「ウィーンのオープンデータポータルを利用した都市緑地の平等性の評価」
Evaluation of equity in urban green spaces using the Vienna Open Data Portal
多くの利点を持つにもかかわらず、都市化の進んだ地域では自然や緑地へのアクセスがますます困難になっています。一部の人々は、支援を必要とするコミュニティがこれらの問題により多くさらされていると心配しています。ここでは、この問題を探求するためのデータ駆動型の方法を提案します。
特に、最近専門家や地方自治体の間で関心を集めている都市開発の問題を提起します — 「グリーンイクオリティ」です。この概念は、特定の都市の異なる地域で人々が緑地にアクセスする際の格差を指します。ここでは、財務の側面を探求し、人口当たりの利用可能な緑地と同じ都市単位の経済水準との間に明確な関係があるかどうかを調べます。
私はオーストリア政府のオープンデータポータルで提供されているEsri Shapefileを使用して、都市の2つの異なる空間分解能(地区および国勢調査地区)を探求します。また、人口と所得の統計データ(人口および所得)をジオリファレンスされた行政地域に組み込みます。その後、行政地域に公式の緑地データセットを重ね合わせ、各都市地区の人口当たりの総緑地面積を数量化します。最後に、各地域の財務状況(年間純収入によって捉えられる)と人口当たりの緑地面積の比を関連付け、どのようなパターンが現れるかを調べます。
1. データソース
オーストリア政府のオープンデータポータルをご覧ください。
この記事を執筆しているときには、ウェブサイトの英語訳がうまく機能していなかったため、私は長い間忘れられていた12年間のドイツ語の授業に頼る代わりに、DeepLを使用してさまざまなサブページや数千のデータセットを探索しました。
- 「VoAGI調査:データサイエンスの支出とトレンド2023 H2における同業他社とのベンチマーク」
- 「PyGraftに会ってください:高度にカスタマイズされた、ドメインに依存しないスキーマと知識グラフを生成する、オープンソースのPythonベースのAIツール」
- 「コンピュータビジョンと言語モデルが見たものを理解する手助け」
そして、後の分析に使用するいくつかのデータファイル(ジオリファレンスされたEsri shapefileと単純な表形式のデータ)を収集しました。収集したデータは以下の通りです。
境界 — ウィーンの以下の空間単位の行政境界に関する情報:
- ウィーンの行政境界
- ウィーンの23の地区の行政境界
- ウィーンの250の国勢調査地区の行政境界
土地利用 — 緑地および建物の位置に関する情報:
- ウィーン市の緑地ベルトの可視化によるウィーン市全体の既存および指定された緑地エリアを囲む1539のジオスペーシャルポリゴンファイル
統計 — エリアの社会経済レベルに対応する人口および所得に関するデータ:
- ウィーンの地区ごとの人口、2002年以降毎年記録され、5年ごとの年齢層、性別、国籍ごとに分割されて格納されています
- ウィーンの国勢調査地区ごとの人口、2008年以降毎年記録され、不規則な3つの年齢層、性別、出身地に基づいて分割されて格納されています
- ウィーンの地区ごとの平均純収入、年間従業員あたりのユーロで表されています
さらに、ダウンロードしたデータファイルを「data」という名前のローカルフォルダに保存しました。
2. 基本的なデータ探索
2.1 行政境界
まず、各行政境界レベルを含む異なるシェイプファイルを読み込み、都市全体についてより詳しく把握します:
folder = 'data'admin_city = gpd.read_file(folder + '/LANDESGRENZEOGD')admin_district = gpd.read_file(folder + '/BEZIRKSGRENZEOGD')admin_census = gpd.read_file(folder + '/ZAEHLBEZIRKOGD')display(admin_city.head(1))display(admin_district.head(1))display(admin_census.head(1))ここで、District IDに対応する列名は「BEZNR」、Census district IDに対応する列名は「ZBEZ」となります。予想外に、これらは異なる形式(numpy.float64とstr)で保存/解析されています:
print(type(admin_district.BEZNR.iloc[0]))print(type(admin_census.ZBEZ.iloc[0]))pythデータファイルのドキュメントによると、23の地区と250の国勢調査地区が実際に存在することを確認します:
print(len(set(admin_district.BEZNR)))print(len(set(admin_census.ZBEZ)))次に、境界を可視化します。まずは市全体、次に地区、そしてさらに小さな国勢調査地区です。
f, ax = plt.subplots(1,3,figsize=(15,5))admin_city.plot(ax=ax[0], edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Reds')admin_district.plot(ax=ax[1], edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Blues')admin_census.plot(ax=ax[2], edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Purples')ax[0].set_title('市の境界')ax[1].set_title('地区の境界')ax[2].set_title('国勢調査地区の境界')このコードは、以下のようにウィーンの可視化結果を出力します:
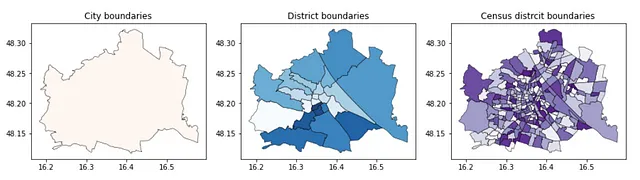
2.2 緑地域
次に、緑地域の分布を見てみましょう:
gdf_green = gpd.read_file(folder + '/GRUENFREIFLOGD_GRUENGEWOGD')display(gdf_green.head(3))ここで、地区との直接的な関連付け方法(例:地区IDの追加など)がないことに注意してください。そのため、後でジオメトリを操作して重なりを見つけることで関連付けを行います。
さて、これを可視化します:
f, ax = plt.subplots(1,1,figsize=(7,5))gdf_green.plot(ax=ax, edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Greens')ax.set_title('ウィーンの緑地域')このコードは、ウィーンの緑地域を表示します:
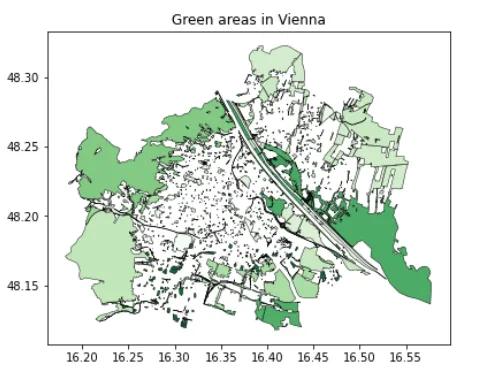
森林セグメントは行政境界内に残っていることに注意すると、市のすべての部分が都市化されており、人口が多いわけではないことがわかります。後で、一人当たりの緑地域を評価する際にこれに戻ってきます。
2.3 統計データ — 人口、所得
最後に、統計データファイルを見てみましょう。最初の主な違いは、これらがジオリファレンスされていない単純なCSVテーブルであることです:
df_pop_distr = pd.read_csv('vie-bez-pop-sex-age5-stk-ori-geo4-2002f.csv', sep = ';', encoding='unicode_escape', skiprows = 1)df_pop_cens = pd.read_csv('vie-zbz-pop-sex-agr3-stk-ori-geo2-2008f.csv', sep = ';', encoding='unicode_escape', skiprows = 1)df_inc_distr = pd.read_csv('vie-bez-biz-ecn-inc-sex-2002f.csv', sep = ';', encoding='unicode_escape', skiprows = 1)display(df_pop_distr.head(1))display(df_pop_cens.head(1))display(df_inc_distr.head(1))3. データの前処理
3.1 統計データファイルの準備
前のセクションでは、統計データテーブルが異なる命名規則を使用していることがわかりました。DISTRICT_CODEとSUB_DISTRICT_CODEの識別子を使用しているため、BEZNRやZBEZのようなものではありません。しかし、各データセットのドキュメントを読むと、容易に変換できることがわかります。次のセルでは、それぞれのデータセットに対して2つの短い関数を示します。地区レベルと国勢調査地区レベルで同時に処理します。
さらに、私は(最新の)集計値と統計情報のデータポイントに興味を持ちます。つまり、最新のスナップショットでの総人口などのデータをクリーンアップし、後で使用する列を保持します。
# これらの関数は、地区と国勢調査地区のIDを形状ファイルで見つかるものと互換性のあるものに変換しますdef transform_district_id(x): return int(str(x)[1:3])def transform_census_district_id(x): return int(str(x)[1:5])# データセットの最新の年を選択df_pop_distr_2 = df_pop_distr[df_pop_distr.REF_YEAR \ ==max(df_pop_distr.REF_YEAR)]df_pop_cens_2 = df_pop_cens[df_pop_cens.REF_YEAR \ ==max(df_pop_cens.REF_YEAR)]df_inc_distr_2 = df_inc_distr[df_inc_distr.REF_YEAR \ ==max(df_inc_distr.REF_YEAR)]# 地区IDを変換df_pop_distr_2['district_id'] = \ df_pop_distr_2.DISTRICT_CODE.apply(transform_district_id)df_pop_cens_2['census_district_id'] = \ df_pop_cens_2.SUB_DISTRICT_CODE.apply(transform_census_district_id)df_inc_distr_2['district_id'] = \ df_inc_distr_2.DISTRICT_CODE.apply(transform_district_id)# 人口の値を集計df_pop_distr_2 = df_pop_distr_2.groupby(by = 'district_id').sum()df_pop_distr_2['district_population'] = df_pop_distr_2.AUT + \ df_pop_distr_2.EEA + df_pop_distr_2.REU + df_pop_distr_2.TCNdf_pop_distr_2 = df_pop_distr_2[['district_population']]df_pop_cens_2 = df_pop_cens_2.groupby(by = 'census_district_id').sum()df_pop_cens_2['census_district_population'] = df_pop_cens_2.AUT \ + df_pop_cens_2.FORdf_pop_cens_2 = df_pop_cens_2[['census_district_population']]df_inc_distr_2['district_average_income'] = \ 1000*df_inc_distr_2[['INC_TOT_VALUE']]df_inc_distr_2 = \ df_inc_distr_2.set_index('district_id')[['district_average_income']]# 最終的なテーブルを表示display(df_pop_distr_2.head(3))display(df_pop_cens_2.head(3))display(df_inc_distr_2.head(3))# 命名規則を統一するadmin_district['district_id'] = admin_district.BEZNR.astype(int)admin_census['census_district_id'] = admin_census.ZBEZ.astype(int)print(len(set(admin_census.ZBEZ)))計算された合計人口値を2つの集計レベルでダブルチェックしてください:
print(sum(df_pop_distr_2.district_population))print(sum(df_pop_cens_2.census_district_population))これらの2つは同じ結果、つまり1931593人を提供するはずです。
3.1. 地理空間データファイルの準備
統計ファイルの必須データ準備が完了したので、緑地ポリゴンを行政区ポリゴンにマッチングします。そして、各行政区域の総緑地面積を計算しましょう。また、興味本位で各行政区域の相対緑地面積を追加します。
SI単位で表された面積を取得するために、ウィーンの場合はEPSG:31282と呼ばれる地域固有のCRS(座標参照系)に切り替える必要があります。このトピック、地図投影と座標参照系については、こことここで詳細を読むことができます。
# すべてのGeoDataFrameをローカルCRSに変換するadmin_district_2 = \ admin_district[['district_id', 'geometry']].to_crs(31282)admin_census_2 = \ admin_census[['census_district_id', 'geometry']].to_crs(31282)gdf_green_2 = gdf_green.to_crs(31282)SI単位で測定された行政単位の面積を計算します:
admin_district_2['admin_area'] = \ admin_district_2.geometry.apply(lambda g: g.area)admin_census_2['admin_area'] = \ admin_census_2.geometry.apply(lambda g: g.area)display(admin_district_2.head(1))display(admin_census_2.head(1))4. 人口当たりの緑地面積比を計算する
4.1 各行政単位の緑地面積を計算する
GeoPandasのoverlay関数を使用して、これらの2つの行政境界のGeoDataFrameと緑地ポリゴンを含むGeoDataFrameをオーバーレイします。次に、異なる行政地域に含まれる各緑地エリアセクションの面積を計算します。その後、これらの面積を行政地域のレベルで合計します。最終的なステップでは、各解像度単位で、以前に計算された行政の公式ユニットの面積を追加し、各地区と国勢調査地区の緑地面積比を計算します。
gdf_green_mapped_distr = gpd.overlay(gdf_green_2, admin_district_2)gdf_green_mapped_distr['green_area'] = \ gdf_green_mapped_distr.geometry.apply(lambda g: g.area) gdf_green_mapped_distr = \ gdf_green_mapped_distr.groupby(by = 'district_id').sum()[['green_area']]gdf_green_mapped_distr = \ gpd.GeoDataFrame(admin_district_2.merge(gdf_green_mapped_distr, left_on = 'district_id', right_index = True))gdf_green_mapped_distr['green_ratio'] = \ gdf_green_mapped_distr.green_area / gdf_green_mapped_distr.admin_areagdf_green_mapped_distr.head(3)
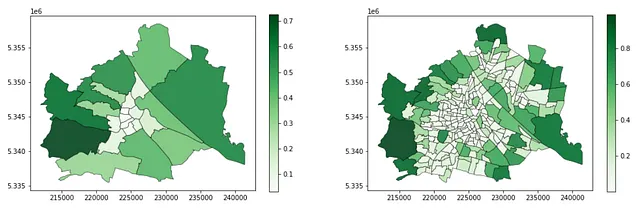
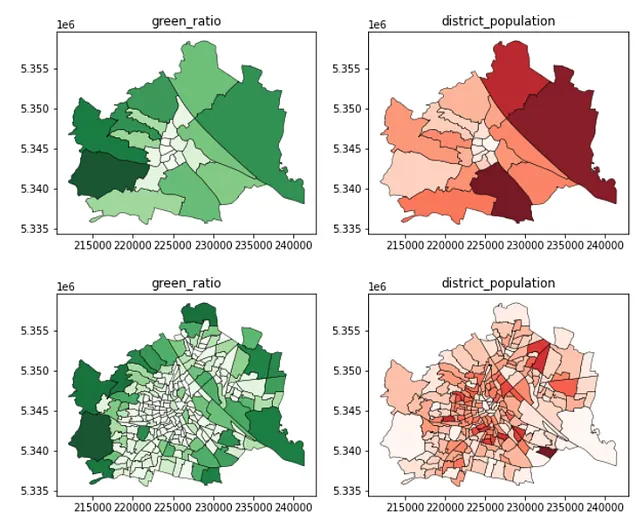
gdf_green_mapped_cens = gpd.overlay(gdf_green_2, admin_census_2)gdf_green_mapped_cens['green_area'] = \ gdf_green_mapped_cens.geometry.apply(lambda g: g.area)gdf_green_mapped_cens = \ gdf_green_mapped_cens.groupby(by = 'census_district_id').sum()[['green_area']]gdf_green_mapped_cens = \ gpd.GeoDataFrame(admin_census_2.merge(gdf_green_mapped_cens, left_on = 'census_district_id', right_index = True))gdf_green_mapped_cens['green_ratio'] = gdf_green_mapped_cens.green_area / gdf_green_mapped_cens.admin_areagdf_green_mapped_cens.head(3)最後に、地区と国勢調査地区ごとの緑地比率を可視化します!結果は非常に意味があり、外側の地域には高い緑地率があり、中心部では低くなっています。また、250の国勢調査地区は、異なる地域の特性のより詳細で細かい画像を明確に示しており、都市計画家により深いローカルな洞察を提供しています。一方、10倍の空間単位の地区レベルの情報は、代わりに大まかな平均値を示しています。
f、ax = plt.subplots(1,2,figsize=(17,5))gdf_green_mapped_distr.plot(ax = ax[0], column = 'green_ratio', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, legend = True, cmap = 'Greens')gdf_green_mapped_cens.plot(ax = ax[1], column = 'green_ratio', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, legend = True, cmap = 'Greens')このコードブロックは、次の地図を出力します:
4.2 各行政単位に人口と所得情報を追加する
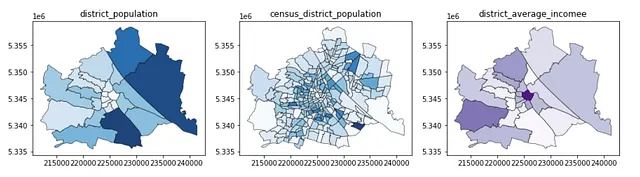
このセクションの最終ステップでは、統計データを行政地域にマッピングします。注意:行政地区と国勢調査地区の両方のレベルで人口データがあります。ただし、所得(社会経済水準指標)については、地区レベルでのみ入手できました。これは、地理空間データ科学における通常のトレードオフです。1つの次元(緑地)がより詳細な解像度(国勢調査地区)でより洞察力がある一方、データの制約により、それでも低い解像度を使用する必要がある場合があります。
display(admin_census_2.head(2))display(df_pop_cens_2.head(2))
gdf_pop_mapped_distr = admin_district_2.merge(df_pop_distr_2, \ left_on = 'district_id', right_index = True)gdf_pop_mapped_cens = admin_census_2.merge(df_pop_cens_2, \ left_on = 'census_district_id', right_index = True)gdf_inc_mapped_distr = admin_district_2.merge(df_inc_distr_2, \ left_on = 'district_id', right_index = True)f, ax = plt.subplots(1,3,figsize=(15,5))gdf_pop_mapped_distr.plot(column = 'district_population', ax=ax[0], \ edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Blues')gdf_pop_mapped_cens.plot(column = 'census_district_population', ax=ax[1], \ edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Blues')gdf_inc_mapped_distr.plot(column = 'district_average_income', ax=ax[2], \ edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Purples')ax[0].set_title('district_population')ax[1].set_title('census_district_population')ax[2].set_title('district_average_incomee')このコードブロックは次の図を生成します:
4.3. 1人当たりの緑地面積の計算
今のところ、ウィーンの地区と国勢調査地区に対応するデータをまとめると、次のようなものがあります:
地区レベルでは、緑地比率、人口、収入データがあります
国勢調査地区レベルでは、緑地比率と人口データがあります
緑の平等をシンプルに捉えるために、地区と国勢調査地区の緑地の絶対的なサイズと人口の情報を統合し、1人当たりの緑地面積の合計を計算します。
入力データである緑地カバレッジと人口を見てみましょう:
# 地区のプロット、ax = plt.subplots(1,2,figsize=(10,5))gdf_green_mapped_distr.plot( ax = ax[0], column = 'green_ratio', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Greens')gdf_pop_mapped_distr.plot( ax = ax[1], column = 'district_population', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Reds')ax[0].set_title('green_ratio')ax[1].set_title('district_population')# 国勢調査地区のプロット、ax = plt.subplots(1,2,figsize=(10,5))gdf_green_mapped_cens.plot( ax = ax[0], column = 'green_ratio', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Greens')gdf_pop_mapped_cens.plot(ax = ax[1], column = 'census_district_population', edgecolor = 'k', linewidth = 0.5, alpha = 0.9, cmap = 'Reds')ax[0].set_title('green_ratio')ax[1].set_title('district_population')このコードブロックは次の図を生成します:
1人当たりの緑地面積を計算するために、以下の手順で緑地と人口のデータフレームを結合します。国勢調査地区を例にして行います。空でないエリアを削除し、ゼロで割ることがないように注意しましょう。
gdf_green_pop_cens = \ gdf_green_mapped_cens.merge(gdf_pop_mapped_cens.drop( \ columns = ['geometry', 'admin_area']), left_on = 'census_district_id',\ right_on = 'census_district_id')[['census_district_id', \ 'green_area', 'census_district_population', 'geometry']]gdf_green_pop_cens['green_area_per_capita'] = \ gdf_green_pop_cens['green_area'] / \ gdf_green_pop_cens['census_district_population']gdf_green_pop_cens = \ gdf_green_pop_cens[gdf_green_pop_cens['census_district_population']>0]f, ax = plt.subplots(1,1,figsize=(10,7))gdf_green_pop_cens.plot( column = 'green_area_per_capita', ax=ax, cmap = 'RdYlGn', edgecolor = 'k', linewidth = 0.5)admin_district.to_crs(31282).plot(\ ax=ax, color = 'none', edgecolor = 'k', linewidth = 2.5)このコードブロックは次の図を生成します:
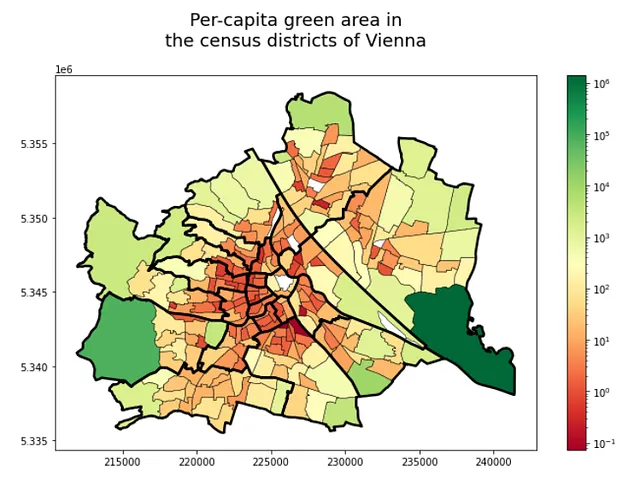
可視化を少し調整しましょう:
f、ax = plt.subplots(1,1,figsize=(11,7))ax.set_title('ウィーンの国勢調査区における一人当たりの緑地面積', fontsize = 18, pad = 30)gdf_green_pop_cens.plot( column = 'green_area_per_capita', ax=ax, cmap = 'RdYlGn', edgecolor = 'k', linewidth = 0.5, legend=True, norm=matplotlib.colors.LogNorm(\ vmin=gdf_green_pop_cens.green_area_per_capita.min(), \ vmax=gdf_green_pop_cens.green_area_per_capita.max()), )admin_district.to_crs(31282).plot( ax=ax, color = 'none', edgecolor = 'k', linewidth = 2.5)このコードブロックによって、以下の図が生成されます:
同様に、地区についても:
# 一人当たりの緑地面積を計算gdf_green_pop_distr = \ gdf_green_mapped_distr.merge(gdf_pop_mapped_distr.drop(columns = \ ['geometry', 'admin_area']), left_on = 'district_id', right_on = \ 'district_id')[['district_id', 'green_area', 'district_population', \ 'geometry']]gdf_green_popdistr = \ gdf_green_pop_distr[gdf_green_pop_distr.district_population>0]gdf_green_pop_distr['green_area_per_capita'] = \ gdf_green_pop_distr['green_area'] / \ gdf_green_pop_distr['district_population']# 地区レベルのマップを可視化f, ax = plt.subplots(1,1,figsize=(10,8))ax.set_title('ウィーンの地区における一人当たりの緑地面積', \ fontsize = 18, pad = 26)gdf_green_pop_distr.plot(column = 'green_area_per_capita', ax=ax, \ cmap = 'RdYlGn', edgecolor = 'k', linewidth = 0.5, legend=True, \ norm=matplotlib.colors.LogNorm(vmin=\ gdf_green_pop_cens.green_area_per_capita.min(), \ vmax=gdf_green_pop_cens.green_area_per_capita.max()), )admin_city.to_crs(31282).plot(ax=ax, \ color = 'none', edgecolor = 'k', linewidth = 2.5)このコードブロックによって、以下の図が生成されます:
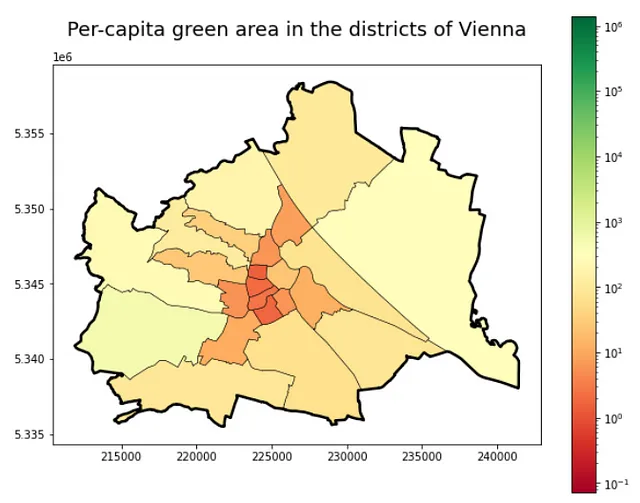
重要な傾向は明確です – 外側のリム、より多くの緑地があり、都心には逆の傾向があります。それにもかかわらず、これらの2つのプロット、特に国勢調査区の詳細なものは、異なる地域で人々が楽しむ緑地の量のばらつきを明確に示しています。さらなる研究や土地利用などの追加のデータソースを組み込むことにより、なぜこれらの地域が緑地面積や人口が多いのかをより良く説明することができるかもしれません。今のところ、この地図を楽しんで、皆さんが自宅で適切な量の緑地を見つけられることを願っています!
# 緑地、人口、財政データの結合gdf_district_green_pip_inc = \ gdf_green_pop_distr.merge(gdf_inc_mapped_distr.drop(columns = \ ['geometry']))財政と緑地の関係を可視化します:
f、ax = plt.subplots(1,1,figsize=(6,4))
ax.plot(gdf_district_green_pip_inc.district_average_income, \ gdf_district_green_pip_inc.green_area_per_capita, 'o')
ax.set_xscale('log')
ax.set_yscale('log')
ax.set_xlabel('district_average_income')
ax.set_ylabel('green_area_per_capita')このコードブロックの結果は、次の散布図です:
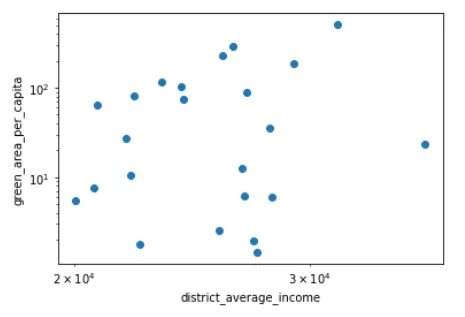
一見すると、この散布図は特に財務が人々の緑地へのアクセスに影響を与える強力な証拠を示していません。正直に言うと、これらの結果には少し驚いています。ただし、ウィーン市が長年にわたり都市の緑化に取り組んでいることを考慮すると、ここで大きな傾向を見ることはないかもしれません。確認するために、これらの2つの変数の相関関係も調べました:
print(spearmanr(gdf_district_green_pip_inc.district_average_income, gdf_district_green_pip_inc.green_area_per_capita))
print(pearsonr(gdf_district_green_pip_inc.district_average_income, gdf_district_green_pip_inc.green_area_per_capita))財務データの重尾分布のため、ここではスピアマンの相関係数(0.13)をより重視するべきですが、ピアソンの相関係数(0.30)でも比較的弱い傾向が示されており、私の以前の観察と一致しています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
