「LLMsの信頼性のあるフューショットプロンプトの選択を確保する」
Ensuring reliable selection of LLMs' fusible prompts.
著者:Chris Mauck、Jonas Mueller
この記事では、大手銀行の顧客サービス要求の意図を分類するために、OpenAIのDavinci Large Language Model(GPT-3/ChatGPTの基盤となるモデル)にフューショットプロンプトを与えます。通常の手法に従い、フューショットの例は人間によってラベル付けされた要求の例を含む利用可能なデータセットから取得します。しかし、実際のデータは乱雑でエラーが発生しやすいため、結果として得られるLLMの予測は信頼性がありません。ポテンシャルにノイズのあるデータを軽減するために、プロンプトテンプレートを手動で修正することで、LLMの性能はわずかに向上します。LLMの予測は、データ指向のAIアルゴリズムである「Confident Learning」のように、高品質なフューショットの例のみがプロンプトテンプレートに選択されるようにすると、さらに正確になります。
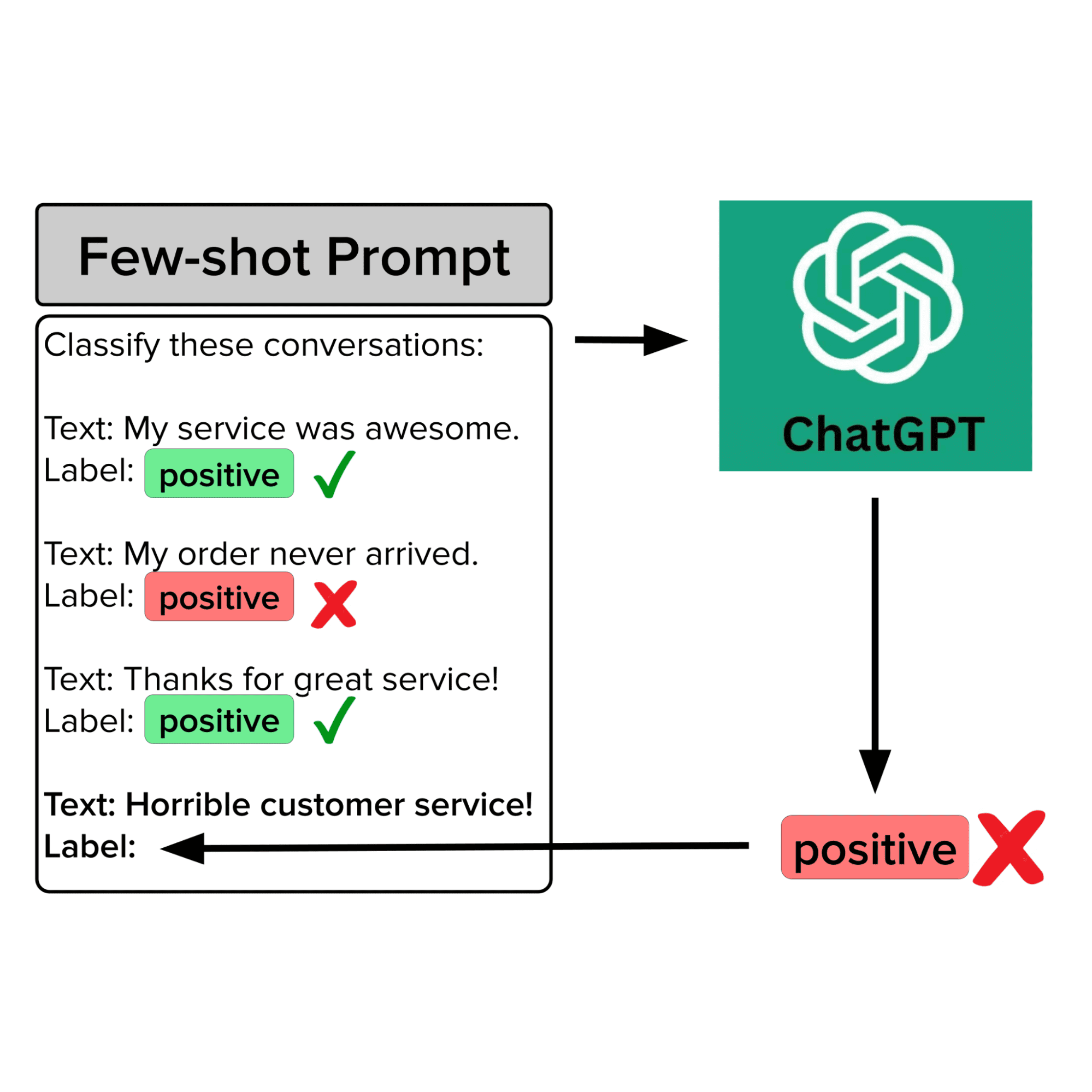
信頼性の高いフューショットの例をキュレーションして、LLMに最も信頼性の高い予測を出させる方法について考えてみましょう。フューショットのプロンプトで高品質な例を確保する必要性は明らかですが、多くのエンジニアはこのような作業をより体系的に行うためのアルゴリズム/ソフトウェアが存在することを知りません(実際、データ指向AIという科学的な学問分野全体があります)。アルゴリズムによるデータキュレーションには、完全自動化、体系的なアプローチ、および意図分類以上の一般的なLLMアプリケーションに広く適用可能な多くの利点があります。
- 「LLMsとメモリは間違いなく必要なものです:Googleはメモリを補完したLLMsが任意のチューリングマシンをシミュレートできることを示しています」
- このAI論文では、ChatGPTに焦点を当て、テキスト注釈タスクにおける大規模言語モデル(LLM)のポテンシャルを探求しています
- GPT-4のようなモデルは、行動能力を与えられた場合に安全に振る舞うのか?:このAI論文では、「MACHIAVELLIベンチマーク」を導入して、マシン倫理を向上させ、より安全な適応エージェントを構築することを提案しています
銀行の意図データセット
この記事では、オンラインバンキングのクエリに対応する意図(下記のラベル)がアノテーションされた、Banking-77データセットの50クラスバリアントを調査します。我々は、このラベルを予測するモデルを、約500のフレーズを含む固定のテストデータセットを使用して評価し、フューショットの例の候補として考慮される約1000のラベル付きフレーズのプールを持っています。

候補のフューショットの例とテストセットをこちらとこちらでダウンロードできます。この記事で示されている結果を再現するために実行できるノートブックも用意しています。
フューショットプロンプティング
フューショットプロンプティング(またはインコンテキスト学習)は、事前学習済みの基盤モデルが明示的なトレーニング(つまり、モデルパラメータの更新)なしに複雑なタスクを実行できるようにするNLPの技術です。フューショットプロンプティングでは、モデルに限られた数の入力-出力ペアを提供します。これらは、特定の入力の処理方法をモデルに指示するためのプロンプトに含まれるプロンプトテンプレートの一部として提供されます。プロンプトテンプレートによって提供される追加の文脈情報は、モデルが望ましい出力のタイプをより良く推測するのに役立ちます。たとえば、入力が「サンフランシスコはカリフォルニアにありますか?」の場合、LLMはこのプロンプトが固定テンプレートと組み合わされ、新しいプロンプトが以下のようになる場合、より良い出力のタイプを把握することができます:
テキスト:ボストンはマサチューセッツにありますか?
ラベル:はい
テキスト:デンバーはカリフォルニアにありますか?
ラベル:いいえ
テキスト:サンフランシスコはカリフォルニアにありますか?
ラベル:
フューショットプロンプティングは、クラスがドメイン固有であるテキスト分類シナリオで特に有用です(これは異なるビジネス内の顧客サービスアプリケーションで通常の場合です)。

私たちの場合、50の可能なクラス(意図)のデータセットを持っており、OpenAIの事前学習済みLLMが文脈の中でクラスの違いを学ぶことができるようにします。LangChainを使用して、ラベル付き候補の例のプールから各クラスから1つのランダムな例を選択し、50ショットのプロンプトテンプレートを構築します。また、LLMの出力が有効なクラス(つまり、意図のカテゴリ)であることを確認するために、フューショットの例の前に可能なクラスをリストする文字列を追加します。
上記の50ショットのプロンプトは、LLMに各テスト例を分類させるために使用されます(上記のターゲットテキストは異なるテスト例間で変化する唯一の部分です)。これらの予測は、正解ラベルと比較され、選択されたフューショットプロンプトテンプレートを使用して生成されたLLMの精度を評価します。
ベースラインモデルのパフォーマンス
# このメソッドは以下を処理します:
# - 各テスト例の収集
# - プロンプトのフォーマット
# - LLM APIのクエリ
# - 出力の解析
def eval_prompt(examples_pool, test, prefix="", use_examples=True):
texts = test.text.values
responses = []
examples = get_examples(examples_pool, seed) if use_examples else []
for i in range(len(texts)):
text = texts[i]
prompt = get_prompt(examples_pool, text, examples, prefix)
resp = get_response(prompt)
responses.append(resp)
return responses# 上記の50-shotプロンプトを評価します。
preds = eval_prompt(examples_pool, test)
evaluate_preds(preds, test)
>>> モデルの正確度:59.6%上記の50-shotプロンプトを使用して、各テスト例をLLMを経由して実行すると、59.6%の正確度が得られます。これは50クラスの問題においては悪くはありません。しかし、私たちの銀行の顧客サービスアプリケーションには十分満足できるものではありません。したがって、データセット(つまりプール)の候補例にもう少し詳しく目を向けましょう。機械学習がうまく機能しない場合、しばしば問題の原因はデータにあります!
データの問題点
私たちのfew-shotプロンプトが抽出された候補例のプールを詳しく調査すると、データには誤ラベルが含まれており、外れ値も存在していることがわかります。以下に、明らかに誤って注釈付けされたいくつかの例を示します。

以前の研究では、データ注釈チームが完璧ではないため、多くの人気データセットに誤ラベルの例が含まれていることが観察されています。
また、顧客サービスのデータセットには、誤って含まれている範囲外の例が含まれることが一般的です。以下に、有効な銀行の顧客サービス要求に対応しないいくつかの奇妙な例があります。

なぜこれらの問題は重要なのか?
LLMのコンテキストサイズが増えるにつれて、プロンプトに多くの例を含めることが一般的になっています。したがって、少ない数の例を含むプロンプトのすべての例を手動で検証することは不可能であり、特に多くのクラスがある場合やそれらに関するドメイン知識がない場合にはなおさらです。これらのfew-shot例のデータソースには、上記のような問題が含まれている場合(実際のデータセットでは多くの場合そうです)、誤った例がプロンプトに含まれる可能性があります。この記事の残りでは、この問題の影響とその緩和方法について調査します。
LLMにノイズが含まれる可能性を警告できるか?
提供されたfew-shot例の中にいくつかのラベルが誤っている可能性があることをLLMに伝えるために、プロンプトに「免責事項の警告」を含めるだけでいいのではないでしょうか?以下は、前述の50のfew-shot例を含むプロンプトテンプレートの変更を検討しています。

prefix = 'いくつかの例のラベルにノイズが含まれ、誤って指定されている可能性があることに注意してください。'
preds = eval_prompt(examples_pool, test, prefix=prefix)
evaluate_preds(preds, test)
>>> モデルの正確度:62.0%上記のプロンプトを使用すると、62%の正確度が得られます。わずかに改善されましたが、まだ銀行の顧客サービスシステムで意図の分類にLLMを使用するには十分ではありません!
ノイズのある例を完全に削除できるか?
few-shot例のプールのラベルには信頼できないため、プロンプトからそれらを完全に削除し、強力なLLMにのみ依存することはできませんか?few-shotプロンプティングではなく、LLMの事前学習済み知識のみに頼る「zero-shotプロンプティング」を行います。

preds = eval_prompt(examples_pool, test, use_examples=False)
evaluate_preds(preds, test)
>>> モデルの正解率: 67.4%
低品質のfew-shot例を完全に削除した後、私たちは67.4%の正確さを達成しました。これは今までで最高の結果です!
実際には、ノイズの多いfew-shot例はモデルの性能を向上させるどころか、逆に損なう可能性があるようです。
ノイズのある例を特定して修正することはできるでしょうか?
プロンプトを修正したり、例を完全に削除する代わりに、データセットを改善するよりスマート(しかし複雑な)方法は、手動でラベルの問題を見つけて修正することです。これにより、モデルに損害を与えているノイズのあるデータポイントが同時に削除され、正確なデータポイントが追加されます。これにより、few-shotプロンプトを介してモデルのパフォーマンスが向上するはずですが、このような修正を手動で行うのは手間がかかります。代わりに、Confident Learningアルゴリズムを実装したCleanlab Studioというプラットフォームを使用してデータを簡単に修正します。
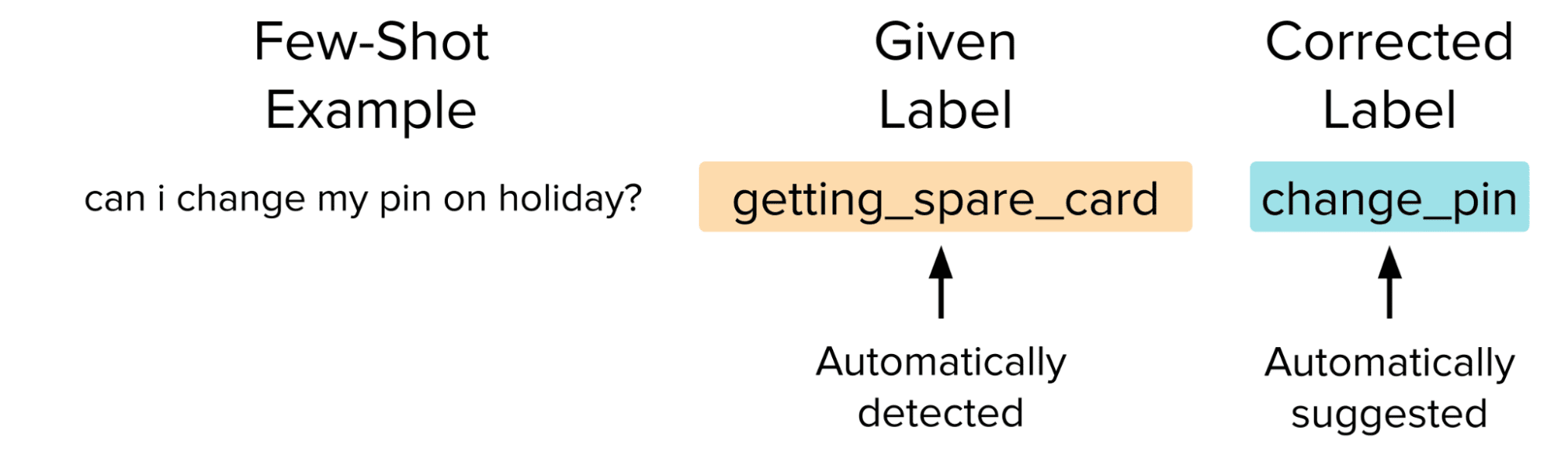
Confident Learningによって推定された悪いラベルをより適切なものに置き換えた後、元の50-shotプロンプトをLLMで再実行します。ただし、今回はLLMに50の高品質な例を提供するために自動修正されたラベルを使用します。
# 修正されたラベルを持つソースの例。
clean_pool = pd.read_csv("studio_examples_pool.csv")
clean_examples = get_examples(clean_pool)
# 高品質の例を使用して元の50-shotプロンプトを評価します。
preds = eval_prompt(clean_examples, test)
evaluate_preds(preds, test)
>>> モデルの正解率: 72.0%
これにより、50クラスの問題に対して非常に印象的な72%の正確さを達成しました。
ノイズの多いfew-shot例はLLMのパフォーマンスをかなり低下させることを示し、プロンプトを手動で変更するだけでは最適なモデルの性能を保証できないことを示しました。最高のパフォーマンスを達成するためには、Confident Learningのようなデータ中心のAI技術を使用して例を修正することもお試しください。
データ中心のAIの重要性
この記事は、特に銀行業界の顧客サービス意図分類において信頼性のあるfew-shotプロンプトの選択を確保する重要性を強調しています。大手銀行の顧客サービス要求データセットの探索とDavinci LLMを使用したfew-shotプロンプト技術の適用を通じて、ノイズや誤りのあるfew-shot例からの課題に遭遇しました。プロンプトを修正したり、例を削除するだけでは最適なモデルのパフォーマンスを保証することはできませんでした。代わりに、Cleanlab Studioなどのツールで実装されたConfident Learningなどのデータ中心のAIアルゴリズムがラベルの問題を特定して修正するのにより効果的であることが示され、正確さが大幅に向上しました。この研究は、信頼性のあるfew-shotプロンプトを得るためのアルゴリズムによるデータのキュレーションの役割を強調し、さまざまなドメインで言語モデルのパフォーマンスを向上させるためのこのような技術の有用性を示しています。 Chris MauckはCleanlabのデータサイエンティストです。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 「FreedomGPT」という名称のAI技術をご紹介しますこの技術はオープンソースであり、アルパカ上に構築され、倫理的な考慮事項を認識し優先するようにプログラムされています何の検閲フィルターもなく、自由な議論を可能にします
- 「AIイメージジェネレータとは何ですか?2023年のトップAIイメージジェネレータ」
- もう1つの大規模言語モデル!IGELに会いましょう:指示に調整されたドイツ語LLMファミリー
- 「LLMは誰の意見を反映しているのか? スタンフォード大学のこのAI論文では、言語モデルLMが一般世論調査の観点から反映している意見について検証しています」
- 「ジェイソン・フラックスとともに会話型AI製品を本番環境に展開する」
- 「AIへの恐怖は迷信的なくだらないことだ」
- 「機械学習モデルのログと管理のためのトップツール」





