マルチモーダルインタラクティブエージェントの評価
Evaluation of Multimodal Interactive Agents.
人間との相互作用をうまく行うエージェントを訓練するためには、進歩を測定できるようにする必要があります。しかし、人間との相互作用は複雑であり、進歩を測定することは困難です。本研究では、時間的に拡張された多様な相互作用を評価するための手法である「Standardised Test Suite (STS)」を開発しました。我々は、3Dシミュレート環境でのタスク実行と質問に対するエージェントへの人間の参加による相互作用を調査しました。
STSの手法では、エージェントを実際の人間の相互作用データから抽出した一連の行動シナリオに配置します。エージェントは再生されたシナリオの文脈を見て、指示を受け取り、その後、オフラインで相互作用を完了するための制御を与えられます。これらのエージェントの継続は記録され、その後、人間の評価者によって成功または失敗として注釈が付けられます。エージェントは、成功したシナリオの割合に基づいて順位付けされます。
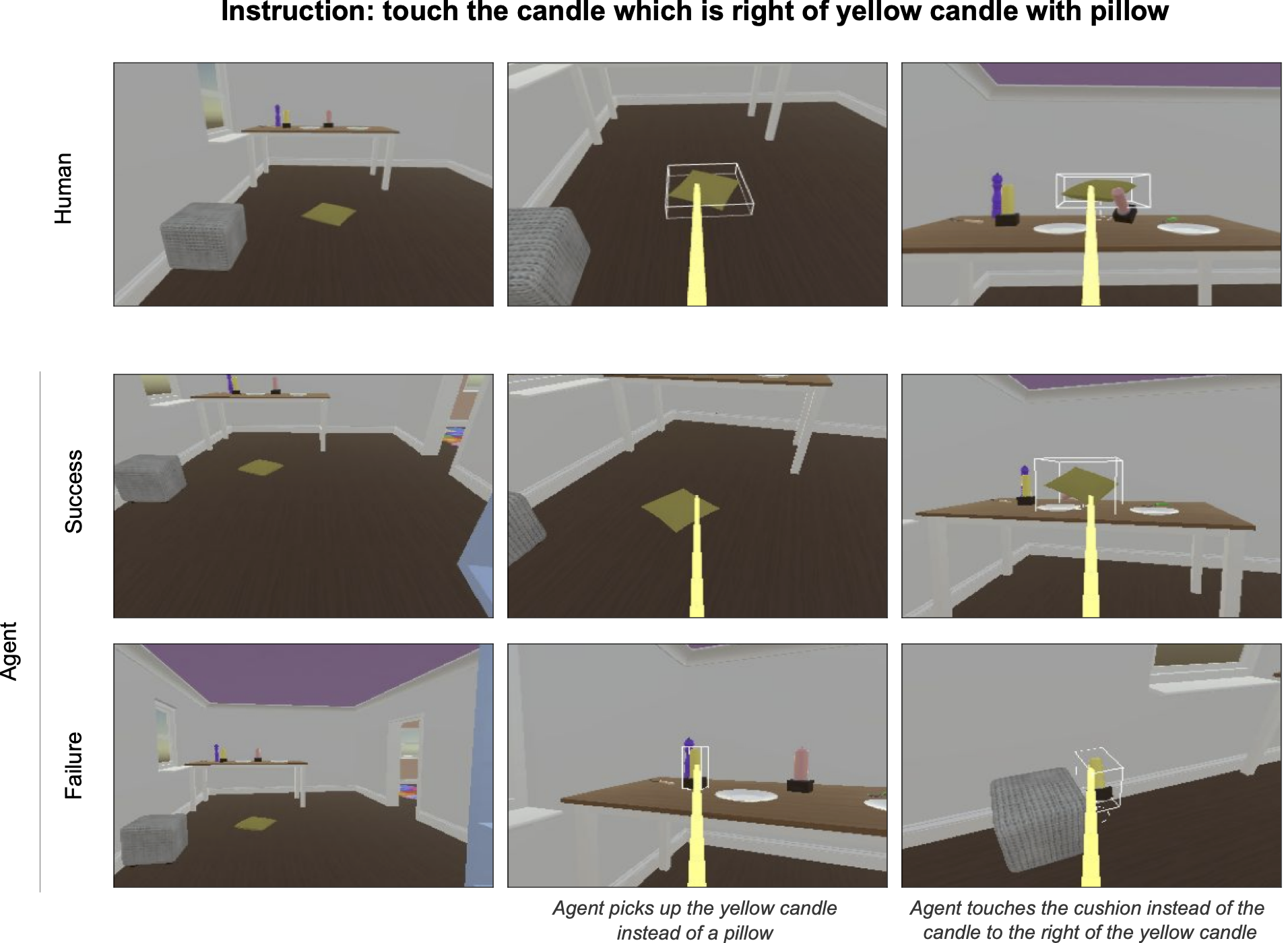
私たちの日常の相互作用において人間にとって当たり前の行動の多くは、言葉にすることが難しく、形式化することは不可能です。したがって、強化学習によるゲーム(Atari、Go、DotA、およびStarcraftなど)の解決に頼るメカニズムは、エージェントに流暢で成功した相互作用を持たせることを試みる際には機能しません。例えば、次の2つの質問の違いについて考えてみてください。「この囲碁の対局は誰が勝ちましたか?」と「何を見ているんですか?」。最初の場合、ゲームの終わりにボード上の石を数え、確定的に勝者を決定するコンピュータコードを書くことができます。しかし、2番目の場合、これをコード化する方法はわかりません。答えは話者に依存するかもしれませんし、関連するオブジェクトのサイズや形状、話者が冗談を言っているかどうか、発話が行われる文脈の他の側面などに依存する可能性があります。人間は、このささいな質問に答えるために関連する多くの要素を直感的に理解しています。
人間の参加によるインタラクティブな評価は、エージェントのパフォーマンスを理解するための基準となりますが、これはノイズが多くコストもかかります。評価時に人間がエージェントに与える正確な指示を制御することは困難です。この評価はリアルタイムで行われるため、進捗に頼るには速すぎます。以前の研究では、インタラクティブな評価のためにプロキシを使用してきました。プロキシは、損失やスクリプトによるプローブタスク(例えば「xを持ち上げる」で、xは環境からランダムに選択され、成功関数が手間暇をかけて手作りされたもの)などの形で使用され、エージェントについての洞察を迅速に得るのに役立ちますが、実際のインタラクティブな評価とはあまり相関しません。私たちの新しい手法は、主に制御と速度を提供し、究極の目標である人間との良好な相互作用を実現するために密接に合致するメトリックを持つ利点があります。
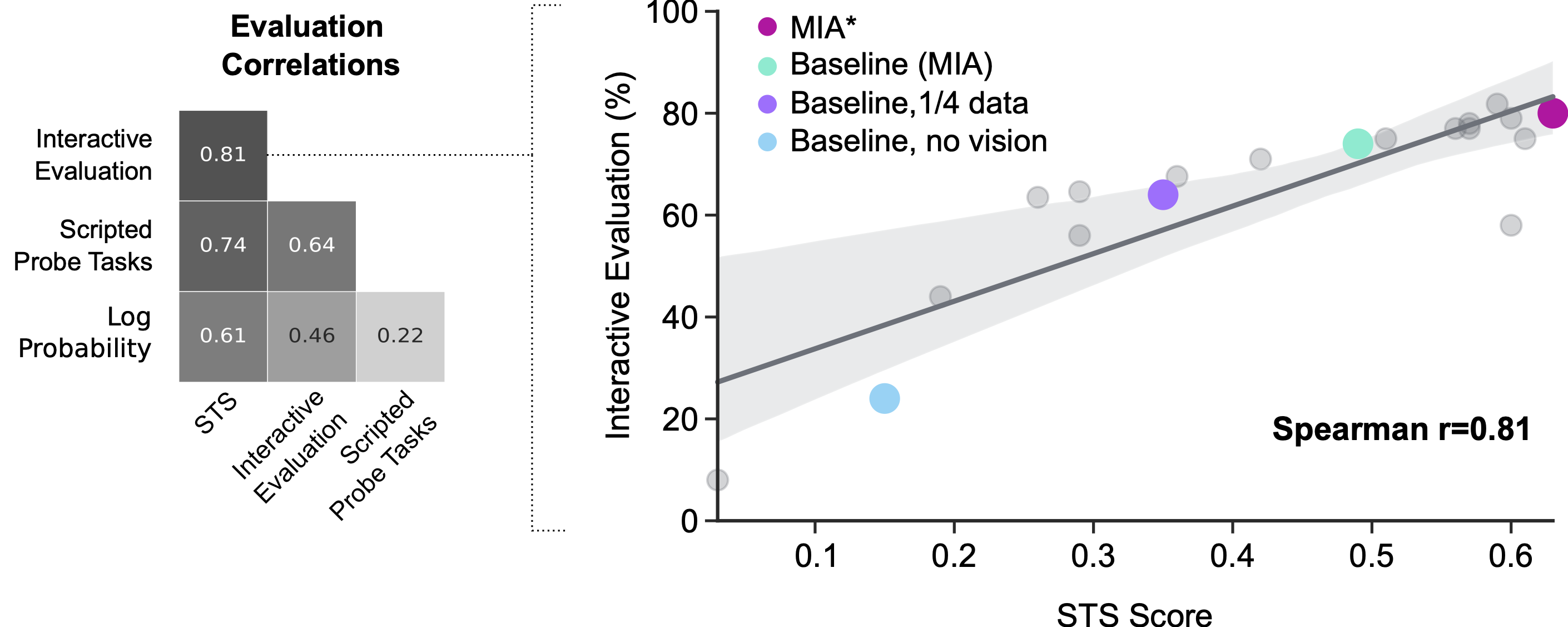
MNIST、ImageNetなどの人間による注釈付きデータセットの開発は、機械学習の進歩に不可欠です。これらのデータセットにより、研究者は分類モデルを訓練および評価するために一度だけ人間の入力コストをかけることができました。STSの手法は、人間-エージェントの相互作用研究において同様のことを目指しています。この評価方法では、引き続き人間がエージェントの継続を注釈付けする必要がありますが、初期の実験ではこれらの注釈の自動化が可能な場合があると示唆されており、これによりインタラクティブなエージェントの迅速かつ効果的な自動評価が可能になる可能性があります。一方で、私たちは他の研究者がこの方法論とシステム設計を利用して、この領域での研究を加速させることを望んでいます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






