感情の解読:EmoTXによる感情と心の状態の明らかにする、新しいTransformer-Powered AIフレームワーク
EmoTX A new Transformer-Powered AI framework for revealing emotions and mental states


映画は物語や感情の中でも最も芸術的な表現の一つです。たとえば、「ハッピネスの追求」では、主人公が別れやホームレスなどの低い状況から、一流の仕事を達成するなどの高い状況まで、様々な感情を経験します。これらの強烈な感情は、観客を引き込み、キャラクターの旅に共感することができます。人工知能(AI)の領域でこのような物語を理解するためには、キャラクターの感情や心理状態の変化を監視することが重要です。この目標は、MovieGraphsからの注釈を活用し、シーンを観察し、対話を分析し、キャラクターの感情や心理状態に関する予測を行うことで追求されます。
感情の対象は歴史を通じて幅広く探求されてきました。古代ローマのキケロの四分類から現代の脳研究まで、感情の概念は常に人類の関心を引きつけてきました。心理学者たちは、プルチキの車輪やエクマンの普遍的な顔の表情などの構造を導入することで、さまざまな理論的な枠組みを提供しました。感情は、感情、行動、認知の側面と身体的な状態を包括する心理状態にさらに分類されます。
最近の研究では、Emoticとして知られるプロジェクトが視覚コンテンツの処理時に26の異なる感情ラベルクラスターを導入しました。このプロジェクトは、画像が平和や関与など、同時にさまざまな感情を伝える可能性があることを許容するマルチラベルのフレームワークを提案しました。従来のカテゴリーのアプローチに代わり、この研究では連続的な3つの次元(快感、興奮、支配)も組み込まれています。
- 『AI入門』
- 「カーシブと出会う:LLMとのインタラクションのためのユニバーサルで直感的なAIフレームワーク」
- デシは、コード生成のためのオープンソース1Bパラメータの大規模言語モデル「DeciCoder」を紹介します
正確な感情の予測には、さまざまなコンテキストモダリティを網羅する必要があります。マルチモーダルな感情認識の主要なアプローチには、対話の中での感情認識(ERC)が含まれます。これにより、対話の交換ごとに感情を分類することができます。また、映画クリップの短いセグメントに対して単一の快感-活動スコアを予測するアプローチもあります。
映画のシーンレベルでの操作は、特定の場所で発生し、特定のキャストを含む、30から60秒の短い時間枠内で物語を伝える一連のショットと一緒に作業することを意味します。これらのシーンは個々の対話や映画クリップよりも長い時間を提供します。この目標は、シーン内のすべてのキャラクターの感情と心理状態、およびシーンレベルでのラベルの蓄積を予測することです。時間の長いウィンドウが与えられるため、この推定は自然にマルチラベル分類アプローチにつながります。キャラクターは同時に複数の感情(好奇心と混乱など)を伝える場合がありますし、他者との相互作用による遷移(たとえば、心配から穏やかに変化する)も起こる可能性があるためです。
さらに、感情は心理状態の一部として広く分類されることができますが、この研究では、キャラクターの態度(驚き、悲しみ、怒りなど)から明確に認識できる外部の感情と、相互作用や対話を通じてのみ識別可能な潜在的な心理状態(礼儀、決意、自信、助け)とを区別しています。著者たちは、広範な感情ラベル空間で効果的に分類するためには、マルチモーダルなコンテキストを考慮する必要があると主張しています。そのため、彼らはビデオフレーム、対話の発話、キャラクターの外観を同時に組み込むモデルであるEmoTxを提案しています。
このアプローチの概要は、以下の図に示されています。

EmoTxは、キャラクターごとおよび映画シーンごとに感情を特定するためにTransformerベースのアプローチを使用しています。プロセスは、初期のビデオの前処理と特徴抽出パイプラインから始まり、データから関連する表現を抽出します。これらの特徴には、ビデオデータ、キャラクターの顔、テキストの特徴が含まれます。この文脈では、モダリティ、キャラクターの列挙、および時間的なコンテキストに基づいて区別するための適切な埋め込みがトークンに導入されます。さらに、個々の感情の分類器として機能するトークンが生成され、シーンまたは特定のキャラクターにリンクされます。これらの埋め込まれたトークンは、線形層を使用して組み合わされ、Transformerエンコーダに供給されます。これにより、さまざまなモダリティ間での情報の統合が可能になります。この方法の分類コンポーネントは、以前のTransformerを用いたマルチラベル分類に関する研究から着想を得ています。
「EmoTx」の振る舞いの例は、著者によって公開され、「フォレスト・ガンプ」のシーンに関連しています。以下の図に報告されています。
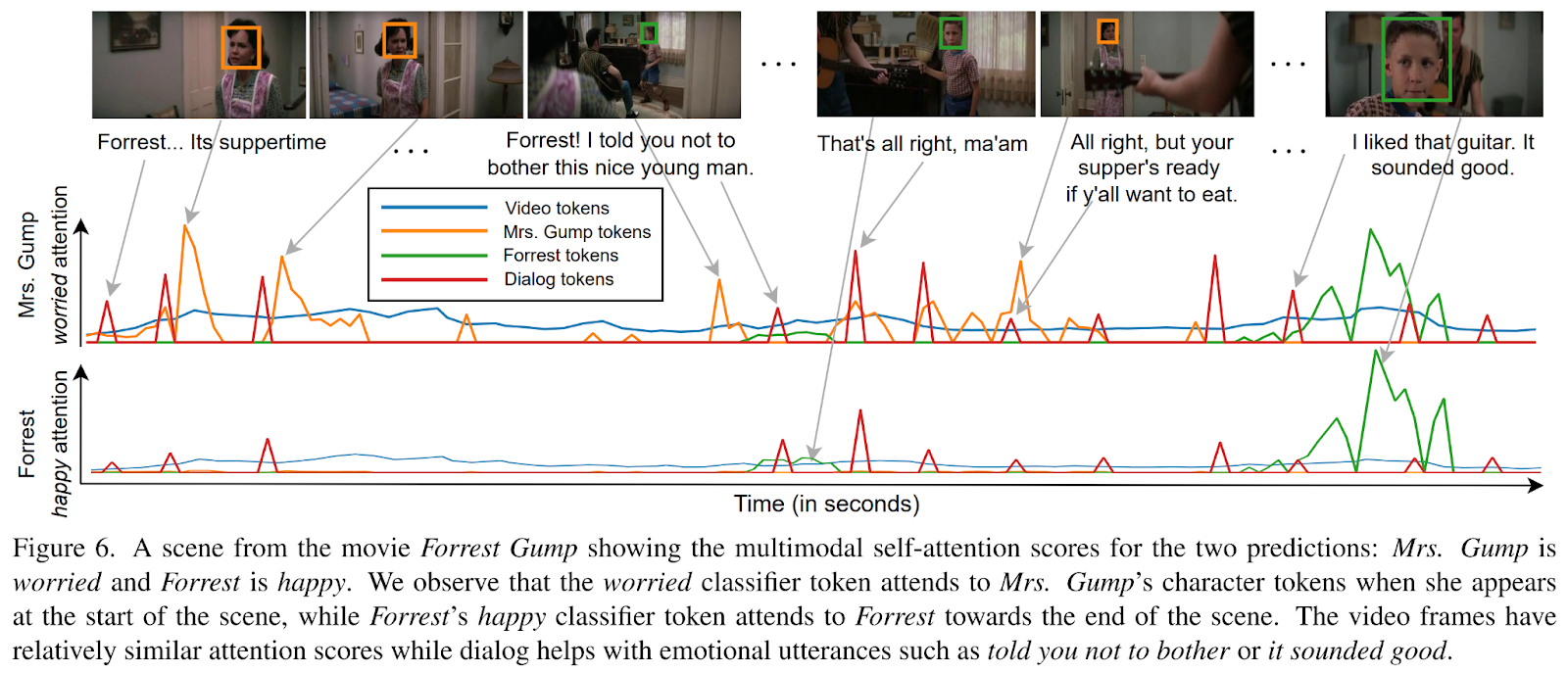
これは、適切なマルチモーダルデータからビデオクリップに登場する被験者の感情を予測する、新しいAIベースのアーキテクチャ「EmoTx」の概要でした。興味がある場合は、以下に引用されたリンクを参照して詳細をご覧ください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles





