「Amazon LexをLLMsで強化し、URLの取り込みを使用してFAQの体験を向上させる」
Enhancing Amazon Lex with LLMs and improving the FAQ experience using URL ingestion.
今日のデジタルワールドでは、消費者の多くは企業やサービスプロバイダーに連絡する時間をかけるよりも、自分でカスタマーサービスの質問に対する答えを見つけることを望んでいます。このブログ記事では、既存のウェブサイトのFAQを使用して、Amazon Lexで質問と回答のチャットボットを構築する革新的なソリューションについて探求します。このAIパワードツールは、実世界の問い合わせに迅速かつ正確な回答を提供し、顧客が一般的な問題を独自に迅速かつ簡単に解決できるようにします。
単一URLの取り込み
多くの企業は、顧客向けのFAQの答えをウェブサイトで公開しています。この場合、公開されたFAQから顧客の質問に答えるチャットボットを提供したいと考えています。Amazon LexとLlamaIndexの組み合わせを使用して、PDFやWordドキュメントなどの既存の知識源を活用して、チャットボットを構築する方法については、「LLMsを使用した対話型FAQ機能でAmazon Lexを強化する」のブログ記事で示されています。ウェブサイトのFAQに基づくシンプルなFAQをサポートするためには、ウェブサイトをクロールし、LlamaIndexが顧客の質問に答えるために使用できる埋め込みを作成する取り込みプロセスを作成する必要があります。この場合、ウェブサイトのFAQから回答を返すボットを前のブログ記事で作成したボットをベースに構築します。
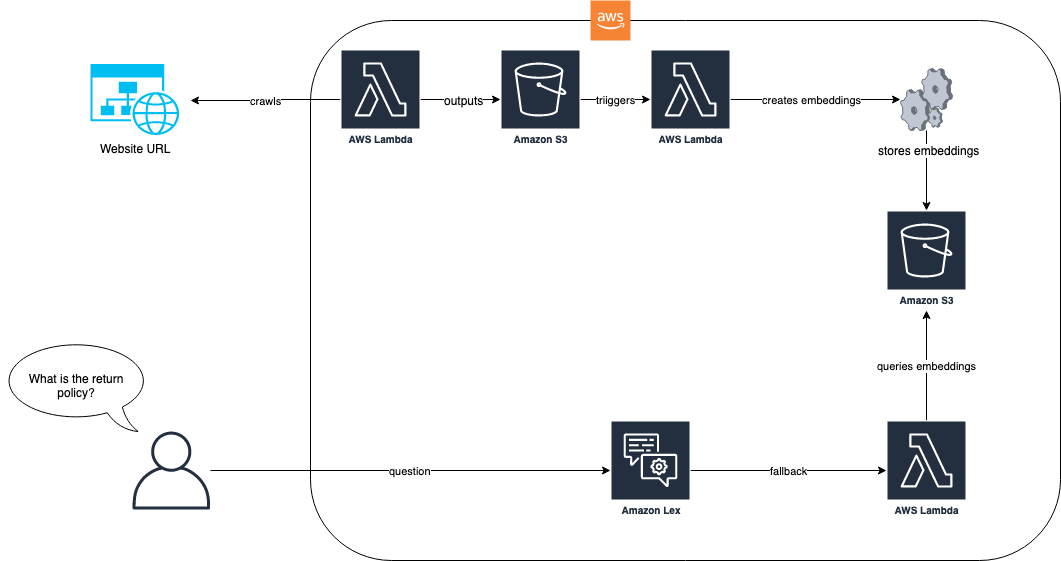
以下の図は、取り込みプロセスとAmazon Lexボットがソリューションでどのように連携するかを示しています。
- 「LLMを使用して、会話型のFAQ機能を搭載したAmazon Lexを強化する」
- OpenAIを使用してカスタムチャットボットを開発する
- Amazon SageMakerを使用して電子メールのスパム検出器を構築する
ソリューションのワークフローでは、FAQを持つウェブサイトはAWS Lambdaを介して取り込まれます。このLambda関数はウェブサイトをクロールし、その結果のテキストをAmazon Simple Storage Service(Amazon S3)バケットに保存します。S3バケットは、LlamaIndexが格納されている埋め込みを作成するLambda関数をトリガーします。エンドユーザーからの質問(例:”返品ポリシーは何ですか?”)が届くと、Amazon LexボットはLlamaIndexを使用して埋め込みをクエリし、RAGベースのアプローチを使用して回答を返します。このアプローチと前提条件についての詳細は、「LLMsを使用した対話型FAQ機能でAmazon Lexを強化する」のブログ記事を参照してください。
前述のブログ記事の前提条件が完了したら、最初のステップはFAQをドキュメントリポジトリに取り込み、LlamaIndexによってベクトル化およびインデックス化されることです。次のコードは、これを実現する方法を示しています:
import logging
import sys
import requests
import html2text
from llama_index.readers.schema.base import Document
from llama_index import GPTVectorStoreIndex
from typing import List
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
class EZWebLoader:
def __init__(self, default_header: str = None):
self._html_to_text_parser = html2text()
if default_header is None:
self._default_header = {"User-agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36"}
else:
self._default_header = default_header
def load_data(self, urls: List[str], headers: str = None) -> List[Document]:
if headers is None:
headers = self._default_header
documents = []
for url in urls:
response = requests.get(url, headers=headers).text
response = self._html2text.html2text(response)
documents.append(Document(response))
return documents
url = "http://www.zappos.com/general-questions"
loader = EZWebLoader()
documents = loader.load_data([url])
index = GPTVectorStoreIndex.from_documents(documents)前述の例では、Zapposの事前定義されたFAQウェブサイトのURLをEZWebLoaderクラスを使用して取り込みます。このクラスでは、URLに移動し、ページにあるすべての質問をインデックスに読み込みます。これで、「Zapposはギフトカードを持っていますか?」という質問をすることができ、ウェブサイトのFAQから直接回答を得ることができます。次のスクリーンショットは、Amazon LexボットのテストコンソールがFAQからその質問に回答している様子を示しています。

最初のステップでURLをクロールし、LlamaIndexが質問の答えを検索するために使用できる埋め込みを作成したため、これを実現することができました。ボットのLambda関数は、フォールバックインテントが返されるたびにこの検索が実行される方法を示しています:
import time
import json
import os
import logging
import boto3
from llama_index import StorageContext, load_index_from_storage
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
def download_docstore():
# S3クライアントを作成する
s3 = boto3.client('s3')
# S3バケット内のすべてのオブジェクトをリストし、それぞれをダウンロードする
try:
bucket_name = 'faq-bot-storage-001'
s3_response = s3.list_objects_v2(Bucket=bucket_name)
if 'Contents' in s3_response:
for item in s3_response['Contents']:
file_name = item['Key']
logger.debug("Downloading to /tmp/" + file_name)
s3.download_file(bucket_name, file_name, '/tmp/' + file_name)
logger.debug('All files downloaded from S3 and written to local filesystem.')
except Exception as e:
logger.error(e)
raise e
# ドキュメントストアをローカルにダウンロードする
download_docstore()
storage_context = StorageContext.from_defaults(persist_dir="/tmp/")
# インデックスをロードする
index = load_index_from_storage(storage_context)
query_engine = index.as_query_engine()
def lambda_handler(event, context):
"""
インテントに基づいて、着信リクエストをルーティングする。
リクエストのJSONボディは、イベントスロット内に提供される。
"""
# ユーザーリクエストをデフォルトでAmerica/New_Yorkのタイムゾーンからのものとして扱う
os.environ['TZ'] = 'America/New_York'
time.tzset()
logger.debug("===== START LEX FULFILLMENT ====")
logger.debug(event)
slots = {}
if "currentIntent" in event and "slots" in event["currentIntent"]:
slots = event["currentIntent"]["slots"]
intent = event["sessionState"]["intent"]
dialogaction = {"type": "Delegate"}
message = []
if str.lower(intent["name"]) == "fallbackintent":
# ユーザーが入力したクエリからクエリを実行する
response = str.strip(query_engine.query(event["inputTranscript"]).response)
dialogaction["type"] = "Close"
message.append({'content': f'{response}', 'contentType': 'PlainText'})
final_response = {
"sessionState": {
"dialogAction": dialogaction,
"intent": intent
},
"messages": message
}
logger.debug(json.dumps(final_response, indent=1))
logger.debug("===== END LEX FULFILLMENT ====")
return final_responseこのソリューションは、単一のウェブページにすべての回答がある場合にはうまく機能します。しかし、ほとんどのFAQサイトは単一のページ上に構築されていません。たとえば、Zapposの例では、「価格の一致ポリシーはありますか?」という質問をすると、次のスクリーンショットに示すように、満足のいく回答は得られません。
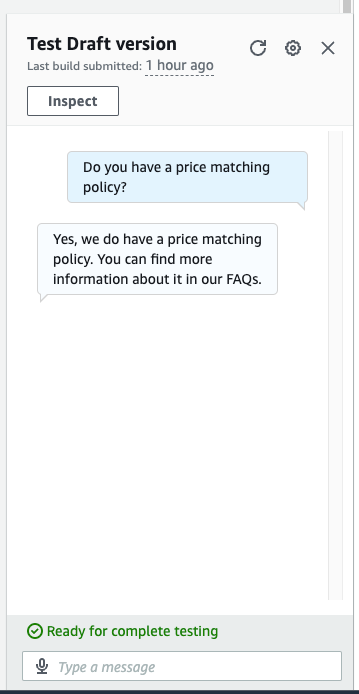
上記の対話では、価格一致ポリシーの回答はユーザーにとって役立ちません。この回答は短くなっています。なぜなら、参照されるFAQは価格一致ポリシーに関する特定のページへのリンクであり、私たちのウェブクロールは単一のページのみに対して行われたからです。より良い回答を得るには、これらのリンクもクロールする必要があります。次のセクションでは、2つ以上のページの深さが必要な質問に対する回答の取得方法を示します。
Nレベルのクローリング
FAQの知識をウェブページでクロールする際、必要な情報はリンクされたページに含まれることがあります。たとえば、Zapposの例では、「価格の一致ポリシーはありますか?」という質問に対して「はい、詳細は<link>をご覧ください。」という回答が得られます。したがって、「価格の一致ポリシーは何ですか?」という質問に対しては、ポリシーを含んだ完全な回答を提供したいと考えています。これを達成するためには、エンドユーザーのための実際の情報を取得するためにリンクをトラバースする必要があります。データ取り込みプロセスでは、ウェブローダーを使用して他のHTMLページへのアンカーリンクを見つけ、それらをトラバースすることができます。以下のコード変更は、クロールしたページでリンクを見つけることができるようにします。また、循環クローリングを防ぐための追加のロジックと、接頭辞によるフィルタリングを許可するようになっています。
import logging
import requests
import html2text
from llama_index.readers.schema.base import Document
from typing import List
import re
def find_http_urls_in_parentheses(s: str, prefix: str = None):
pattern = r'\((https?://[^)]+)\)'
urls = re.findall(pattern, s)
matched = []
if prefix is not None:
for url in urls:
if str(url).startswith(prefix):
matched.append(url)
else:
matched = urls
return list(set(matched)) # 重複を削除するためにセットに変換してからリストに戻す
class EZWebLoader:
def __init__(self, default_header: str = None):
self._html_to_text_parser = html2text
if default_header is None:
self._default_header = {"User-agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36"}
else:
self._default_header = default_header
def load_data(self,
urls: List[str],
num_levels: int = 0,
level_prefix: str = None,
headers: str = None) -> List[Document]:
logging.info(f"Number of urls: {len(urls)}.")
if headers is None:
headers = self._default_header
documents = []
visited = {}
for url in urls:
q = [url]
depth = num_levels
for page in q:
if page not in visited: # リンクをすでにクロールしているかどうかを確認して循環を防止する
logging.info(f"Crawling {page}")
visited[page] = True # クロールしたページを再クロールしないようにvisitedにエントリを追加する
response = requests.get(page, headers=headers).text
response = self._html_to_text_parser.html2text(response) # HTMLをテキストに縮小する
documents.append(Document(response))
if depth > 0:
# リンクされたページをクロールする
ingest_urls = find_http_urls_in_parentheses(response, level_prefix)
logging.info(f"Found {len(ingest_urls)} pages to crawl.")
q.extend(ingest_urls)
depth -= 1 # 深さカウンタを減らしてクロールをnum_levelsまで行う
else:
logging.info(f"Skipping {page} as it has already been crawled")
logging.info(f"Number of documents: {len(documents)}.")
return documents
url = "http://www.zappos.com/general-questions"
loader = EZWebLoader()
# サイトを1レベルの深さでクロールし、カスタマーサービスのルートに対する接頭辞として"/c/"を使用する
documents = loader.load_data([url]
num_levels=1, level_prefix="https://www.zappos.com/c/")
index = GPTVectorStoreIndex.from_documents(documents)前述のコードでは、Nレベルまでクロールする能力を導入し、特定のURLパターンで始まるものにのみクロールを制限するためのプレフィックスを与えます。Zapposの例では、顧客サービスページはすべてzappos.com/cからルートされているため、より小さなかつ関連性の高いサブセットにクロールを制限するためにそれをプレフィックスとして含めます。このコードでは、最大2レベルまで取り込むことができる方法が示されています。クローラーのLambdaロジックは変わらず、ドキュメントの取り込みが増えただけです。
今やすべてのドキュメントがインデックスされ、より詳細な質問ができます。以下のスクリーンショットでは、ボットが質問「価格のマッチングポリシーはありますか?」に正しい答えを提供しています。

価格のマッチングに関する質問に対する完全な答えが得られました。単に「はい、ポリシーをご覧ください」と言われるだけでなく、2レベル目のクロールからの詳細が提供されます。
クリーンアップ
将来の費用を発生させないために、この演習の一部として展開されたすべてのリソースを削除してください。Sagemakerエンドポイントを正常にシャットダウンするためのスクリプトを用意しました。使用方法の詳細はREADMEを参照してください。また、他のすべてのリソースを削除するには、cdkコマンドと同じディレクトリでcdk destroyを実行してスタック内のすべてのリソースを解除できます。
結論
FAQのセットをチャットボットに取り込む能力により、お客様は簡単な自然言語のクエリで質問の答えを見つけることができます。Amazon Lexのフォールバック処理の組み込みサポートとLlamaIndexなどのRAGソリューションの組み合わせにより、FAQに対して満足のいく、厳選された、承認済みの回答への素早い経路を提供することができます。ソリューションにNレベルのクローリングを適用することで、複数のFAQリンクにまたがる回答や、顧客のクエリに対するより深い回答を可能にすることができます。これらの手順に従うことで、強力なLLMベースのQ&A機能と効率的なURLの取り込みをAmazon Lexのチャットボットにシームレスに組み込むことができます。これにより、ユーザーとの対話がより正確で包括的で文脈を理解したものになります。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






