「表形式データの進化:分析からAIへ」
Evolution of Tabular Data From Analysis to AI
Kaggleのコンペティション、オープンソースコミュニティ、およびGenerative AIによって、表形式のデータ空間がどのように変革されているかを発見しましょう。

イントロダクション
表形式のデータは、行と列に整理されたデータを指します。これにはCSVファイルやスプレッドシートから関係データベースまで、さまざまなものが含まれます。表形式のデータは数十年前から存在し、データ分析や機械学習で最も一般的に使用されるデータ型の一つです。
従来、表形式のデータは情報の整理や報告に使用されてきました。しかし、過去10年間で、いくつかの重要な要因により、その使用法は大きく進化しました:
- Kaggleのコンペティション:Kaggleは2010年に登場し、実世界の表形式のデータセットを使用したデータサイエンスや機械学習のコンペティションを普及させました。これにより、多くのデータサイエンティストや機械学習エンジニアが表形式のデータの分析やモデル構築の力に触れることができました。
- オープンソースの貢献:Pandas、DuckDB、SDV、Scikit-learnなどの主要なオープンソースライブラリのおかげで、表形式のデータの操作、前処理、予測モデルの構築が非常に簡単になりました。さらに、オープンソースのデータセットは初心者に実世界のデータセットでの練習の機会を提供しています。
- Generative AI:特に大規模な言語モデルを含むGenerative AIの最近の進歩により、現実的な表形式のデータの生成が可能になり、基本的に誰でもデータ分析や機械学習アプリケーションの構築が容易になりました。
このエッセイでは、これらの要因について詳しく説明し、企業や研究者が今日革新的な方法で表形式のデータをどのように使用しているかについて例を挙げます。主なポイントは、機械学習やAIの恩恵を受けるために、表形式のデータを適切に分析し準備することの重要性です。
このエッセイは、2023年のKaggle AIレポートの一部であり、参加者が7つのトピックのうちの1つについてエッセイを書くコンペティションです。プロンプトでは、コミュニティが過去2年間の作業と実験から学んだことを説明するように求められています。
表形式のデータ Kaggle コンペティション
Kaggleコンペティションは、データサイエンスと機械学習エンジニアリングの分野に大きな影響を与えています。さらに、表形式のコンペティションは、新しい技術やツール、さまざまな表形式のタスクを導入しました。
学習と知識の開発に加えて、コンペティションで優勝することはしばしば現金賞金を伴い、参加のさらなる動機づけとなります。例えば:
- 平均して、Kaggleコンペティションは約21,246ドルの賞金を提供し、約1,498の参加チームがあります。
- 最大の賞金は$125,000まであり、優勝者には表形式のデータで可能な限りのことを行う動機づけが与えられます。
注意:分析とコードの例にはMeta Kaggleデータセットを使用します。このデータセットはApache 2.0のもとで提供されており、毎日更新されています。
import pandas as pdcomptags = pd.read_csv("/kaggle/input/meta-kaggle/CompetitionTags.csv")tags = pd.read_csv("/kaggle/input/meta-kaggle/Tags.csv")comps = pd.read_csv("/kaggle/input/meta-kaggle/Competitions.csv")tabular_competition_ids = comptags.query("TagId == 14101")['CompetitionId']tabular_competitions = comps.set_index('Id').loc[tabular_competition_ids]tabular_competitions.describe()[["RewardQuantity","TotalTeams"]]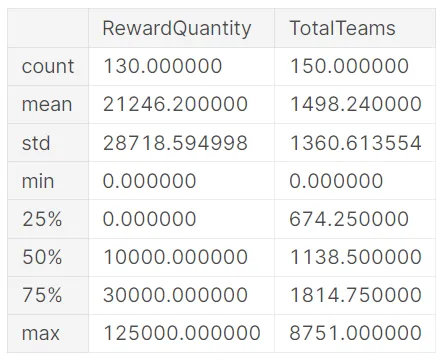
過去10年間、Kaggleは数多くの表形式のデータに焦点を当てたコンペティションを開催しており、2015年以降は優勝チームに最大$100,000の現金賞金を提供しています。
import plotly.express as pxtabular_competitions["EnabledDate"] = pd.to_datetime( tabular_competitions["EnabledDate"], format="%m/%d/%Y %H:%M:%S")tabular_competitions["EnabledDate"] = tabular_competitions["EnabledDate"].dt.yeartabular_competitions.sort_values(by="EnabledDate", inplace=True)fig = px.bar( tabular_competitions, x="EnabledDate", y="RewardQuantity", title="Reward Distribution of Tabular Competitions over the Years", labels={"RewardQuantity": "Prize Money($)", "EnabledDate": "Year"},)fig.show()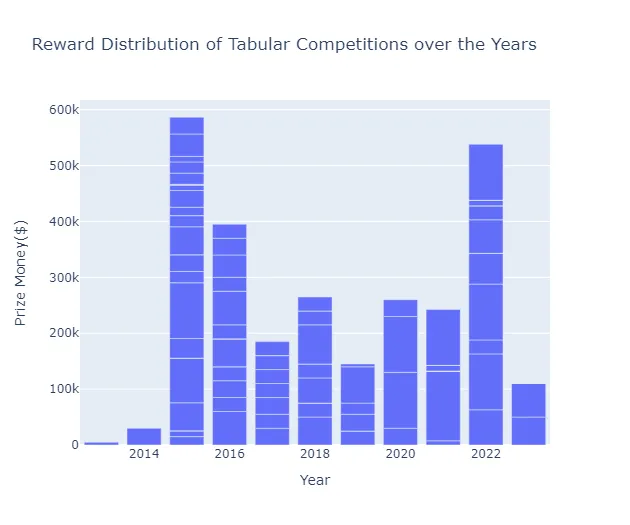
この期間において、タブラーデータ競技の数は大幅に増加し、特に2015年と2022年には非常に活発な活動が見られました。
fig = px.histogram( tabular_competitions, x="EnabledDate", nbins=20, title="タブラーデータ競技の数の推移", labels={"EnabledDate": "年"},)fig.show()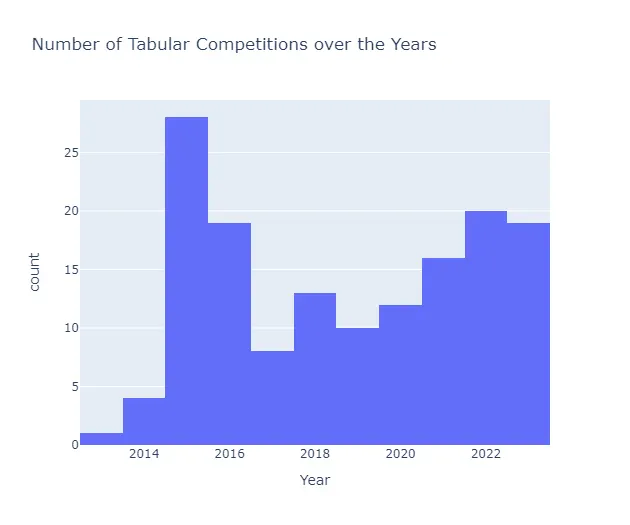
タブラープレイグラウンドシリーズ
タブラーデータの問題に対する大きな需要を受けて、Kaggleのスタッフは2021年に実験を開始し、月次のコンテストであるタブラープレイグラウンドシリーズを開催しました [2]。これらの競技は、参加者がタブラーデータ上でスキルを磨くための一貫したプラットフォームを提供することを目的としています。
タブラープレイグラウンドシリーズの競技は、公開データや以前のKaggleの競技からのデータの構造を再現した合成データセットに基づいています。これらの合成データセットは、CTGANと呼ばれるディープラーニングの生成ネットワークを使用して作成されました[3]。
- エクスポージャー: 多くの機械学習の実践者は、タブラーデータとの作業において、タブラープレイグラウンドシリーズを通じて最初の経験を得ました。これにより、データの読み込み、特徴量エンジニアリング、モデルの調整などの概念に慣れることができました。
- テクニック: Kaggleの競技では、タブラーデータに特に有用な特徴量エンジニアリング、データ拡張、アンサンブルモデリングなどのテクニックが紹介されました。競技者はこれらのテクニックを使用して高いスコアを達成し、他の人に示しました。
- コミュニティ: Kaggleの競技内での議論は、タブラーデータの最良の取り扱い方法についてのテクニックやアイデアの共有に非常に役立ちました。これにより、タブラーデータを中心とした実践コミュニティが形成されました。
- 民主化: Kaggleの競技により、データ専門家だけでなく、より広い範囲の人々にとってタブラーデータ上の機械学習がよりアクセスしやすくなりました。参加者はCPUとGPU、大規模なデータセットの無料アクセスを得ることができ、誰でも競技に参加することができます。
タブラープレイグラウンドシリーズは現在も続いており、シーズン3のエピソード18です。これは、現金の賞金やポイントシステムを提供していないため、参加者にとって現金の賞金だけが動機ではないことを示しています。むしろ、このシリーズは、さまざまなタイプのタブラーデータを実践することでスキルを磨きたいデータ愛好家を対象としています。
競技の解決策
優勝解答の調査から、高い成績を収めるためには派手なツールや深層学習モデルは必要ないことがわかりました。線形回帰のようなよりシンプルなモデルも、注意深い特徴量エンジニアリングと組み合わせることで賞を獲得することができます。重要なのは、与えられた問題を解決するためのシンプルで効果的な技術を見つけることです。
たとえば、GoDaddy – マイクロビジネス密度予測競技 [5] の優勝者 [4] は、線形回帰を使用しました。これは、優勝解答がしばしば単純なモデルに基づいているが、広範な特徴量選択、クロスバリデーション、データ拡張、アンサンブル技術を組み合わせているためです。
タブラーデータのオープンソース貢献
タブラーデータに関連するオープンソースの貢献は、この分野の進歩と実世界の応用において非常に貴重です。貢献は主に以下の2つのカテゴリに分類されます:
- オープンソースのデータセット
- オープンソースのツール
オープンソースのデータセット
Kaggleの成功は、機械学習の問題に対して実世界の表形式のデータセットを共有するオープンソースの貢献者による寛大な貢献によるものです。これらのデータセットは、さまざまなドメインやユースケースをカバーしており、機械学習コミュニティにとって貴重なトレーニングおよびベンチマークデータを提供しています。多くの企業や組織が自社のプロプライエタリな表形式のデータを公然と貢献して、この分野を進めるための貢献をしています。Kaggleで利用可能なデータセットの数と多様性は、表形式のデータを扱うためのイノベーションの重要な要素となっています。
具体的なデータセットを探している初心者やエキスパートにとって、Kaggleのデータセット[6]は頼りになる場所です。その膨大な数の表形式のデータセットは、コミュニティのメンバーが新しい技術を実践し、新しいタイプのデータを扱うのを手助けしています。
オープンソースのツール
表形式のデータを解析、操作、モデリングするためのいくつかの主要なオープンソースのツールは、開発者コミュニティの貢献によって可能になりました。Pandas、Numpy、scikit-learn、TensorFlow、XGBoostなどのツールは、大規模な表形式のデータを扱うための重要な手段となっています。これらのライブラリは包括的な機能セットを提供しており、表形式のデータ機械学習を広範なユーザーにアクセス可能にしました。コミュニティの貢献により、これらのツールは継続的に改善され、新しい要件に適応しています。
さらに、DuckDBやPySparkなどの効率的なツールも利用可能であり、大規模な表形式のデータを分析および処理するための使いやすくてパワフルな方法を提供しています。
%pip install duckdb -qDuckDBを使用すると、CSVファイルを簡単にインポートしてSQLクエリを数秒で実行できます。
import duckdbduckdb.sql('SELECT * FROM "/kaggle/input/meta-kaggle/Competitions.csv" LIMIT 5')
┌───────┬────────────────┬──────────────────────┬───┬──────────────────────┬──────────┬───────────────────┐│ Id │ Slug │ Title │ … │ EnableSubmissionMo… │ HostName │ CompetitionTypeId ││ int64 │ varchar │ varchar │ │ boolean │ varchar │ int64 │├───────┼────────────────┼──────────────────────┼───┼──────────────────────┼──────────┼───────────────────┤│ 2408 │ Eurovision2010 │ Forecast Eurovisio… │ … │ false │ NULL │ 1 ││ 2435 │ hivprogression │ Predict HIV Progre… │ … │ false │ NULL │ 1 ││ 2438 │ worldcup2010 │ World Cup 2010 - T… │ … │ false │ NULL │ 1 ││ 2439 │ informs2010 │ INFORMS Data Minin… │ … │ false │ NULL │ 1 ││ 2442 │ worldcupconf │ World Cup 2010 - C… │ … │ false │ NULL │ 1 │├───────┴────────────────┴──────────────────────┴───┴──────────────────────┴──────────┴───────────────────┤│ 5行 42列(表示されるものは6列) │└─────────────────────────────────────────────────────────────────────────────────────────────────────────┘Python Relational APIを使用して、表形式のデータに対してクイックかつ複数のアクションを実行できます。その構文は、pandasに似ているため、使いやすくなっています。
rel = duckdb.read_csv('/kaggle/input/meta-kaggle/Competitions.csv')rel.filter("RewardQuantity > 100000").project( "EnabledDate,RewardQuantity").order("RewardQuantity").limit(5)
┌─────────────────────┬────────────────┐│ EnabledDate │ RewardQuantity ││ varchar │ double │├─────────────────────┼────────────────┤│ 07/25/2019 21:10:14 │ 120000.0 ││ 11/02/2021 16:00:27 │ 125000.0 ││ 11/14/2016 08:02:32 │ 150000.0 ││ 11/22/2021 18:53:57 │ 150000.0 ││ 05/11/2022 18:46:43 │ 150000.0 │└─────────────────────┴────────────────┘表形データのための生成型AI
生成型AIは、Variational AutoencodersやGenerative Adversarial Networks (GANs)などのニューラルネットワークによって動かされる人工知能のサブフィールドであり、写真のようなリアルな画像を生成したり、オリジナルの音楽を作曲したり、ニュース記事や物語を執筆したり、さらにはオブジェクトをデザインすることができます。これらは大規模なデータセットでトレーニングされており、生成型AIモデルはデータに存在する潜在的なパターン、構造、統計的な分布を発見することができます。
生成型AIモデルは、表形データの取り扱いの分野で大きな進歩を遂げています。データの拡張、異常検出、合成データの生成などの機能により、データの不足、プライバシー、バイアスなどの問題に取り組むことができます。
ただし、ChatGPTやその他の大規模な言語モデル(LLM)のような最近の進展により、これらはタブラーデータタスクのアシスタントとしても使用されるようになっています。生成型AIがワークフローを変革している方法の一部は次のとおりです:
- コードアシスタント: ChatGPTのようなLLMは、タブラーデータの特徴エンジニアリング、前処理、モデリング、機械学習パイプラインの評価などのコーディングタスクをサポートすることができます。コードの断片、関数、スクリプト全体を提案することができます。
- データの理解: 生成型AIは、データの分布、相関関係、欠損値、外れ値、ターゲット変数などの洞察を提供することができます。
- 深い分析: 統計的なテストを実行し、視覚化を作成し、モデリングの意思決定に関する詳細な分析を提供します。
- Webスクレイピング: 生成型AIツールは、Webサイトやアプリケーションから新しい表形データをスクレイピングするのに役立ち、データ取得のタスクを支援します。
安全性、バイアス、狭い機能などの問題は残っていますが、大規模な言語モデルは日常的にタブラーデータを取り扱うデータサイエンティストや機械学習エンジニアの作業方法を変えつつあります。これらはさまざまな分析やコーディングのタスクを担当するアシスタントとしてますます重要な存在となり、実践者がより高度な作業に集中できるようになりました。
タブラーデータのためのChatGPT
ChatGPT [7]は、タブラーデータの取り扱いのほぼすべての段階で貴重なアシスタントとなっており、データのクリーニングや特徴エンジニアリングの支援から、複雑なモデルコードの生成、メトリクスの解釈、データ分析レポートの作成、さらにはデータの拡張や異常検出などのための合成データ生成の支援まで行うことができます。
ChatGPTを使用すると、詳細なプロンプトを入力するだけで、簡単に機械学習モデルを構築してトレーニングすることができます。さらに、コードの実行やインターネットアクセスなどの複雑なタスクを自動化するために複数のプラグインを利用することもできます。
実際のデータサイエンスプロジェクトでChatGPTを使用する方法については、「データサイエンスプロジェクトにChatGPTを使用するガイド」[8]をご覧ください。
表形データのための生成型AIツール
PandasAI [9]などの生成型AIツールは、データ分析、データセットのクリーニング、データの可視化を、誰にでも非常に簡単に行えるようにしました。これらのツールはgpt-3.5-turbo [10]のような大規模な言語モデルを使用して、洞察に富んだ結果を生成します。また、AI分析を実行するためにHugging Faceでホストされているオープンソースモデルに接続することもできます。
%pip install pandasai -q
from kaggle_secrets import UserSecretsClientfrom pandasai import PandasAIfrom pandasai.llm.openai import OpenAIuser_secrets = UserSecretsClient()secret_value_0 = user_secrets.get_secret("OPENAI_API_KEY")llm = OpenAI(api_token=secret_value_0)pandas_ai = PandasAI(llm)最高のRewardQuantityを持つトップ5の競技を表示するために、ChatGPTにプロンプトを入力して表示するように依頼しました。
pandas_ai.run(tabular_competitions, prompt='最高のRewardQuantityを持つトップ5の競技のリストを表示してください。競技の名前、日付、対応する報酬のみを表示してください。')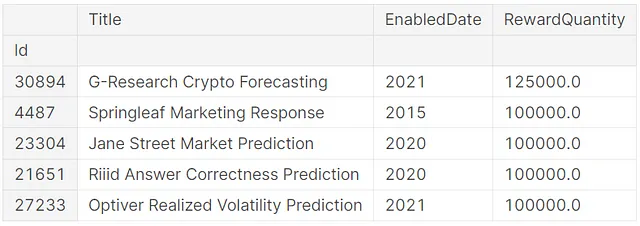
さらに、複雑なタスクや可視化の生成を依頼することもできます。
pandas_ai.run(tabular_competitions, prompt='「Market」を含む全ての競技をリストアップしてください。')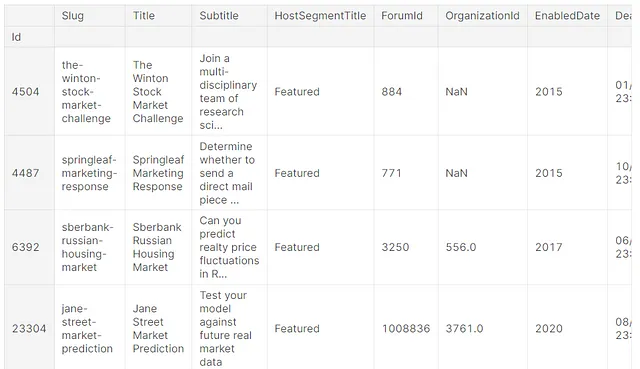
これは始まりに過ぎません。データサイエンティストや開発者の生活を簡単にし、タスクを自動化して支援する多くの新しいAIツールを見ることになるでしょう。
結論
機械学習やAIアプリケーションにおいてタブularデータを活用するためには、大きな進歩がされていますが、これは始まりに過ぎません。将来、高度なAIエージェントによって推進される新しい強力なツールが登場し、データの取り込みやクリーニングから特徴エンジニアリング、モデルのトレーニング、評価、そしてウェブアプリケーションへの展開まで、タブラーマシンラーニングタスクのワークフロー全体を自動化することができるでしょう [11]。生成AIと自然言語処理の進歩により、これらのエージェントは高レベルのプロンプトを受けて、データから洞察まで、完全なタブラーデータサイエンスプロジェクトを完了することができるようになるでしょう。
このエッセイでは、Kaggleのコンペティション、オープンソースコミュニティ、生成AIが、データ解析や機械学習などのタブラーデータの取り扱いに与える重要な影響について紹介しました。さらに深くこのトピックについて知りたい場合は、2023年のKaggle AIレポートコンペティションの優勝エッセイを読むことができます [12]。
参考文献
[1] Wikipediaの投稿者、「Kaggle」、Wikipedia、2023年6月、[オンライン]。利用可能:https://en.wikipedia.org/wiki/Kaggle
[2] 「Tabular Playground Series — Jan 2021 | Kaggle.」 https://www.kaggle.com/competitions/tabular-playground-series-jan-2021
[3] Sdv-Dev、「GitHub — sdv-dev/CTGAN: Conditional GAN for generating synthetic tabular data.」、GitHub。https://github.com/sdv-dev/CTGAN
[4] KAGGLEQRDL、「#1 solution — generalization with linear regression」、2023年3月16日。https://www.kaggle.com/competitions/godaddy-microbusiness-density-forecasting/discussion/395131
[5] 「GoDaddy — Microbusiness Density Forecasting | Kaggle」、2022年12月15日。https://www.kaggle.com/competitions/godaddy-microbusiness-density-forecasting/overview
[6] 「Find Open Datasets and Machine Learning Projects | Kaggle.」 https://www.kaggle.com/datasets
[7] 「Introducing ChatGPT」、OpenAI、2022年11月30日。https://openai.com/blog/chatgpt
[8] A. A. Awan、「A Guide to Using ChatGPT For Data Science Projects」、2023年3月、[オンライン]。利用可能:https://www.datacamp.com/tutorial/chatgpt-data-science-projects
[9] Gventuri、「GitHub — gventuri/pandas-ai: Pandas AI is a Python library that integrates generative artificial intelligence capabilities into Pandas, making dataframes conversational」、GitHub。https://github.com/gventuri/pandas-ai
[10] 「GPT-3.5」、OpenAI。https://platform.openai.com/docs/models/gpt-3-5
[11] R. Cotton、「Introduction to AI Agents: Getting Started With Auto-GPT, AgentGPT, and BabyAGI」、2023年5月、[オンライン]。利用可能:https://www.datacamp.com/tutorial/introduction-to-ai-agents-autogpt-agentgpt-babyagi
[12] 「2023 Kaggle AI Report」、2023年5月、[オンライン]。利用可能:https://www.kaggle.com/competitions/2023-kaggle-ai-report/leaderboard
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
