データサイエンティストのための必須ガイド:探索的データ分析
Essential Guide for Data Scientists Exploratory Data Analysis

イントロダクション
探索的データ分析(EDA)は、すべてのデータサイエンスプロジェクトの開始時に実行する必要がある最も重要なタスクです。
本質的には、データを徹底的に調べ、その基本的な特性、可能性のある異常、そして隠れたパターンと関係性を見つけることが含まれます。
このデータの理解は、データ前処理からモデル構築、結果の分析までの次のステップをガイドすることになります。
- AIフロンティアシリーズ:人材
- AIの導入障壁:主要な課題と克服方法
- オッターに会いましょう:大規模データセット「MIMIC-IT」を活用した最先端のAIモデルであり、知覚と推論のベンチマークにおいて最新の性能を実現しています
EDAのプロセスは、基本的に3つの主要なタスクから構成されます:
- ステップ1: データセットの概要と記述統計
- ステップ2: 特徴量評価と可視化
- ステップ3: データ品質評価
これらのタスクのそれぞれは、かなり包括的な分析を必要とする可能性があるため、pandasデータフレームをスライスして印刷し、プロットする必要があるかもしれません。
適切なツールを選ばない限り、
この記事では、効果的なEDAプロセスの各ステップにダイブして、それをマスターするために「ydata-profiling」を1つのストップショップに変えるべき理由について説明します。
ベストプラクティスをデモンストレーションし、洞察を調べるために、KaggleまたはUCIリポジトリ(ライセンス:CC0:パブリックドメイン)で無料で利用できる「成人国勢調査収入データセット」を使用します。
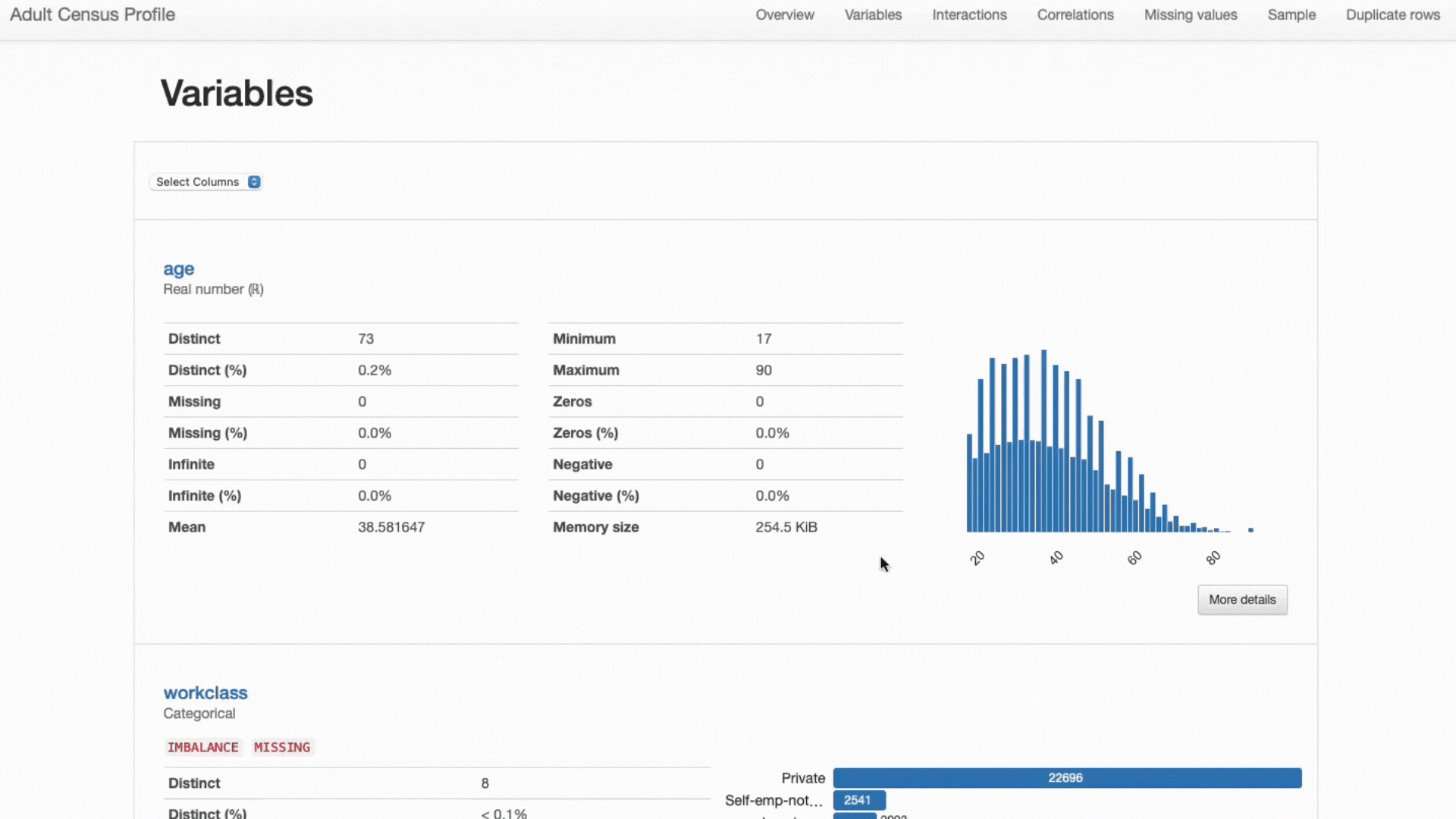
ステップ1:データの概要と記述統計
未知のデータセットを手に入れたときに最初に思い浮かぶのは、「何を扱っているのか」ということです。
将来の機械学習タスクで効率的に処理するために、データを深く理解する必要があります
おおよそ、私たちは伝統的に、観測数、特徴量の数とタイプ、全体の欠損率、および重複した観測の割合に関連したデータを特徴付けることから始めます。
いくつかのpandas操作と適切なチートシートを使用すると、上記の情報をいくつかの短いコードスニペットで出力できます。
データセットの概要:成人国勢調査データセット。 観測数、特徴量、特徴量タイプ、重複行、欠損値。 作者によるスニペット。
全体的に、出力形式は理想的ではありません… pandasに精通している場合、EDAプロセスを開始する標準的なモーダスオペランディはdf.describe()であることを知っています:
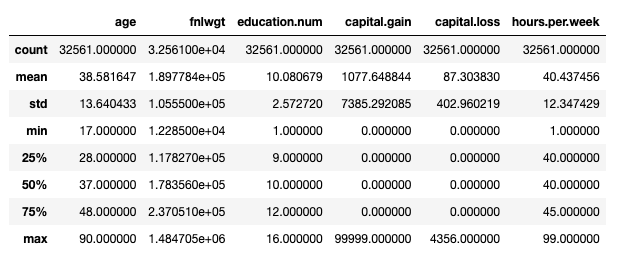
ただし、これは数値特徴のみを考慮しています。 df.describe(include='object')を使用してカテゴリカル特徴のいくつかの追加情報(カウント、ユニーク、モード、頻度)を出力できますが、既存のカテゴリを簡単にチェックするには、もう少し冗長なものが必要です:
データセットの概要:成人国勢調査データセット。 データの各カテゴリの既存のカテゴリとそれぞれの頻度を印刷する。 作者によるスニペット。
ただし、私たちはこれを行うことができます – そして、すべての後続のEDAタスク!- “ ydata-profilingを使用して1行のコードで行うことができます:
Adult Census Datasetのプロファイリングレポート、ydata-profilingを使用して。 作者によるスニペット。
上記のコードはデータの完全なプロファイリングレポートを生成します。これ以上のコードを書く必要はありません。
以下のセクションでレポートのさまざまなセクションについて説明します。全体的なデータの特徴に関する情報は、概要セクションに含まれています:
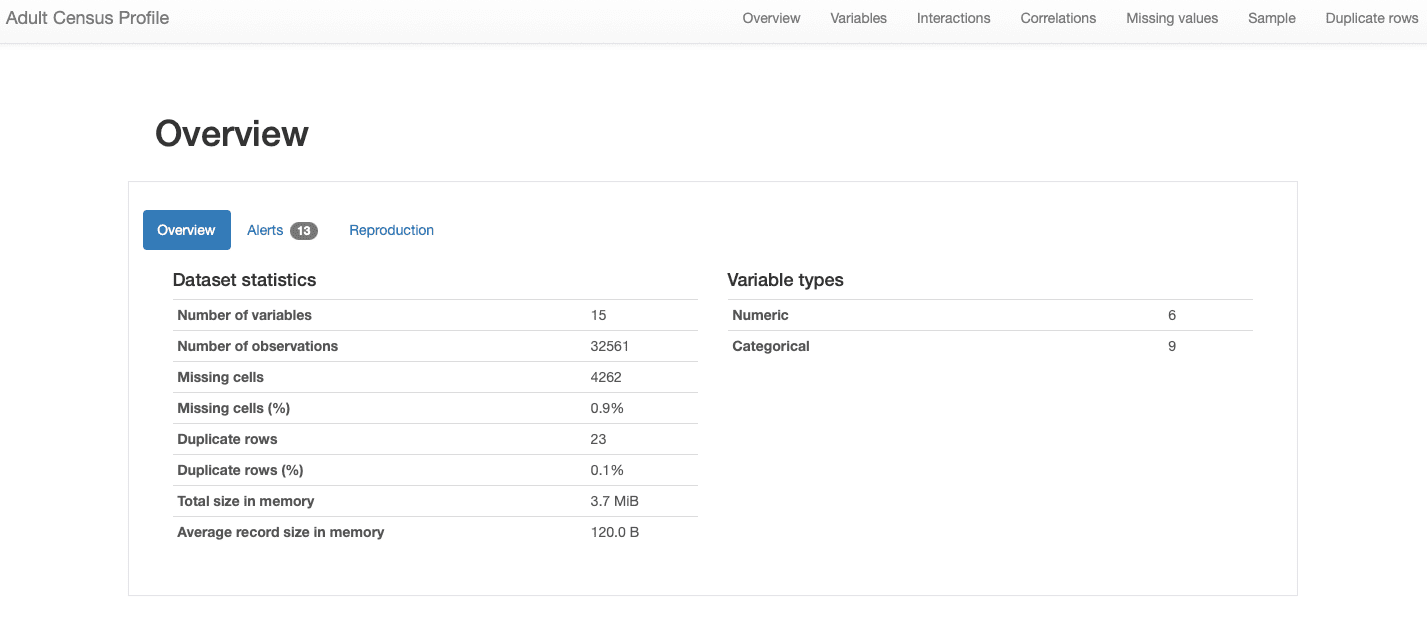
データセットは15の特徴量と32561の観測値、23の重複レコード、そして0.9%の欠損率を持っていることがわかります。
さらに、表形式のデータセットとして正しく識別され、数値とカテゴリーの特徴量が混在しているという異質性があります。時間依存性があり、異なるパターンを示す時系列データに対しては、ydata-profilingはレポートに他の統計や分析を組み込みます。
より複雑な分析に入る前に、生データと既存の重複レコードを調べ、特徴量を全体的に理解することができます。
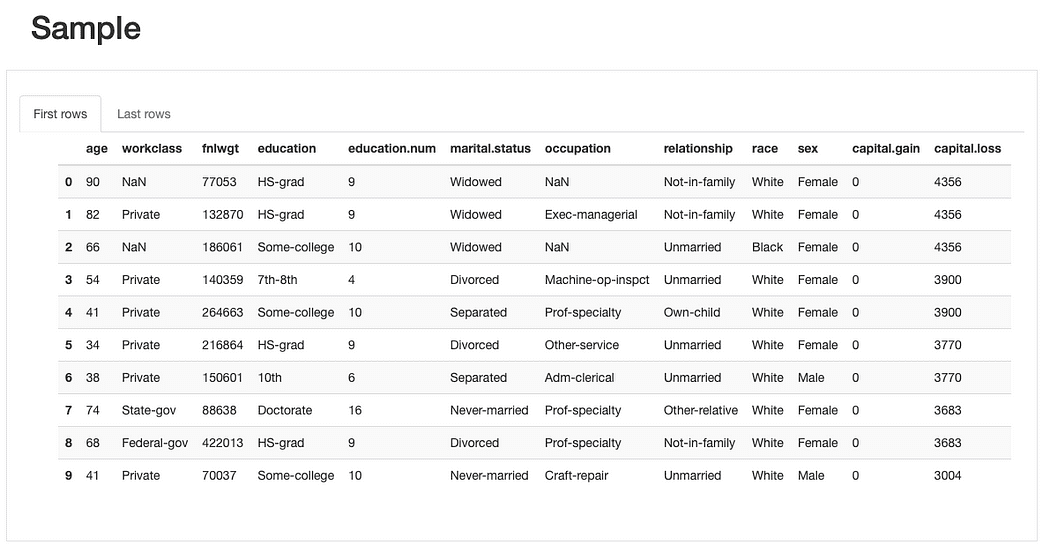
データサンプルの簡単なプレビューから、データセット全体の欠損率は低いですが、いくつかの特徴量は他よりも影響を受けやすいことがすぐにわかります。また、いくつかの特徴量にはかなり多数のカテゴリーがあり、0値の特徴量(あるいは少なくとも多数の0が含まれる特徴量)が特定されます。
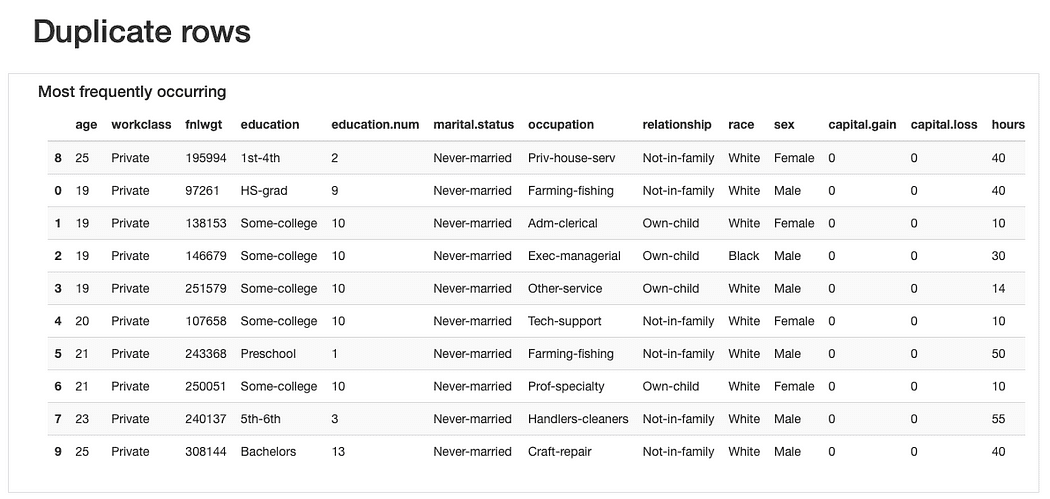
重複行について、複数の人々が同時に「当てはまる」カテゴリーを表す特徴量であるため、「繰り返された」観測値が見つかることは珍しくありません。
ただし、これらの観測値が同じ年齢値(妥当である)および正確に同じfnlwgtを共有している点は、提示された値を考慮すると信じるのは難しいため、さらなる分析が必要ですが、おそらくこれらの重複レコードは後で削除する必要があります。
全体的に、データの概要は単純な分析ですが、それは私たちのパイプラインで行う作業を定義するのに非常に影響力があるものです。
ステップ2:特徴量の評価と可視化
全体的なデータ記述を一通り見た後、個々の特徴量に焦点を当てて、その個々のプロパティ(単変量解析)や相互作用、関係(多変量解析)を理解する必要があります。
両方のタスクは、適切な統計および視覚化の調査に強く依存しており、手元の特徴量に合わせて(数値、カテゴリーなど)、分析する行動に合わせて調整する必要があります(相互作用、相関など)。
各タスクのベストプラクティスを見てみましょう。
単変量解析
各特徴量の個々の特性を分析することは、分析のための関連性や、最適な結果を得るために必要なデータの前処理のタイプを決定するために重要です。
たとえば、極端に範囲外の値があり、不整合や外れ値を示す場合があります。存在するカテゴリーの数に応じて、数値データの標準化またはカテゴリーのワンホットエンコーディングを実行する必要があります。また、機械学習アルゴリズムが特定の分布(通常はガウス分布)を期待する場合、シフトまたはスキューされた数値特徴量を処理するための追加のデータ前処理が必要になる場合があります。
したがって、記述統計量とデータ分布などの各特性を徹底的に調査することがベストプラクティスです。
これらは、外れ値の除去、標準化、ラベルエンコーディング、データ補完、データ拡張、および他の種類の前処理の後続タスクの必要性を強調します。
以下、raceとcapital.gainについて詳しく調べてみましょう。何がすぐに見つかりますか?
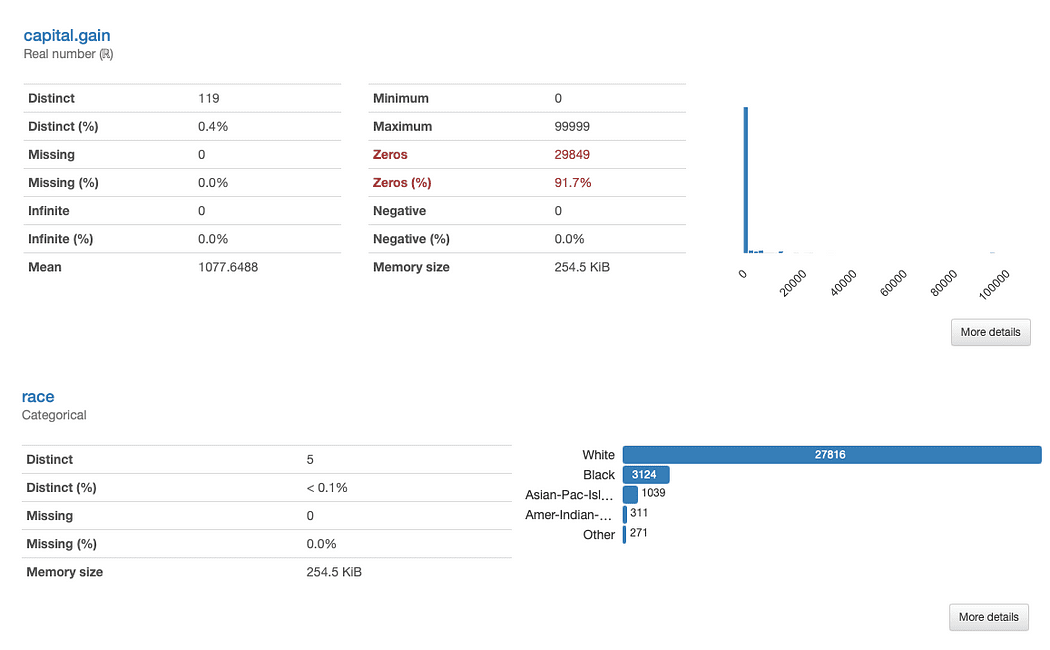
capital.gainの評価は簡単です:
データ分布を考えると、特徴が分析にどのような価値を加えるか疑問に思うことがあります。というのも、91.7%の値が「0」であるためです。
raceの分析は少し複雑です:
White以外の人種の代表者が明らかに少ないです。これには2つの主要な問題があります。
- 1つは、機械学習アルゴリズムが
small disjuncts問題として知られる少数の概念を見落とす傾向があることです。これは、学習性能が低下することにつながります。 - もう1つは、この問題の派生物的なものです。敏感な特徴に対処しているため、「見落としの傾向」は、
race値に直接関係するバイアスと公平性の問題を引き起こす可能性があります。これは、モデルに潜り込ませたくないものです。
これを考慮すると、代表されていないカテゴリに応じたデータ拡張を行うこと、およびrace値に関連するパフォーマンスの不一致をチェックするための公平性に配慮した尺度を考慮することが検討されるかもしれません。
データ品質のベストプラクティス(ステップ3)で対処する必要のある他のデータ特性については、さらに詳しく説明します。この例は、各個の特徴の特性を評価することでどれだけの洞察を得られるかを示しています。
さらに、以前に言及したように、異なる特徴タイプには異なる統計量や可視化戦略が必要です:
- 数値特徴は、平均、標準偏差、歪度、尖度、その他の分位数統計量を含む情報を多く含み、ヒストグラムプロットを使用して最適に表現されます。
- カテゴリ特徴は、モード、中央値、および頻度表を使用して通常説明され、カテゴリ分析にはバープロットが使用されます。
このような詳細な分析を一般的なPandas操作で実行することは手間がかかりますが、幸いにもydata-profiling はこの機能をすべてプロファイリングレポートの ProfileReport に組み込んでいるため、スニペットに追加する追加のコードは必要ありませんでした!
多変量解析
多変量解析において、ベストプラクティスは主に2つの戦略に焦点を当てています。1つ目は、特徴間の相互作用を分析すること、2つ目は、それらの相関を分析することです。
相互作用の分析
相互作用を使用すると、各特徴の動作方法、つまり、1つの特徴の値が他の特徴の値とどのように関連しているかを視覚的に探索できます。
例えば、それらは、一方の値の増加が他方の値の増加または減少と関連するかどうかに応じて、正のまたは負の関係を示す場合があります。
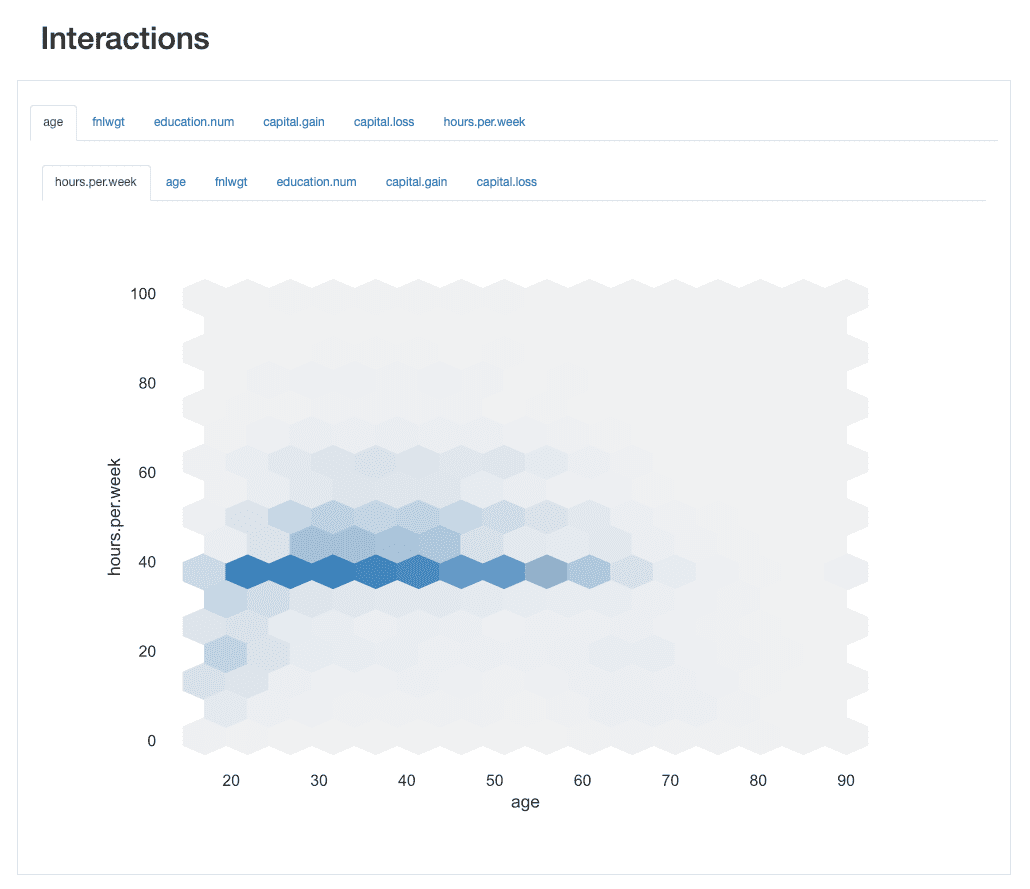 ydata-profiling:プロファイリングレポート-相互作用。作者による画像。
ydata-profiling:プロファイリングレポート-相互作用。作者による画像。
例えば、ageとhours.per.weekの相互作用を取ると、労働力の大多数が標準の40時間働いていることがわかります。ただし、30歳から45歳の間には、60時間または65時間まで働く「忙しい人」がいくつかいます。 20代の人たちは過剰勤務する傾向が少なく、週によってはより軽い勤務スケジュールを持つ場合があります。
相関の分析
相互作用と同様に、相関を分析することで、特徴間の関係を分析できます。ただし、相関はそれに値を与えるため、その関係の「強さ」を決定するのが容易になります。
この「強度」は、相関係数によって測定され、数値的に(例えば、相関行列を調べる)またはヒートマップを使用して分析することができます。ヒートマップは、色とシェーディングを使用して興味深いパターンを視覚的に強調するものです:
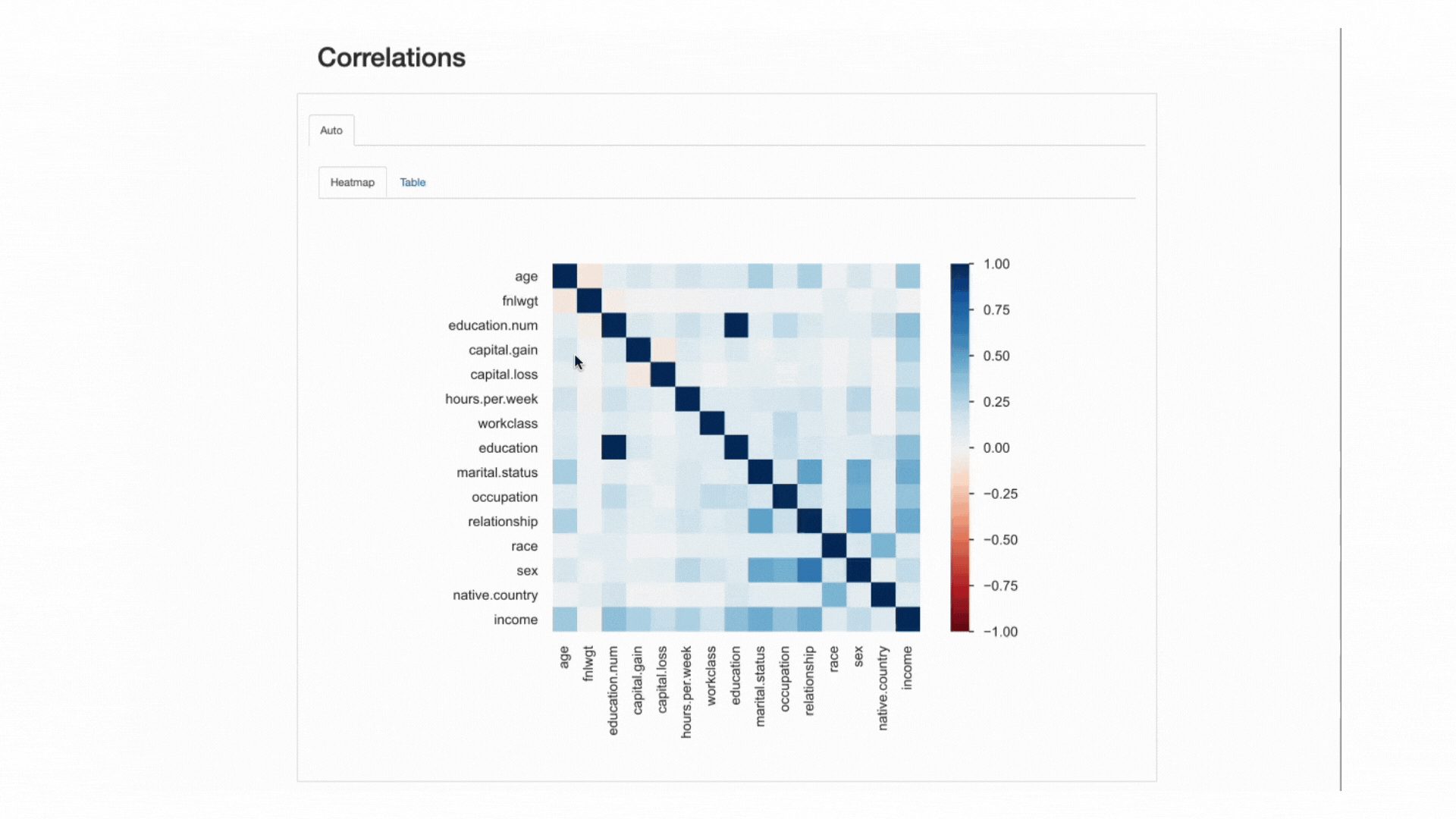 ydata-profiling:プロファイリングレポート-ヒートマップと相関行列。著者によるスクリーンキャスト。
ydata-profiling:プロファイリングレポート-ヒートマップと相関行列。著者によるスクリーンキャスト。
私たちのデータセットに関して、educationとeducation.numの相関関係が目立つことに注意してください。実際、彼らは同じ情報を持っており、education.numは単にeducationの値のビン分割です。
目を引く他のパターンは、sexとrelationshipの相関関係ですが、これもまたあまり情報がありません。両方の機能の値を見ると、これらの機能がおそらく関連していることがわかります。つまり、maleとfemaleはそれぞれhusbandとwifeに対応するからです。
このような冗長性は、いくつかの機能を分析から削除できるかどうかを確認するためにチェックできます(marital.statusもrelationshipとsexに関連しているため、native.countryとraceなど他の機能も含まれます)。
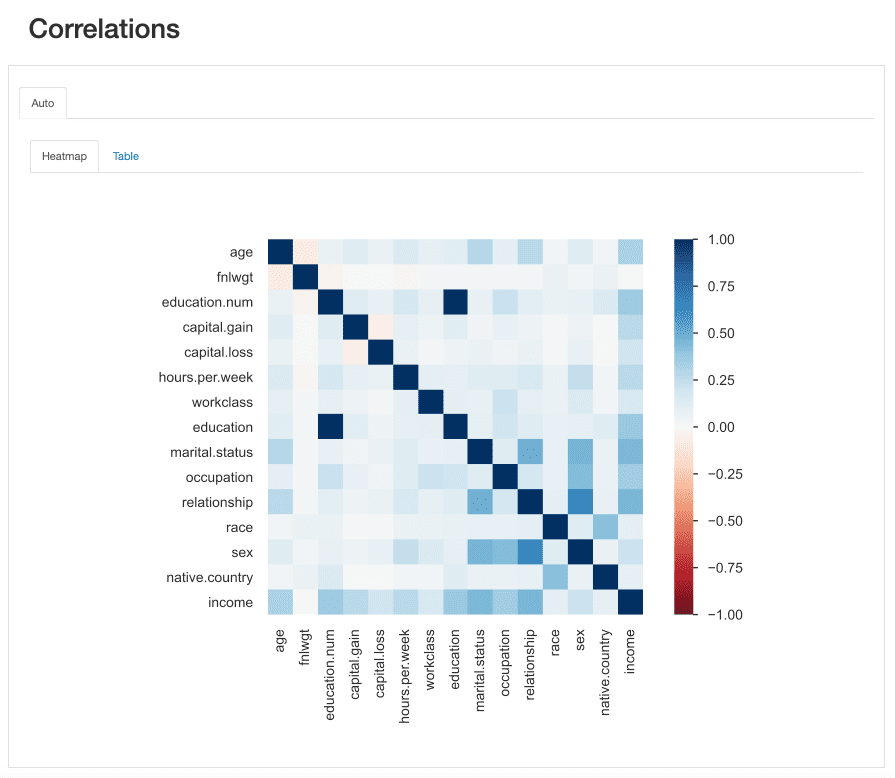 ydata-profiling:プロファイリングレポート-相関。著者による画像。
ydata-profiling:プロファイリングレポート-相関。著者による画像。
ただし、他の相関関係も目立ち、分析の目的に興味深い可能性があります。
たとえば、sexとoccupationの相関関係、またはsexとhours.per.weekの相関関係などがあります。
最後に、incomeと残りの機能との相関関係は本当に情報量が豊富であり、分類問題をマッピングしようとしている場合に特に重要です。ターゲットクラスに最も相関関係がある機能を知ることは、最も識別的な機能を特定するのに役立ちます。また、モデルに影響を与える可能性のあるデータリーカーを見つけるのにも役立ちます。
ヒートマップから、marital.statusまたはrelationshipが最も重要な予測子の1つであるように思われますが、fnlwgtは結果に大きな影響を与えないようです。
データ記述子や視覚化と同様に、相互作用や相関関係も手元にある機能の種類に注意を払う必要があります。
言い換えれば、異なる組み合わせは異なる相関係数で測定されます。デフォルトでは、ydata-profilingはautoで相関関係を実行します。これは次のようになります。
- 数値対数値の相関関係は、スピアマンの順位相関係数を使用して測定されます。
- カテゴリ対カテゴリの相関関係は、クラメールのVを使用して測定されます。
- 数値対カテゴリの相関関係も、最初に数値機能を離散化した上で、クラメールのVを使用します。
そして、他の相関係数(例えば、ピアソン、ケンドール、ファイ)を確認したい場合は、簡単にレポートのパラメータを設定できます。
ステップ3:データ品質評価
AI開発のデータ中心のパラダイムに向けて進んでいく中で、データに起因する複雑化要因について把握しておくことが重要です。
「複雑化要因」とは、データ収集や処理中に発生するエラーや、データの本質的な特徴であり、データの本質そのものの反映であるものを指します。
これには、欠損データ、不均衡データ、定数値、重複、高度に相関するまたは冗長な機能、ノイズのあるデータなどが含まれます。
 データ品質の問題:エラーとデータ固有の特性。著者による画像。
データ品質の問題:エラーとデータ固有の特性。著者による画像。
プロジェクトの開始時にこれらのデータ品質の問題を発見すること(そして開発中にそれらを継続的に監視すること)は重要です。
モデル構築の段階でこれらが特定されずに対処されないと、全体のMLパイプラインとそれから派生する分析と結論が危険にさらされる可能性があります。
自動化されたプロセスがなければ、EDA分析を実施する人の個人的な経験と専門知識に完全に依存することになり、これは明らかに理想的ではありません。加えて、高次元のデータセットを考慮すると、一人で対処するのは重荷です。入ってくる悪夢の警告です!
このydata-profilingの最も高く評価されている機能の1つは、データ品質の自動生成アラートです:
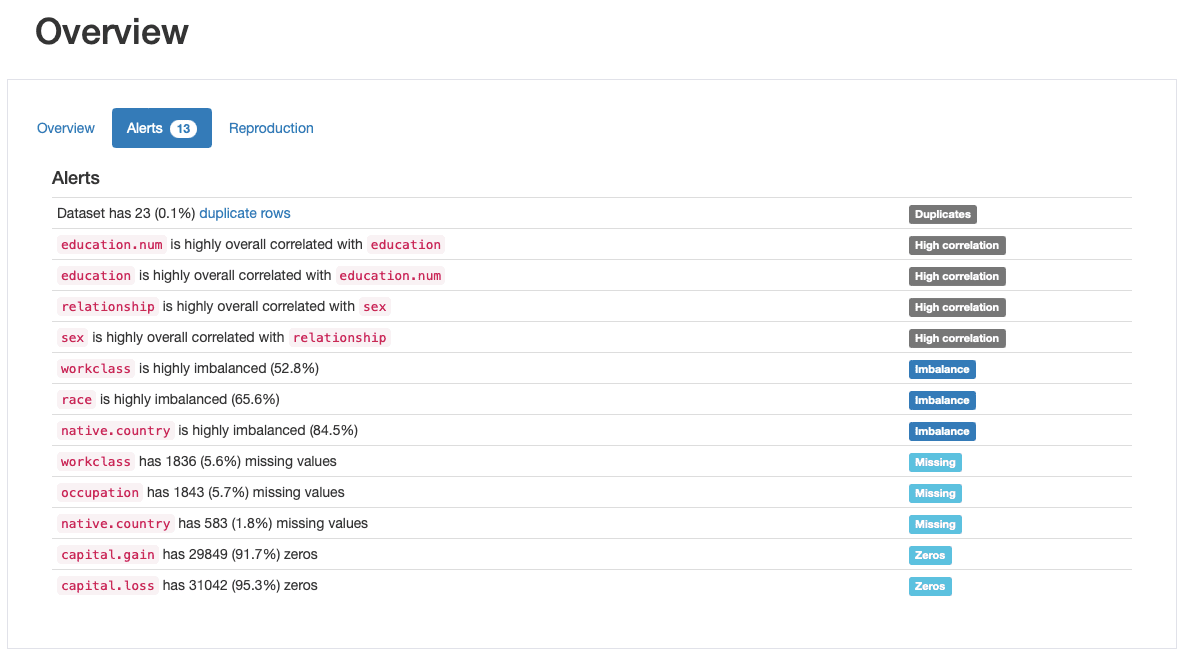 ydata-profiling:プロファイリングレポート-データ品質アラート。作者による画像。
ydata-profiling:プロファイリングレポート-データ品質アラート。作者による画像。
プロファイルは、重複、高い相関、不均衡、欠落、0などの少なくとも5つの異なるデータ品質問題を出力します。
実際、私たちはすでに、ステップ2を進めるにつれて、raceは高度に不均衡な特徴であり、capital.gainは主に0で占められていることを特定していました。また、educationとeducation.num、relationshipとsexの間の密接な相関も見てきました。
欠落データパターンの分析
包括的なアラートの範囲の中で、ydata-profilingは特に欠落データパターンの分析に役立ちます。
欠落データは現実世界のドメインで非常に一般的な問題であり、一部の分類器の適用を妨げることがあり、またその予測を厳重にバイアスする可能性があるため、欠落データの割合と振る舞いを注意深く分析することは別のベストプラクティスです。
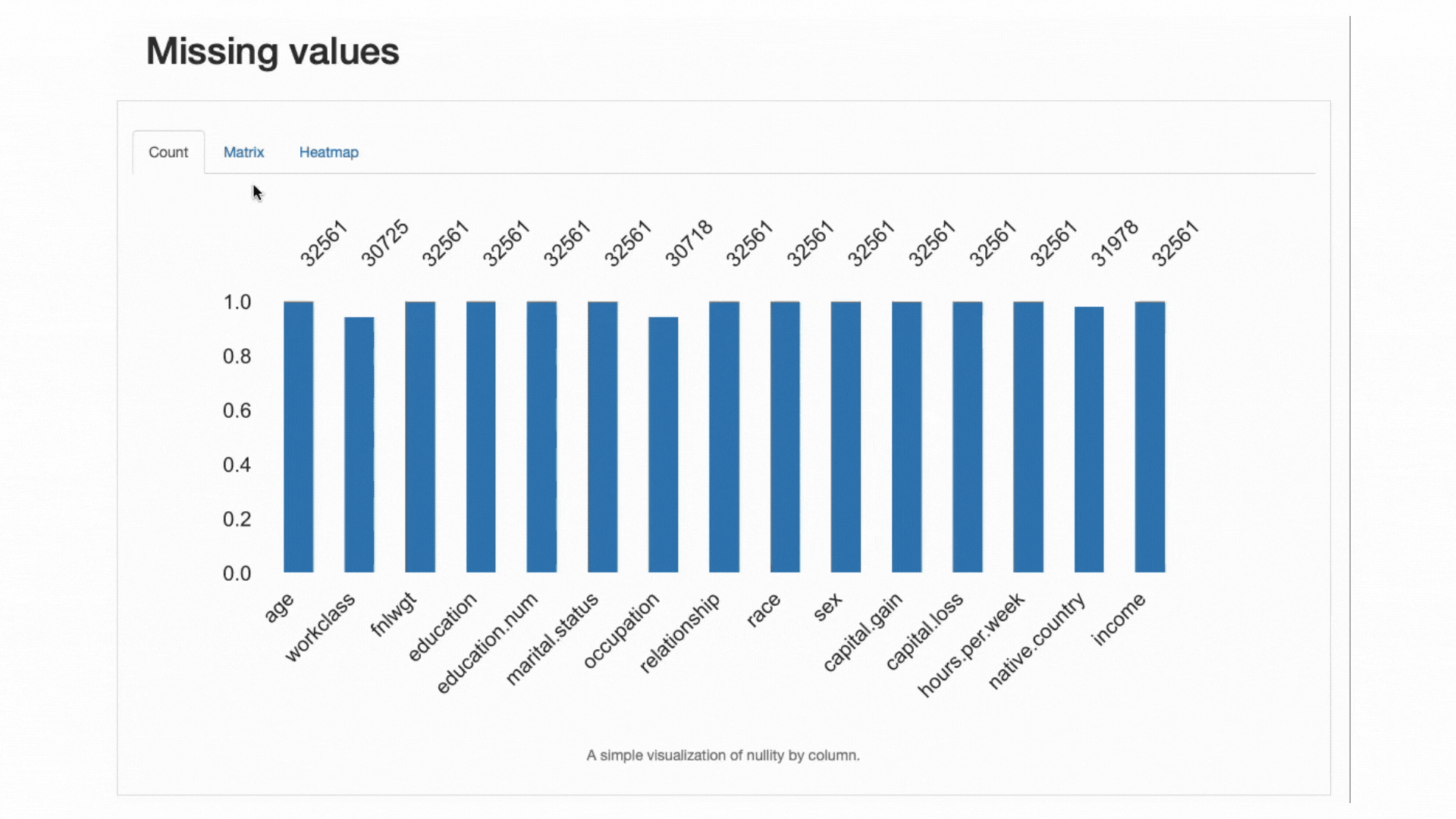 ydata-profiling:プロファイリングレポート-欠落値の分析。作者によるスクリーンキャスト。
ydata-profiling:プロファイリングレポート-欠落値の分析。作者によるスクリーンキャスト。
データアラートセクションから、workclass、occupation、native.countryには欠席の観測があることをすでに知っていました。ヒートマップは、occupationとworkclassの欠落パターンと直接関係があることを示しています:1つの特徴に欠落値がある場合、他の特徴も欠落します。
主要な洞察:データプロファイリングはEDAを超えます!
これまで、徹底的なEDAプロセスを構成するタスクと、データ品質の問題と特性の評価、私たちはデータプロファイリングと呼ぶことができるプロセスが確かにベストプラクティスであることについて議論してきました。
しかし、EDAを通常はどのように定義しているので、データプロファイリングはEDAを超えるということを明確にすることが重要です。一般的に、データパイプラインを開発する前の探索的、対話型のステップとしてEDAを定義しますが、データプロファイリングは反復プロセスであり、データ前処理とモデル構築のすべてのステップで発生するべきです。
結論
効率的なEDAは、成功する機械学習パイプラインの基盤を築くことになります。
データの診断を実行し、特性、関係、問題について必要なすべてを学び、可能な限り最良の方法で対処できるようにするのと同様に、EDDは私たちのインスピレーションの始まりです。EDAから質問や仮説が浮かび上がり、分析が計画されて、その過程でそれらを検証または拒否するための準備が整います。
本記事では、効果的なEDAをガイドする3つの主要な基本的なステップをカバーし、ydata-profilingという優れたツールが正しい方向を指し示し、時間と精神的負担を大幅に節約することの影響についても議論しました。
このガイドがあなたが「データ探偵」としての技術を習得するのに役立つことを願っています。いつものように、フィードバックや質問、提案は大歓迎です。他にどのようなトピックについて書いてほしいか、またはData-Centric AIコミュニティで一緒に協力しましょう。
ミリアム・サントスは、データサイエンス&マシンラーニングのコミュニティに教育を重点的に置き、生の、汚れた、”悪い”または不完全なデータからスマートで知的で高品質なデータに移行する方法を指導し、機械学習分類器がさまざまな産業(Fintech、ヘルスケア&ファーマ、テレコム、小売)で正確で信頼性の高い推論を引き出すことを可能にします。
オリジナル。許可を得て再掲載。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
