機械学習でパワーアップした顧客サービス
'Enhanced customer service powered by machine learning.'
![]()
このブログ投稿では、実際の顧客サービスのユースケースをシミュレートし、Hugging Faceエコシステムの機械学習ツールを使用してそれに対処します。
強くお勧めするのは、このノートブックをテンプレート/例として使用して、あなた自身の実世界のユースケースを解決することです。
タスク、データセット、モデルの定義
実際のコーディングに取り掛かる前に、自動化または一部自動化したいユースケースの明確な定義を持つことが重要です。ユースケースの明確な定義は、最適なタスク、使用するデータセット、および適用するモデルを特定するのに役立ちます。
NLPタスクの定義
では、自然言語処理モデルを使用して解決したい仮想的な問題について考えてみましょう。私たちは製品を販売しており、顧客サポートチームはフィードバック、クレーム、質問を含む数千のメッセージを受け取っています。理想的には、これらのメッセージにすべて返答する必要があります。
すぐに明らかになるのは、顧客サポートがすべてのメッセージに返信することは不可能であるということです。したがって、私たちは最も不満な顧客にのみ返信し、これらのメッセージに100%回答することを決定します。それらは中立的なメッセージや肯定的なメッセージと比べて最も緊急性があると考えられるためです。
非常に不満な顧客のメッセージが全メッセージの一部であると仮定し、不満なメッセージを自動的にフィルタリングできるとすると、顧客サポートはこの目標を達成できるはずです。
不満なメッセージを自動的にフィルタリングするために、自然言語処理技術を適用する予定です。
最初のステップは、私たちのユースケース(不満なメッセージのフィルタリング)を機械学習タスクにマッピングすることです。
Hugging Face Hubのタスクページは、与えられたシナリオに最も適したタスクを確認するための素晴らしい場所です。各タスクには詳細な説明と潜在的な使用例があります。
最も不満な顧客のメッセージを見つけるタスクは、テキスト分類のタスクとしてモデル化できます。メッセージを次の5つのカテゴリのいずれかに分類します:非常に不満、不満、中立、満足、または非常に満足。
適切なデータセットの見つけ方
タスクを決定したら、次にモデルをトレーニングするためのデータを見つける必要があります。これはユースケースのパフォーマンスにとって通常はモデルアーキテクチャを選ぶよりも重要です。モデルはトレーニングされたデータの質によってのみ優れた性能を発揮します。したがって、データセットの選択と作成には非常に注意が必要です。
不満なメッセージのフィルタリングという仮想的なユースケースを考えると、使用可能なデータセットを見てみましょう。
実際のユースケースでは、おそらくNLPシステムが処理する実際のデータを最もよく表す内部データがあるでしょう。したがって、そのような内部データをNLPシステムのトレーニングに使用するべきです。ただし、モデルの汎用性を向上させるために公開されているデータも含めることは役立ちます。
Hugging Face Hubの利用可能なデータセットをすべて見てみましょう。左側にはタスクカテゴリやより具体的なタスクに基づいてデータセットをフィルタリングできます。私たちのユースケースはテキスト分類 -> 感情分析に対応しているので、これらのフィルタを選択しましょう。このノートブックの執筆時点では、約80のデータセットが残ります。データセットを選ぶ際には、次の2つの側面を評価する必要があります:
- 品質:データセットの品質は高いですか?具体的には:データはユースケースで扱うデータに対応していますか?データは多様で偏りがありませんか?
- サイズ:データセットの大きさはどれくらいですか?通常、データセットが大きいほど良いと言えます。
データセットが効率的に高品質であるかどうかを評価するのはかなり難しいですし、データセットがどのように偏っているかを知るのはさらに難しいです。高品質のための効率的で合理的なヒューリスティックは、ダウンロードの統計を見ることです。ダウンロードが多いほど、使用されている可能性が高く、データセットの品質が高いです。サイズは簡単に評価できます。最もダウンロードされたデータセットを見てみましょう:
- Glue
- Amazon polarity
- Tweet eval
- Yelp review full
- Amazon reviews multi
これで、データセットの詳細をより詳しく調べることができます。データセットカードを読みながら、関連する重要な情報を提供するはずです。さらに、データセットビューアは、データが使用目的に適しているかどうかを調べるための非常に強力なツールです。
では、上記のモデルのデータセットカードをさっと見てみましょう:
- GLUEは、研究者が新しいモデルアーキテクチャを比較するための小規模なデータセットのコレクションです。これらのデータセットは小さすぎて、私たちの使用目的には十分に対応していません。
- Amazonの極性は、顧客のフィードバックに適した非常に大きなデータセットです。ただし、このデータには2値のラベル(肯定的/否定的)しかありません。私たちは感情分類により詳細な粒度を求めています。
- Tweet evalは、満足度から不満足度までのスケールに簡単にマッピングできないさまざまな絵文字を使用したラベルを使用しています。
- Amazonのレビュー(マルチ)は、ここで最も適したデータセットのようです。Amazonの星の数に対応する1-5の感情ラベルがあります。これらのラベルは、非常に不満足、中立、満足、非常に満足にマッピングできます。データセットビューアでいくつかの例を調べて、レビューが実際の顧客フィードバックレビューに非常に似ていることを確認しました。したがって、これは非常に良いデータセットのようです。さらに、各レビューには
product_categoryラベルがありますので、私たちが取り組んでいる製品カテゴリに対応する製品のレビューのみを使用することさえできます。このデータセットは多言語対応ですが、今のところ英語版に興味があります。 - Yelpのフルレビューは非常に適したデータセットのようです。それは大規模であり、製品のレビューと1から5の感情ラベルを含んでいます。残念ながら、データセットビューアはここでは機能しておらず、データセットカードも比較的簡素であり、データセットを調べるためにはさらに時間がかかります。この時点で、私たちは論文を読むべきですが、このブログ投稿の制約時間を考慮して、Amazonのレビュー(マルチ)を選ぶことにします。結論として、すべてのトレーニング例を考慮に入れてAmazonのレビュー(マルチ)データセットに焦点を当てましょう。
最後に、プライベートデータセットを使用する場合でも、Hubのデータセット機能を活用することをおすすめします。Hugging Face Hub、Transformers、およびDatasetsは完全に統合されており、モデルのトレーニング時にそれらを組み合わせて使用することは非常に簡単です。
さらに、Hugging Face Hubでは以下の機能も提供されています:
- すべてのデータセットに対するデータセットビューア
- ウィジェットを使用したすべてのモデルの簡単なデモ
- プライベートおよびパブリックモデル
- リポジトリのGitバージョン管理
- 最高のセキュリティメカニズム
適切なモデルの見つけ方
タスクと使用目的に最も適したデータセットを選びましたので、次は使用するモデルを選ぶことを考えてみましょう。
おそらく、ご自身の使用目的に合わせて事前学習済みモデルを微調整する必要があると思われますが、既に適切に微調整されたモデルがHubにあるかどうかを確認する価値はあります。その場合、そのモデルをデータセットでさらに微調整するだけで、より高いパフォーマンスを得ることができるかもしれません。
Amazon Reviews Multiで微調整されたすべてのモデルを見てみましょう。モデルの一覧は右下隅にあります – このデータセットで微調整されたすべてのモデルの一覧を表示するために、Browse models trained on this datasetをクリックします。ただし、私たちは英語版のデータセットにのみ興味があります。私たちの顧客フィードバックは英語のみです。最もダウンロードされているモデルのほとんどは、データセットの多言語版でトレーニングされており、多言語対応ではないものは情報が非常に少ないか、パフォーマンスが低いようです。この時点では、上記のリンクに表示される既に微調整されたモデルの代わりに、純粋な事前学習済みモデルを微調整する方がより合理的かもしれません。
さて、次のステップは、微調整に使用する適切な事前学習済みモデルを見つけることです。Hugging Face Hubには、事前学習済みおよび微調整済みのモデルが多数存在するため、実際にはそれほど簡単ではありません。最良のオプションは、さまざまなモデルを試して、最も優れたパフォーマンスを発揮するモデルを見つけることです。Hugging Faceで異なるモデルのチェックポイントを比較するための完璧な方法はまだ見つかっていませんが、以下のいくつかのリソースを提供しています:
- モデルの概要には、さまざまなモデルアーキテクチャの短い概要が記載されています。
- Hugging Face Hubでタスク固有の検索、例えばテキスト分類モデルの検索は、最もダウンロードされているチェックポイントを表示します。これは、それらのチェックポイントがどれだけ優れているかの指標でもあります。
ただし、上記の両方のリソースは現在最適ではありません。モデルの概要は常に作者によって最新の状態に保たれているわけではありません。新しいモデルアーキテクチャがリリースされ、古いモデルアーキテクチャが時代遅れになる速度は非常に速く、すべてのモデルアーキテクチャの最新の概要を持つことは非常に困難です。同様に、最もダウンロードされたモデルチェックポイントが最も優れたものであるとは限りません。たとえば、bert-base-casedは最もダウンロードされたモデルチェックポイントのうちの1つですが、もはや最も優れたチェックポイントではありません。
最良の方法は、さまざまなモデルアーキテクチャを試し、その分野の専門家をフォローして新しいモデルアーキテクチャについて最新情報を得、よく知られたリーダーボードをチェックすることです。
テキスト分類の場合、注目すべき重要なベンチマークはGLUEとSuperGLUEです。両方のベンチマークは、文法の正確さ、自然言語推論、Yes/Noの質問応答など、さまざまなテキスト分類タスクで事前学習済みモデルを評価します。これらのタスクは、感情分析の対象タスクと非常に似ています。したがって、これらのベンチマークのトップモデルの1つを選択することは合理的です。
このブログ記事の執筆時点では、最高のパフォーマンスを発揮するモデルは、10億以上のパラメータを含む非常に大規模なモデルであり、そのほとんどはオープンソースではありません。例えば、ST-MoE-32B、Turing NLR v5、またはERNIE 3.0などです。アクセスしやすいトップランキングのモデルの1つはDeBERTaです。したがって、DeBERTaの最新のベースバージョン、つまりmicrosoft/deberta-v3-baseを試してみましょう。
🤗 Transformersと🤗 Datasetsでモデルのトレーニング/ファインチューニング
このセクションでは、非常に不満な顧客のフィードバックメッセージを自動的にフィルタリングするために、モデルをエンドツーエンドでファインチューニングするための技術的な詳細について説明します。
素晴らしいですね!まずは必要なpipパッケージをインストールしてコード環境をセットアップし、次にデータセットの前処理を調べ、最後にモデルのトレーニングを開始しましょう。
以下のノートブックは、GPUランタイム環境が有効になっているGoogle Colab Proでオンラインで実行できます。
必要なパッケージをインストールする
まず、トレーニング中にトレーニング済みのチェックポイントをHubに自動アップロードできるように、git-lfsをインストールしましょう。
apt install git-lfsさらに、このノートブックを実行するために🤗 Transformersと🤗 Datasetsライブラリをインストールします。このブログ記事ではDeBERTaを使用するため、そのトークナイザのためにsentencepieceライブラリもインストールする必要があります。
pip install datasets transformers[sentencepiece]次に、Hugging Faceアカウントにログインしてモデルが正しくあなたの名前のタグの下にアップロードされるようにしましょう。
from huggingface_hub import notebook_login
notebook_login()出力:
ログイン成功
あなたのトークンが /root/.huggingface/token に保存されました
git-credentialストアを介して認証済みですが、これはマシン上で定義されたヘルパーではありません。
Hugging Face Hubにプッシュするときに再認証が必要な場合は、ターミナルで次のコマンドを実行して、この認証ヘルパーをデフォルトに設定することができます。
git config --global credential.helper storeデータセットの前処理
モデルのトレーニングを開始する前に、データセットをモデルが理解できる形式に変換する必要があります。
幸い、🤗 Datasetsライブラリを使用すると、次のセルで見るように、これが非常に簡単に行えます。
load_dataset関数はデータセットをロードし、review_bodyやstarsなどの事前定義された属性にきれいに整理し、最終的に新しく整理されたデータをアローフォーマットでディスクに保存します。アローフォーマットは、高速かつメモリ効率の良いデータの読み書きを可能にします。
まず、amazon_reviews_multiデータセットの英語版をロードして準備しましょう。
from datasets import load_dataset
amazon_review = load_dataset("amazon_reviews_multi", "en")出力:
データセット amazon_reviews_multi/en をダウンロードして準備中 (ダウンロードサイズ: 82.11 MiB、生成サイズ: 58.69 MiB、後処理サイズ: 不明、合計サイズ: 140.79 MiB) /root/.cache/huggingface/datasets/amazon_reviews_multi/en/1.0.0/724e94f4b0c6c405ce7e476a6c5ef4f87db30799ad49f765094cf9770e0f7609...
データセット amazon_reviews_multi が /root/.cache/huggingface/datasets/amazon_reviews_multi/en/1.0.0/724e94f4b0c6c405ce7e476a6c5ef4f87db30799ad49f765094cf9770e0f7609 にダウンロードされ、準備されました。以降の呼び出しでは、このデータが再利用されます。素晴らしい、それは速かったです🔥。データセットの構造を見てみましょう。
print(amazon_review)出力:
{.output .execute_result execution_count="5"}
DatasetDict({
train: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 200000
})
validation: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
test: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
})トレーニング例は20万、バリデーションとテスト例はそれぞれ5000あります。トレーニングにはこれが適切です!入力は"review_body"列であり、ターゲットは"stars"列になります。
ランダムな例を見てみましょう。
random_id = 34
print("Stars:", amazon_review["train"][random_id]["stars"])
print("Review:", amazon_review["train"][random_id]["review_body"])出力:
Stars: 1
Review: この商品は私の肌に激しい炎症を引き起こしました。他のブランドを使用しても問題はありませんでしたデータセットは人間が読める形式ですが、これを「機械が読める」形式に変換する必要があります。選択したチェックポイントを前処理および微調整するために必要なすべてのユーティリティを含むモデルリポジトリを定義しましょう。
model_repository = "microsoft/deberta-v3-base"次に、モデルリポジトリのトークナイザ(DeBERTaのトークナイザ)をロードします。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_repository)前述のように、モデルの入力には"review_body"、モデルのターゲットには"stars"を使用します。次に、トークナイザを使用して入力をモデルが理解できるトークンIDのシーケンスに変換します。トークナイザはこれを正確に行い、入力データを特定の長さに制限してメモリの問題が発生しないようにするのにも役立ちます。ここでは、最大トークン数を128に制限しています。DeBERTaの場合、これはおおよそ100単語に相当し、また約5-7文に相当します。データセットビューアを再度確認すると、これがほぼすべてのトレーニング例をカバーしていることがわかります。 重要:これは、モデルがより長い入力シーケンスを処理できないことを意味するものではありません。トランスフォーマーモデルは、トレーニング後により長いシーケンスに対して一般化する能力が非常に高いことが示されています。
トークン化について詳しく学びたい場合は、Tokenizersのドキュメントを参照してください。
ラベルは既に生の形で数値に対応しているため、簡単に変換することができます。つまり、範囲は1から5です。ここでは、インデックスが通常0から始まるため、ラベルを0から4の範囲にシフトするだけです。
素晴らしいですね、思考をコードに注ぎ込みましょう。各データサンプルに適用するpreprocess_functionを定義します。
def preprocess_function(example):
output_dict = tokenizer(example["review_body"], max_length=128, truncation=True)
output_dict["labels"] = [e - 1 for e in example["stars"]]
return output_dictこの関数をデータセット内のすべてのデータサンプルに適用するために、先に作成したamazon_reviewオブジェクトのmapメソッドを使用します。これにより、amazon_reviewのすべての分割のすべての要素に関数が適用され、トレーニング、バリデーション、テストデータが一度に前処理されます。プロセスを高速化するために、batched=Trueモードでマッピング関数を実行し、トレーニングには不要な列をすべて削除します。
tokenized_datasets = amazon_review.map(preprocess_function, batched=True, remove_columns=amazon_review["train"].column_names)新しい構造を見てみましょう。
tokenized_datasets出力:
DatasetDict({
train: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 200000
})
validation: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 5000
})
test: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 5000
})
})外側の構造は変わらず、列の名前が変わりました。前に見たランダムな例を前処理したものを見てみましょう。
print("Input IDS:", tokenized_datasets["train"][random_id]["input_ids"])
print("Labels:", tokenized_datasets["train"][random_id]["labels"])出力:
Input IDS: [1, 329, 714, 2044, 3567, 5127, 265, 312, 1158, 260, 273, 286, 427, 340, 3006, 275, 363, 947, 2]
Labels: 0入力テキストは整数のシーケンスに変換され、モデルによって単語の埋め込みに変換できます。また、ラベルインデックスは単純に-1だけシフトされます。
モデルの微調整
データセットを前処理した後は、次にモデルを微調整することができます。人気のあるHugging Face Trainerを使用して、わずか数行のコードでトレーニングを開始できます。 TrainerはPyTorchのほとんどすべてのタスクに使用でき、トレーニングに必要なボイラープレートコードの多くを簡単に処理してくれるため、非常に便利です。
便利な AutoModelForSequenceClassification を使用してモデルチェックポイントをロードすることから始めましょう。モデルリポジトリのチェックポイントは事前学習済みのチェックポイントであるため、num_labels=5 を渡して分類ヘッドのサイズを定義する必要があります(5つの感情クラスがあるため)。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(model_repository, num_labels=5)
モデルリポジトリ microsoft/deberta-v3-base のチェックポイントの一部は、DebertaV2ForSequenceClassification を初期化する際に使用されませんでした: ['mask_predictions.classifier.bias', 'mask_predictions.LayerNorm.bias', 'mask_predictions.dense.weight', 'mask_predictions.dense.bias', 'mask_predictions.LayerNorm.weight', 'lm_predictions.lm_head.dense.bias', 'lm_predictions.lm_head.bias', 'lm_predictions.lm_head.LayerNorm.weight', 'lm_predictions.lm_head.dense.weight', 'lm_predictions.lm_head.LayerNorm.bias', 'mask_predictions.classifier.weight']
- これは、別のタスクで訓練されたモデルまたは別のアーキテクチャで訓練されたモデル(例えば、BertForPreTrainingモデルからBertForSequenceClassificationモデルを初期化する)からDebertaV2ForSequenceClassificationを初期化している場合には予想される動作です。
- BertForSequenceClassificationモデルからBertForSequenceClassificationモデルを初期化する場合には、これは予想されない動作です。
DebertaV2ForSequenceClassification の一部の重みは、microsoft/deberta-v3-base のモデルチェックポイントから初期化されず、新たに初期化されました: ['pooler.dense.bias', 'classifier.weight', 'classifier.bias', 'pooler.dense.weight']
このモデルを予測や推論に使用する場合は、ダウンストリームタスクでこのモデルをトレーニングする必要があります。次に、データコレータをロードします。データコレータは、トレーニング中に各バッチが正しくパディングされるようにする責任があります。これは、トレーニングサンプルが各エポックの前に再シャッフルされるため、動的に行う必要があります。
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)トレーニング中には、モデルのパフォーマンスを保持された検証セットで監視することが重要です。そのために、トレーナーに compute_metrics 関数を定義するために渡す必要があります。この関数は、トレーニング中の各検証ステップで呼び出されます。
テキスト分類タスクの最も単純なメトリックは正確度(accuracy)であり、トレーニングサンプルの何パーセントが正しく分類されたかを示します。ただし、正確度メトリックは、検証データまたはテストデータが非常にバランスが取れていない場合に問題が発生する可能性があります。各ラベルの出現回数をカウントして、それが問題ではないことを迅速に確認しましょう。
from collections import Counter
print("検証:", Counter(tokenized_datasets["validation"]["labels"]))
print("テスト:", Counter(tokenized_datasets["test"]["labels"]))出力:
検証: Counter({0: 1000, 1: 1000, 2: 1000, 3: 1000, 4: 1000})
テスト: Counter({0: 1000, 1: 1000, 2: 1000, 3: 1000, 4: 1000})検証データセットとテストデータセットはできるだけバランスが取れているため、ここでは安全に正確度を使用できます!
データセットライブラリを介して正確度メトリックをロードしましょう。
from datasets import load_metric
accuracy = load_metric("accuracy")次に、compute_metricsを定義します。これは、モデルの予測出力(EvalPrediction型)に適用され、モデルの予測と正解ラベルが公開されます。モデルの予測のargmaxを取得してから、正解ラベルと一緒に正確度メトリックに渡すことで、予測されたラベルクラスを計算します。
import numpy as np
def compute_metrics(pred):
pred_logits = pred.predictions
pred_classes = np.argmax(pred_logits, axis=-1)
labels = np.asarray(pred.label_ids)
acc = accuracy.compute(predictions=pred_classes, references=labels)
return {"accuracy": acc["accuracy"]}素晴らしいですね、トレーニングに必要なすべてのコンポーネントが準備されました。残りの作業は、Trainerのハイパーパラメータを定義することです。トレーニング中にモデルのチェックポイントがHugging Face Hubにアップロードされるようにする必要があります。 push_to_hub=Trueを設定することで、便利なpush_to_hubメソッドを使用して、save_stepsごとに自動的に行われます。
また、学習率、ウォームアップステップ、トレーニングエポックなどの標準的なハイパーパラメータも定義します。500ステップごとに損失を記録し、5000ステップごとに評価を実行します。
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="deberta_amazon_reviews_v1",
num_train_epochs=2,
learning_rate=2e-5,
warmup_steps=200,
logging_steps=500,
save_steps=5000,
eval_steps=5000,
push_to_hub=True,
evaluation_strategy="steps",
)すべてをまとめれば、必要なすべてのコンポーネントを渡して、Trainerを最終的にインスタンス化することができます。トレーニング中には、"validation"スプリットをヘルドアウトデータセットとして使用します。
from transformers import Trainer
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"]
)トレーナーの準備が整いました 🚀 trainer.train()を呼び出すことでトレーニングを開始できます。
train_metrics = trainer.train().metrics
trainer.save_metrics("train", train_metrics)出力:
***** トレーニングを実行 *****
Num examples = 200000
Num Epochs = 2
デバイスごとのバッチサイズ = 8
合計トレーニングバッチサイズ(並列、分散、蓄積を含む)= 8
勾配蓄積ステップ = 1
合計最適化ステップ = 50000出力:
出力:
***** 評価を実行 *****
Num examples = 5000
バッチサイズ = 8
モデルチェックポイントを deberta_amazon_reviews_v1/checkpoint-50000 に保存中
設定を deberta_amazon_reviews_v1/checkpoint-50000/config.json に保存中
モデルウェイトを deberta_amazon_reviews_v1/checkpoint-50000/pytorch_model.bin に保存中
トークナイザー設定ファイルを deberta_amazon_reviews_v1/checkpoint-50000/tokenizer_config.json に保存中
特殊トークンファイルを deberta_amazon_reviews_v1/checkpoint-50000/special_tokens_map.json に保存中
追加トークンファイルを deberta_amazon_reviews_v1/checkpoint-50000/added_tokens.json に保存中
トレーニングが完了しました。huggingface.co/models でモデルを共有するのを忘れないでください =)すごいですね、モデルは何かを学んでいるようです!トレーニングロスとバリデーションロスが減少しており、正解率もランダムチャンス(20%)を大幅に上回っていることがわかります。興味深いことに、5000ステップ後には約58.6%の正解率があり、その後はあまり改善されません。より大きなモデルを選択したり、より長くトレーニングを行ったりすれば、より良い結果が得られた可能性がありますが、仮想的なユースケースには十分です!
さて、最後にモデルのチェックポイントをハブにアップロードしましょう。
trainer.push_to_hub()出力:
モデルチェックポイントを deberta_amazon_reviews_v1 に保存しています
設定が deberta_amazon_reviews_v1/config.json に保存されました
モデルの重みが deberta_amazon_reviews_v1/pytorch_model.bin に保存されました
トークナイザーの設定ファイルが deberta_amazon_reviews_v1/tokenizer_config.json に保存されました
特殊トークンのファイルが deberta_amazon_reviews_v1/special_tokens_map.json に保存されました
追加トークンのファイルが deberta_amazon_reviews_v1/added_tokens.json に保存されました
いくつかのコミット(2個)がアップストリームにプッシュされます
進捗バーは信頼性がないかもしれませんモデルの評価 / 分析
モデルを微調整したので、パフォーマンスを詳細に分析する必要があります。正解率などの一般的な指標は、モデルのパフォーマンスについて一般的なイメージを得るのに役立ちますが、実際のユースケースでモデルのパフォーマンスを評価するには十分ではありません。より良い方法は、実際のユースケースを最もよく表す指標を見つけ、トレーニング中およびトレーニング後にまさにこの指標を測定することです。
さあ、モデルの評価に入りましょう 🤿。
モデルはトレーニング後に deberta_v3_amazon_reviews の名前でハブにアップロードされましたので、最初にそれを再度ダウンロードしましょう。
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("patrickvonplaten/deberta_v3_amazon_reviews")Trainerはモデルのトレーニングだけでなく、データセットでモデルを評価するための優れたクラスです。前と同じインスタンスと関数でトレーナーをインスタンス化しましょうが、今回はトレーニングデータセットを渡す必要はありません。
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
)Trainerのpredict関数を使用して、同じ指標でテストデータセット上のモデルを評価します。
prediction_metrics = trainer.predict(tokenized_datasets["test"]).metrics
prediction_metrics出力:
***** 予測実行中 *****
サンプル数 = 5000
バッチサイズ = 8出力:
{'test_accuracy': 0.608,
'test_loss': 0.9637690186500549,
'test_runtime': 21.9574,
'test_samples_per_second': 227.714,
'test_steps_per_second': 28.464}結果はバリデーションデータセットのパフォーマンスに非常に似ており、これはテストデータセットを過学習していないことを示しています。
ただし、5クラス分類問題では60%の正解率は完璧ではありませんが、すべてのクラスに対して非常に高い正解率が必要なのでしょうか?
非常に否定的な顧客フィードバックに関心があるため、最も不満足な顧客のレビューを分類するモデルのパフォーマンスに焦点を当てることにしましょう。また、私たちが少し手助けをすることも決めました – 非常に不満足または不満足と分類されたフィードバックはすべて私たちが処理することになります – 非常に不満足メッセージのほぼ99%をキャッチできます。同時に、中立的、満足、非常に満足の顧客からのメッセージに回答することで、どれだけ不必要な作業を行っているかも測定します。
素晴らしいですね、新しいcompute_metrics関数を作成しましょう。
import numpy as np
def compute_metrics(pred):
pred_logits = pred.predictions
pred_classes = np.argmax(pred_logits, axis=-1)
labels = np.asarray(pred.label_ids)
# まずは非常に不満足なメッセージをキャッチする割合を計算しましょう
very_unsatisfied_label_idx = (labels == 0)
very_unsatisfied_pred = pred_classes[very_unsatisfied_label_idx]
# 今度は0と1の両方のラベルが0のラベルで、それ以外は0より大きい
very_unsatisfied_pred = very_unsatisfied_pred * (very_unsatisfied_pred - 1)
# 0のラベルがいくつあるか数えましょう - これが "非常に不満足" - 正解率です
true_positives = sum(very_unsatisfied_pred == 0) / len(very_unsatisfied_pred)
# 次に、満足したメッセージに不必要に回答した数を計算しましょう
satisfied_label_idx = (labels > 1)
satisfied_pred = pred_classes[satisfied_label_idx]
# すべての満足したメッセージに対して不満足とラベル付けされた予測はいくつありますか?
false_positives = sum(satisfied_pred <= 1) / len(satisfied_pred)
return {"%_unsatisfied_replied": round(true_positives, 2), "%_satisfied_incorrectly_labels": round(false_positives, 2)}再びTrainerをインスタンス化して評価を簡単に実行します。
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
)そして、新しいメトリック計算を使用して再度評価を実行しましょう。このメトリック計算は、私たちのユースケースにより適しています。
prediction_metrics = trainer.predict(tokenized_datasets["test"]).metrics
prediction_metrics出力:
***** 予測実行 *****
例数 = 5000
バッチサイズ = 8出力:
{'test_%_satisfied_incorrectly_labels': 0.11733333333333333,
'test_%_unsatisfied_replied': 0.949,
'test_loss': 0.9637690186500549,
'test_runtime': 22.8964,
'test_samples_per_second': 218.375,
'test_steps_per_second': 27.297}素晴らしい!これはすでにかなり良い結果を示しています。私たちは非常に不満足な顧客の約95%を自動的に捕捉することができ、満足したメッセージの10%に努力を浪費することになります。
さて、簡単な計算をしましょう。私たちは毎日約10,000件のメッセージを受け取り、そのうち約500件が非常にネガティブであると予想しています。この自動フィルタリングを使用すると、10,000件のすべてのメッセージに返信する代わりに、500 + 0.12 * 10,000 = 1700件のメッセージを確認し、そのうちの475件にのみ返信する必要があります。また、メッセージの5%を誤って見落とすことになります。非常に不満足な顧客の努力削減率は83%ですが、見落とし率はわずか5%です!
もちろん、数値は実際のユースケースの獲得価値を表していませんが、十分な高品質のトレーニングデータがあれば、現実世界の例にかなり近づけることができます!
結果を保存しましょう
trainer.save_metrics("prediction", prediction_metrics)そして、すべてをハブにアップロードします。
trainer.push_to_hub()出力:
モデルのチェックポイントを deberta_amazon_reviews_v1 に保存中
設定を deberta_amazon_reviews_v1/config.json に保存しました
モデルの重みを deberta_amazon_reviews_v1/pytorch_model.bin に保存しました
トークナイザの設定を deberta_amazon_reviews_v1/tokenizer_config.json に保存しました
特殊トークンファイルを deberta_amazon_reviews_v1/special_tokens_map.json に保存しました
追加されたトークンファイルを deberta_amazon_reviews_v1/added_tokens.json に保存しました
https://huggingface.co/patrickvonplaten/deberta_amazon_reviews_v1 にプッシュ中
599b891..ad77e6d main -> main
次の結果は必要なすべてのフィールドを持っていないため、削除されます:
{'task': {'name': 'テキスト分類', 'type': 'text-classification'}}
https://huggingface.co/patrickvonplaten/deberta_amazon_reviews_v1 にプッシュ中
ad77e6d..13e5ddd main -> mainデータはここに保存されました。
今日はこれで終わりです 😎。最終的なステップとして、実際の実世界データでモデルを試すことも非常に意味があります。これは、モデルカードの推論ウィジェットで直接行うことができます:
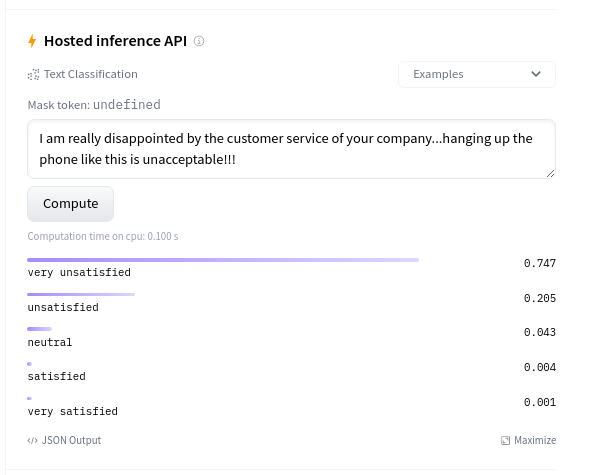
実際の実世界データにもかなりうまく汎化されているようです🔥
最適化
モデルのパフォーマンスが本番用に十分に良いと思われると、モデルをメモリ効率化と高速化することが重要です。
最適な加速ハードウェア(例:より良いGPU)の選択、順方向パス中の勾配計算の避け、浮動小数点数の精度(例:float16)の低下など、明らかな解決策がいくつかあります。
より高度な最適化手法には、ONNX Runtimeや量子化などのオープンソースのアクセラレータライブラリ、Tritonなどの推論サーバーの使用が含まれます。
Hugging Faceでは、特にオープンソースのOptimumライブラリを使用して、モデルの最適化を容易にするために多くの作業を行ってきました。Optimumを使用すると、ほとんどの🤗 Transformersモデルを最適化するのが非常に簡単になります。
もしも技術的な知識を必要としない高度に最適化されたソリューションをお探しの場合、Inference APIはおすすめです。このプラグ&プレイソリューションは、感情分析を含むさまざまな機械学習タスクを本番環境で提供することができます。
さらに、カスタムのユースケースに対するサポートを探している場合は、Hugging Faceの専門家チームがMLプロジェクトを加速させるお手伝いができます!私たちのチームは、研究から本番までの機械学習の旅の中で必要な質問に答え、解決策を見つけるお手伝いをします。詳細や見積もりのリクエストについては、hf.co/supportをご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






