データパイプラインのテスト計画を進化させる
Evolution of testing plans for data pipelines.
徹底的なマルチソースマルチデスティネーションテスト駆動開発の危険性
テスト駆動開発のアイデアに初めて触れたとき、TDDが約束することに多くの初心者データエンジニアがショックを受けます。より速い開発、よりクリーンなコード、キャリアの向上、世界征服などが名前を挙げることができます。しかし、現実は全く異なります。データエンジニアリングにTDDを適用する最初の試みは、多くのデータエンジニアを落胆させます。TDDの価値を引き出すには多くの努力が必要です。初心者のDEツールベルトにはないテスト技術の深い知識が必要です。何をテストするかを学ぶプロセスは困難です。TDDをデータパイプラインに適用する際のトレードオフを学ぶことはさらに困難です。
本記事では、過度のテスト仕様から生じる苦痛を回避するために、データパイプラインのテスト計画を進化させる方法について見ていきます。
問題
テスト駆動開発の危険性は何でしょうか?その利点にもかかわらず、TDDは新しいデータエンジニアにとって危険なものです。すべてをテストするという最初の衝動は強く、最適でない設計選択肢につながる可能性があります。良いものが過ぎると、言われるように。
データパイプラインのすべての部分をテストするという衝動は、エンジニアリング志向のある人々にとって魅力的な方向です。しかし、正気を保つためには必ず制約が必要です。さもなければ、赤い海に囲まれたテストのジャングルができあがります。そして、泥玉もすぐそこにあります。
- A/Bテストの意味を理解する:厳しい質問でよりよく理解する
- JavaScriptを使用してOracleデータベース内からHugging Face AIを呼び出す方法
- LangChainを使用したLLMパワードアプリケーションの構築
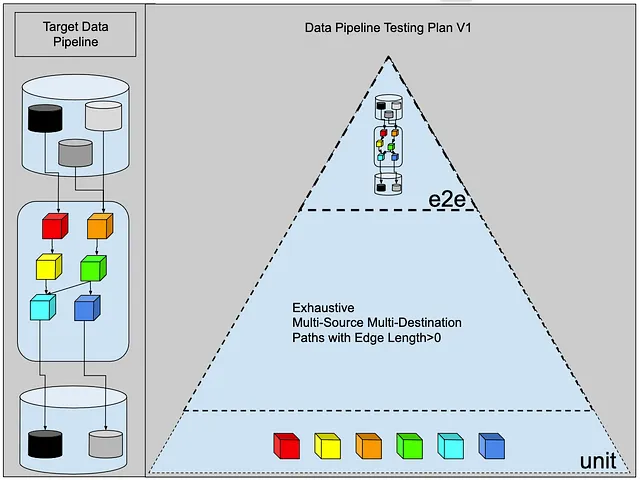
例えば、以下のデータパイプラインがあるとしましょう。

3つのデータソース、6つの変換、2つのデータデスティネーションがあります。
未経験のデータエンジニアはどのようなテスト計画を作成するでしょうか? 私たちも経験があります。
解決策1:エッジ長さ > 0の徹底的なマルチソースマルチデスティネーションパス
クラシックな3つの部分からなるテストフレームワークを使用して、データエンジニアはおそらく次のように始めることができます:
- ユニットテスト ✅ :各変換を取り、各変換に対していくつかのサンプル入力データを生成し、サンプルデータをパイプラインの各ステップに通し、結果をキャプチャし、出力を使用して変換ロジックを検証します。
- E2Eテスト ✅ :本番データのサンプルでパイプライン全体を実行する必要があるので、本番データのサンプルでパイプライン全体を実行し、結果をキャプチャし、エンドツーエンドのパイプラインを検証します。
- 統合テスト ❓❓❓:しかし、ここでは何をすればよいのでしょうか?最初の衝動は、変換ステージの組み合わせごとに1つのテストを構築することです。
おおよその計算を行った後、データエンジニアは6つの変換ステップの組み合わせが急速に増加することを理解し始めます。もっと良い方法があるはずです。
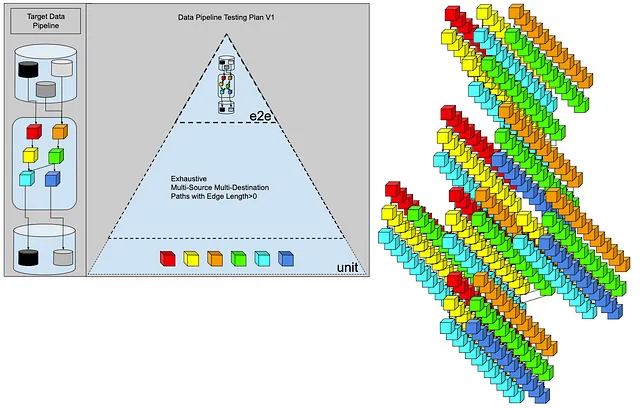
可変長のエッジを持つすべての組み合わせをテストすることは、お客様に約束した締め切りには間に合わないでしょう。もっと時間を予算化すべきでした。
解決策2:
「わかった、でもそんなにひどくないはずだ。」
はい、統合テストが実際のソースとシンクに触れることはないと考えると、それでいいでしょう。これらの6つの変換をつなぎ合わせましょう。以下にグラフの組み合わせを示します。おおよそ10の統合テストが得られます。
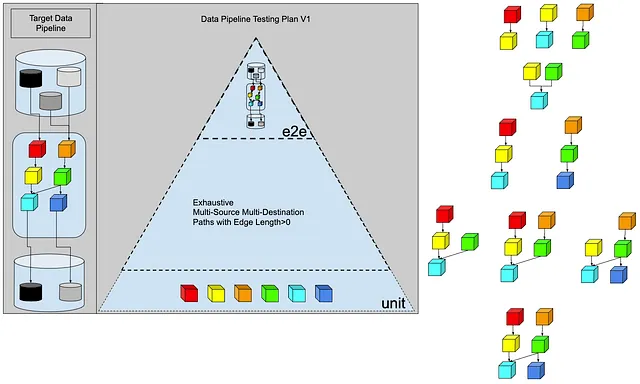
しかし、これはデータエンジニアリングですので、入力データは私たちの制御範囲外であり、時間とともに変化します。したがって、データ中心のテストを追加する必要があります(もちろん、あなたがよりよく知っているかもしれませんが、この議論に従いましょう)。

解決策#3:
「そうですが、なんとかこれを要約できませんか? 絶対にサポートする必要があるデータ検証のコアセットがあるはずですよね? データ検証の優先リストのようなものはありませんか?」
もちろん、データ検証のチェックを遅らせても、以下のような状況になります:

「本当にこれほどのテストが必要ですか? 受け入れテストはユーザーが見るものをテストするものではないのですか? 開発者の経験を犠牲にして、問題を解決する良い製品を時間通りに提供することはできませんか?」
もちろん、次の論理的なステップは、E2Eテストのみを実行して、私たちの生活を進めることです。ただし、ここには「インラインアサーション」と呼ばれる、両方の問題「統合テストが多すぎる」と「堅牢なデータ検証テスト」を解決する中間ステップがあります。おそらく以前に使用したことがあるかもしれませんが、名前がなかったのです。「インラインアサーション」とは、防御プログラミングの伝統から派生した非常に便利なトリックです。
解決策#4:
これらの「インラインアサーション」の基本的なアイデアは、可能な限りパイプライン全体をモノリスとして構築し、コードインタフェースとモノリスのコンポーネント間のデータインタフェースについてのアサーションを含めることです。
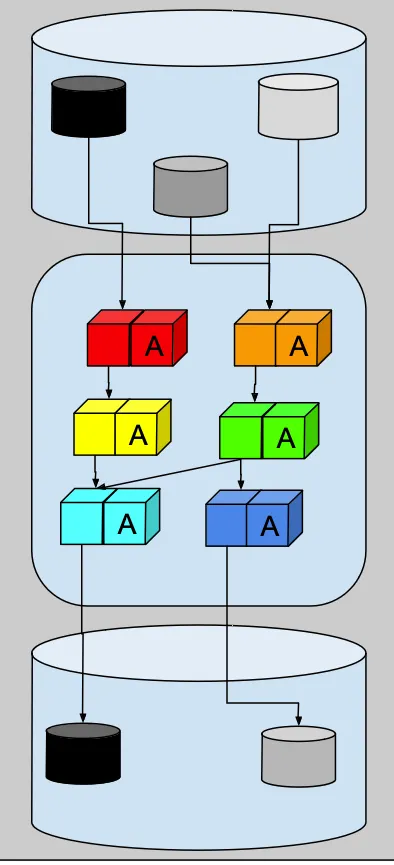
それだけです。赤、緑、リファクタリングの開発ループにそれを組み込み、偶発的な問題が発生するたびにアサーションのリストを増やしていきます。
少し情熱的になっていますが、プロダクションデータソースとプロダクションシンクを使用しています。困っている場合は、それを使用してください。時間がある場合は、少なくとも専用のテストシンクを作成し、入力データソースから取得する行数に制限を設定することを忘れないでください。
これはあなたにとって当たり前のことかもしれませんが、私たちはここで顧客の問題を解決するデータパイプラインの構築方法を学んでいます 🙂
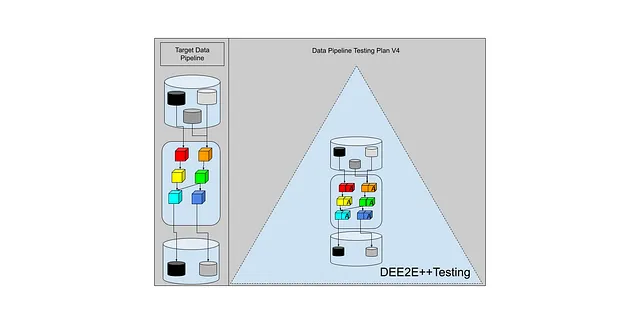
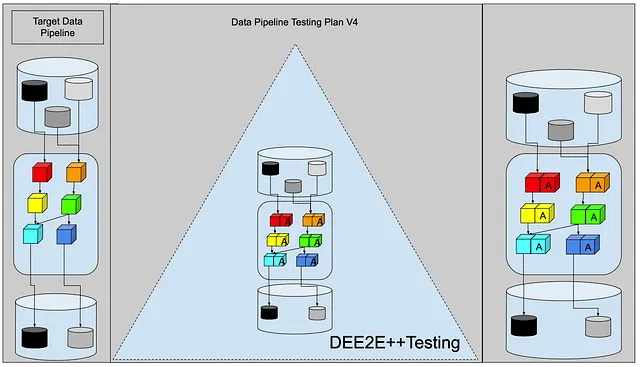
それが尊敬されるテストピラミッドでどのように見えるのでしょうか?
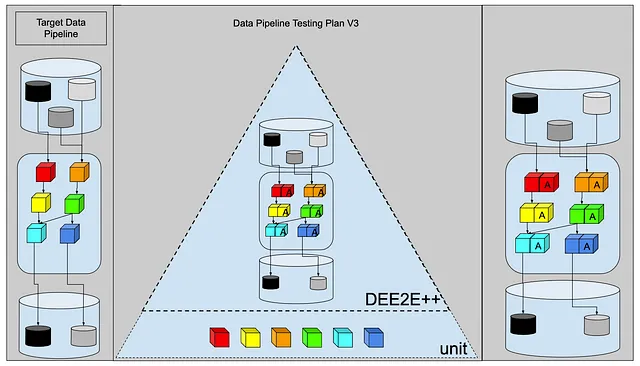
それをDEE2E++テストと呼びましょう。データエンジニアリングエンドツーエンド++テスト。
DEE2E++テストには2つのフレーバーがあるようです:
- 普遍的なアンチコラプションレイヤー(U-ACL)
- 主に警告のアンチコラプションレイヤー(MW-ACL)
普遍的なアンチコラプションレイヤー(U-ACL)の場合、次のようになります:
各変換には、上流の変更から保護する入力アンチコラプションレイヤーと、現在の変換の内部変更から下流のコンシューマーを保護する出力アンチコラプションレイヤーがあります。上流データのスキーマや内容に変更がある場合、入力ACLが処理を停止し、エラーをユーザーに報告します。そして、現在の変換のデータスキーマや内容を変更する場合、出力ACLもエラーをキャッチして処理を停止します。
これは初めてのデータエンジニアにとってかなりの仕事です。各変換に必須の検証ルールを追加すると、データエンジニアは「バッチ作業」となります。パイプラインを複数のステップに分割する代わりに、彼らは「各変換にこれらのACLを追加する必要があるなら、変換の数の2倍になるだろう。それなら2つだけ追加すればいい。パイプラインの上部と下部それぞれに1つずつ。変換の内部は自分で処理する。」と考えるでしょう。これは妥当な初期アプローチであり、焦点は1)トップレベルのインジェストロジックと2)顧客が見えるデータの出力にあります。この戦略の問題は、バグの局所化に関するテストの利点を失うことです。6つの変換のうち4番目にバグがある場合、ACLのテストでは最終出力が無効であることしか示しません。変換4が原因であることは示しません。
さらに、データソースが進化するにつれて、ここでは90%が警告であり、10%がブロッキングエラーです。入力データに新しい列が表示されたからといって、パイプライン全体が失敗する必要はありません。また、ある列の分布平均が少し変わったからといって、すべてのデータが無効であるわけではありません。顧客はビジネスの意思決定に最新の利用可能なデータに興味を持ち、必要に応じて後で調整を行うかもしれません。
そのためには、「主に警告を出すアンチコラプションレイヤー」が必要です。
これは開発者に何か問題があることを知らせますが、処理を停止しません。入力および出力のACLと同じ役割を果たし、各変換に対してより寛容です。このタイプのACLは警告とメトリクスを生成し、開発者は後で警告の優先順位を付けることができます。何かが完全に手に負えなくなった場合、開発者はデータ変換を修正した後にデータをバックフィルすることができます。
もちろん、個人の状況によります。現在のデータパイプラインの出力には少数の確立された人間のユーザーがいる場合、消費者とのコミュニケーションが新しい開発者がドメインについて学ぶのに役立ちます。一方、このパイプラインには多数の確立された自動データパイプラインが存在し、出力を消費している場合、このDEE2E++テストは十分ではないかもしれません。ただし、初めて始める新しいデータ開発者は、数百のデータコンシューマーに影響を与えるビジネスクリティカルなデータパイプラインに1日目から割り当てられる可能性は低いでしょう。したがって、新しいデータ開発者を外国のテスト技術とミッションクリティカルなドメインの両方で押しつぶすことなく、DEE2E++メソッドは新しいデータ開発者のための良い出発点になることができます。
ここにDEE2E++ダイアグラムが再び表示されます。
「待って、待って、待って、各コンポーネントには警告のみのアンチコラプションレイヤーしか付かないって言ってるの?」
「警告のみ」ではなく、「主に警告」です。アサーションのいくつかは確かに処理を停止し、ジョブを失敗させるでしょう。ただし、そうです、それがアイデアです。普遍的なアンチコラプションレイヤー戦略を実行すると、より多くの時間が必要になります。ドメインがより明確になるにつれて、データパイプラインの重要な部分により厳格なACLを追加できます。このドメイン理解は、変換の複雑さに基づいて変換をランク付けするのに役立ちます。追加の注意が必要な複雑な変換を特定した場合、例えば、非常に重要なビジネスロジックを保護するために「MW-ACL」から「U-ACL」に移行できます。
「つまり、単体テストはなぜ必要ですか?インラインテストでカバーされているのではないですか?」
もちろん、そうですね、削除しましょう。
よし?みんな仕事に戻りましょう。
結論
要するに、テスト駆動開発の一般的な原則は、新しいデータエンジニアにとっては非常に圧倒的なものです。TDDは法律ではなく、設計ツールであることを覚えておくことが重要です。賢く使えば、それはあなたに役立つでしょう。しかし、あまりにも多く使いすぎると、苦しい状況に陥ることになります。
この記事では、過度に具体化されたテストがどのような結果をもたらすかを検証しました。まず、一見シンプルなデータパイプラインを取り上げ、私たちが「徹底的な多元ソース多元宛先パス」の罠に陥った場合に何が起こるかを見ました。次に、統合テストがデータ中心のテストと比較して氷山の一角に過ぎないことを確認しました。最後に、初心者のデータエンジニアにとって、E2Eテストに「ほとんど警告のある防腐層」をインラインテストとして重点を置くのが良いスタート地点であることがわかりました。このDEE2E++テスト戦略には2つの利点があります。まず、新人データエンジニアは初日からテストを諦めることはありません。2つ目に、開発者にはドメインについて学び、既存の基本的なデータエンジニアリングの知識を活用してデータパイプラインの設計を反復する余地が与えられます。TDDのマイクロレベルにすぐに迷い込むのではなく、ステークホルダーに動作するソフトウェアを提供し、その後、DEE2E++テストが提供する保護の上により詳細なテストを追加して要件が進化することができます。
以上がテスト駆動開発の危険性です。皆さんはそれらを避け、データパイプラインが常に健全であることを願っています。
現代のデータパイプラインのテスト手法についてもっと学びたいですか?
このテーマに関する私の最新の書籍をチェックしてください。この本は、現代のデータパイプラインのテストにおける最も人気のある手法を視覚的に紹介しています。
2023年の書籍リンク:
書籍リンク: Modern Data Pipelines Testing Techniques on leanpub.
それでは、さようなら!
免責事項:この投稿で表明された意見は私個人のものであり、現在の雇用主や過去の雇用主の意見と必ずしも一致するとは限りません。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- LangChain:LLMがあなたのコードとやり取りできるようにします
- ドキュメント指向エージェント:ベクトルデータベース、LLMs、Langchain、FastAPI、およびDockerとの旅
- PythonのAsyncioをAiomultiprocessで強化しましょう:包括的なガイド
- 私が通常のRDBMSをベクトルデータベースに変換して埋め込みを保存する方法
- UCLAの研究者が、最新の気候データと機械学習モデルに簡単で標準化された方法でアクセスするためのPythonライブラリ「ClimateLearn」を開発しました
- ベクトルデータベースについてのすべて – その重要性、ベクトル埋め込み、および大規模言語モデル(LLM)向けのトップベクトルデータベース
- Hamiltonを使って、8分でAirflowのDAGの作成とメンテナンスを簡単にしましょう
