データランドスケープの進化
Evolution of Data Landscape
著者:SrujanとTravis Thompsonによる共同執筆
データドメインは、地下に厚いファイルが出現した頃から大きく成熟し、長い道のりを歩んできました。その旅は、ソフトウェア革命と同じくらい魅力的でスリルに満ちていたと言えます。良いことに、今私たちはデータ革命の真っ只中におり、それを直接目撃する機会があります。
5〜10年前とはまったく異なる問題に直面しており、現在は全く新しい問題に直面しています。そのいくつかは、データのカンブリア爆発の結果発生し、その他のいくつかは、初期の問題を解決するために考案された解決策の結果として驚くべきものでした。
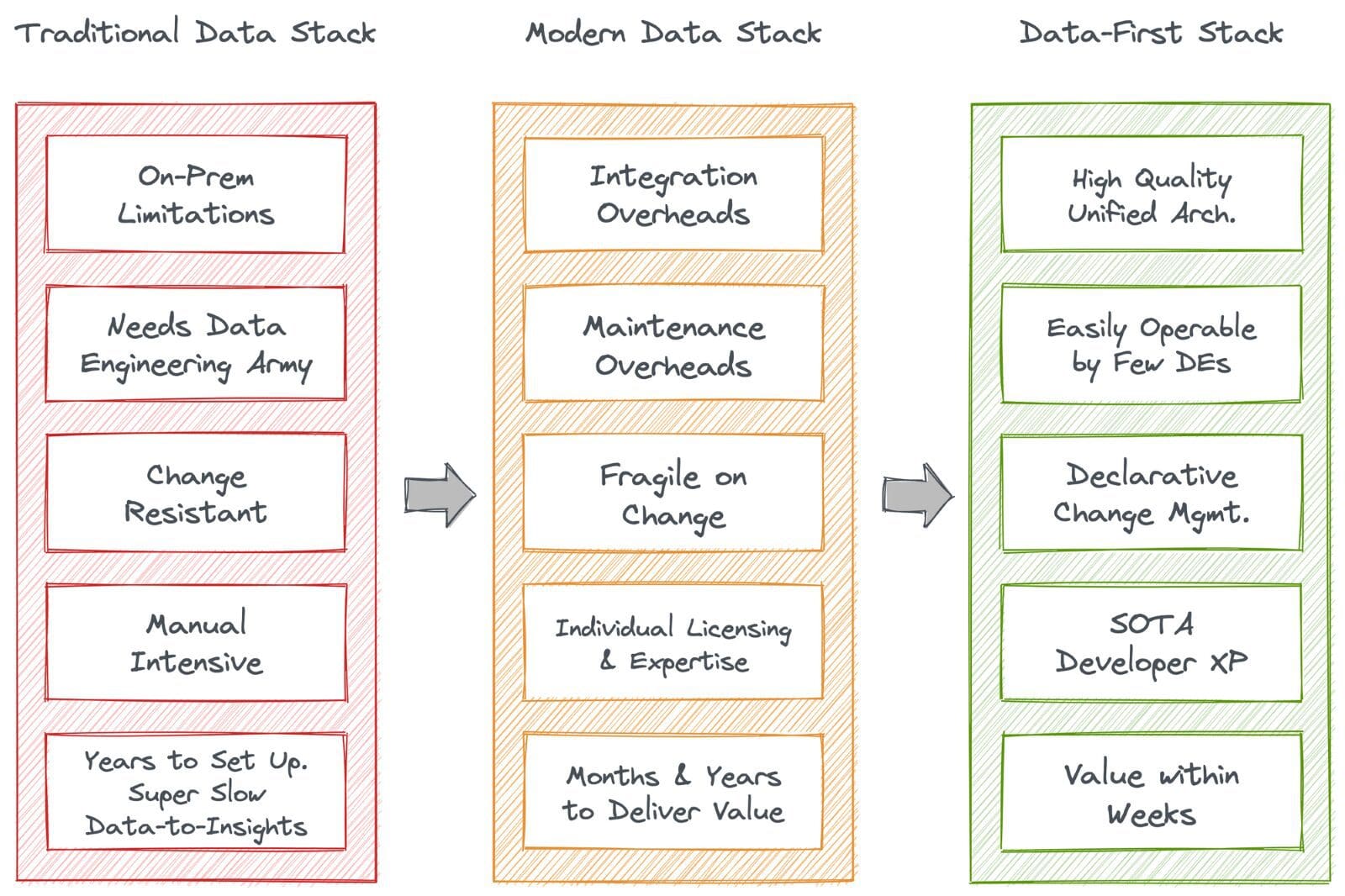
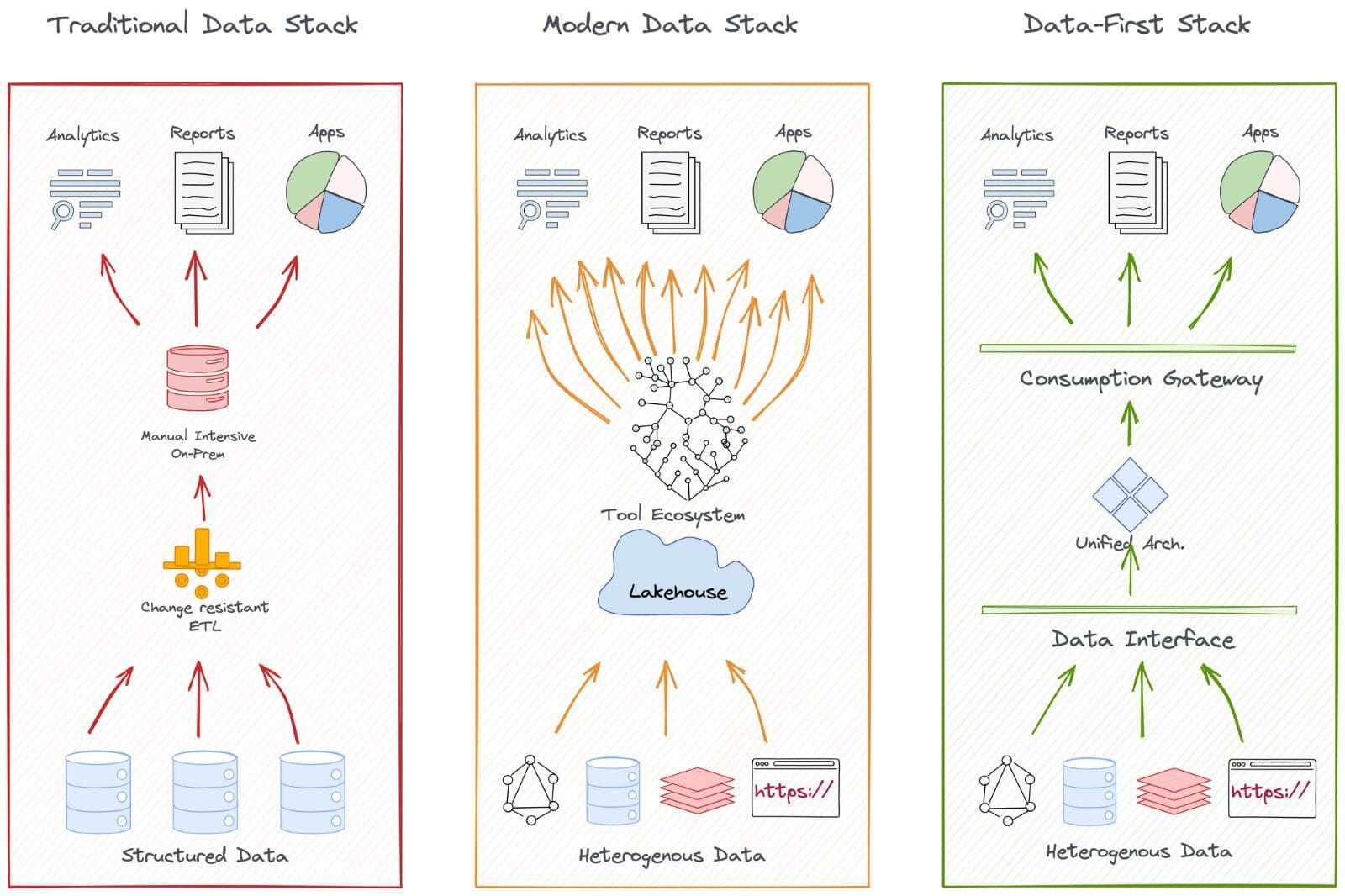
これにより、多数のデータスタックとアーキテクチャを跨いで多くの移行が発生しました。ただし、単純でありながら根本的に転換点となる3つのスタックが目立ちました:従来のデータスタック、現代のデータスタック、データファーストスタック。これがどのように機能したか見てみましょう。
進化的基本原則:データランドスケープを変化させたパターン
進化には2つの大きなパターンがあります:分岐進化と収束進化。これらの大きなパターンは、データランドスケープにも当てはまります。
地球上の生物種の多様性は、分岐進化の結果です。同様に、分岐進化により、MADランドスケープとして知られるデータ業界の幅広いツールとサービスの範囲が生まれます。収束進化により、共通の特徴を持つツールのバリアントが時間をかけて作られます。たとえば、ネズミとトラは非常に異なる動物ですが、両方には髭、毛皮、四肢、尾などの類似点があります。
収束進化は、ツールの共通な分母を生み出し、ユーザーは冗長な機能のために費用を支払います。分岐進化は、さらに高い統合コストが発生し、各ツールの独自の哲学を理解し、維持するための専門家が必要です。
共通の分母があるということは、ポイントソリューションが統一されたソリューションに向かって収束しているわけではないことに注意してください。代わりに、各ポイントは需要に基づいて他のポイントの他のソリューションと交差するソリューションを開発しています。これらの共通の機能には、別々の言語と哲学があり、ニッチな専門家が必要です。
たとえば、ImmutaとAtlanは、それぞれデータガバナンスとカタログのソリューションです。ただし、Immutaはデータカタログも開発しており、Atlanはガバナンス機能を追加しています。顧客は、二次的な機能をそれらに特化したツールで置き換える傾向があります。これにより、以下のことが発生します。
- 各製品の言語と哲学を理解するために投資された時間
- 似たようなオファリングを持つ2つのツールをオンボードする冗長なコスト
- ニッチな専門家の高いリソースコスト。良い人材が不足しているため、さらに困難です
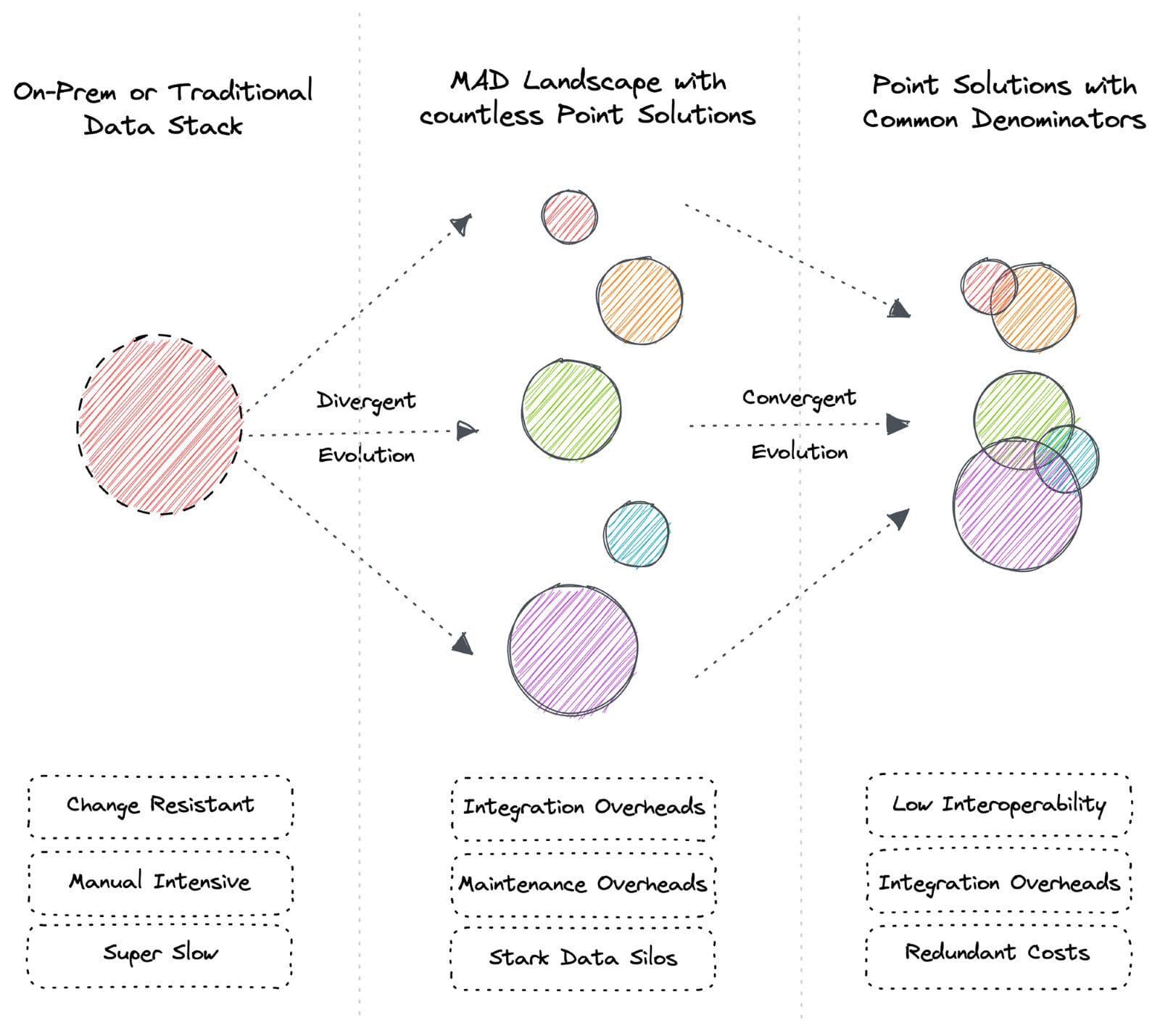
進化のパターンの高レベルな理解ができたので、データドメインでどのように表れるかを見てみましょう。簡潔さのためにあまり遡りません。
数年前に巻き戻す
今日のデータ業界が抱える問題は、5〜6年前とは大きく異なりました。当時、組織が直面した主な課題は、オンプレミスシステムからクラウドへの大規模な移行でした。オンプレミスのビッグデータエコシステムやSQLウェアハウス(または従来のデータスタック、TDSとも呼ばれます)は、非常に低いアップタイムで維持するのも困難で、データからインサイトまでの旅程も非常に遅くなっていました。要するに、スケールと効率は、特に以下の障壁のために遥かに手の届かないところにありました。
データエンジニアの軍隊
社内システムのメンテナンスには、どれだけ多くのデータエンジニアがいても足りませんでした。データウェアハウスやETLからダッシュボードやBIワークフローまで、すべて社内でエンジニアリングする必要があり、組織のほとんどのリソースが収益を生む活動ではなく、構築とメンテナンスに費やされました。
パイプラインの圧倒
データパイプラインは複雑で相互に関連し、新しいビジネスニーズに対応するために多数作成されたものが多くありました。時には、単一の質問に答えるために新しいパイプラインが必要であったり、少数のソーステーブルから多数のデータウェアハウステーブルを作成するために新しいパイプラインが必要であったりしました。この複雑さは圧倒的で、管理が困難でした。
ゼロフォルトトレランス
バックアップ、リカバリー、またはRCAなしでは、データは安全でも信頼できませんでした。データ品質とガバナンスは後のことで、パイプライン活動の重荷の下で苦労するエンジニアの仕事の範囲を超えることがありました。
データ移動のコスト
レガシーシステム間での大規模なデータ移行は別の赤信号であり、膨大なリソースと時間を費やしました。さらに、破損したデータや形式の問題が発生し、解決に別の数ヶ月かかったり、廃棄されたりしました。
変更に対する抵抗力
オンプレミスシステムのパイプラインは非常に壊れやすく、頻繁な変更や全くの変更に対して抵抗力があり、動的かつ変化に対応するデータ操作にとっては災害となり、実験のコストがかかります。
過酷なペース
新しいパイプラインを展開するために数ヶ月、数年が費やされ、一般的なビジネスの質問に答えるために使用されました。動的なビジネス要求は問題外でした。高頻度のダウンタイム中にアクティブビジネスを失うことを忘れてはなりません。
スキル不足
高い借金またはクラフトは、重要な依存関係のためにプロジェクトのハンドオフに抵抗力を生じさせました。市場で必要な適切なスキルが不足していたため、重要なパイプラインのために重複したトラックが数ヶ月にわたって起こりました。
当時のソリューションとその結果生じた問題
クラウドの出現とクラウドネイティブになる義務
10年前、データは今ほどの資産としては見られていませんでした。特に、組織に十分な量のデータがなかったため、1つの動作ダッシュボードを生成するために無数の問題に対処する必要がありました。しかし、時間の経過とともに、プロセスと組織がよりデジタルでデータフレンドリーになるにつれて、データの生成とキャプチャの急激な指数関数的な増加が起こりました。
組織は、容量を超えるような大量の歴史的なパターンを理解することによって、プロセスを改善できることに気付きました。TDSの持続的な問題に対処し、データアプリケーションを強化するために、複数のポイントソリューションが登場し、中央データレイクに統合されました。これをモダンデータスタック(MDS)と呼びました。それは、当時のデータ業界の問題に対してほぼ完璧なソリューションであることは疑いようがありませんでした。
➡️ モダンデータスタック(MDS)への移行
MDSは、当時のデータランドスケープのいくつかの持続的な問題に対処しました。その最大の成果は、データをよりアクセス可能にするだけでなく、回復可能にするクラウドへの革命的なシフトであったと言えるでしょう。Snowflake、Databricks、Redshiftなどのソリューションは、大規模な組織がデータをクラウドに移行し、信頼性と耐久性を高めるのに役立ちました。
予算制約を含むさまざまな理由でTDSに肯定的だったデータリーダーたちは、他の組織での成功した移行を見て、クラウドに移行して競争力を維持することを義務づけられました。これには、CFOを説得して優先順位を設定し、将来の価値を約束することによって達成されました。
しかし、クラウドネイティブになることは、単にクラウドに移行することで終わったわけではありません。本当にクラウドネイティブになるためには、クラウド内でデータを操作するためのソリューションプールを統合する必要がありました。計画は良さそうでしたが、MDSはすべてのデータを中央レイクにダンプしてしまい、業界全体で管理不能なデータスワンプを引き起こしました。
💰 幻の約束に投資する
- クラウドへの大規模なデータアセットの移行コスト
- クラウドの稼働コスト
- クラウドを操作するために必要なポイントソリューションの個別ライセンスコスト
- ポイントソリューション間の共通または冗長な分母のコスト
- 各ツールの異なる哲学を理解するための認知負荷とニッチな専門知識のコスト
- 新しいツールがエコシステムに参加するたびに継続的な統合のコスト
- 継続的な統合のメンテナンスコスト、およびそれによるパイプラインの洪水のコスト
- ポイントソリューションを操作するためのデータ設計インフラストラクチャのセットアップコスト
- インフラストラクチャを稼働させ続けるための専用プラットフォームチームのコスト
- データスワンプ内の100%のデータの保存、移動、および計算のコスト
- 各露出または統合ポイントごとの孤立したガバナンスのコスト
- 複数の露出ポイントによる頻繁なデータリスクのコスト
- 頻繁なプロジェクトハンドオフ中の複雑な依存関係の非複雑化のコスト
想像できるように、このリストはかなり網羅的ではありません。
🔄 データROIの悪循環
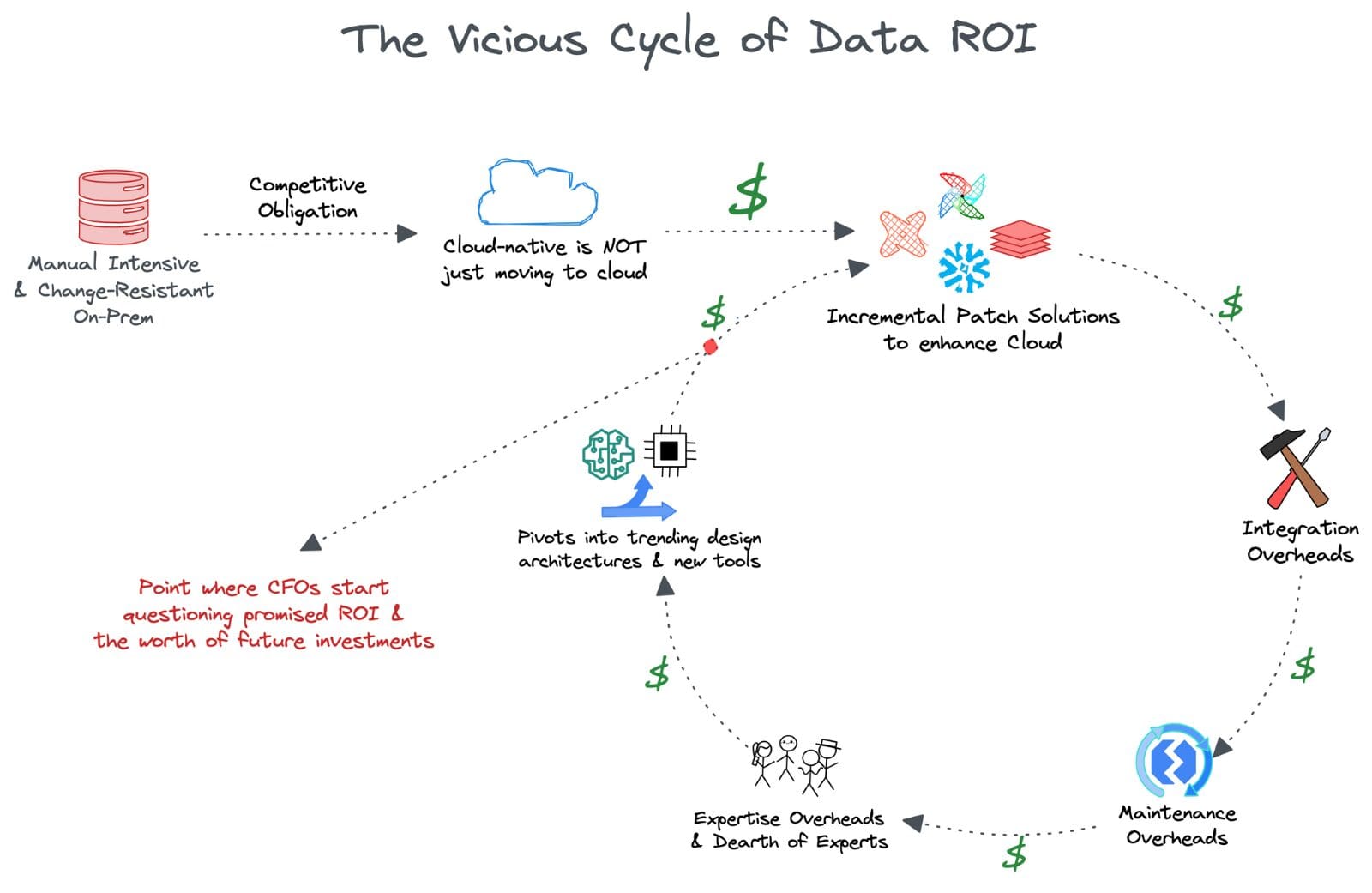
データリーダー、CDO、CTOを含む人々は、数百万ドルの規模の投資に対する未実現の約束の重荷を感じ始めました。増分のパッチソリューションは、解決した問題と同じ数の問題を作り出し、データチームは所有する豊富なデータを使用できないという基本的な問題に戻りました。
将来に対する保障がないことは、リーダーにとって重大なリスクであり、彼らの組織内での在任期間が24か月未満に短縮されています。CFOがリターンを見るために、彼らはトレンドのデータ設計アーキテクチャや新しいツールイノベーションに注目し、新しい約束を展開しました。
この時点で、CFOのオフィスは、約束された結果の信頼性について疑問を持ち始めました。さらに危険なことに、彼らはデータ中心の垂直に投資する価値自体を疑問視し始めました。他の運用に数百万ドルを費やした方が、5年以内にはより良い影響をもたらしたのではないでしょうか?
上記で議論した実際のソリューションに少し深く掘り下げると、隠れた予期しないコストにより、データ投資が何年にもわたって錆びついてしまったことがよくわかります。
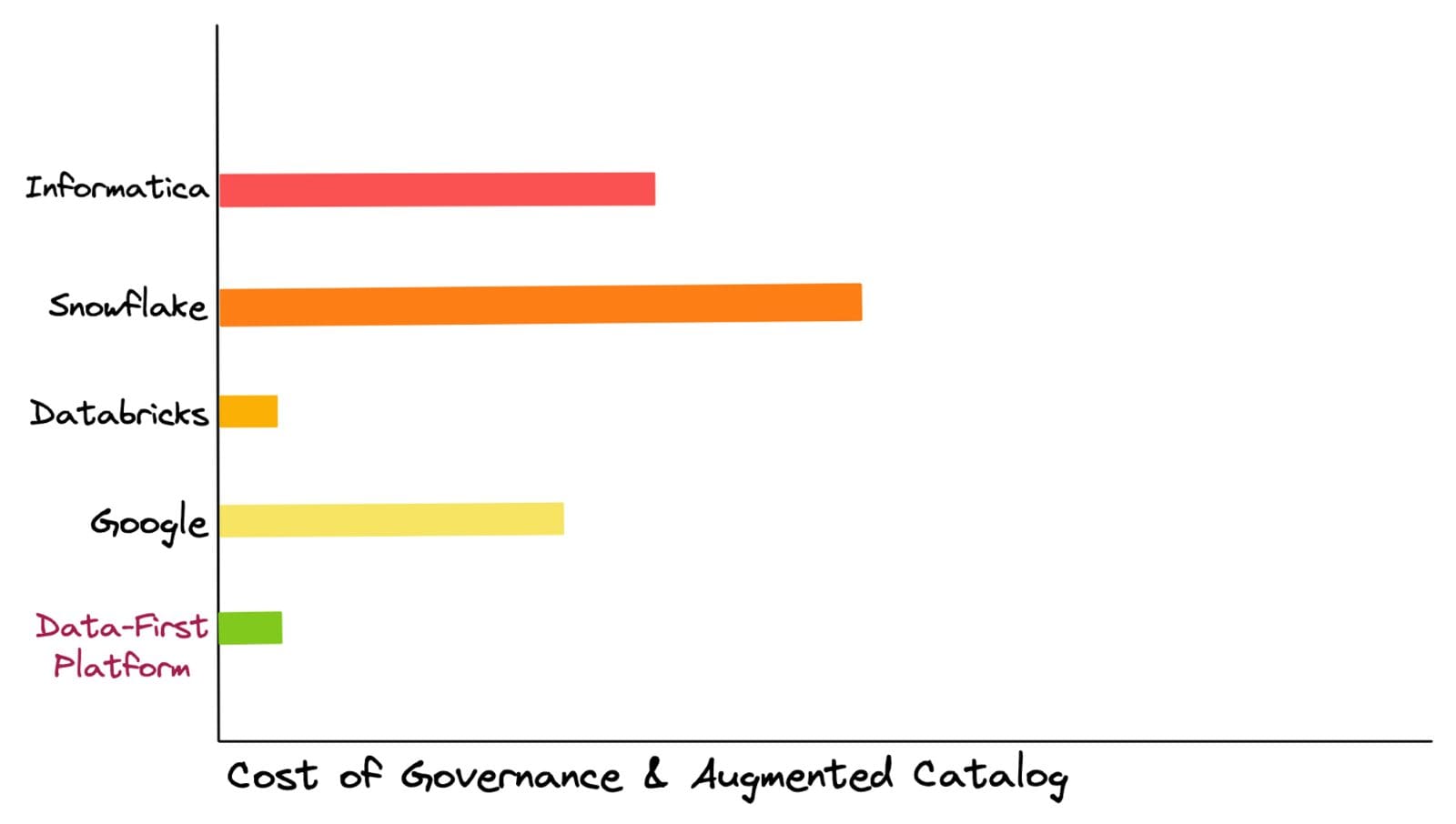
TCOの見積もりは、ニッチな専門家のコスト、移行、セットアップ、固定ワークロードを管理するための計算、ストレージ、ライセンス料金、ガバナンス、カタログ化、BIツールなどのポイントソリューションの累積コストに基づいて行われます。これらのベンダーとの顧客の経験に基づいて、これらのプラットフォームを使用する際に予期しないコストの跳躍が発生することがよくあるため、上部に市松模様のバーが追加されています。
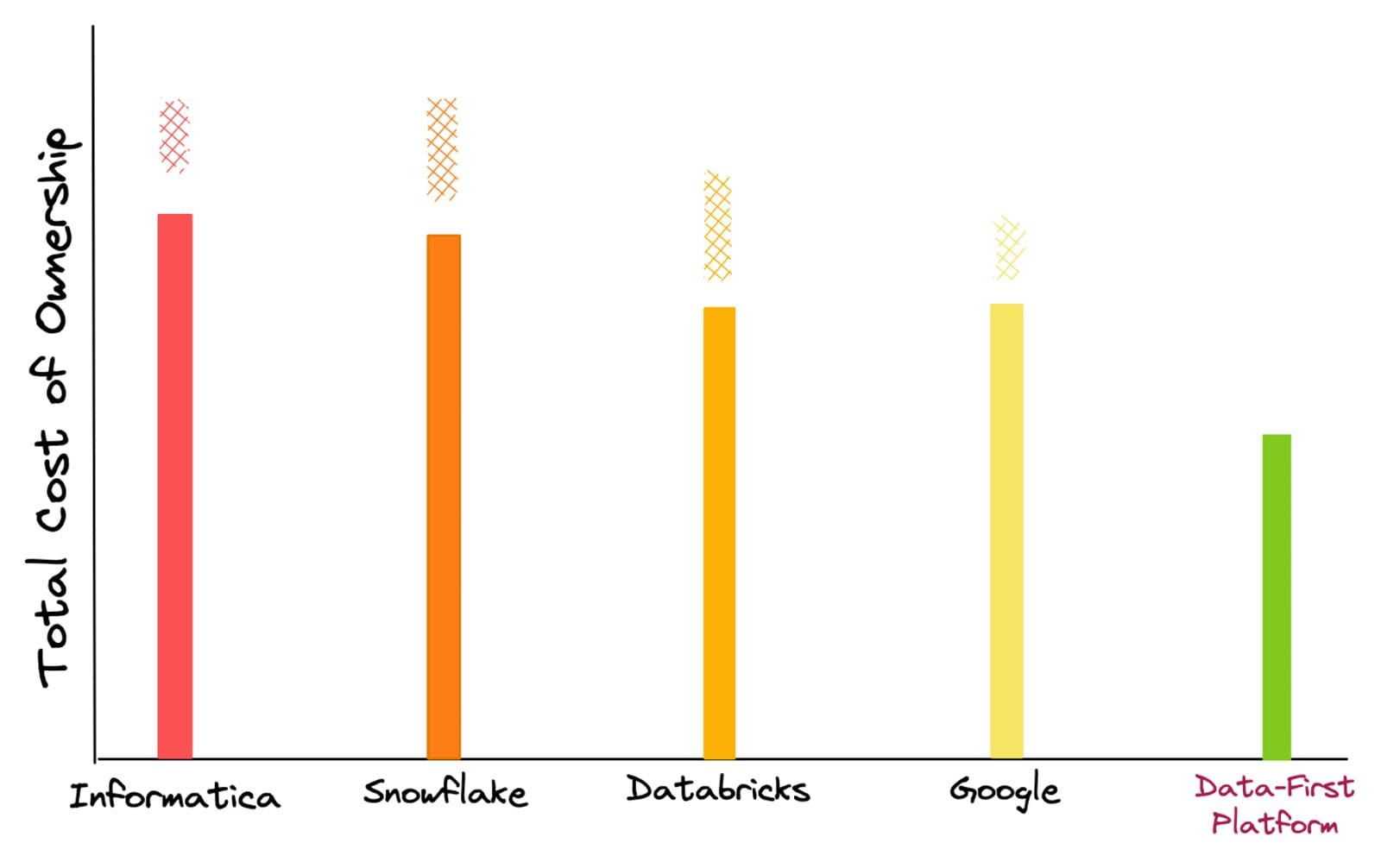
これらのコストは多様であり、ワークロードの増加や価格モデルそのものへのバックグラウンドクエリなど、最も謎めいたコストと分類されます。一方、ツーリングの複雑さを抽象化するデータファーストアプローチでは、TCOの予期しないジャンプはありません。すべてのワークロードに提供されるコンピュートと使用されるストレージに完全に制御があります。
💣 ツーリングの大量増殖により、すべてのスタックがメンテナンスファーストであり、データラストになりました。
MADランドスケープまたはMDSに示されるように、豊富なツールを持っているため、組織がビジネス結果をもたらす解決策開発に焦点を合わせることがますます困難になっています。
貧弱なデータエンジニアは、メンテナンスファースト、統合セカンド、そしてデータラストの経済に陥っています。これには、インフラストラクチャの欠点を解決するために費やされた数え切れない時間が含まれます。複数のツールをホストして統合するために必要なインフラストラクチャも同様に苦痛です。
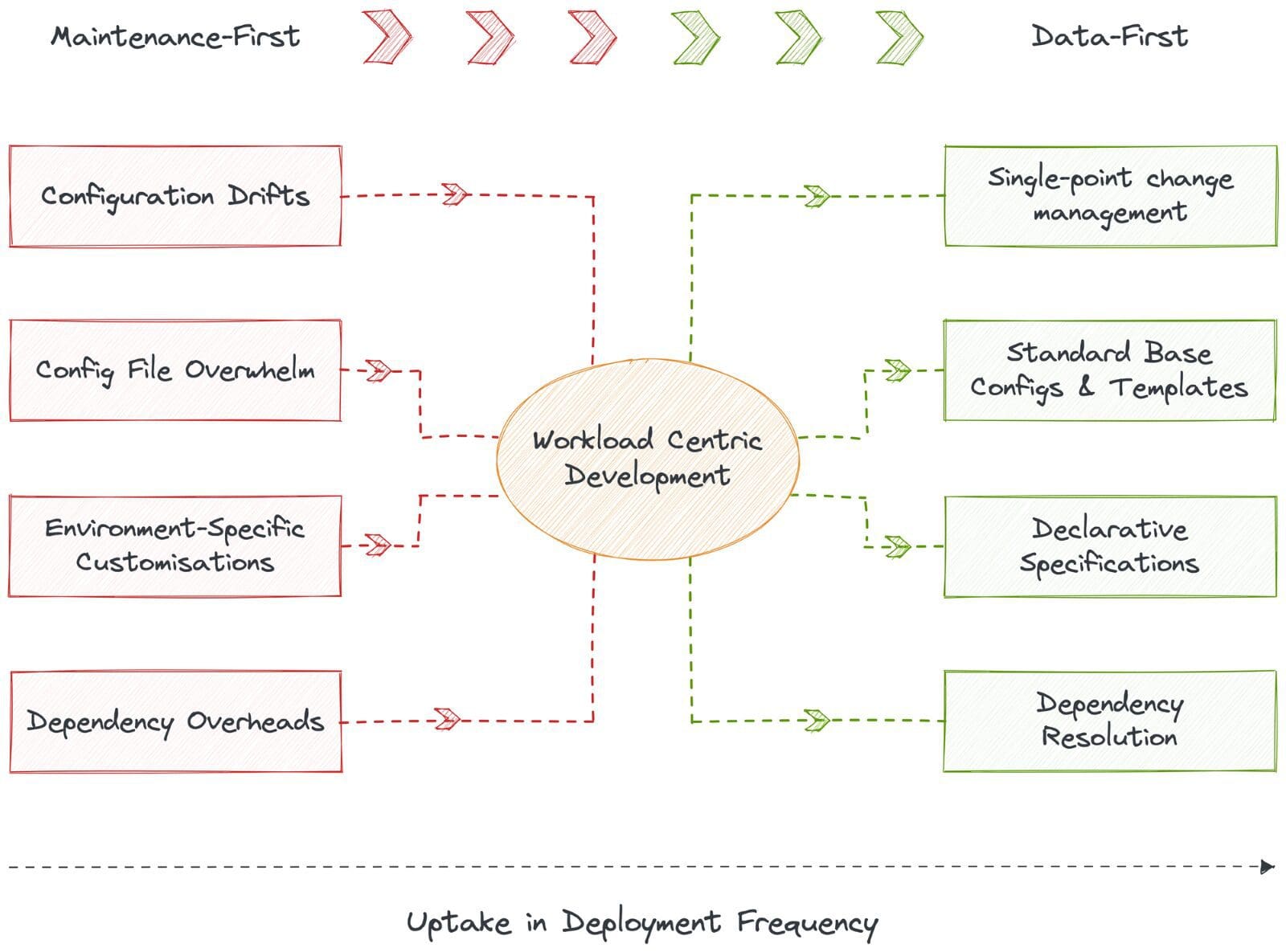
データエンジニアは、構成ファイルの膨大な数、頻繁な構成の漂流、各ファイルの環境固有のカスタマイズ、および数え切れない依存関係のオーバーヘッドに圧倒されています。つまり、データエンジニアは、データインフラがアップタイムSLOに一致するようにするために、眠れない夜を過ごしています。
ツーリングの圧倒感は、時間と労力の面で高価だけでなく、統合とメンテナンスのオーバーヘッドが、ビジネスドライブのデータアプリケーションの直接的な改善を可能にせず、文字通りのコストに影響を与えます。
ここに、従来のETLおよびELT方法を介した企業データ移動の表現があります。バッチおよびストリーミングデータソースの両方を統合し、データワークフローをオーケストレーションするコストが含まれます。
年々のコスト増加は、企業が時間とともにプラットフォームの使用量を増やし、統合されたソースシステムの数とその後のデータ処理を実行することを前提としています。
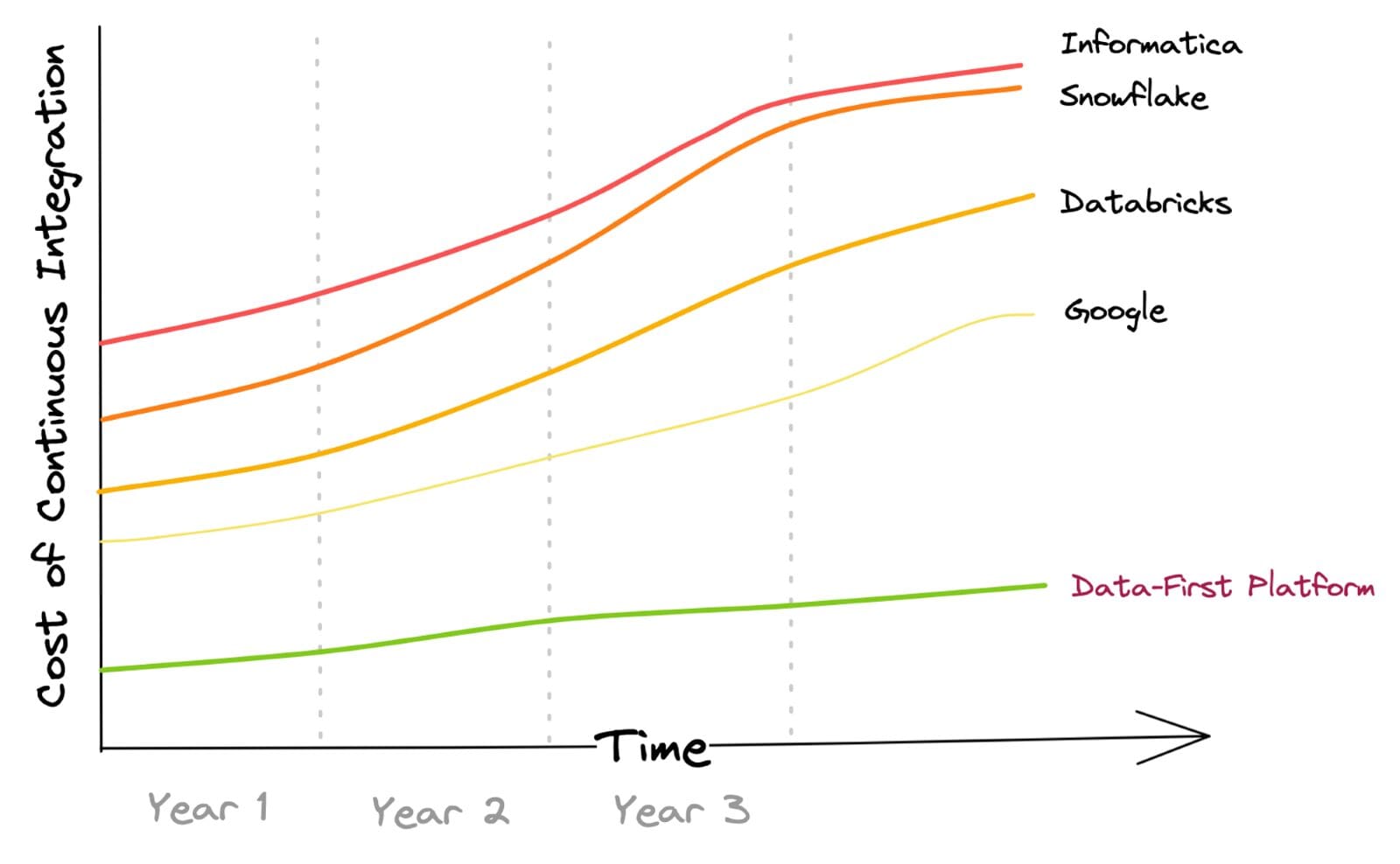
これは、ほとんどの顧客がベンダー全体で当てはまることが判明しました。データファーストアプローチでは、インテリジェントデータムーブメントと抽象化された統合管理を信じているため、データ統合コストはゼロから最小限に抑えられます。
🚧 組織はツールの哲学に従うことを義務付けられています。
異なるソリューションの束を管理することは終わりではありません。組織は、これらの個々のツールの事前定義された方向性や哲学に従わなければなりません。たとえば、ガバナンスツールがオンボードされた場合、データ開発者は、そのツールを操作する方法を学び、他のツールとの特定のやりとり方法を学び、他のツールを新しいコンポーネントの仕様に合わせて再配置します。
各ツールは、独自の哲学の結果として、設計アーキテクチャに影響を与えるため、相互運用性ははるかに複雑で選択的になります。柔軟性の欠如も、メッシュやファブリックなどの新しい革新的なインフラストラクチャデザインに移行するためのコストが高い理由の1つです。これらのデザインは、約束されたROIを高める可能性があります。
独自の哲学を持つ豊富なツールは、熟練したデータエンジニアが多数必要です。実際的には、多数のデータエンジニアを採用、育成、維持、協力することは不可能です。特に、この分野に熟練した経験豊富な専門家が不足していることが更にそのような状況を悪化させます。
🧩 アトミックインサイトをキャプチャーおよびオペレーショナル化できない
豊富なツールと統合の結果、堅牢なインフラストラクチャができあがり、アトミックデータバイトを適切な顧客フェーシングエンドポイントに正確にチャネルするための柔軟性が低下しました。アトミック性の欠如は、相互運用性が低く、お互いに話すための確立されたルートを持っていない孤立したサブシステムの結果でもあります。
良い例は、各ポイントツールが個別のメタデータエンジンを維持してメタデータをオペレーショナル化することです。メタデータエンジンには別々の言語と転送チャネルがあり、特別に設計されない限り、ほとんどお互いに通信することができません。これらの新しく設計されたチャネルは、メンテナンスタブにも追加されます。使用データは翻訳で失われ、並列の垂直線はお互いから引き出された洞察を活用することができません。
さらに、MDSでのデータオペレーションは、MDSの混沌の広がりにソフトウェア的なプラクティスを強制することができないため、バッチで開発、コミット、およびデプロイされることがよくあります。実際的には、データスタックの唯一の非決定論的なコンポーネントであるデータが、データシロやデータコードシロの排除だけでなく、アトミックコミット、変更ラインに沿った垂直テスト、およびCI/CD原則を強制する統一されたティアに差し込まれない限り、DataOpsは実現できません。
MDSの結果として現れた問題に対処するために出現した解決策
従来のデータスタックからモダンデータスタック、最終的にはData-First Stack(DFS)への移行は、ほとんど避けられませんでした。DFSの要件は、データエンジニアリングの領域内に蓄積されたテックデット(技術的負債)の膨大な量によって引き起こされました。DFSは、パッチワーク哲学を提唱するのではなく、TDSとMDS全体の弱点をターゲットにした統一アプローチまたはアンブレラソリューションを提供しました。
DFSはビジネスチームに自己サービスの機能をもたらしました。彼らはITリソースを争う代わりに、自分たちのコンピューティングリソースを持ち込むことができます(多くの企業では、これがデータへのビジネスチームのアクセスを大幅に制限しています)。DFSにより、パートナーとのデータ共有やコンプライアンスに基づく収益化が容易になりました。散りばめられた数百のソリューションを統合することに苦労する代わりに、ユーザーはデータを最優先にし、ビジネスアウトカムを直接向上させることに集中することができます。
資源コストの削減は、現在の市場において組織の優先事項の1つであり、複数のポイントソリューションの散在する風景を統治し分類する場合、コンプライアンスコストが非常に高いため、ほぼ不可能です。DFSの統合インフラストラクチャは、これらのポイント機能を基本的なビルディングブロックに構成し、これらのブロックを中央で管理することにより、発見性と透明性を瞬時に改善し、これらのコストを削減します。
DFSのカタログソリューションは包括的であり、そのデータディスカバリ&オブザーバビリティ機能には、アクティブなメタデータ管理を可能にするネイティブガバナンスと豊富な意味的知識が組み込まれています。それに加えて、データインフラストラクチャのすべてのアプリケーション&サービスに対する完全なアクセス制御を可能にします。
Data-First Stackは、エンドユーザーがアウトカムに沿った体験を持つために必要なすべてのプログラムを管理するプログラムである(オペレーティングシステム)です。私たちの多くは、ラップトップ、電話、実際にはインターフェース駆動のデバイス上のOSに経験があります。私たちはこれらのシステムにフックされているので、日々のアプリケーションの低レベルのニュアンスを起動、維持、実行する痛みから抽象化されています。代わりに、私たちはそのようなアプリケーションを直接使用してアウトカムを駆動します。
データオペレーティングシステム(DataOS)は、データを理解し、データインフラストラクチャを構築するのではなく、データのユーザーである組織でなければならないことを理解するデータスタックです。 DataOSは、それ以外の場合、データ開発者のアクティブな時間の大部分を吸い取る低レベルデータ管理のすべてのニュアンスを抽象化します。
🥇 メンテナンスファーストからデータファーストへの移行
データオペレーティングシステム(DataOS)は、データを最優先にし、組織がデータのユーザーである必要があることを理解しています。DataOSは、低レベルデータ管理のすべてのニュアンスを抽象化し、データ開発者のアクティブな時間の大部分を取られることを防ぎます。
デクラレーティブに管理されたシステムは、壊れやすさの範囲を大幅に排除し、必要に応じてRCAレンズを表面化し、リソースとROIを最適化します。これにより、エンジニアリングの才能をデータに費やし、ビジネスに直接影響を与えるデータアプリケーションを構築することができます。
データ開発者は、環境固有の変数を必要としない標準ベースの構成を介して、構成のドリフトと膨大な数の構成ファイルを排除することで、ワークロードを迅速に展開できます。システムはアプリケーションのマニフェストファイルを自動生成し、CRUD操作、実行、およびメタストレージを提供します。つまり、DataOSは、データ開発者がワークロード要件を宣言し、DataOSがリソースを提供し、依存関係を解決するワークロード中心の開発を提供します。その結果、展開頻度が可視化され、即座に実現されます。
💠 統合アーキテクチャへの収束
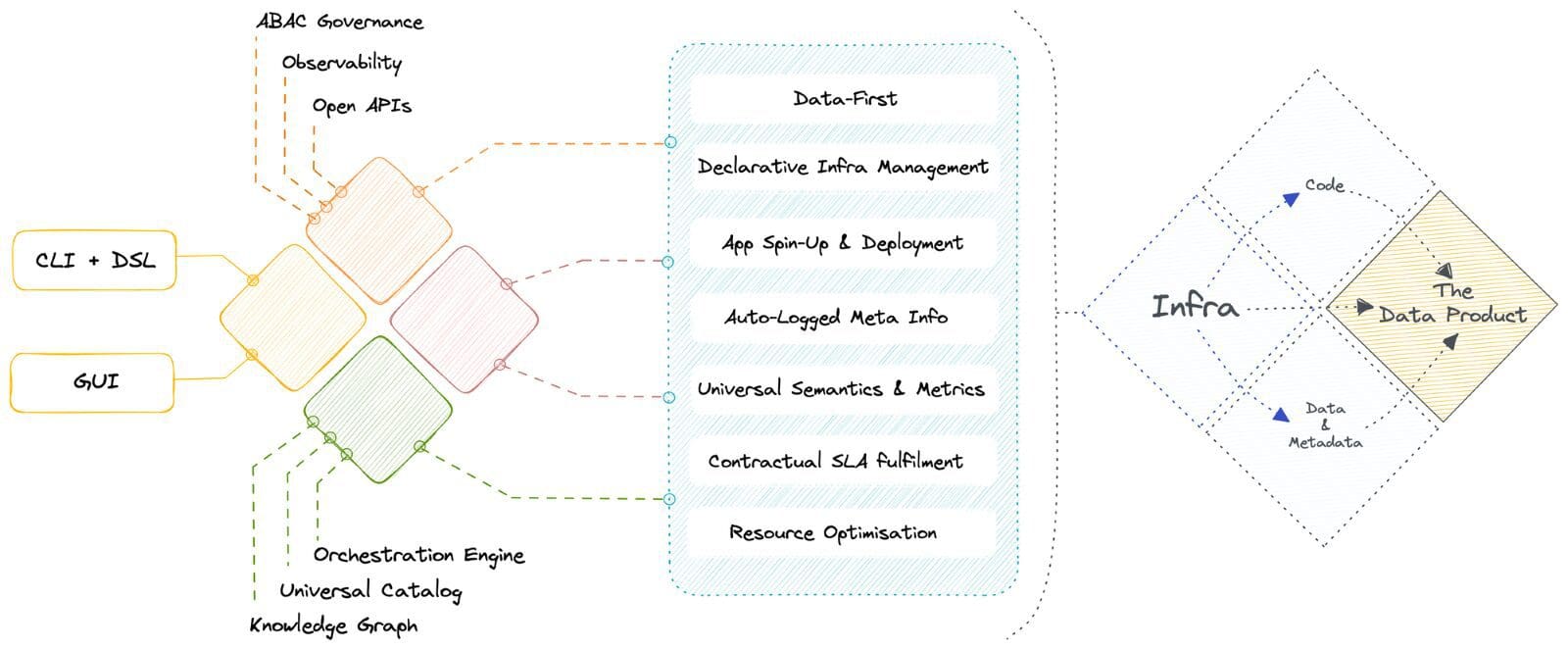
🧱 パッチワークソリューションから原始的なビルディングブロックへの移行
コンポーザブルなデータオペレーティングシステムアーキテクチャの高い内部品質により、わずか数週間でデータファーストを実現できます。モジュール化により、データスタックの基本形であると特定された有限のプリミティブセットを使用してモジュール化が可能です。これらのプリミティブは、高次のコンポーネントやアプリケーションを構築するために特定に配置できます。
これらはアーティファクトとして扱われ、バージョン管理システムを使用してソースコントロールおよび管理できます。各プリミティブは、目標や成果を宣言的な方法で列挙できる抽象化と見なせます。これにより、「どのようにしてこれらの成果に到達するか」を定義する煩雑なプロセスを代替できます。
🦾 宣言的管理のための既存ツールの統合
DataOSは、オープンスタンダードでアーティファクトファーストであるため、既存のデータインフラストラクチャの上にアーキテクチャレイヤーとして使用されます。これにより、組織は既存のシステムを完全にオーバーホールすることなく、新しい革新的なテクノロジを既存のデータインフラストラクチャに統合できます。
これは、開発者がAPIおよびCLIを介してリソースを宣言的に管理するための完全なセルフサービスインターフェースであり、ビジネスユーザーは、直感的なGUIを介してビジネスロジックをデータモデルに直接統合し、自己サービスを取得できます。 GUIインターフェイスは、開発者がリソースの割り当てを視覚化し、リソース管理を簡素化することもできます。これにより、技術的な知識がなくても開発者が簡単にリソースを管理できるため、時間が大幅に短縮され、生産性が向上します。
☀️ 中央のガバナンス、オーケストレーション、およびメタデータ管理
DataOSは、コントロールが垂直コンポーネントの中央集権管理と1つ以上のデータ平面の間で分岐するデュアルプレーン概念アーキテクチャで動作します。
ユーザーは、クラウドネイティブ環境のさまざまなタッチポイントの基于ポリシーおよび目的駆動型アクセス制御を中央管理し、データワークロードをオーケストレーションし、コンピュートクラスタのライフサイクル管理、DataOSリソースのバージョン管理、およびさまざまなタイプのデータアセットのメタデータを管理できます。
⚛️ 実証ユースケースのためのアトミックインサイト
業界は急速にトランザクションから実証的ユースケースに移行しています。長期間のバッチで大きなデータブロックから描かれたビッグバンインサイトは、今では二次的な要件です。ポイントデータから推測されるアトミックまたはバイトサイズのインサイトは、リアルタイムに近い速度で、顧客はそれに十分な価値を見出しています。
共通の基本レイヤーのプリミティブにより、データは統合アーキテクチャのすべてのタッチポイントで見え、ビジネスユースケースが要求するときに意味論的抽象化を介して任意のチャネルに具現化できます。
Animesh Kumarは、Chief Technology Officer&Co-Founder @Modern、およびData Operating System Infrastructure Specificationの共同作成者です。30年以上にわたるデータエンジニアリングの分野で、NFL、GAP、Verizon、Rediff、Reliance、SGWS、Gensler、TOIなど、さまざまなA-Player向けのエンジニアリングソリューションを設計してきました。
Srujanは、CEO&Co-Founder @Modernです。30年以上のデータとエンジニアリングの分野で、モトローラ、TeleNav、Doot、Personagraphなどの組織で複数の受賞製品のローンチに積極的に関わってきました。
トラビス・トンプソン(共著者):トラビスはデータ・オペレーティング・システム・インフラストラクチャー仕様の主任アーキテクトです。30年にわたってデータとエンジニアリング全般に取り組んできた彼は、GAP、Iterative、MuleSoft、HPなどのトップ組織に最先端のアーキテクチャーとソリューションを設計しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
