「Neo4jにおける非構造化テキストに対する効率的な意味検索」
Efficient Semantic Search for Unstructured Text in Neo4j
新しく追加されたベクトルインデックスをLangChainに統合して、RAGアプリケーションを強化する
ChatGPTが6ヶ月前に登場して以来、技術の風景は変革的な変化を遂げています。ChatGPTの優れた一般化能力により、専門の深層学習チームや広範なトレーニングデータセットが必要なカスタムNLPモデルの作成要件が低下しました。これにより、要約や情報抽出などのさまざまなNLPタスクへのアクセスが民主化され、これまで以上に利用しやすくなりました。しかし、ChatGPTのようなモデルの制約もすぐに明らかになりました。知識の日付の切れやプライベート情報へのアクセスの不可などが挙げられます。私の意見では、その後、関連情報をクエリ時にモデルに供給してより良い正確な回答を構築するために、Retrieval Augmented Generation(RAG)アプリケーションの台頭とともに、生成型AIの第二の波が起こりました。
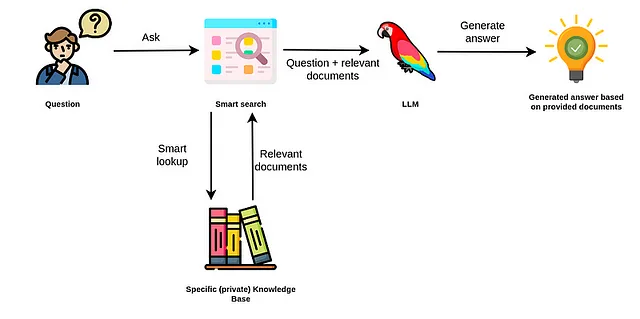
先述のように、RAGアプリケーションでは、ユーザーの入力に基づいて追加情報を取得できるスマートな検索ツールが必要です。これにより、LLM(言語モデル)はより正確で最新の回答を生成できるようになります。最初は、セマンティックサーチを使用して非構造化テキストから情報を取得することが主な焦点でした。しかし、「PDFとチャットする」アプリケーションを超えるには、構造化データと非構造化データの組み合わせが最適なアプローチであることがすぐに明らかになりました。
Neo4jは構造化情報の処理に優れていますが、セマンティックサーチでは少し苦労しました。しかし、Neo4jはバージョン5.11で新たに導入されたベクトルインデックスにより、非構造化テキストや他の埋め込みデータモダリティに対して効率的なセマンティックサーチを行うことができるようになりました。新たに追加されたベクトルインデックスにより、Neo4jは構造化データと非構造化データの両方との組み合わせで、ほとんどのRAGアプリケーションに適しています。
このブログ記事では、Neo4jにベクトルインデックスを設定し、LangChainエコシステムに統合する方法を紹介します。コードはGitHubで利用できます。
Neo4j環境の設定
このブログ記事の例に従うためには、Neo4j 5.11以上をセットアップする必要があります。最も簡単な方法は、Neo4j Auraで無料のインスタンスを開始することです。Neo4j Auraは、Neo4jデータベースのクラウドインスタンスを提供しています。また、Neo4jデスクトップアプリケーションをダウンロードし、ローカルデータベースインスタンスを作成することでも、Neo4jデータベースのローカルインスタンスをセットアップすることができます。
Neo4jデータベースをインスタンス化した後、LangChainライブラリを使用してそれに接続することができます。
from langchain.graphs import Neo4jGraphNEO4J_URI="neo4j+s://1234.databases.neo4j.io"NEO4J_USERNAME="neo4j"NEO4J_PASSWORD="-"graph = Neo4jGraph( url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD)ベクトルインデックスの設定
Neo4jのベクトルインデックスはLuceneによって実現されており、Luceneはベクトル空間上で近似最近傍(ANN)クエリを実行するために階層的ナビゲータブル小世界(HNSW)グラフを実装しています。
ベクトルインデックスのNeo4jの実装は、ノードラベルの単一のノードプロパティを索引化するように設計されています。たとえば、ノードのラベルがChunkで、ノードプロパティがembeddingの場合、次のCypher手順を使用します。
CALL db.index.vector.createNodeIndex( 'wikipedia', // インデックス名 'Chunk', // ノードのラベル 'embedding', // ノードのプロパティ 1536, // ベクトルサイズ 'cosine' // 類似度メトリクス)インデックス名、ノードのラベル、プロパティに加えて、ベクトルのサイズ(埋め込み次元)と類似度メトリクスを指定する必要があります。この例では、OpenAIのtext-embedding-ada-002埋め込みモデルを使用し、ベクトルサイズは1536です。現時点では、cosineとEuclideanの類似度メトリクスのみが利用可能です。OpenAIは、自身の埋め込みモデルを使用する場合は、cosine類似度メトリクスを使用することを推奨しています。
ベクトルインデックスの作成
Neo4jはスキーマレスな設計です。つまり、ノードのプロパティに入れるものに制限を課しません。例えば、Chunkノードのembeddingプロパティには整数、整数のリスト、または文字列が格納される可能性があります。では、実際に試してみましょう。
WITH [1, [1,2,3], ["2","5"], [x in range(0, 1535) | toFloat(x)]] AS exampleValuesUNWIND range(0, size(exampleValues) - 1) as indexCREATE (:Chunk {embedding: exampleValues[index], index: index})このクエリは、リストの各要素ごとにChunkノードを作成し、その要素をembeddingプロパティの値として使用します。例えば、最初のChunkノードはembeddingプロパティの値が1、2番目のノードは[1,2,3]、といった具合です。Neo4jはノードのプロパティに格納する値については特に制限を課しません。ただし、ベクトルインデックスには値のタイプと埋め込み次元に関する明確な指示があります。
ベクトルインデックスがインデックス化した値を確認するために、ベクトルインデックス検索を実行してみましょう。
CALL db.index.vector.queryNodes( 'wikipedia', // インデックス名 3, // 返されるトップKの近傍ノード数 [x in range(0,1535) | toFloat(x) / 2] // 入力ベクトル)YIELD node, scoreRETURN node.index AS index, scoreこのクエリを実行すると、トップ3の近傍ノードが返されるようにリクエストしていたにもかかわらず、返されるノードは1つだけです。なぜでしょうか?ベクトルインデックスは、値が指定されたサイズの浮動小数点数のリストである場合にのみプロパティの値をインデックス化します。この例では、1つだけembeddingプロパティの値が、選択された長さである1536のリストの浮動小数点数タイプを持っていました。
ノードがベクトルインデックスによってインデックス化される条件は次のとおりです:
- ノードには設定されたラベルが含まれていること。
- ノードには設定されたプロパティキーが含まれていること。
- 対応するプロパティ値のタイプが
LIST<FLOAT>であること。 - 対応する値の
size()が設定された次元数と同じであること。 - 値が設定された類似性関数に対して有効なベクトルであること。
ベクトルインデックスをLangChainエコシステムに統合する
次に、Neo4jのベクトルインデックスを使用して正確かつ最新の情報を生成するための関連情報を取得するために、簡単なカスタムLangChainクラスを実装します。ただし、まずはベクトルインデックスを作成する必要があります。
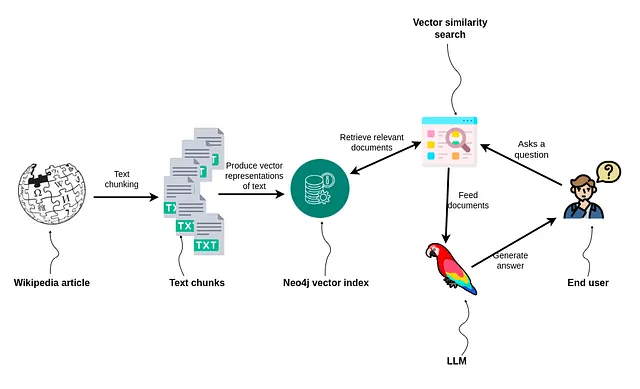
このタスクは以下の手順で行われます:
- Wikipediaの記事を取得する。
- テキストをチャンク分割する。
- テキストとそのベクトル表現をNeo4jに保存する。
- RAGアプリケーションをサポートするために、カスタムLangChainクラスを実装する。
この例では、単一のWikipedia記事のみを取得します。Baldur’s Gate 3のページを使用することにしました。
import wikipediabg3 = wikipedia.page(pageid=60979422)次に、テキストをチャンク分割して埋め込みます。テキストを二重の改行デリミタでセクションごとに分割し、適切なベクトルで各セクションを表現するためにOpenAIの埋め込みモデルを使用します。
import osfrom langchain.embeddings import OpenAIEmbeddingsos.environ["OPENAI_API_KEY"] = "API_KEY"embeddings = OpenAIEmbeddings()chunks = [{'text':el, 'embedding': embeddings.embed_query(el)} for el in bg3.content.split("\n\n") if len(el) > 50]LangChainクラスに進む前に、テキストのチャンクをNeo4jにインポートする必要があります。
graph.query("""UNWIND $data AS rowCREATE (c:Chunk {text: row.text})WITH c, rowCALL db.create.setVectorProperty(c, 'embedding', row.embedding)YIELD nodeRETURN distinct 'done'""", {'data': chunks})注目すべきことの一つは、ベクトルをNeo4jに保存するためにdb.create.setVectorProperty手順を使用したことです。この手順は、プロパティの値が実際に浮動小数点数のリストであることを検証するために使用されます。さらに、ベクトルプロパティのストレージスペースを約50%削減するという追加の利点があります。したがって、常にこの手順を使用してNeo4jにベクトルを保存することが推奨されます。
今度は、Neo4jのベクトルインデックスから情報を取得し、それを使用して回答を生成するために使用されるカスタムなLangChainクラスを実装していきます。まず、情報を取得するために使用されるCypherステートメントを定義します。
vector_search = """WITH $embedding AS eCALL db.index.vector.queryNodes('wikipedia',3, e) yield node, scoreRETURN node.text AS resultORDER BY score DESCLIMIT 3"""ご覧の通り、インデックス名と取得する近傍ノードの数kをハードコードしています。必要に応じて適切なパラメータを追加することで、これを動的にすることもできます。
カスタムなLangChainクラスは非常にシンプルに実装されています。
class Neo4jVectorChain(Chain): """Neo4jのベクトルインデックスに対して質問応答を行うためのチェーン。""" graph: Neo4jGraph = Field(exclude=True) input_key: str = "query" #: :meta private: output_key: str = "result" #: :meta private: embeddings: OpenAIEmbeddings = OpenAIEmbeddings() qa_chain: LLMChain = LLMChain(llm=ChatOpenAI(temperature=0), prompt=CHAT_PROMPT) def _call(self, inputs: Dict[str, str], run_manager) -> Dict[str, Any]: """質問を埋め込み、ベクトル検索を行う。""" question = inputs[self.input_key] # 質問を埋め込む embedding = self.embeddings.embed_query(question) # ベクトルインデックスから関連情報を取得 context = self.graph.query( vector_search, {'embedding': embedding}) context = [el['result'] for el in context] # 回答を生成 result = self.qa_chain( {"question": question, "context": context}, ) final_result = result[self.qa_chain.output_key] return {self.output_key: final_result}<p読みやすくするために一部のボイラープレートコードは省略しています。基本的に、Neo4jVectorChainを呼び出すと、以下の手順が実行されます:
- 関連する埋め込みモデルを使用して質問を埋め込む
- テキスト埋め込み値を使用してベクトルインデックスから最も類似したコンテンツを取得する
- 類似コンテンツから提供されたコンテキストを使用して回答を生成する
それでは、実装をテストしてみましょう。
vector_qa = Neo4jVectorChain(graph=graph, embeddings=embeddings, verbose=True)vector_qa.run("Baldur's Gate 3のゲームプレイはどのようなものですか?")レスポンス
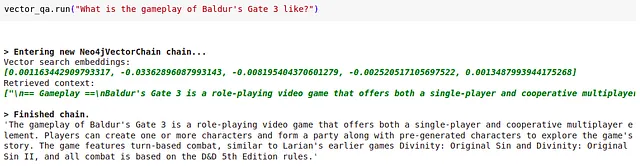
verboseオプションを使用することで、回答を生成するために使用されたベクトルインデックスから取得したコンテキストも評価することができます。
まとめ
Neo4jの新しいベクトルインデックス機能を活用することで、効果的に機能する統一されたデータソースを作成し、検索強化生成アプリケーションを実装することができます。これにより、「PDFやドキュメントとのチャット」ソリューションだけでなく、リアルタイムアナリティクスも実施することができるようになります。これにより、操作を効率化し、データのシナジーを高めることができるため、構造化データと非構造化データの両方を管理するための優れたソリューションとなります。
いつも通り、コードはGitHubで利用できます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- なぜ私たちはHugging Face Inference Endpointsに切り替えるのか、そしてあなたも切り替えるべきかもしれません
- 「Snorkel AI x Hugging Face 企業向けの基盤モデルを解放する」
- 複雑な生成型AIユースケースにおいて、Hugging Faceを活用する
- 「エンジニアがセメントとカーボンブラックを使用したバッテリーの代替手段を開発」
- 「25以上のChatGPTのプロンプトで、より多くのリードを生成し(そしてより多くの売り上げを生み出す)」
- 「AutoGPTQとtransformersを使ってLLMsを軽量化する」
- 「ESGレポーティングとは何ですか?」





