「私たちのLLMモデルを強化するための素晴らしいプロンプトエンジニアリング技術」
「美容とファッションのエキスパートになるための魅力的なプロンプトエンジニアリング技術」

人工知能はテックワールドにおいて完全なる革命をもたらしました。
人間の知能を模倣し、かつては完全に人間の領域だと考えられていたタスクを実行できる能力は、私たちのほとんどをまだ驚かせています。
しかし、これらの最新のAIの進歩がどれほど優れているとしても、改善の余地は常にあります。
そして、それが prompt engineering(プロンプトエンジニアリング)の重要性が生まれる場所です!
AIモデルの生産性を大幅に向上させることができるこの分野に入ってみましょう。
一緒にすべてを発見しましょう!
プロンプトエンジニアリングの本質
プロンプトエンジニアリングは、言語モデルの効率と効果を向上させることに焦点を当てたAIの急成長領域です。私たちの求める出力を生成するためにAIモデルを導く完璧なプロンプトを作り出すことです。
それは誰かにより良い指示を与えることを学ぶのと同じようなものであり、タスクを正しく理解して実行することを保証するための手法です。
プロンプトエンジニアリングの重要性
- 生産性の向上: 高品質のプロンプトを使用することで、AIモデルはより正確かつ関連性のある応答を生成することができます。これにより、修正にかかる時間が短縮され、AIの機能を最大限に活用するための時間が増えます。
- コスト効率: AIモデルのトレーニングには多くのリソースが必要です。プロンプトエンジニアリングにより、モデルのパフォーマンスを最適化することで再トレーニングの必要性を減らすことができます。
- 多目的性: 熟練されたプロンプトによって、AIモデルはより多様なタスクや課題に取り組むことができるようになります。
最も高度な技術に入る前に、最も有用(かつ基本的な)プロンプトエンジニアリングの技術を振り返りましょう。
基本的なプロンプトエンジニアリングの手法の一部を垣間見る
「ステップバイステップで考えましょう」という連続的な思考
今日、LLMモデルの正確さは、「ステップバイステップで考えましょう」という言葉を加えることで大幅に向上することがよく知られています。
なぜでしょうか?
それは、タスクを複数のステップに分解させることで、モデルがそれぞれを処理する十分な時間を持つようにするためです。
例えば、以下のプロンプトでGPT3.5に挑戦することができます:
ジョンが梨を5つ持っていて、それらのうち2つを食べ、さらに5つを購入し、最後に3つを友人にあげた場合、ジョンは何個の梨を持っていますか?
モデルは即座に答えを出します。しかし、最後に「ステップバイステップで考えましょう」と追加すると、複数のステップの考えるプロセスをモデルに生成させることができます。
フューショットプロンプティング
ゼロショットプロンプトは、コンテキストや以前の知識を提供せずにモデルにタスクを実行させることを指しますが、フューショットプロンプティング手法では、特定の質問に加えて、求める出力の数例をLLMに提示します。
例えば、詩的なトーンで任意の用語を定義するモデルを作成したい場合、説明することは非常に困難かもしれません。
しかしこのようなフューショットプロンプトを使用することで、モデルを望む方向に導くことができます。
あなたのタスクは、以下のスタイルに合った一貫性のあるスタイルで答えることです。
<user>: 誇りに思いでください。
<system>: 誇りは風と一緒に揺れる木のようなものであり、決して折れることはありません。
逆境から跳ね返り、前に進み続ける能力です。
<user>: ここに入力してください。
まだ試したことがない場合は、GPTに挑戦してみてください。
しかし、ほとんどの方々がこれらの基本的な手法を既にご存知だと確信しているため、いくつかの高度な技術で皆さんを挑戦してみたいと思います。
高度なプロンプトエンジニアリング技術
1. Chain of Thought (CoT) プロンプティング
2022年にGoogleによって導入されたこの手法は、モデルに最終的な応答を提供する前に、複数の思考過程を経てもらうよう指示するものです。
なんだか聞いたことがありますよね?そう思った方は全く合っています。
これは、連続思考と少量プロンプティングの両方を結びつけたものです。
では、どのようにするのでしょうか?
基本的に、CoTプロンプティングはLLMに情報を順序立てて処理するよう指示します。つまり、最初の問題を複数のステップの推論で解決する方法を実証し、実際のクエリに対して解答する際にも類似した思考チェーンをエミュレートすることを期待して、モデルに実際のタスクを送信します。
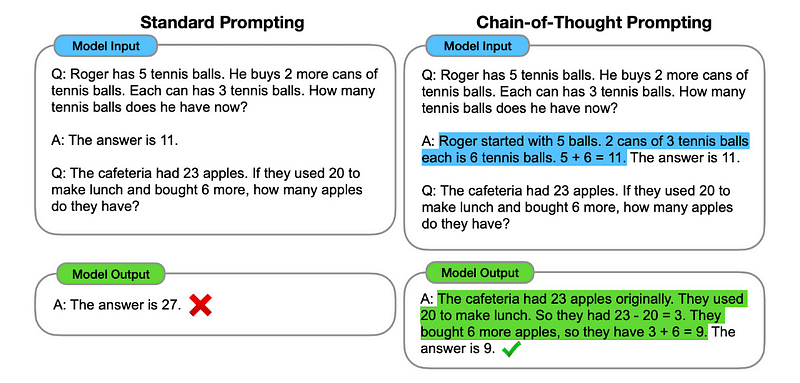
ですから、最初の例に従って、最初の問題とそれを解決する手順の順序立てられた説明をプロンプトとして提供することができます。そして、入力を送信し、魔法がどのように起こるか見ることができます。
<ユーザー> もしジョンが梨を5個持っていて、それから2つ食べて、さらに5つ買って、最後に3つ友達にあげたとしたら、ジョンは何個の梨を持っているでしょうか?手順を考えましょう。
<エージェント> 一つずつ考えていきましょう。ジョンは最初に5個の梨を持っています。彼は2個の梨を食べたので、残りは5-2=3個の梨です。それから、彼はさらに5個の梨を買います。ですから、彼は今、3+5=8個の梨を持っています。最後に、彼は3個の梨を友達にあげます。したがって、彼は8-3=5個の梨を残します。これらのステップを経て、ジョンは5個の梨を持っています。
<ユーザー> ここにあなたの入力です。
しかし、ほとんどの方は考えているでしょう… ChatGPTで何か質問したい時に、必ず順序立てて問題を解決する方法を考える必要があるのでしょうか?
まあ…あなたは最初ではありません!そして、それが私たちを次に導くのは…
2. Automatic Chain-of-Thought (Auto-CoT)
2022年、Zhang氏とその同僚は、この手作業のプロセスを回避する方法を提案しました。手作業のタスクを回避する理由としては、主に2つあります:
- それは退屈であることがあります。
- 思考プロセスが間違っている場合など、悪い結果をもたらす可能性があります。
彼らは、LLMと「一つずつ考えていきましょう」というプロンプトを組み合わせて、各デモンストレーションのために推論チェーンを順次生成する方法を提案しました。
つまり、ChatGPTにどのように問題を順次解決するかを尋ね、それから同じ例を使用して他のどんな問題でも解決する方法を訓練するということです。
3. 自己整合性
自己整合性は、より複雑な推論問題のための思考の連鎖を改善するための興味深いプロンプティング手法です。
では…主な違いは何でしょうか?
自己整合性の基本的な考え方は、モデルを間違った例で訓練できるということです。前の問題を間違った思考プロセスで解決すると想像してみてください:
<ユーザー> もしジョンが5個の梨を持っていて、それから2個を食べて、さらに3個を友達にあげる場合、ジョンは何個の梨を持っていますか?手順を考えましょう。
<エージェント> 最初に5個の梨から始めましょう。ジョンは2個の梨を食べます。それから、彼は3個の梨を友達にあげます。これらの行動は結合できます:2 (食べた) + 3 (あげた) = 合計5個の梨が影響を受けました。 そして、最初の5個の梨から影響を受けた梨の総数を引きます:5 (最初の数) – 5 (影響を受けた数) = 0個の梨が残ります。それでは、モデルに送信する他のタスクはすべて間違ってしまいます。
これがなぜセルフコンシステンシーには、各々が思考の鎖を含むさまざまな推論パスからサンプリングし、その後LLMに最善かつ最も一貫性のあるパスを選択させて問題を解決させる必要がある理由です。
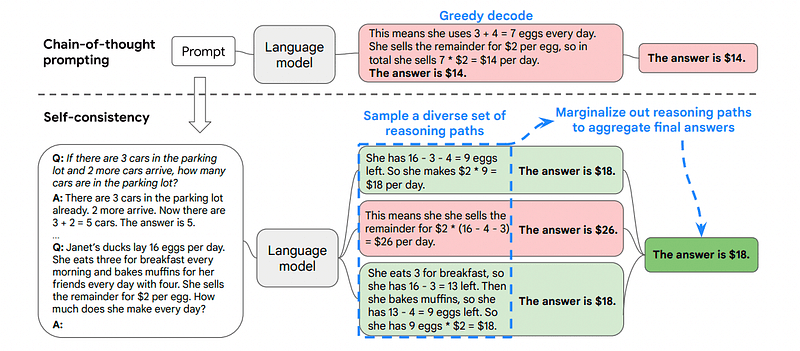
この場合、最初の例に続いて、モデルにさまざまな問題解決方法を示すことができます。
<ユーザー> ジョンが梨を5個持っていて、2個食べて、5個買って、それから3個友達にあげる場合、彼は何個の梨を持っていますか?
<エージェント> 5個の梨から始めます。ジョンが2つの梨を食べるので、残りは5−2=3個の梨です。彼はさらに5個の梨を買いますので、合計で3+5=8個の梨になります。最後に、彼は3個の梨を友達にあげるので、残りは8−3=5個の梨です。
<ユーザー> ジョンが梨を5個持っていて、2個食べて、5個買って、それから3個友達にあげる場合、彼は何個の梨を持っていますか?
<エージェント> 5個の梨から始めます。彼はさらに5個の梨を買います。ジョンが今2個の梨を食べます。これらの行動を組み合わせることができます: 2個(食べた)+ 5個(買った)= 合計7個の梨です。合計量の中からジョンが食べた梨を引いて、残りの梨 7(合計量)− 2(食べた)= 残る梨5個です。
<ユーザー> ここに入力してください。
そして、最後のテクニックが登場します。
4. 一般知識のプロンプティング
プロンプトエンジニアリングの共通の方法は、最終的なAPIコールをGPT-3またはGPT-4に送る前に、クエリに追加の知識を付加することです。
Jiacheng Liu and Coによると、質問についてLLMがより理解するために常にいくつかの知識を追加できます。
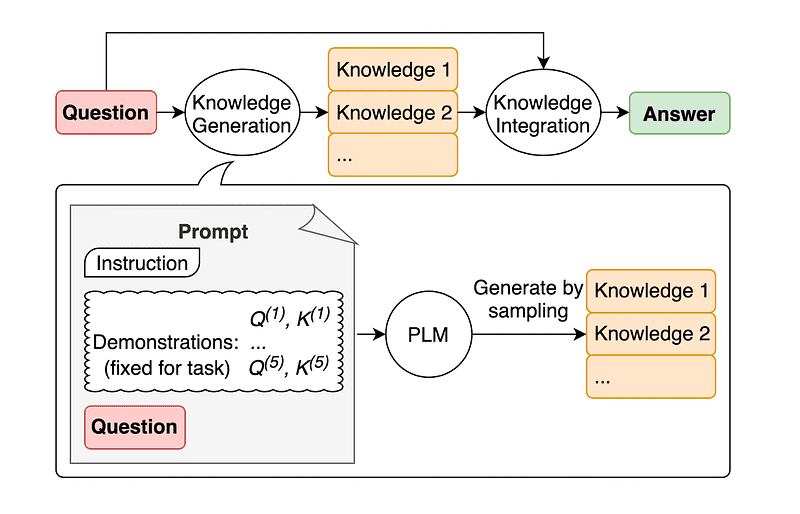
したがって、例えば、ゴルフの一部が他の人よりも高いポイント総数を目指すことであるかどうかをChatGPTに尋ねる場合、私たちに確認されます。しかし、ゴルフの主な目標はまったく逆です。このため、「スコアが低いプレーヤーが勝つ」という以前の知識を追加することができます。

では。。。モデルにまさに答えを教えているので、おかしなところは何でしょうか?
この場合、この技術はLLMが私たちとの対話を改善するために使用されます。
外部データベースから補足的なコンテキストを取り出すのではなく、この論文の著者は、LLMが自身の知識を生成することを推奨しています。この自己生成された知識は、常識的な推論を強化し、より良い出力を提供するために、プロンプトに統合されます。
LLMの訓練データセットを増やさずに、LLMを改善する方法です。
まとめ
プロンプトエンジニアリングは、LLMの機能を向上させるための重要な技術として浮上しています。プロンプトを反復して改善することで、AIモデルとより直接的にコミュニケーションを取り、より正確で文脈に即した出力を得ることができます。これにより、時間とリソースの両方を節約することができます。
テック愛好家、データサイエンティスト、コンテンツクリエーターなど、プロンプトエンジニアリングの理解とマスタリングは、AIのフルポテンシャルを引き出す上で貴重な資産となるでしょう。
注意深く設計された入力プロンプトとこれらの高度な技術を組み合わせることで、プロンプトエンジニアリングのスキルセットを持つことは、将来の成功において有利となることでしょう。
[Josep Ferrer](https://www.linkedin.com/in/josep-ferrer-sanchez)はバルセロナ出身の解析エンジニアです。彼は物理工学を卒業し、現在は人間の移動に応用されるデータサイエンス分野で働いています。彼はデータサイエンスとテクノロジーに特化したパートタイムのコンテンツクリエーターです。彼にはLinkedIn、Twitter、またはVoAGIで連絡することができます。
We will continue to update VoAGI; if you have any questions or suggestions, please contact us!
Was this article helpful?
93 out of 132 found this helpful
Related articles
- ユニバーサルシミュレータ(UniSim)をご紹介します:生成モデリングを通じたリアルワールドの対話をインタラクティブにシミュレートするシミュレータ
- ChatGPT vs. BARD’の比較
- 「切り分けて学ぶ」による機械学習におけるオブジェクトの状態合成の認識と生成
- ウェアラブルテックを革命:エッジインパルスの超効率的な心拍数アルゴリズムと拡大するヘルスケアスイート
- このAI論文は、言語エージェントのための自然言語とコードの調和を目指して、LemurとLemur Chatを紹介しています
- Amazon SageMakerのマルチモデルエンドポイントを使用して、Veriffがデプロイ時間を80%削減する方法
- RAGアプリケーションデザインにおける実用的な考慮事項






