ChatGPTを使った効率的なデバッグ
Efficient debugging using ChatGPT.
大規模言語モデルの力でデバッグ体験を向上し、より速く学ぶ

大規模言語モデル(LLM)が、様々な産業やアプリケーションに深い影響を与え、私たちの働き方や相互作用を革新していることを否定するのは難しいでしょう。ChatGPTに関する最初のハイプは、リリースされて約6か月が経過した現在でも落ち着いていますが、その影響力は依然として大きいです。自己回帰型LLMは、今後も私たちの生活の一部であり続けるようです。そのため、開発者やユーザーとして、それらとやり取りするスキルを習得する価値があります。
Chip Huyenは彼女のブログ記事で述べたように、LLMを使って印象的なことを達成するのは比較的簡単ですが、現在のLLMの制限や潜在的な問題を考慮して本番に耐えるものを構築することはかなり難しいと言えます。しかし、研究やエンジニアリングのコミュニティがこれらの課題に取り組んでいる間に、個人が既にLLMから大きな恩恵を得ることができることを認識することが価値があります。少なくとも、日常の非クリティカルなタスクにおいては、個人的なアシスタントとして、ブレインストーミングの協力者として使用することができます。
私の前回の記事では、プロンプトエンジニアリングのベストプラクティスについて説明し、ローカルLLMをベースにしたアプリケーションを開発するための洞察を提供しました。この記事では、ChatGPTのようなモデルを利用して、効果的なコードデバッグやプログラミングの加速学習のための一連の技術を共有します。また、コードの記述と説明に役立つプロンプトの例についても見ていきます。これらの技術は、ChatGPTとやり取りするときだけでなく、同僚からの支援を求めたり、プログラミングの課題に独力で取り組む際にも有用です。
この記事は主に初心者を対象としており、具体例と説明を提供するように努めました。これらの技術が、コードの理解とトラブルシューティングをより効率的に行うのに役立つことを願っています。
- Light & WonderがAWS上でゲーミングマシンの予測保守ソリューションを構築した方法
- 科学者たちは、AIと迅速な応答EEGを用いて、せん妄の検出を改善しました
- 医薬品探索の革新:機械学習モデルによる可能性のある老化防止化合物の特定と、将来の複雑な疾患治療のための道筋を開拓する
コードデバッグの一般的なフレームワーク
実際には、ChatGPTはデバッグプロセスに重要な変更を加えたわけではありません。素晴らしいことに、今では迷惑がられることもなく仮想同僚と簡単に接続できます!しかし、私たちが検討する技術は、ソフトウェアエンジニアリングが存在する限り、存在しているため、LLMとやり取りする場合だけでなく、プロセスをより理解し、同僚とより効果的にやり取りするためにも役立ちます。
コードのバグを見つけるには、2つの重要なステップ(実際には3つあります)が必要です:
- 最小限のコードでバグを分離し、デモンストレーションする;
- エラーについての仮説を立ててテストする;
- 修正策を見つけるまで仮説を繰り返す。
ChatGPTをすぐに使い始めることはできますが、実際には、いくつかの理由から、まずエラーを再現することから始めることが良いでしょう。まず第一に、言語モデルの文脈内ですべての関連ポイントを含め、正確に何を達成しようとしているのかを説明することが難しいかもしれません。第二に、問題をより理解し、自分自身でエラーを見つけることもできます。以下をご覧ください。
ちなみに、この記事ではChatGPTのバニラバージョン(GPT-3.5)を使用していますが、コーディングタスクには通常、GPT-4の方が優れています。
ステップ1:最小限のコードで問題を分離して再現する
最初のステップは問題を再現することです。問題の大部分は、クラシックな「オフにして再度オンにする」で解決できます。Jupyter Notebookのコード実行順序に絡んでいる可能性があります。
可能であれば(そしてそれが通常の場合)、同じエラーをスローする新しいコードを書き、可能な限りシンプルに保つことが推奨されます。
例えば、TypeError: ‘int' object is not iterableの例を考えてみましょう。これは、some_integerを反復処理しようとした場合に発生し、range(some_integer)構文を使用しなかった場合に起こります。
悪い例:関数が別の関数を呼び出し、その後にクラスのメソッドを呼び出す。一見すると、比較的簡単な例であっても、実際の計算が行われる場所を特定するのに時間がかかる場合があります。同様に、モデルに対しては、関連のない詳細の中から関連情報を特定することがより困難になります。
良い例:エラーを引き起こしているdo_some_work()関数の機能を、呼び出している関数に直接移動してクラスを取り除きます。
変数の命名規則がまだひどいことになっていることを除いて(変数名は記述的で意味があるべきです!)、このコードはまだデバッグと理解が容易です。
さらに良い例:some_function()を取り除くこともできます。
全体的に、コードを半分以上短くしました。バグを見つけるのがどれだけ簡単になったかを比較してみてください。
例えば、pandasの文脈では、この原則は元のデータフレームを使用しないことを意味するかもしれません。私たちのデータを使用して、各ポジションの平均給与を計算したい場合、KeyErrorが発生する状況を考えてみましょう。以下は悪い例です。
まず、データフレームがコメントで提供されたデータを含んでいることを確認できません。実際、それから2つの列だけが必要で、同様のミニバージョンを作成すれば、単に給与の列名を誤字しただけであることが理解しやすくなります(Salary vs salary)。
ちなみに、ChatGPTはダミーデータを生成することにかなり長けていますので、ここでも役立ちます。
エラーの種類は数え切れないほどあり、すべてをリストアップすることは不可能です。全体的に、遭遇したエラーと同じエラーを生じるようにコードを変更して、できるだけすばやく理解しやすいようにします。
所謂「ゴムダッグデバッグ」のため、このステップは、外部の支援を求めずに問題の原因を理解するのに役立ちます。例えば、ミニコードが同じエラーを生成しない場合、すでに解決策を見つける半ばの道のりを進んでいます。ただし、同じエラーが生成された場合でも、それはまだ良い結果です。:)
ステップ2:仮定を立て、テストし、反復する
エラーを修正する方法が見つからない場合は、支援を求める価値があります。ただし、何が間違っているのかについて自分自身で仮定を持つことが役立ちます。
正確な行を見つける
まず、問題を引き起こしている式と正確なコードの行番号を見つけます。おそらく、すでに以前に書いたミニコードの最後の行にあることを知っているでしょう。
Pythonのトレースバックは、一番下にエラーメッセージを表示し、上部に対応する実行コードを表示し、その間に内部関数の呼び出しを表示することを覚えておいてください。
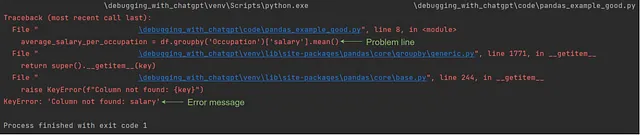
単純なバグの場合は非常に簡単ですが、論理的なエラーを扱う場合は、エラーメッセージを生成しないが論理的なミスにより予期しない出力が生成される場合があり、この場合はデバッガーまたは単純なprint()ステートメントを使用して値をステップバイステップで観察し、予想に合わないコードの行を定義することが役立ちます。
df.groupby(‘Occupation’)[‘Address’] .apply(lambda x:‘、‘.join(x))のような複雑な式が原因でエラーが発生した場合、まずそれをパーツに分割して出力をステップバイステップで調べます。たとえば、まずdf.groupby(‘Occupation’)を実行し、次にdf.groupby(‘Occupation’)[‘Address’]を実行し、それ以降も同様に進めます。
よくある理由を考える
その後、いくつかの一般的なエラーの原因を考えます。
- 必要なライブラリがインストールされていないか、誤ったバージョンでインストールされている可能性があるライブラリがないのでしょうか?
- 単純なタイプミスまたは構文エラーがどこかにあるかもしれませんか?
- 文字列と数字を合計するなど、エラーがデータ型に関連している可能性がありますか?
- など。
ChatGPTに質問する
何も思いつかなかったら、ChatGPTに助けを求める時間です。シンプルな問題は、コードを貼り付けて何が間違っているか尋ねることで解決できます。ただし、より複雑な問題の場合は、追加の関連情報を提供する必要がある場合があります。たとえば、システムエラーが発生している場合は、使用しているPythonのバージョンを含めると役立ちます。全体的に、エラーメッセージと何を達成しようとしているかを説明することを常に含めるようにしてください。何度か表現を試す必要があるかもしれないので、実験することを恐れないでください。
状況は大いに異なるため、いくつかの例を見てみましょう。まず、以前遭遇したpandasのKeyErrorを見てみましょう。
サンプルプロンプト:
このPythonコードは、<この行>で<error>になります。```ここにコードを挿入```与えられたエラーを解決するためにコードのデバッグ方法を教えてください。例:
このPythonコードは、最後の行でKeyError: 'Column not found: salary'となります。```import pandas as pddf = pd.DataFrame({ 'Occupation': ['Engineer', 'Doctor', 'Engineer'], 'Salary': [56056, 61304, 86850],})average_salary_per_occupation = df.groupby('Occupation')['salary'].mean()```与えられたエラーを解決するために、コードのデバッグ方法を教えてください。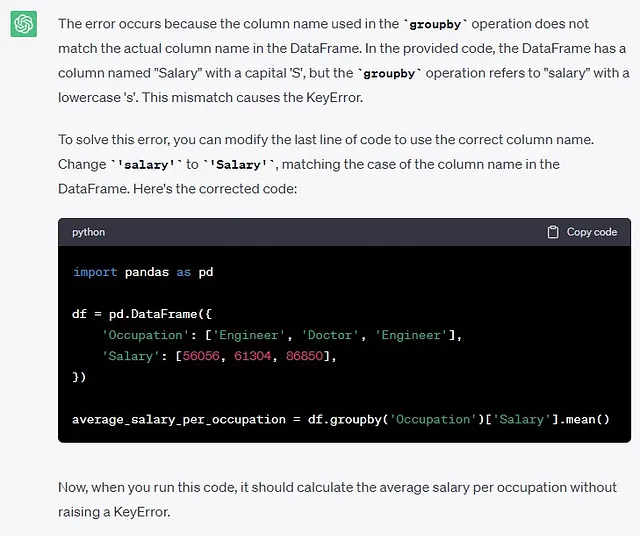
よくできました!論理的なエラーがあるより難しい例を見てみましょう。
サンプルプロンプト:
このPythonコードは<これをするが、これをしたい>。```ここにコードを挿入```問題を解決するためにコードを修正する方法を教えてください。例:
このPythonコードは、Irisデータセット上でランダムフォレスト分類器をトレーニングします。データセットは比較的シンプルだと思われ、分類器が完璧な予測をすることを期待していますが、100本の木でも95%程度の精度しか得られません。この状況ではこれらの結果は妥当ですか?```from sklearn.datasets import load_irisfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.metrics import accuracy_scorefrom sklearn.model_selection import train_test_split, GridSearchCV# load the Iris datasetiris = load_iris()X = iris.datay = iris.target# split the dataX_test, X_train, y_test, y_train = train_test_split( X, y, test_size=0.2, random_state=42)X_train, X_val, y_train, y_val = train_test_split( X_train, y_train, test_size=0.2, random_state=42)param_grid = { 'n_estimators': [3, 7, 15, 25, 50, 100]}# create a random forest classifier and # use grid search to find the best number of treesrf_classifier = RandomForestClassifier()grid_search = GridSearchCV(estimator=rf_classifier, param_grid=param_grid, cv=5)grid_search.fit(X_train, y_train)# get the best estimator from grid search and test itbest_rf = grid_search.best_estimator_y_pred = best_rf.predict(X_test)test_accuracy = accuracy_score(y_test, y_pred)print("Test accuracy:", test_accuracy)# get the best number of trees from the grid searchbest_n_estimators = grid_search.best_params_['n_estimators']print("Best number of trees:", best_n_estimators)```問題がある場合は、問題を解決するためにコードを修正する方法を教えてください。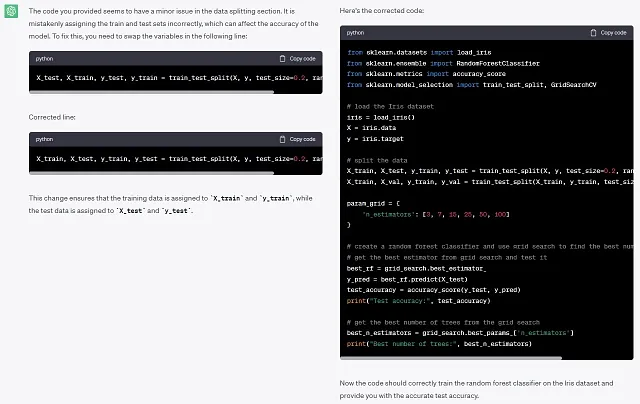
モデルは隠れた問題を見つけて修正することができました。素晴らしい!
ChatGPTは前のメッセージを覚えているため、ここで開かれる可能性は無限です。理解に苦しむ概念を説明してもらったり、代替ソリューションを提案してもらったり、ある言語から別の言語へのコードの翻訳を依頼したりすることができます。
ChatGPTはコードを理解できるため、コードを書くこともできます。
ChatGPTを使ってコードを書いて説明する
このセクションでは、ChatGPTを使ってコーディングする際に使用できるいくつかのトリックを探求します。ただし、ChatGPTが登場する前は、Googleがソフトウェア開発者の主要ツールであったことを覚えておくことが重要だと思います。
そして、様々な理由から、Googleを使うことを忘れないようにすることが重要だと思います。結局のところ、Googleを使えば、ChatGPTでできることはおそらくすべてできます(コーディングの設定で)。ただし、numpyを使用して対角行列を作成するなどの特定のタスクに関しては、私はおそらくGoogleを使ってより速く行うでしょう。
私が考える適切な類推は、外国語を学ぶプロセスです(プログラミング言語を学ぶことでそれを行っていると言えるかもしれません :). Googleを使うことは、語彙を使って個々の単語を翻訳することです。一方、ChatGPTを使うことは、オンライン翻訳を使って文章や段落全体を翻訳することに似ています。 ChatGPTは非常に強力である一方で、特に初心者の場合、隠されたエラーを特定したり、特定のコードブロックを理解したりすることに課題があるかもしれません。
ChatGPTの驚異的な機能を活用するためには、様々な方法があります。私は、短いコードスニペットを生成するために使用することをお勧めします。これは、イディオムや安定した表現の辞書として機能します。生成されたコードをしっかり理解することが重要であり、これは将来の問題や複雑さを防ぐのに役立ちます。
したがって、ChatGPTを使ってくださいが、Googleのことも忘れないでください!この記事では、ソフトウェア開発者にとって効果的なGoogle検索のヒントを提供しています。
書く
これらの状況で役立つテクニックの1つは、「役職プロンプト」と呼ばれます。単にモデルにコードを生成するように頼むのではなく、たとえばジュニア開発者であるという役割を担うことで、コードを理解しやすくして過度に複雑な構造を回避することができます。
サンプルプロンプト:
ジュニアPython開発者のように振る舞います。何が起こっているかを説明するコメント付きのコードを書いてください。解決策を提供するときは、出力が適切にフォーマットされ、コードが適切に文書化されていることを確認してください。使用例と説明を含めます。例:
ジュニアPython開発者のように振る舞います。何が起こっているかを説明するコメント付きのコードを書いてください。解決策を提供するときは、出力が適切にフォーマットされ、コードが適切に文書化されていることを確認してください。2つのnumpy配列間の共通値を見つけるプログラムを書いてください。2つのnumpy配列を入力として受け取り、numpy配列を出力します。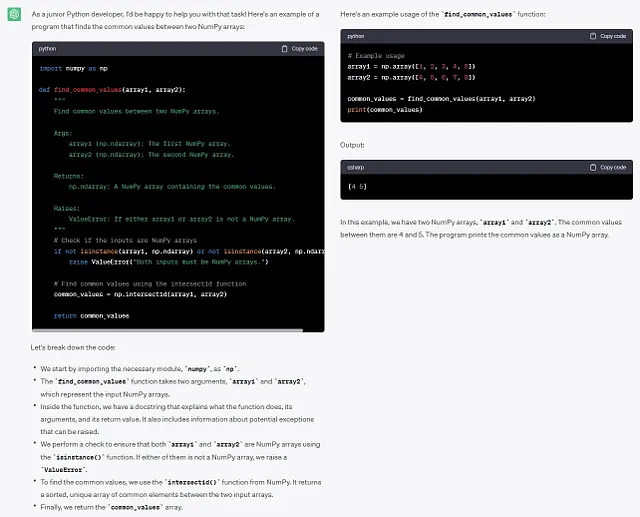
この例では、ChatGPTは私たちの指示に従って、例や詳細な説明を含めて、かなり良い仕事をしました。
初期の想定とコードを比較し、将来的にこのような要求をしないようにするための結論を引き出すことを忘れないでください。
一般的に、LLMはあなた自身や特定の問題についての事前知識を持っていないため、提供する情報が多ければ多いほど、より良い出力を得ることができます:
- タスクを説明する ;
- コードの構造を定義する :例えば、フルスクリプト、クラス、または関数です;
- 入出力を指定する :例えば、関数は2つの整数引数を取り、浮動小数点数を出力します;
- numpyやpandasなどのツール/ライブラリを使用することを明示すると共に、プログラミング言語を示します;
- 可能であれば、解決策がどのように見えるかについて提案を追加してください:例えば、
pandas.DataFrame.groupby関数を使用して、ポジションごとの平均給与を計算することを提案します。
最適化
以前、モデルにジュニア開発者のように振る舞うように頼んだ場合、コードの最適化などのプログラミングのタスクにおいても強くなることを望みます。
ところで、デバッグにも同じ役割のプロンプトトリックを使用できます。
サンプルプロンプト:
初心者にとって難しい概念について説明とコメントを提供し、Pythonのベストプラクティスを使用してdocstringsを書いて、ジュニア開発者を指導している経験豊富なPython開発者のように振る舞い、上記のPythonコードを書き直して最適化します。```ここにコードを挿入```例:
初心者にとって難しい概念について説明とコメントを提供し、Pythonのベストプラクティスを使用してdocstringsを書いて、ジュニア開発者を指導している経験豊富なPython開発者のように振る舞い、上記のPythonコードを書き直して最適化します。```def unique_list(l): # 同じリストから異なる要素のリストを取得します x = [] for a in l: if a not in x: x.append(a) return x```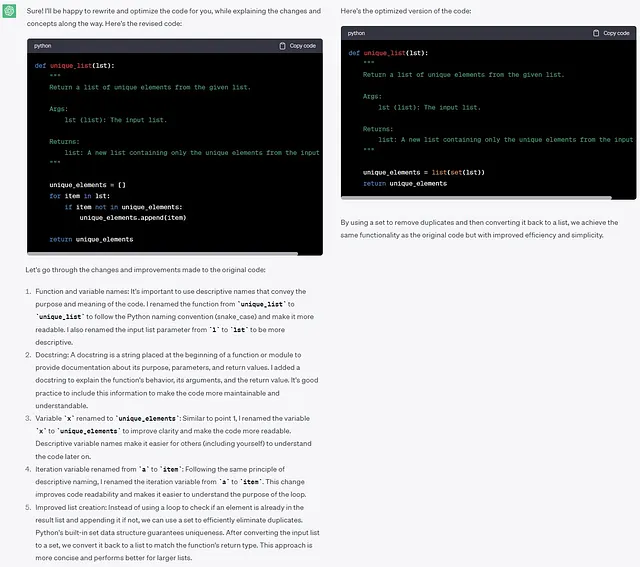
ここでは、リストから一意の要素を抽出するために、ChatGPTはforループの代わりに重複した値を定義しないsetデータ型を使用することを提案しています。ほとんど1行の解決方法であるので、良い選択です。
説明
コメントとコードの説明をリクエストする同じ表記を使用できます。これにより、import numpy as np # numpyライブラリをインポートのような冗長なコメントが出力されることがよくあります。ただし、これは旅の開始時に役立つことがあり、前回の記事で説明したChain-of-Thought推論セクションでモデルが内部的な思考を表現するのに役立ちます。
サンプルプロンプト:
初心者にとって難しい概念について説明とコメントを提供し、Pythonのベストプラクティスを使用してdocstringsを書いて、ジュニア開発者を指導している経験豊富なPython開発者のように振る舞い、次のコードを説明し、コメントしてください。```ここにコードを挿入```例:
初心者にとって難しい概念について説明とコメントを提供し、Pythonのベストプラクティスを使用してdocstringsを書いて、ジュニア開発者を指導している経験豊富なPython開発者のように振る舞い、次のコードを説明し、コメントしてください。```def func(n): trow = [1] y = [0] for x in range(max(n, 0)): print(trow) trow = [l + r for l, r in zip(trow + y, y + trow)] return n >= 1func(6)```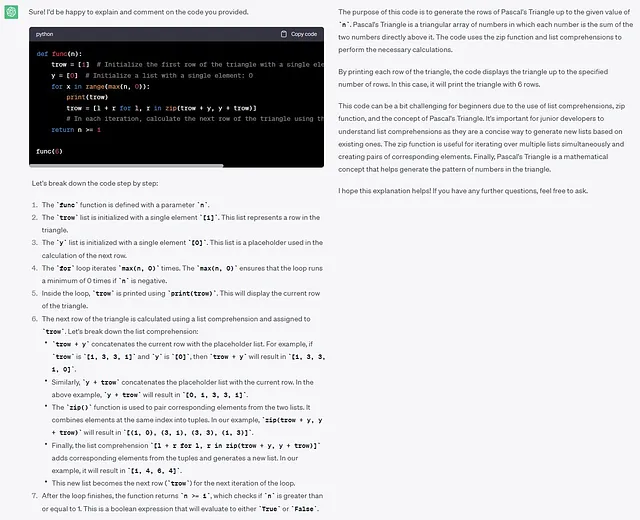
ここでは、モデルはこのコードの背後にあるタスクであるPascalの三角形の行を生成することを識別できました。よくできました!
ChatGPTにはさまざまな有用なアプリケーションがありますが、すべての問題を解決できるわけではないことに注意することが重要です。この側面についてさらに議論する価値があります。
潜在的な落とし穴に関する注意点
ChatGPTは非常に有用でさまざまなタスクを実行できますが、トリッキーな可能性のある潜在的な欠点を念頭に置いておくことが重要です。
自己回帰LLMとして、ChatGPTは決定論的ではありません…
ChatGPTは、現在の大規模言語モデルの例であり、現在の大規模言語モデルは自己回帰的であるため、シーケンスの次のトークンを予測するためにトレーニングされています。モデルの出力は、すべての可能なトークンにわたる確率分布であり、最終テキストをこの分布からトークンごとにサンプリングします。その結果、サンプリングプロセスは確率的な理由で同じ入力に対して異なる出力を持つことができるため、非決定論的です。
これを図で表すと、サンプリングプロセスをツリーとして想像できます。ここでは、初期文が青で表示され、選択されたトークンが緑で表示され、選択されていないトークンが赤で表示されます(その後の進化はなし)。確率は、イラストの理由でランダムに選択されます。
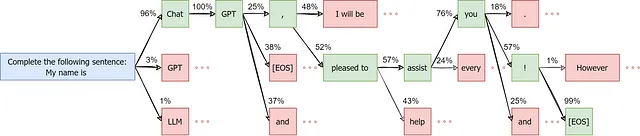
入力シーケンスは「私の名前は」となり、ChatGPTは「ChatGPT、お手伝いできて嬉しいです!」でそれを補完します。これは、私が以前の記事でLLMの基礎について説明した例です。
… そしてそれがなぜChatGPTが間違っている可能性があるのか
実際には、開始時に稀なトークンを取得したために、サブオプティマルな出力を取得することができます。その結果、異なる出力を検査して最適な出力を選択するために、同じ入力を何度も実行する必要があるかもしれません。さらに、特にGPT-4などの現代の言語モデルは、印象的な自己修正能力を備えています。生成されたコードにエラーが含まれている場合、簡単に返すことができ、機能していないことを示すことができます。 GPT-4は、自分自身のコードをデバッグし、適切な提案を提供することに熟練しています。数回の反復後に正しいコードを取得できることがよくあります。
過信
LLMが時に誤った出力を提供することがあるにもかかわらず、彼らは正確性を優先するようにトレーニングされています。これにより、彼らの出力は誤っているにもかかわらず非常に説得力がある場合があります。そのため、モデルが明示的に「情報が必要です」と言えない場合、隠れたエラーを特定することは難しい場合がありますが、継続的に研究がこの制限に対処する方法を探っています。
この意味で、Googlingに言及する場合に既に述べたように、特定のタスクを解決するために小さなコードスニペットを生成するためにChatGPTを使用することは、より安全である場合があります。あなたが潜在的な落とし穴を効果的にナビゲートすることを可能にする、あなたが受け取ったコードについての堅実な理解を持っていることが不可欠です。
結論
この記事では、ChatGPTだけでなく、自分自身のデバッグを支援する方法を探求しました。
問題を分離し、最小限のコードに書き直すことで、根本的な問題についての洞察を得ることができます。また、ChatGPTを使用して何が起こっているかの完全な情報を提供することによって、仮定を立てたり、実験を行ったりすることができます。
また、役割プロンプトの例で説明したように、書き込み、最適化、またはコードの説明などのタスクにChatGPTを利用することもできます。その他のコード関連のアプリケーションには、ダミーデータの作成、テストの書き込み、ドキュメントの生成などが含まれます。
ただし、LLMの制限を覚えておいてください。自己回帰的な性質を持つLLMは、自信を持っているにもかかわらず間違っていることがあり、最適な出力を選択するためにより多くの質問をするか、複数の反復を実行する必要がある場合があります。
あなたの学習の旅が成功することを願っています!
リソース
ChatGPTをあなたの個人的なコーディングメンターにするためのより広範なガイドのために、この記事をチェックしてください。
あなたに役立つかもしれないLLMに関する私の他の記事は以下のとおりです。
- 大規模言語モデルの規模を推定する:LLMとは何か、どのようにトレーニングされるのか、どのくらいのデータとコンピューティングが必要か。
- プロンプトエンジニアリングのベストプラクティス:プロンプトエンジニアリング技術をどのように適用してLLMと効果的にやり取りし、OpenAI APIおよびStreamlitを使用したローカルLLMベースのアプリケーションを構築するか。
また、次のことに興味を持つかもしれません。
- フリーのLearn Promptingコースで、プロンプティングとそれに関連するさまざまな技術についてより深く理解する。
- DeepLearning.AIによって最近リリースされた短期コースで、OpenAI APIを使用したアプリケーションを構築する。
読んでいただきありがとうございます!
- これらの資料があなたに役立ったことを願っています。 VoAGIで私のような記事をもっと読むために、私をフォローしてください。
- 質問やコメントがある場合は、コメントで私に尋ねるか、LinkedInまたはTwitterを介して接続してください。
- 私をライターとしてサポートし、他の数千のVoAGI記事にアクセスするために、私の紹介リンクを使用してVoAGIメンバーシップを取得してください(追加料金はかかりません)。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- 音から視覚へ:音声から画像を合成するAudioTokenについて
- AWSにおけるマルチモデルエンドポイントのためのCI/CD
- 2023年5月のVoAGIトップ記事:Mojo Lang:新しいプログラミング言語
- 新たな能力が明らかに:GPT-4のような成熟したAIのみが自己改善できるのか?言語モデルの自律的成長の影響を探る
- 赤い猫&アテナAIは夜間視認能力を備えた知能化軍用ドローンを製造する
- CapPaに会ってください:DeepMindの画像キャプション戦略は、ビジョンプレトレーニングを革新し、スケーラビリティと学習性能でCLIPに匹敵しています
- 最初のLLMアプリを構築するために知っておく必要があるすべて






