「LLMを使用して、会話型のFAQ機能を搭載したAmazon Lexを強化する」
Enhancing Amazon Lex with conversational FAQ functionality using LLM.
Amazon Lexは、Amazon Connectなどのアプリケーションに対して、会話型ボット(”チャットボット”)、仮想エージェント、インタラクティブ音声応答(IVR)システムを迅速かつ簡単に構築できるサービスです。
人工知能(AI)と機械学習(ML)は、Amazonが20年以上にわたり焦点としてきた領域であり、顧客がAmazonを使用する際に利用される多くの機能は、MLによって駆動しています。現在、大規模言語モデル(LLM)は、開発者や企業が自然言語理解(NLU)に関連する伝統的に複雑な課題を解決する方法を変革しています。私たちは最近、Amazon Bedrockを発表しました。これは、開発者がAWSのツールや機能を使って簡単にジェネレーティブAIベースのアプリケーションを構築し、スケールさせるための基盤モデルへのアクセスを民主化するものです。企業が直面する課題の一つは、ビジネス知識をLLMに組み込んで正確かつ関連性のある応答を提供することです。効果的に活用すると、企業の知識ベースは、カスタマーが問題を独自に解決するのに役立つ情報を提供することで、自己サービスおよびアシストサービスのエクスペリエンスをカスタマイズするために使用できます。現在、ボット開発者は、Amazon Lexボット内でLLMを使用せずに自己サービスのエクスペリエンスを向上させることができます。まず、インテント、サンプル発話、および応答を作成することで、Amazon Lexボット内の予想されるすべてのユーザーの質問をカバーします。また、開発者は、検索ソリューションともボットを統合することができます。これにより、幅広いリポジトリに保存されているドキュメントをインデックス化し、カスタマーの質問に最も関連性の高いドキュメントを見つけることができます。これらの方法は効果的ですが、開発リソースが必要であり、始めるのが難しいです。
LLMが提供する利点の一つは、関連性の高い魅力的な対話型自己サービスエクスペリエンスを作成できることです。これは、企業の知識ベースを活用し、より正確でコンテキストに即した応答を提供することによって実現されます。このブログ記事では、Retrieval Augmented Generation(RAG)を使用してAmazon LexにLLMベースのFAQ機能を追加する強力なソリューションを紹介します。RAGアプローチを使用して、企業のデータソースを活用してAmazon LexのFAQ応答を強化する方法を見ていきます。さらに、LlamaIndexとのAmazon Lexの統合もデモンストレーションします。LlamaIndexは、ボット開発者に知識ソースとフォーマットの柔軟性を提供するオープンソースのデータフレームワークです。ボット開発者がLLM統合を探索するためのLlamaIndexの使用に自信を持つようになると、Amazon Lexの機能をさらにスケーリングすることができます。また、Amazon Lexとネイティブに統合されたエンタープライズ検索サービスであるAmazon Kendraも利用できます。
このソリューションでは、Amazon Lexのチャットボットを使用したLLMベースのRAGの拡張の実際の応用を紹介します。Zapposのカスタマーサポートのユースケースを例に、このソリューションの効果を実証します。これにより、ユーザーはデフォルトのフォールバック(LLMなし)ではなく、強化されたFAQエクスペリエンス(LLM付き)を経て問題を解決できます。
- OpenAIを使用してカスタムチャットボットを開発する
- Amazon SageMakerを使用して電子メールのスパム検出器を構築する
- メタからのLlama 2基盤モデルは、Amazon SageMaker JumpStartで利用可能になりました
ソリューションの概要
RAGは、従来の検索ベースとジェネレーティブAIベースのQ&Aシステムの強みを組み合わせた手法です。この手法は、Amazon Titanなどの大規模言語モデルやオープンソースモデル(たとえばFalcon)などの言語モデルを使用して、検索システムで生成タスクを実行します。また、保存されたドキュメントからの意味的なコンテキストも効果的かつ効率的に考慮します。
RAGは、初期の検索ステップでユーザーのクエリに基づいて関連するドキュメントを取得します。次に、言語モデルを使用して、取得したドキュメントと元のクエリの両方を考慮して応答を生成します。RAGをAmazon Lexに統合することで、ユーザーのクエリに正確かつ包括的な回答を提供し、より魅力的で満足度の高いユーザーエクスペリエンスを実現することができます。
RAGアプローチでは、LLMベースの検索を可能にするためにドキュメントのインジェスションが必要です。次の図は、インジェスションプロセスが新しいドキュメントをインジェストし、その埋め込みを別のS3バケットに配置する様子を示しています。これらの埋め込みは、Amazon Lexボットのフォールバック時に使用され、カスタマーの質問に答えるために活用されます。
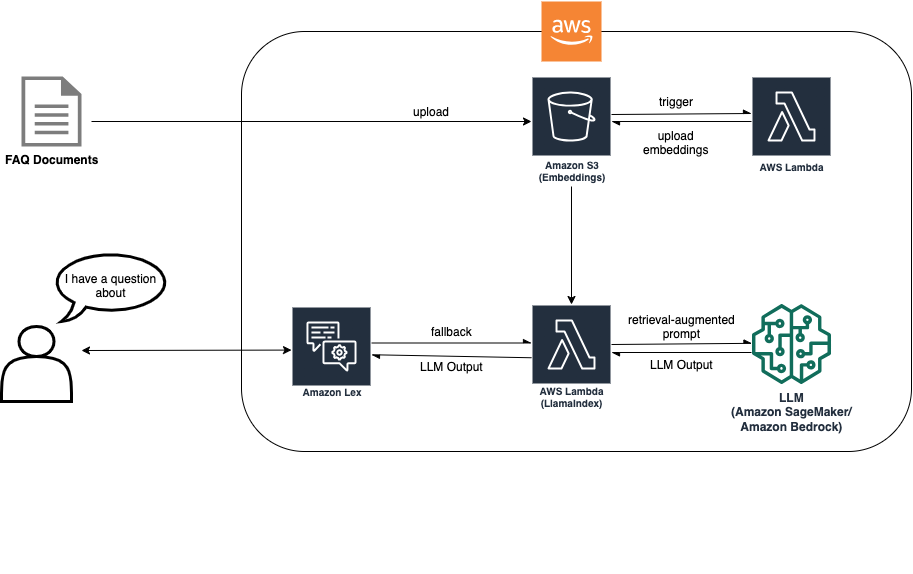
このソリューションアーキテクチャでは、ユースケースに最適なLLMを選択する必要があります。また、Amazon Simple Storage Service(Amazon S3)バケットにドキュメントをアップロードします。S3バケットには、バケットの変更時にAWS Lambda関数を呼び出すイベントリスナーがアタッチされています。イベントリスナーは、新しいドキュメントをインジェストし、埋め込みを別のS3バケットに配置します。これらの埋め込みは、Amazon Lexボットのフォールバックインテント中にRAGの実装によって使用され、カスタマーの質問に答えるために活用されます。次の図は、Amazon Lex内のFAQボットがLLMとRAGで強化される方法を示しています。
RAGベースのLlamaIndexをAmazon Lexボットに統合する方法を探ってみましょう。統合の設定を支援するコード例やAWS Cloud Development Kit(AWS CDK)のインポートを提供しています。コード例は、GitHubリポジトリで入手できます。次のセクションでは、環境のセットアップと必要なリソースのデプロイを支援するステップバイステップガイドを提供します。
RAGがAmazon Lexと連携する方法
RAGのフローは、リトリーバコンポーネントが関連するパッセージを取得し、質問とパッセージがプロンプトの構築に役立ち、生成コンポーネントが応答を生成するという反復的なプロセスに基づいています。このリトリーバと生成の組み合わせにより、RAGモデルは両方のアプローチの強みを活用し、ユーザーの質問に正確かつ文脈に適した回答を提供することができます。このワークフローには、以下の機能が提供されます:
- リトリーバエンジン – RAGモデルは、大規模なコーパスから関連するドキュメントを取得するためのリトリーバコンポーネントから開始します。このコンポーネントは通常、TF-IDFやBM25などの情報検索技術を使用して、与えられた質問に答えを含む可能性が高いドキュメントをランク付けして選択します。リトリーバはドキュメントコーパスをスキャンし、関連するパッセージのセットを取得します。
- プロンプトの作成支援 – リトリーバが関連するパッセージを特定した後、RAGモデルはプロンプトの作成に移ります。プロンプトは質問と取得したパッセージの組み合わせであり、生成コンポーネントへの入力として使用される追加のコンテキストとなります。モデルは通常、選択されたパッセージを特定の形式で質問に追加してプロンプトを作成します。
- 応答生成 – 質問と関連するパッセージから構成されるプロンプトは、RAGモデルの生成コンポーネントに供給されます。生成コンポーネントは通常、プロンプトを通じて推論を行い、一貫性のある適切な応答を生成することができる言語モデルです。
- 最終的な応答 – 最後に、RAGモデルは最もランクの高い回答を出力として選択し、元の質問に対する応答として提示します。選択された回答は、ユーザーに返される前に必要に応じてさらに後処理や書式設定が行われることがあります。さらに、このソリューションでは、検索結果が信頼スコアが低い場合、つまり分布外の可能性が高い場合に、生成された応答のフィルタリングを有効にすることができます。
LlamaIndex:LLMベースのアプリケーション向けのオープンソースデータフレームワーク
この記事では、LlamaIndexをベースにしたRAGソリューションを紹介します。LlamaIndexは、LLMベースのアプリケーションを容易にするために特別に設計されたオープンソースのデータフレームワークです。さまざまな形式のドキュメントコレクションの管理において、堅牢かつスケーラブルなソリューションを提供します。LlamaIndexを使用することで、ボット開発者は大規模なドキュメントコレクションに対応したソリューションの管理に関連する複雑さを取り除きながら、LLMベースのQA(質問応答)機能をシームレスに統合することができます。さらに、このアプローチは、小規模なドキュメントリポジトリに対しても費用効果が高いことが証明されています。
前提条件
以下の前提条件を満たしている必要があります:
- AWSアカウント
- AWS Identity and Access Management(IAM)ユーザーおよびロールのアクセス権限を持っていること
- Amazon Lex
- Lambda
- Amazon SageMaker
- S3バケット
- AWS CDKがインストールされていること
開発環境のセットアップ
主なサードパーティのパッケージ要件は、llama_indexとsagemaker sdkです。環境を適切に設定するために、GitHubリポジトリのREADMEに指定されたコマンドに従ってください。
必要なリソースのデプロイ
このステップでは、Amazon Lexボット、S3バケット、およびSageMakerエンドポイントの作成が必要です。さらに、DockerイメージディレクトリのコードをDockerイメージに含め、イメージをAmazon Elastic Container Registry(Amazon ECR)にプッシュして、Lambdaで実行できるようにする必要があります。サービスをデプロイするために、GitHubリポジトリのREADMEに指定されたコマンドに従ってください。
このステップでは、SageMaker Deep Learning Containersを介したLLMホスティングをデモンストレーションします。計算ニーズに応じて設定を調整してください:
- モデル – 要件を満たすモデルを見つけるために、Hugging Faceモデルハブなどのリソースを探索することができます。Falcon 7BやFlan-T5-XXLなど、さまざまなモデルが提供されています。さらに、公式にサポートされているさまざまなモデルアーキテクチャの詳細な情報も提供されており、情報を基に適切な決定をすることができます。さまざまなモデルタイプの詳細については、最適化されたアーキテクチャについての情報を参照してください。
- モデル推論エンドポイント – モデルのパス(例:Falcon 7B)を定義し、インスタンスタイプ(例:g5.4xlarge)を選択し、量子化(例:int-8量子化)を使用します。注:このソリューションでは、別のモデル推論エンドポイントを選択する柔軟性が提供されます。Amazon Titanなどの他のLLMにアクセスできるAmazon Bedrockを使用することもできます。注:このソリューションでは、別のモデル推論エンドポイントを選択する柔軟性が提供されます。Amazon Titanなどの他のLLMにアクセスできるAmazon Bedrockを使用することもできます。
LlamaIndexを使用してドキュメントインデックスを設定する
ドキュメントインデックスを設定するには、まずドキュメントデータをアップロードしてください。FAQのコンテンツのソース(PDFやテキストファイルなど)をお持ちだと仮定しています。
ドキュメントデータがアップロードされると、LlamaIndexシステムは自動的にドキュメントインデックスの作成プロセスを開始します。このタスクはLambda関数によって実行され、インデックスが生成されてS3バケットに保存されます。
関連情報の効率的な検索を可能にするために、LlamaIndex Retriever Query Engineを使用してドキュメントリトリーバを設定してください。このエンジンでは、以下のようないくつかのカスタマイズオプションが提供されています:
- 埋め込みモデル – Hugging Face埋め込みなど、埋め込みモデルを選択できます。
- 信頼度のカットオフ – 検索結果の品質を決定するための信頼度のカットオフ閾値を指定します。信頼度スコアがこの閾値を下回る場合、インデックスされたドキュメントの範囲外の応答を提供することができます。
統合のテスト
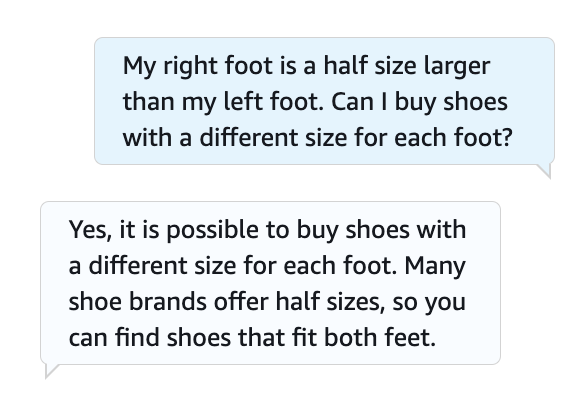
フォールバックインテントを持つボット定義を定義し、Amazon Lexコンソールを使用してFAQのリクエストをテストしてください。詳細については、GitHubリポジトリを参照してください。以下のスクリーンショットは、ボットとの例の会話を示しています。

ボットの効率を向上させるためのヒント
以下のヒントは、ボットの効率をさらに向上させる可能性があります:
- インデックスの保存 – インデックスをS3バケットやAmazon OpenSearchなどのベクトルデータベース機能を持つサービスに保存します。クラウドベースのストレージソリューションを利用することで、インデックスのアクセシビリティとスケーラビリティを向上させ、検索時間を短縮し、全体的なパフォーマンスを向上させることができます。また、Amazon LexボットにAmazon Kendra検索ソリューションを利用したケースについては、このブログ記事も参考にしてください。
- リトリーバの最適化 – リトリーバの埋め込みモデルの異なるサイズを試してみてください。埋め込みモデルの選択は、LLMの入力要件に大きな影響を与える可能性があります。モデルサイズと検索パフォーマンスの最適なバランスを見つけることで、効率が向上し応答時間が短縮されます。
- プロンプトエンジニアリング – 異なるプロンプトの形式、長さ、スタイルを試して、ボットの回答のパフォーマンスと品質を最適化してください。
- LLMモデルの選択 – 特定のユースケースに最適なLLMモデルを選択してください。モデルサイズ、言語の対応能力、アプリケーション要件との互換性などの要素を考慮してください。適切なLLMモデルを選択することで、最適なパフォーマンスとシステムリソースの効率的な利用が実現されます。
コンタクトセンターの会話は、セルフサービスからライブな人間同士の対話までさまざまです。Amazon Connectを介した人間同士の対話を含むユースケースでは、Wisdomを使用してFAQ、ウィキ、記事、および異なる顧客の問題の対応手順など、複数のリポジトリ内のコンテンツを検索して見つけることができます。
クリーンアップ
将来の費用を発生させないために、このエクササイズの一部として展開されたすべてのリソースを削除してください。SageMakerエンドポイントを正常にシャットダウンするためのスクリプトを提供しています。使用方法の詳細はREADMEを参照してください。また、スタック内のすべてのリソースを削除するには、他のcdkコマンドと同じディレクトリでcdk destroyを実行してください。
サマリー
この記事では、RAG戦略とLlamaIndexを使用してAmazon LexをLLMベースのQA機能で強化するための以下のステップについて説明しました:
- LlamaIndexライブラリを含む必要な依存関係をインストールする
- Amazon SageMakerまたはAmazon Bedrock(限定プレビュー)を介してモデルホスティングを設定する
- LlamaIndexを構成し、関連ドキュメントでインデックスを作成して埋め込む
- Amazon LexにRAGを統合し、ドキュメントの検索にLlamaIndexを使用するように構成する
- チャットボットとの会話を行い、正確な回答の検索と生成を観察して統合をテストする
これらの手順に従うことで、強力なLLMベースのQA機能と効率的なドキュメントインデックスをAmazon Lexチャットボットにシームレスに組み込むことができます。これにより、ユーザーとのより正確で包括的で文脈に即した対話が実現します。さらに、Amazon Lex FAQの体験をURLの組み込みとLLMを使って向上させる方法については、次のブログ記事もご覧いただけます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






