「Amazon SageMakerでのRayを使用した効果的な負荷分散」
Effective Load Balancing with Ray on Amazon SageMaker
DNNトレーニングの効率向上とトレーニングコストの削減のための方法
以前の投稿(例:こちら)では、DNNトレーニングのワークロードのパフォーマンスをプロファイリングし最適化する重要性について詳しく説明しました。ディープラーニングモデルのトレーニングは、特に大規模なものは費用がかかる作業です。モデルの収束を加速しトレーニングコストを最小限に抑えるために、トレーニングリソースの最大限の利用を実現する能力は、プロジェクトの成功において決定的な要素となります。パフォーマンスの最適化は、アプリケーション内のパフォーマンスボトルネック、つまりリソース利用の増加や実行時間の加速を妨げている部分を特定し修正する反復的なプロセスです。
この投稿は、ディープラーニングモデルのトレーニング時によく遭遇するパフォーマンスボトルネックの一つである「データ前処理のボトルネック」に焦点を当てた一連の投稿の3つ目です。データ前処理のボトルネックは、GPU(または代替のアクセラレータ)が、過負荷のCPUリソースからのデータ入力を待っている間にアイドル状態になる状況です。
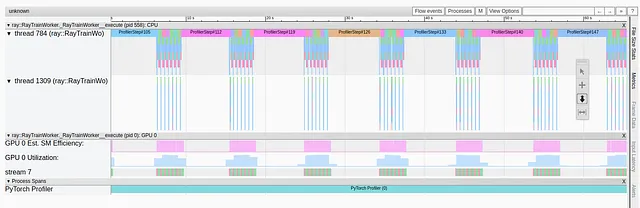
このトピックに関する最初の投稿では、次のような対策方法について説明し、デモンストレーションしました。
- ワークロードにより適したCPUからGPUの計算比率を持つトレーニングインスタンスを選択すること
- CPUとGPUのワークロードバランスを改善し、一部のCPU操作をGPUに移動すること
- 補助CPUワーカーデバイスに一部のCPU演算をオフロードすること
TensorFlow Data Service APIを使用して3番目のオプションをデモンストレーションしました。これはTensorFlowに特化したソリューションであり、gRPCを基礎とした通信プロトコルを使用して、一部の入力データ処理を他のデバイスにオフロードすることができます。
- 『ご要望に合わせたチャット:ソフトウェア要件に応用した生成AI(LLM)の旅』
- プラグインを使ったチャットボットのためのカスタムスキルの作成
- 集団ベーストレーニング(PBT)ハイパーパラメータのチューニング
2番目の投稿では、より一般的な目的のgRPCベースのソリューションを提案し、おもちゃのPyTorchモデルでデモンストレーションしました。TensorFlow Data Service APIよりも手動のコーディングと調整が少し多く必要でしたが、このソリューションはより大きな堅牢性を提供し、トレーニングパフォーマンスの同じ最適化を可能にしました。
Rayによる負荷分散
この投稿では、一般的なソリューションの堅牢性とTensorFlow固有のAPIの簡単さと使いやすさを組み合わせるための、補助CPUワーカーの使用に関する追加の方法を示します。デモンストレーションする方法は、Ray DataライブラリのRayデータセットを使用するものです。Rayのリソース管理と分散スケジューリングシステムの全力を活用することで、Ray Dataはトレーニングデータの前処理をスケーラブルかつ分散的に実行することができます。特に、Ray Datasetを設定して、利用可能なCPUリソースを自動的に検出して利用するようにします。さらに、Ray AIR Trainerでモデルのトレーニングループをラップすることで、マルチGPU環境へのシームレスなスケーリングを実現します。
Amazon SageMakerでのRayクラスターのデプロイ
複数ノード環境でRayフレームワークとその提供するユーティリティを使用するための前提条件は、Rayクラスターのデプロイです。一般的に、このような計算クラスターの設計、デプロイ、管理、保守は困難な作業であり、専門のDevOpsエンジニア(またはエンジニアチーム)が必要となることがしばしばあります。これは開発チームにとって乗り越えられない障壁となる場合もあります。この投稿では、Amazon SageMakerの管理トレーニングサービスを使用してこの障壁を克服する方法を示します。具体的には、GPUインスタンスとCPUインスタンスの両方を備えたSageMakerの異種クラスターを作成し、起動時にRayクラスターをデプロイします。その後、Rayクラスター上でRay AIRトレーニングアプリケーションを実行し、クラスター内のすべてのリソースに対して効果的な負荷分散を実現するためにRayのバックエンドに頼ります。トレーニングアプリケーションの完了時には、Rayクラスターは自動的に解体されます。このようにSageMakerを使用することで、クラスター管理に一般的に関連するオーバーヘッドなしにRayクラスターを展開して使用することができます。
Rayは、さまざまな機械学習のワークロードを可能にする強力なフレームワークです。この投稿では、Rayのバージョン2.6.1を使用して、その能力とAPIの一部を紹介します。この投稿はRayのドキュメンテーションの代わりに使用しないでください。Rayのユーティリティの最も適切で最新の使用方法については、公式ドキュメンテーションを確認してください。
始める前に、Ray Dataライブラリとそのユニークな機能を紹介してくれたBoruch Chalkさんに特別な感謝を申し上げます。
おもちゃの例
議論を容易にするために、合成データセット上でトレーニングされるシンプルなPyTorch(2.0)Vision Transformerベースの分類モデルを定義してトレーニングします。Ray AIRのドキュメンテーションには、Ray AIRを使用してさまざまなタイプのトレーニングワークロードを構築する方法を示すさまざまな例が含まれています。ここで作成するスクリプトは、PyTorchの画像分類器の例に記載されている手順に基づいています。
Rayデータセットと前処理の定義
Ray AIR Trainer APIでは、トレーニングループにフィードする前にデータセットの要素に適用される前処理パイプラインと、生のRayデータセットを区別します。生のRayデータセットには、サイズがnum_recordsの整数のシンプルな範囲を作成します。次に、データセットに適用したい前処理を定義します。RayのPreprocessorには、2つのコンポーネントが含まれています。1つ目は、生の整数をランダムな画像-ラベルのペアにマップするBatchMapperです。2つ目は、ランダムなバッチをPyTorchテンソルに変換し、一連のGaussianBlur操作を適用するTorchVisionPreprocessorです。GaussianBlur操作は、比較的重いデータ前処理パイプラインをシミュレートするためのものです。2つのPreprocessorはChain Preprocessorを使って結合されます。RayデータセットとPreprocessorの作成は、以下のコードブロックで示されています:
import rayfrom typing import Dict, Tupleimport numpy as npimport torchvision.transforms as transformsfrom ray.data.preprocessors import Chain, BatchMapper, TorchVisionPreprocessordef get_ds(batch_size, num_records): # 生のRayタブラデータセットを作成する ds = ray.data.range(num_records) # 整数をランダムな画像-ラベルのペアにマップする def synthetic_ds(batch: Tuple[int]) -> Dict[str, np.ndarray]: labels = batch['id'] batch_size = len(labels) images = np.random.randn(batch_size, 224, 224, 3).astype(np.float32) labels = np.array([label % 1000 for label in labels]).astype( dtype=np.int64) return {"image": images, "label": labels} # プリプロセッサの最初のステップは、バッチの整数をランダムな画像-ラベルのペアにマップする synthetic_data = BatchMapper(synthetic_ds, batch_size=batch_size, batch_format="numpy") # numpyのペアをテンソルに変換し、一連のガウシアンブラーを適用するtorchvisionの変換を定義する transform = transforms.Compose( [transforms.ToTensor()] + [transforms.GaussianBlur(11)]*10 ) # プリプロセッサの2番目のステップは、torchvisionの変換を適用する vision_preprocessor = TorchVisionPreprocessor(columns=["image"], transform=transform) # プリプロセッサのステップを結合する preprocessor = Chain(synthetic_data, vision_preprocessor) return ds, preprocessorRayのデータパイプラインは、Rayクラスタ内で利用可能なすべてのCPUを自動的に使用します。これには、GPUインスタンスのCPUリソースと、クラスタ内の追加の補助インスタンスのCPUリソースも含まれます。
トレーニングループの定義
次のステップは、各トレーニングワーカー(例:GPU)で実行されるトレーニングシーケンスを定義することです。まず、人気のあるtimm(0.6.13)Pythonパッケージを使用してモデルを定義し、train.torch.prepare_model APIを使用してラップします。次に、データセットから適切なシャードを抽出し、要求されたバッチサイズでデータバッチを生成し、トレーニングデバイスにコピーするイテレータを定義します。それから、トレーニングループ自体が続きます。このループを終了すると、結果の損失メトリクスを報告します。ワーカーごとのトレーニングシーケンスは、以下のコードブロックで示されています:
import timefrom ray import trainfrom ray.air import sessionimport torch.nn as nnimport torch.optim as optimfrom timm.models.vision_transformer import VisionTransformer# timmを使用してViTモデルを構築するdef build_model(): return VisionTransformer()# ワーカーごとのトレーニングループを定義するdef train_loop_per_worker(config): # PyTorchモデルをRayオブジェクトでラップする model = train.torch.prepare_model(build_model()) criterion = nn.CrossEntropyLoss() optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9) # 適切なデータセットシャードを取得する train_dataset_shard = session.get_dataset_shard("train") # データセットからバッチを返すイテレータを作成する train_dataset_batches = train_dataset_shard.iter_torch_batches( batch_size=config["batch_size"], prefetch_batches=config["prefetch_batches"], device=train.torch.get_device() ) t0 = time.perf_counter() for i, batch in enumerate(train_dataset_batches): # 入力とラベルを取得する inputs, labels = batch["image"], batch["label"] # パラメータの勾配をゼロにする optimizer.zero_grad() # 順伝搬 + 逆伝搬 + 最適化 outputs = model(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 統計情報を表示する if i % 100 == 99: # 100ミニバッチごとに表示 avg_time = (time.perf_counter()-t0)/100 print(f"Iteration {i+1}: avg time per step {avg_time:.3f}") t0 = time.perf_counter() metrics = dict(running_loss=loss.item()) session.report(metrics)Ray Torch Trainer の定義
データパイプラインとトレーニングループを定義したら、Ray TorchTrainer の設定に移ることができます。Trainer をクラスタ内の利用可能なリソースを考慮して設定します。具体的には、トレーニングワーカーの数を GPU の数に合わせ、バッチサイズを対象 GPU の利用可能なメモリに合わせて設定します。また、1000 ステップのトレーニングに必要なレコード数でデータセットを構築します。
from ray.train.torch import TorchTrainerfrom ray.air.config import ScalingConfigdef train_model(): # 利用可能なリソースに合わせてワーカーの数、データセットのサイズ、データストレージのサイズを設定します num_gpus = int(ray.available_resources().get("GPU", 0)) # GPU の数に基づいてトレーニングワーカーの数を設定します num_workers = num_gpus if num_gpus > 0 else 1 # Amazon EC2 g5 インスタンスファミリーの GPU メモリ容量に基づいてバッチサイズを設定します batch_size = 64 # 1000 ステップのトレーニングに必要なデータで合成データセットを作成します num_records = batch_size * 1000 * num_workers ds, preprocessor = get_ds(batch_size, num_records) ds = preprocessor(ds) trainer = TorchTrainer( train_loop_per_worker=train_loop_per_worker, train_loop_config={"batch_size": batch_size}, datasets={"train": ds}, scaling_config=ScalingConfig(num_workers=num_workers, use_gpu=num_gpus > 0), ) trainer.fit()Ray クラスタのデプロイとトレーニングシーケンスの実行
トレーニングスクリプトのエントリーポイントを定義します。ここで、Ray クラスタをセットアップし、ヘッドノードでトレーニングシーケンスを開始します。このチュートリアルで説明されているように、sagemaker-training ライブラリの Environment クラスを使用して、ヘテロジニアスな SageMaker クラスタのインスタンスを検出します。GPU インスタンスグループの最初のノードを Ray クラスタのヘッドノードと定義し、他のすべてのノードに適切なコマンドを実行してクラスタに接続します(クラスタの作成の詳細については、Ray のドキュメントを参照してください)。ヘッドノードは、すべてのノードが接続されるまで待機し、その後トレーニングシーケンスを開始します。これにより、Ray は基礎となる Ray タスクの定義と配布に利用可能なすべてのリソースを利用します。
import timeimport subprocessfrom sagemaker_training import environmentif __name__ == "__main__": # Environment() クラスを使用して SageMaker クラスタを自動検出します env = environment.Environment() if env.current_instance_group == 'gpu' and \ env.current_instance_group_hosts.index(env.current_host) == 0: # ヘッドノードが Ray クラスタを開始します p = subprocess.Popen('ray start --head --port=6379', shell=True).wait() ray.init() # クラスタ内のノードの総数を計算します groups = env.instance_groups_dict.values() cluster_size = sum(len(v['hosts']) for v in list(groups)) # SageMaker のノードが Ray クラスタに接続するまで待機します connected_nodes = 1 while connected_nodes < cluster_size: time.sleep(1) resources = ray.available_resources().keys() connected_nodes = sum(1 for s in list(resources) if 'node' in s) # トレーニングシーケンスを呼び出します train_model() # Ray クラスタを終了します p = subprocess.Popen("ray down", shell=True).wait() else: # ワーカーノードがヘッドノードに接続します head = env.instance_groups_dict['gpu']['hosts'][0] p = subprocess.Popen( f"ray start --address='{head}:6379'", shell=True).wait() # クラスタがまだ稼働しているか確認するためのユーティリティ def is_alive(): from subprocess import Popen p = Popen('ray status', shell=True) p.communicate()[0] return p.returncode # ヘッドノードのプロセスが完了するまでノードを稼働させ続けます while is_alive() == 0: time.sleep(10)Amazon SageMaker ヘテロジニアスクラスタでのトレーニング
トレーニングスクリプトが完成したら、Amazon SageMaker ヘテロジニアスクラスタにデプロイする必要があります。このために、このチュートリアルで説明されている手順に従います。まず、source_dir ディレクトリを作成し、その中に train.py スクリプトと、スクリプトの依存関係である timm と ray[air] の 2 つの pip パッケージを含む requirements.txt ファイルを配置します。これらは、SageMaker クラスタ内の各ノードに自動的にインストールされます。次に、1 つ目は ml.g5.xlarge インスタンス(1 つの GPU と 4 つの vCPU を含む)で、2 つ目は ml.c5.4xlarge インスタンス(16 つの vCPU を含む)で、2 つの SageMaker インスタンスグループを定義します。そして、SageMaker PyTorch エスティメータを使用して、トレーニングジョブを定義し、クラウドに展開します。
from sagemaker.pytorch import PyTorch
from sagemaker.instance_group import InstanceGroup
cpu_group = InstanceGroup("cpu", "ml.c5.4xlarge", 1)
gpu_group = InstanceGroup("gpu", "ml.g5.xlarge", 1)
estimator = PyTorch(
entry_point='train.py',
source_dir='./source_dir',
framework_version='2.0.0',
role='<arn role>',
py_version='py310',
job_name='hetero-cluster',
instance_groups=[gpu_group, cpu_group])
estimator.fit()結果
以下の表では、トレーニングスクリプトを2つの異なる設定で実行した場合のランタイム結果を比較しています。1つは単一のml.g5.xlarge GPUインスタンスで実行し、もう1つはml.g5.xlargeインスタンスとml.c5.4xlargeインスタンスを含む異種クラスタで実行します。システムリソースの利用状況はAmazon CloudWatchを使用して評価し、トレーニングコストはこの執筆時点でのAmazon SageMakerの価格情報(ml.c5.4xlargeインスタンスの場合は1時間あたり$0.816、ml.g5.xlargeの場合は$1.408)を使用して推定しています。
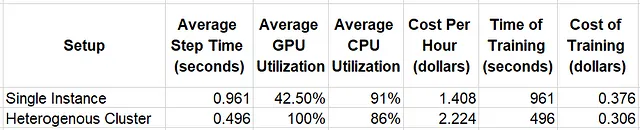
単一のインスタンス実験では、比較的高いCPU利用率と低いGPU利用率が示され、データ前処理パイプラインにおけるパフォーマンスボトルネックが明確になります。この問題は異種クラスタへの移行によって解消されます。GPUの利用率だけでなく、トレーニング速度も向上します。全体的に、トレーニングの価格効率が23%向上します。
これらのおもちゃの実験は、Rayエコシステムによって有効化された自動負荷分散機能をデモンストレーションするために作成されたものであることを強調しておきます。制御パラメータの調整によりパフォーマンスが向上した可能性もあります。また、CPUのボトルネックに対する別の解決策(例えば、より多くのCPUを持つEC2 g5ファミリのインスタンスを選択するなど)を選択することで、コストパフォーマンスが向上する可能性もあります。
まとめ
この記事では、Rayデータセットを使用して、クラスタ内のすべての利用可能なCPUワーカーに重いデータ前処理パイプラインの負荷を均等に分散する方法を示しました。これにより、トレーニング環境に補助的なCPUインスタンスを追加するだけでCPUのボトルネックを簡単に解消することができます。Amazon SageMakerの異種クラスタサポートは、専任のデボップスサポートが不要であり、Rayトレーニングジョブをクラウドで実行する魅力的な方法です。
ここで提示された解決策は、CPUのボトルネックに対処するための多くの異なる方法のうちの1つに過ぎません。最適な解決策は、プロジェクトの詳細に大きく依存することに注意してください。
通常どおり、ご意見、訂正、質問についてお気軽にお問い合わせください。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles






