べ物を注文することができます。機械翻訳は、文字通り言語と文化を融合させます。
深層学習が台頭する前に、機械翻訳の主流なアプローチは、ルックアップテーブルに基づいていました。たとえば、中国語では、「私」は「我」、「運転する」は「開」、「車」は「车」と翻訳されます。したがって、「私が車を運転する」という文章は、単語ごとに「我开车」と翻訳されます。しかし、任意のバイリンガルスピーカーは、このシステムの弱点を知っています。同じように綴られた多くの単語には異なる意味があります。1つの言語には、他の言語で1つの単語として翻訳される複数の単語がある場合があります。さらに、異なる言語には異なる文法構造があり、翻訳された単語自体を再配置する必要があります。英語の記事は、スペイン語やフランス語などの性別に基づく言語で複数の異なる文脈依存の翻訳があります。これらの問題を巧妙な言語的な解決策で調整しようとする試みは多数ありますが、短くてシンプルな文にしか有効ではありません。
一方、深層学習は、言語をより深く理解し、おそらく人間が言語を理解する方法に近づくことができるモデルを構築するチャンスを提供してくれます。このセクションでは、言語の深層モデリングから複数の追加のアイデアを紹介し、Google翻訳がどのように動作するかについての技術的な探求で集大成を迎えます。
テキスト出力再帰モデル
現在、実行可能な再帰モデルを構築するための最も顕著な障害は、テキストを出力できないことです。以前に議論した再帰モデルは「読む」ことができますが、「書く」ことができませんでした。出力は単一の数値(または数値のコレクション、ベクトル)でした。これを解決するには、言語モデルにテキストのシリーズ全体を出力する機能を付与する必要があります。
幸い、私たちは多くの作業をする必要はありません。以前に紹介された再帰層のスタッキングのコンセプトを思い出してください。再帰層がシーケンス全体を実行した後に「メモリステート」を収集するだけでなく、各タイムステップで「メモリステート」を収集します。したがって、シーケンスを出力するには、各タイムステップでメモリステートの出力を収集できます。次に、各メモリステートを指定されたMLPに渡し、メモリステートが予測された確率に基づいて、出力語彙のどの単語を予測するかを予測します(「MLP C」としてマークされます)。最も高い予測確率を持つ単語が出力として選択されます。
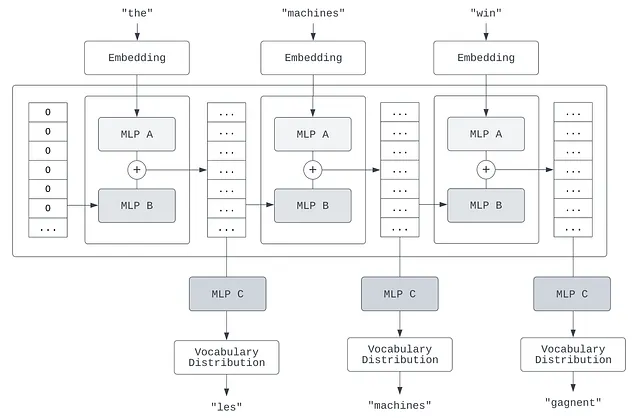
各メモリステートがどのように出力予測に変換されるかを完全に明確にするために、次の図の進行を考えてください。
最初の図では、最初に出力された隠れ層の状態(つまり、最初の単語「the」を読み込んだ後に導出された隠れ層の状態)がMLP Cに渡されます。MLP Cは、出力語彙に関する確率分布を出力します。つまり、出力語彙の各単語に、その単語がその時間に翻訳として選択される可能性を示す確率を与えます。これはフィードフォワードネットワークです。隠れ層でロジスティック回帰を実行して、特定の単語の可能性を決定しています。理想的には、最大の確率を持つ単語は「les」である必要があります。これは「the」のフランス語の翻訳です。

再帰層が「the」と「machines」の両方を読み取った後に導出される次の隠れ状態は、再びMLP Cに渡されます。今回は、最高の確率を持つ単語が「machine」であることが理想的です(これはフランス語の「machines」の複数形の翻訳です)。

最後のタイムステップで選択される最も可能性の高い単語は、「gagnent」であるはずです。これは、特定の時制の「win」の翻訳です。「gagner」や、その他の時制の単語ではなく、以前に読み取った情報に基づいてモデルは「gagnent」を選択する必要があります。これが翻訳に深層学習モデルを使用する利点が発揮されるところであり、文全体にわたって現れる文法ルールを理解する能力があるためです。

実際には、1つの再帰層だけでなく、複数の再帰層を積み重ねたいことがよくあります。これにより、理解の複数のレイヤーを開発できます。最初に入力テキストの意味を「理解」し、次に出力言語の「意味」を再表現します。
双方向性
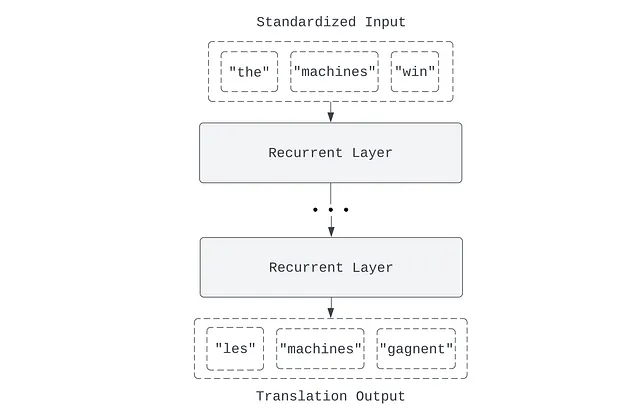
再帰層は順次処理されます。テキスト「the machines win」を読み取ると、「the」、「machines」、そして「win」という順序で読み取ります。最後の単語「win」は、前の単語「the」と「machines」の文脈で読み取られますが、その逆は真ではありません。最初の単語「the」は、後の単語「machines」と「win」の文脈で読み取られません。これは問題です。なぜなら、言語はしばしば私たちが後で何を言うかを予期して話されるからです。フランス語のような性別に基づく言語では、「the」のような冠詞は多くの異なる形を取ることがあります。「la」は女性のもの、「le」は男性のもの、「les」は複数形のものです。どのバージョンの「the」を翻訳するかわかりません。もちろん、文の残りを読んでから、「the machines」であることがわかり、オブジェクトが複数形であることがわかり、「les」を使用する必要があることがわかります。これは、テキストの早い段階が後の段階によって知らされる場合があるという場合です。一般的に言って、私たちは文を再読するときに、最初の部分を最初の文脈で読んでいます。言語は順次読み取られますが、しばしば「順序通りに」(つまり、厳密には始めから終わりまで単方向的に)解釈される必要があります。
この問題を解決するために、双方向性を使用できます。これは再帰的モデルに対して単純な修正であり、層が前方と後方の両方を「読む」ことができるようにします。双方向再帰層は実際には2つの異なる再帰層です。1つのレイヤーは時間軸方向に前方に読み取り、もう1つのレイヤーは後方に読み取ります。両方が読み終わった後、各タイムステップの出力は加算されます。

双方向性により、モデルは過去を未来の文脈で読み取ることができるようになります。デフォルトの再帰層の機能である過去の文脈に加えて、未来の文脈でも読み取ることができます。各タイムステップでの双方向再帰層の出力は、それ以前のすべてのタイムステップだけでなく、シーケンス全体によって通知されます。たとえば、10タイムステップのシーケンスでは、t = 3のタイムステップは、[ t = 0] → [ t = 1] → [ t = 2] → [ t = 3]のシーケンスをすでに読み取った「メモリ状態」と、[ t = 9] → [ t = 8] → [ t = 7] → [ t = 6] → [ t = 5] → [ t = 4] → [ t = 3]のシーケンスをすでに読み取った別の「メモリ状態」によって通知されます。
この単純な変更により、より豊かな言語理解の深度が実現されます。
自己回帰生成
現在の翻訳モデルの動作モデルは、大規模な(双方向の)再帰層のスタックです。しかしながら、問題があります。テキストAを別のテキストBに翻訳するとき、私たちはAに言及してBを書くだけでなく、B自体に言及してBを書きます。
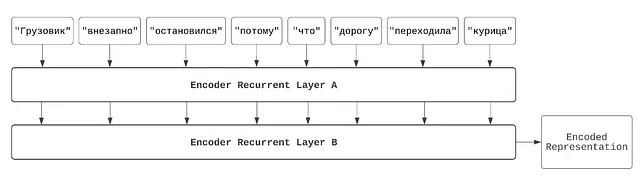
例えば、ロシア語の複雑な文「Грузовик внезапно остановился потому что дорогу переходила курица」を英語の「The truck suddenly stopped because a chicken was crossing the road」と直接的に翻訳することはできません。ロシア語を単語順に直接翻訳すると、「Truck suddenly stopped because road was crossed by chicken」となります。ロシア語では、名詞の後にオブジェクトが置かれますが、この形式を英語で保つことは読めますが、滑らかでなく、最適ではありません。そのため、理解できる使うには、翻訳が原文に忠実であるだけでなく、自己一貫性がある(self-consistent)ことが必要です。
それを行うためには、自己回帰生成と呼ばれる異なるテキスト生成が必要です。これにより、モデルは各単語を、元のテキストに関連してだけでなく、すでに翻訳されたものに関連して翻訳できます。自己回帰生成は、ニューラル翻訳モデルだけでなく、高度なチャットボットやコンテンツジェネレータを含むあらゆる種類の現代的なテキスト生成モデルの支配的なパラダイムです。
まず、’エンコーダ’モデルから始めましょう。この場合、エンコーダモデルは再帰層のスタックとして表現できます。エンコーダは入力シーケンスを読み込み、エンコードされた表現という単一の出力を生成します。この一覧の数字は、定量的な形で入力テキストシーケンスの「本質」を表します。エンコーダの目的は、入力シーケンスをこの基本的な意味のパケットに蒸留することです。
このエンコード表現が得られたら、デコードのタスクを開始します。デコーダはエンコードされた表現(つまり、エンコーダの出力)と特別な「開始トークン」(</s>で示される)を受け入れます。開始トークンは文の始まりを表します。デコーダのタスクは、与えられた文で次の単語を予測することです。この場合、デコーダは「ゼロワードの文章」が与えられており、したがって最初の単語を予測する必要があります。この場合、以前に翻訳された内容がないため、デコーダはエンコードされた表現に完全に依存しており、「The」という最初の単語を予測します。

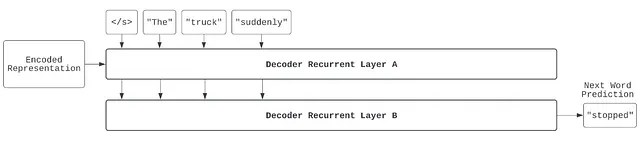
次に、重要な自己回帰ステップがあります。デコーダの前回の出力を取り出して、再度デコーダに入力しています。これで、「1ワードの文章」ができます(開始トークンの後に「The」という単語が続く)。この2つのトークンは、エンコードされた表現とともにデコーダに渡され、デコーダは次の単語を予測します。この場合、デコーダは以前に翻訳された内容と元のロシア語の文の意味の両方を参照できるため、「truck」という次の単語を正しく予測することができます。

このトークンは、別の入力として扱われます。ここでは、自己回帰生成がテキスト生成の役立つアルゴリズミックな足場である理由がより明確に理解できます。現在の作業中の文が「The truck」であることを知っていることで、どのようにそれを完成させるかが制約されます。この場合、次の単語は動詞または副詞である可能性が高く、文法的な構造として「知っている」ということです。一方、デコーダが元のロシア語テキストにしかアクセスできなかった場合、可能性の範囲を効果的に制限することはできません。この場合、デコーダは、以前に翻訳された内容と元のロシア語の文の意味の両方を参照して、次の単語を正しく「suddenly」と予測することができます。

この自己回帰生成プロセスは続きます:
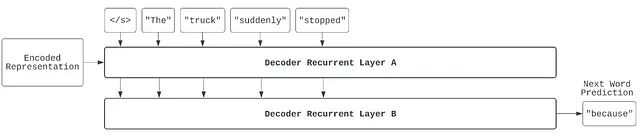
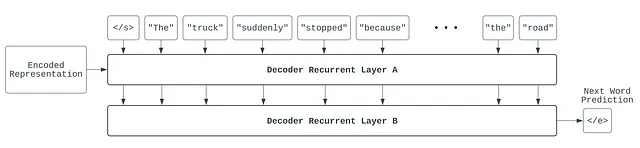
最後に、デコーダモデルは指定された “終了トークン”(</e>で示されます)を予測して文を終了します。この場合、デコーダは、現在の翻訳された文とエンコードされた表現を照合して、翻訳が満足できるかどうかを決定し、文の生成プロセスを停止します。
2016年のGoogle翻訳
これまでに、多くのことをカバーしてきました。現在、Google翻訳のモデルがどのように設計されたかをかなり理解するために必要なほとんどの要素を備えています。 Google翻訳のようなモデルの重要性についてはほとんど説明する必要はありません。粗いとしても、正確でアクセスしやすいニューラル機械翻訳システムは多くの言語の壁を取り払います。この特定のモデルは、私たちにとって、多くの概念を一つの統合されたアプリケーションで話し合ったことをまとめるのに役立ちます。
この情報は、Googleの機械翻訳のためのディープラーニングシステムを紹介した2016年のGoogle Neural Machine Translation論文から取得されています。使用されているモデルがその後の多くの年月で変更されたことはほぼ確実であるが、このシステムは依然としてニューラル機械翻訳システムの興味深いケーススタディを提供しています。明確にするために、このシステムを ‘Google翻訳’ と呼び、現在のものではないと認識します。
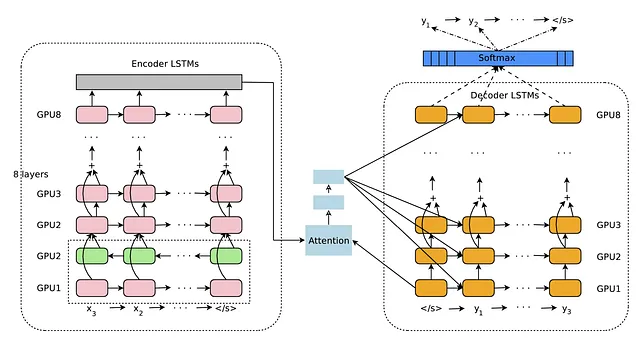
Google翻訳はエンコーダ-デコーダの自己回帰モデルを使用しています。つまり、モデルはエンコーダコンポーネントとデコーダコンポーネントで構成されています。デコーダは自己回帰的であり(以前に生成された出力を入力に追加することを思い出してください)、この場合はエンコーダの出力も追加されます。
エンコーダは7つの長期・短期記憶(LSTM)レイヤーのスタックです。最初のレイヤーは双方向です(したがって、バイナリレイヤーが2つあるため、技術的には8つのレイヤーがあります)。これにより、入力テキストの重要なパターンを両方向から取り込むことができます。さらに、アーキテクチャでは、各レイヤー間に残余接続が使用されています。以前の議論から思い出すように、再帰型ニューラルネットワークの残余接続は、再帰層の入力を各タイムステップで出力に追加することにより実装できます。これにより、再帰層は入力に適用する最適な差分を学習するようになります。
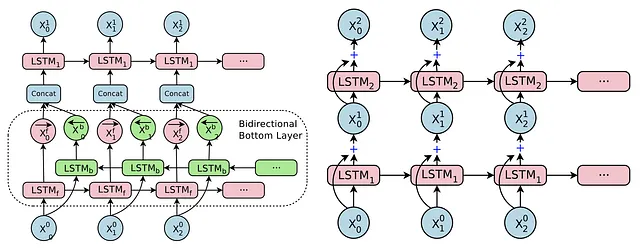
デコーダも8つのLSTM層のスタックです。自己回帰的に以前に生成されたシーケンスを開始トークン </s> で受け取ります。ただし、Google Neural Machine Translationアーキテクチャは、自己回帰的な生成と注意の両方を使用しています。
アテンションスコアは、元のテキストの各単語(エンコーダ内の隠れ状態で表され、テキストを反復的に変換しますが、位置を表します)ごとに計算されます。アテンションは、デコーダとエンコーダの間の対話と考えることができます。デコーダは言います。「これまでに生成した[文]があります。次の翻訳された単語を予測したいです。元の文章のどの単語がこの次の翻訳された単語に最も関連していますか?」エンコーダは答えます。「あなたが考えていることを見て、元の入力について学んだことに一致させます…ああ、あなたは[単語A]に注意を払う必要がありますが、[単語B]や[単語C]にはあまり注意を払わない方がよいです。次の特定の単語を予測するためには、それらはあまり関連していません。」デコーダはエンコーダに感謝します。「私は生成する方法を決定するためにこの情報を考えます。そして、[単語A]に焦点を合わせるようにします。」アテンションに関する情報は、すべてのLSTM層に送信されます。そのため、このアテンション情報は生成のすべてのレベルで知られています。
これがGoogle Neural Machine Translationシステムの主要な部分を表しています。モデルは、英語の入力が与えられた場合、スペイン語の出力を予測するという大規模な翻訳タスクのデータセットでトレーニングされます。モデルは、読み取り方の最適な方法(エンコーダ内のパラメータ)、入力にアテンションを向ける最適な方法(アテンション計算)、およびスペイン語の出力に関連する入力の最適な方法を学習します(デコーダ内のパラメータ)。
後続の作業により、ニューラル機械翻訳システムは多言語能力に拡張され、単一のモデルを使用して複数の言語ペア間で翻訳できるようになりました。これは実用的な観点からだけでなく、すべての言語ペアに対してモデルをトレーニングして保存することは不可能であるため、必要不可欠であるだけでなく、どの2つの言語ペア間の翻訳も改善することが示されています。さらに、GNMTの論文ではトレーニングの詳細について説明しており、これはハードウェアに制約されている非常に深いアーキテクチャであり、実際の展開においても、大きなモデルはトレーニングだけでなく予測を取得するのにも遅延が発生するため、Google翻訳のユーザーはテキストを翻訳するために数秒以上待たなければなりません。
GNMTシステムは確かに計算言語理解における画期的なものである一方、数年後には、ある意味で根本的に簡素化された新しいアプローチが、従来の再帰層を完全に取り除いて言語モデリングを全く新しいものに変えました。Transformersについての2番目の投稿については、引き続きご覧ください!
読んでくれてありがとう!
この投稿では、再帰ニューラルネットワークについて、そのデザインロジック、より複雑な機能、およびアプリケーションを詳しく調査しました。
いくつかのキーポイント:
- RNNはフィードフォワードネットワークの自然な拡張であり、機械翻訳に使用できます。RNNは、これまでに学習した情報を追跡し、新しい情報を以前に見た情報と関連付けるように設計されており、人間が順序付けられた情報を処理する方法に似ています。
- RNNは、短期記憶を表す隠れ状態を持つ再帰層を使用します。
- 再帰層をスタックして、ネットワークの理解と推論の深さを増やすことができます。
- 長期記憶と短期記憶を分離するより複雑な種類の再帰層であるLSTMネットワークがあります。LSTMは、長期記憶と短期記憶の両方をクリア、更新、および通知するメカニズムを持っています。
- RNNは、金融分析、ソーシャルメディア分析、推薦システム、言語翻訳など、さまざまな分野でのアプリケーションを持っています。
- 現実のアプリケーションでRNNを使用することは、プライバシー、モデルの誤り、有害なコンテンツのラベル付けに関する哲学的および倫理的な問題を引き起こすことがあります。
- ニューラル機械翻訳は、異なる言語間の言語翻訳を可能にするRNNの強力なアプリケーションであり、コミュニケーションと文化交流を促進します。
写真はすべて著者によるものです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles




