「生成モデルを活用して半教師あり学習を強化する」
Enhancing semi-supervised learning with generative models.
はじめに
機械学習のダイナミックな世界では、限られたラベル付きデータのフルポテンシャルを引き出すという一つの課題が常に存在します。それに対応するために、半教師あり学習という領域が存在します。この半教師あり学習は、少量のラベル付きデータと大量のラベルなしデータを組み合わせるという独創的なアプローチです。本記事では、変分オートエンコーダ(VAEs)や生成対抗ネットワーク(GANs)といった生成モデルを活用するという、ゲームチェンジングな戦略を探求します。魅力的な旅の終わりには、これらの生成モデルが半教師あり学習アルゴリズムの性能を劇的に向上させる方法を理解していただけるでしょう。まるでドキドキするストーリーの巧妙な展開のように、これらの生成モデルが半教師あり学習に深い影響を与えることに驚かされることでしょう。
学習目標
- まず、半教師あり学習について探求し、なぜそれが重要であり、実際の機械学習シナリオでどのように使用されるのかを理解します。
- 次に、VAEsやGANsといった魅力的な生成モデルの世界に入ります。これらのモデルが半教師あり学習をどのように強化するのかを見ていきます。
- 実践的な側面についてご案内します。データの準備からモデルの訓練まで、これらの生成モデルを実世界の機械学習プロジェクトに統合する方法を学びます。
- モデルの一般化やコスト削減といったメリットを強調します。さらに、このアプローチが異なる分野にどのように適用されるかを紹介します。
- すべての旅には課題がありますが、それらを乗り越えていきます。また、生成モデルを半教師あり学習に責任を持って使用するために重要な倫理的考慮事項についても見ていきます。
この記事はデータサイエンスブログマラソンの一環として公開されました。
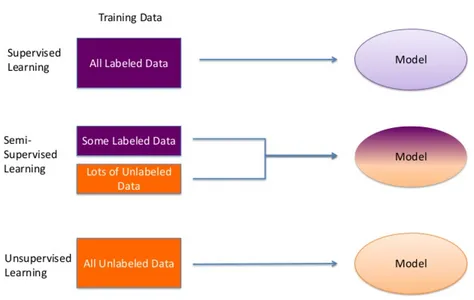
半教師あり学習への入門
機械学習の広大な領域において、ラベル付きデータの取得は困難な場合があります。データの注釈付けには時間とコストがかかることが多く、教師あり学習のスケーラビリティを制限する可能性があります。そこで登場するのが半教師あり学習です。このアプローチは、ラベル付きデータとラベルなしデータの領域とをつなぐ知恵です。ラベル付きデータは非常に重要ですが、未ラベルのデータの広大なプールはしばしば眠っており、活用されることを待っています。
例えば、画像中のさまざまな動物をコンピュータに認識させるという課題が与えられたとしましょう。しかし、それぞれの動物にラベルを付けることは困難な作業です。ここで半教師あり学習が登場します。小さなバッチのラベル付き画像と大量のラベルなし画像を組み合わせて機械学習モデルの訓練に使用することを提案します。このアプローチにより、モデルは未ラベルデータの潜在能力にアクセスし、パフォーマンスと適応性を向上させることができます。まるで情報の銀河系を航海する際の少数の導きの星のようなものです。
- TinyLlamaと出会ってください:3兆トークンで1.1Bのラマモデルを事前学習することを目指した小さなAIモデル
- アリババは、2つのオープンソースの大規模ビジョン言語モデル(LVLM)、「Qwen-VL」と「Qwen-VL-Chat」を発表しました
- 「AI時代における学術的誠実性の再考:ChatGPTと32のコースの大学生の比較分析」
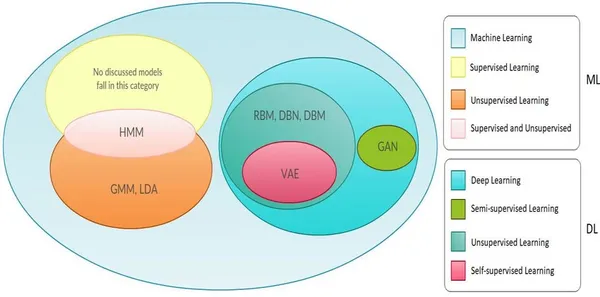
半教師あり学習を通じて、その重要性、基本原理、そして革新的な戦略を探求し、特にVAEsやGANsなどの生成モデルがその能力をいかに高めるかに焦点を当てます。生成モデルと手を取り合って、半教師あり学習の力を解き放ちましょう。
生成モデル:半教師あり学習の強化
魅力的な機械学習の世界において、生成モデルは半教師あり学習に新たな息吹を与える本当のゲームチェンジャーとして登場します。これらのモデルは、データの複雑さを理解するだけでなく、それを学んだ内容と鏡像する新しいデータを生成するというユニークな才能を持っています。この領域で最も優れたパフォーマンスを示すのは、変分オートエンコーダ(VAEs)と生成対抗ネットワーク(GANs)です。これらの生成モデルが半教師あり学習の限界を押し広げる触媒となる方法を探求する旅に出かけましょう。
VAEsはデータ分布の本質を捉えることに優れています。これは、入力データを隠れた空間にマッピングし、それを念入りに再構築することで実現されます。この能力は、半教師あり学習において意味のある簡潔なデータ表現をモデルに抽出するために大きな役割を果たします。これらの表現は、豊富なラベル付きデータの必要性を排除することなく、限られたラベル付き例に直面しても改善された一般化の鍵となります。一方、GANsは魅力的な対抗的なダンスを演じます。ここでは、生成器が実データと区別できないデータを作り出すことを目指し、識別器が厳しい批評家の役割を果たします。このダイナミックなデュエットにより、データの拡張が行われ、完全に新しいデータの生成への道が開かれます。VAEsとGANsがスポットライトを浴びるのは、この魅力的なパフォーマンスを通じて、半教師あり学習の新たな時代を切り拓くからです。
実践的な実装手順
理論的な側面を探求した後は、袖をまくってジェネレーティブモデルを用いた半教師あり学習の実践的な実装に入りましょう。ここで魔法が起こります。アイデアを現実の解決策に変える場所です。以下は、このシナジーを実現するために必要な手順です:

ステップ1:データの準備 – 舞台の設定
良い基盤を持つことは、どんなよく計画されたプロダクションにも必要です。まずデータを収集しましょう。ラベル付きデータの小さなセットと、ラベルのないデータの豊富なリザーバを用意してください。データがきれいで整理され、準備が整っていることを確認してください。
# データの読み込みと前処理の例
import pandas as pd
from sklearn.model_selection import train_test_split
# ラベル付きデータの読み込み
labeled_data = pd.read_csv('labeled_data.csv')
# ラベルのないデータの読み込み
unlabeled_data = pd.read_csv('unlabeled_data.csv')
# データの前処理(正規化、欠損値の処理など)
labeled_data = preprocess_data(labeled_data)
unlabeled_data = preprocess_data(unlabeled_data)
# ラベル付きデータをトレーニングと検証のセットに分割
train_data, validation_data = train_test_split(labeled_data, test_size=0.2, random_state=42)
#import csvステップ2:ジェネレーティブモデルの組み込み – 特殊効果
主役であるジェネレーティブモデルが登場します。バリエーショナルオートエンコーダ(VAE)や敵対的生成ネットワーク(GAN)を半教師あり学習パイプラインに統合してください。ラベルのないデータでジェネレーティブモデルをトレーニングするか、データ拡張に使用することができます。これらのモデルは、半教師あり学習を輝かせる特殊効果を追加します。
# データ拡張のためのVAEの統合の例
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Input, Lambda
from tensorflow.keras import Model
# VAEのアーキテクチャを定義(エンコーダとデコーダ)
# ...(エンコーダの層を定義)
# ...(デコーダの層を定義)
# VAEモデルを作成
vae = Model(inputs=input_layer, outputs=decoded)
# VAEモデルのコンパイル
vae.compile(optimizer='adam', loss='mse')
# ラベルのないデータでVAEを事前学習
vae.fit(unlabeled_data, unlabeled_data, epochs=10, batch_size=64)
#import csvステップ3:半教師あり学習のトレーニング – アンサンブルのリハーサル
いよいよ半教師あり学習モデルのトレーニングの時間です。ジェネレーティブモデルによって生成されたデータをラベル付きデータと組み合わせてください。このデータのアンサンブルキャストは、モデルが重要な特徴を抽出し、効果的に一般化する力を与えます。まるで経験豊富な俳優が役柄を見事に演じるように。
# TensorFlow/Kerasを使用した半教師あり学習の例
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# 半教師ありモデル(ニューラルネットワークなど)を作成
model = Sequential()
# 層を追加(入力層、隠れ層、出力層など)
model.add(Dense(128, activation='relu', input_dim=input_dim))
model.add(Dense(64, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
# モデルをコンパイル
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# ラベル付きデータと拡張データの両方でモデルをトレーニング
model.fit(
x=train_data[['feature1', 'feature2']], # 関連する特徴量を使用
y=train_data['label'], # ラベル付きデータのラベル
epochs=50, # 必要に応じて調整
batch_size=32,
validation_data=(validation_data[['feature1', 'feature2']], validation_data['label'])
)ステップ4:評価と微調整 – ドレスリハーサル
モデルのトレーニングが完了したら、ドレスリハーサルの時間です。別の検証データセットを使用してモデルのパフォーマンスを評価します。その結果に基づいてモデルを微調整します。演出家がパフォーマンスを完璧にするように、反復して洗練させ、最適な結果を得るまで微調整を行います。
# モデルの評価と微調整のためのサンプルコード
from sklearn.metrics import accuracy_score
# バリデーションセット上で予測を行う
y_pred = model.predict(validation_data[['feature1', 'feature2']])
# 正解率を計算する
accuracy = accuracy_score(validation_data['label'], y_pred.argmax(axis=1))
# バリデーション結果に基づいてハイパーパラメータやモデルの構造を微調整する
# 最適なパフォーマンスが得られるまで繰り返すこれらの実践的な手順では、コンセプトを具体的な行動に変換し、コードスニペットを使ってガイドします。これにより、生成モデルによってパワードされた半教師あり学習モデルがスポットライトに輝く場面が生まれます。それでは、進んで実装を見てみましょう。
利点と実世界の応用
生成モデルと半教師あり学習を組み合わせることで、驚くべき結果が得られます。以下の理由から重要です:
1. 汎化性能の向上:ラベルのないデータを利用することで、この方法で訓練されたモデルは限られたラベル付きの例でも優れたパフォーマンスを発揮します。まるで最小限のリハーサルでも舞台で輝く才能ある俳優のようです。
2. データ拡張:VAEやGANのような生成モデルは、豊富な拡張データの源となります。これにより、モデルの頑健性が向上し、過学習を防ぎます。まるで独自の小道具部門が無限のシーンのバリエーションを作り出すようです。
3. アノテーションコストの削減:データのアノテーションには費用がかかる場合があります。生成モデルを統合することで、データのアノテーションの必要性を減らし、製作予算を最適化することができます。
4. ドメイン適応:この手法は、少量のラベル付きデータで新しい未知のドメインに適応するのが得意です。まるで俳優がさまざまな役柄をシームレスに移り変わるかのようです。
5. 実世界の応用:可能性は広がります。自然言語処理では、感情分析、言語翻訳、テキスト生成を向上させます。コンピュータビジョンでは、画像分類、物体検出、顔認識を高めます。医療では疾患診断、金融では詐欺検出、自動運転では知覚の向上に貴重な資産となります。
これは単なる理論だけではありません。多様な産業において実践的なゲームチェンジャーであり、魅力的な結果とパフォーマンスを約束するものであり、長く残る影響を与えるような見事に実行された映画のようなものです。
課題と倫理的な考慮事項
生成モデルを使用した半教師あり学習のエキサイティングな領域を探索する中で、この革新的なアプローチに伴う課題と倫理的な考慮事項に光を当てる必要があります。
- データの品質と分布:トレーニングに使用するデータの品質と代表性を確保することは、主な課題の1つです。バイアスのあるデータやノイズのあるデータは、全体のプロダクションに影響を与える欠陥のある台本のような結果になる可能性があります。
- 複雑なモデルトレーニング:生成モデルを統合することで、トレーニングプロセスに複雑さが導入されます。これには、従来の機械学習だけでなく、生成モデリングの微妙なニュアンスにも専門知識が必要です。
- データのプライバシーとセキュリティ:大量のデータを扱う際には、データのプライバシーとセキュリティを確保することが重要です。機密性の高い情報の取り扱いには厳格なプロトコルが必要であり、エンターテイメント業界で機密のスクリプトを保護するのと同様です。
- バイアスと公平さ:生成モデルの使用には、生成されたデータにバイアスが生じたり、モデルの意思決定に影響を与えるバイアスが生じることがないように注意する必要があります。
- 規制の遵守:医療や金融など、多くの産業にはデータ使用に関する厳格な規制があります。これらの規制に従うことは義務です。まるでプロダクションが業界の基準に準拠するようにするのと同様です。
- 倫理的なAI:AIや機械学習の社会への影響に関する包括的な倫理的な考慮事項があります。これらの技術の利益がすべてに対してアクセス可能かつ公平であることを確保することは、エンターテイメント界での多様性と包括性の促進と同じです。
これらの課題と倫理的な考慮事項に取り組む際には、生成モデルを半教師あり学習に統合するために、注意深く責任を持って取り組む必要があります。思考を刺激し、社会的な意識を持った芸術作品を作り上げるようなアプローチであり、社会を豊かにする一方で、害を最小限に抑えることを目指すべきです。

実験結果と事例研究
さて、本題に入りましょう。生成モデルと半教師あり学習の組み合わせによる具体的な影響を示す実験結果について詳しく見ていきましょう。
- 画像分類の改善:コンピュータビジョンの領域では、研究者が生成モデルを使用してラベル付きデータセットを拡張するための実験を行いました。その結果、この手法で訓練されたモデルは、従来の教師あり学習方法と比べて、はるかに高い精度を示しました。
- 限られたデータでの言語翻訳:自然言語処理の分野では、半教師あり学習と生成モデルを組み合わせたケーススタディが、言語翻訳における効果を証明しました。わずかなラベル付き翻訳データと大量の単言語データだけで、モデルは印象的な翻訳精度を達成しました。
- 医療診断:医療に注目すると、実験ではこの手法の医療診断への潜在能力が示されました。ラベル付きの医療画像が不足している中、生成モデルによる半教師あり学習により、病気の正確な検出が可能になりました。
- 金融における詐欺検出:金融業界では、ケーススタディが生成モデルと半教師あり学習の組み合わせによる詐欺検出の優れた能力を示しました。ラベル付きのデータを例として増やすことで、モデルは詐欺取引の高い精度で識別することができました。
半教師あり学習は、異なる分野の専門家が協力して素晴らしいものを作り出すように、さまざまなドメインで顕著な成果をもたらすことを示しています。
結論
生成モデルと半教師あり学習の探究により、MLを革新する可能性を秘めた画期的な手法が明らかになりました。この強力なシナジーは、ラベル付きデータが不足する領域においてモデルが繁栄するための解決策です。まとめると、この統合はパラダイムの転換を象徴し、人工知能の領域を再定義するものであることが明らかです。
重要なポイント
1. 融合による効率化:生成モデルを用いた半教師あり学習は、ラベル付きと未ラベルのデータのギャップを埋めることで、より効率的かつ費用効果の高い機械学習の手段を提供します。
2. 生成モデルの主役:変分オートエンコーダ(VAE)や敵対的生成ネットワーク(GAN)は、学習プロセスを高めるための重要な役割を果たしており、演技を引き立てる才能ある共演者と同様です。
3. 実装の実践的な手順:実装には、データの準備、生成モデルのシームレスな統合、厳格なトレーニング、反復的な改善、倫理的な考慮事項などが含まれます。これは、大規模な制作の緻密な計画と同様です。
4. 多様な現実世界への影響:この手法の利点は、医療から金融まで多様な分野に広がります。異なる観客に響く異なるユニークな脚本のように、この手法の適用範囲と現実世界での実用性を示しています。
5. 倫理的な責任:どんなツールでも、倫理的な考慮事項が最優先です。公正さ、プライバシー、責任あるAIの使用を確保することは、芸術やエンターテイメント業界の倫理基準を維持することと同様です。
よくある質問
この記事に表示されるメディアはAnalytics Vidhyaの所有ではなく、著者の裁量で使用されています。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






